clickhouse分布式之弹性扩缩容的故事
现状
社区不支持喔,以后也不会有了。曾经尝试过,难道是是太难了,无法实现吗?因为他们企业版支持了,可能是利益相关吧,谁知道呢,毕竟开源也要赚钱,谁乐意一直付出没有回报呢。
社区之前有个"残废"的 Zero-copy replication特性,本质就是为了做弹性扩缩容的。该特性一直半推半就,直到现在官方都说不稳定,bug多,不推荐使用。推荐使用云原生企业版SharedMergeTree,建议你花钱。
Zero-copy replication
从名字看,是个零拷贝复制。原理如图:
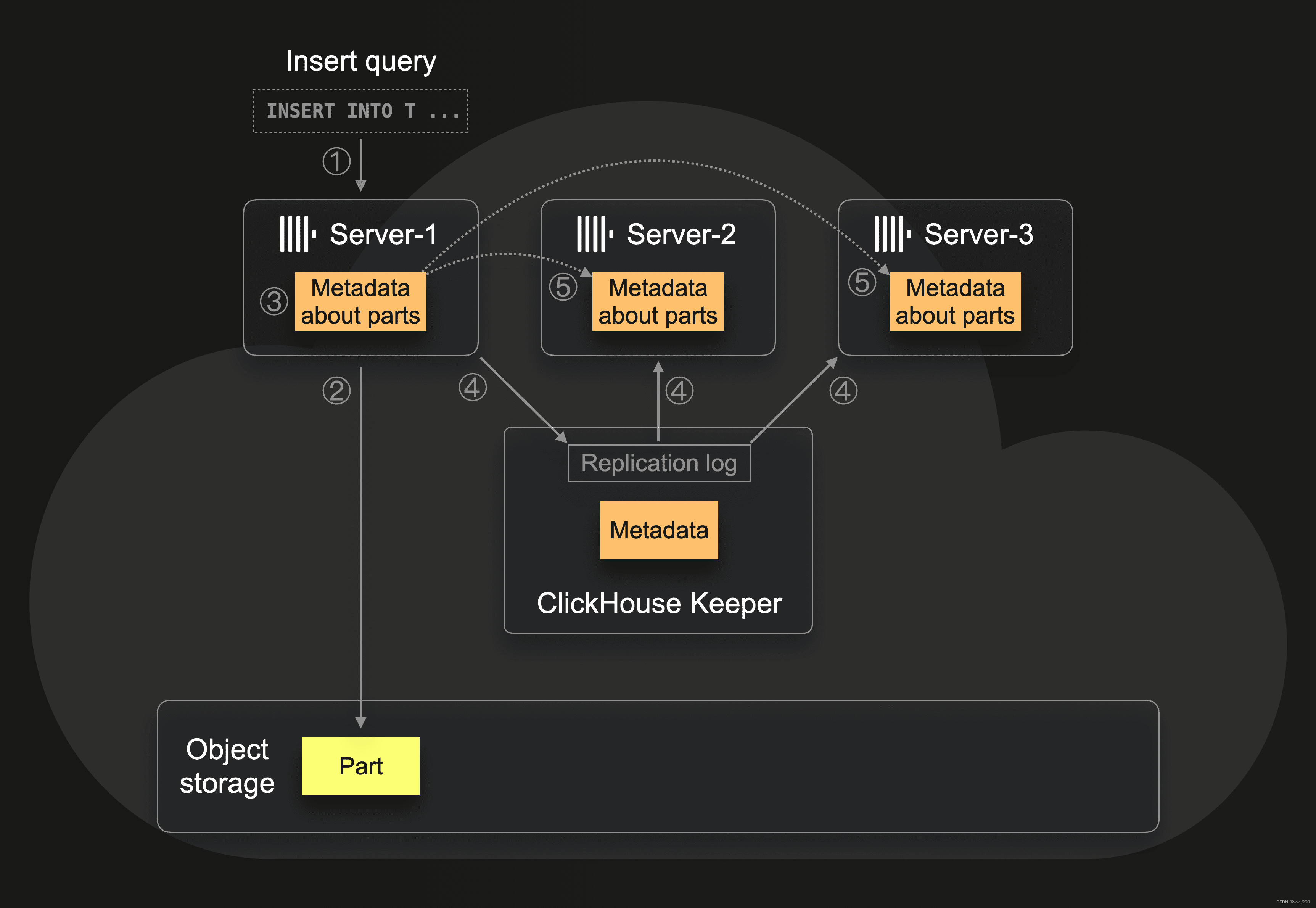
- server-1收到插入业务数据请求
- server-1把业务数据写入到远端的对象存储中
- server-1在本地磁盘记录业务数据的元数据(例如,业务数据存储在对象存储中的位置)
- server-1通过clickhouse-keeper (zoo-keeper) 通知server-2和server-3,自己有新的元数据
- server-2和server-3从server-1下载对应的元数据,写入到本地磁盘
这种改变,对于clickhouse来说,数据不需要“再均衡”,弹性扩缩容变得很容易。同时也带来了如下几个问题:
- 需要分布式引用计数。当删除数据时,首先要确保所有节点上,关于该数据的元数据都被删除后,才能真的删除该数据。
- 需要分布式锁。合并和变更同时只能一个节点去做。
- 元数据仍然与计算节点耦合,本地磁盘是附加的故障点。
- 很难用于大规模集群。大量节点之间的元数据同步和锁的竞争,会拖垮整个集群。
SharedMergeTree
这个就是企业版中弹性扩缩容的依仗。既然是企业版,那么就意味着代码没有开源。
从名字看,
首先是共享,也必然是shared storage架构,只有这样才能做到快速的弹性扩缩容,而不影响集群数据的完整性。
然后是MergeTree,依然是MergeTree家族系列。意味着你也可以继承MergeTree从而实现自己的SharedMergeTree。
原理如图:
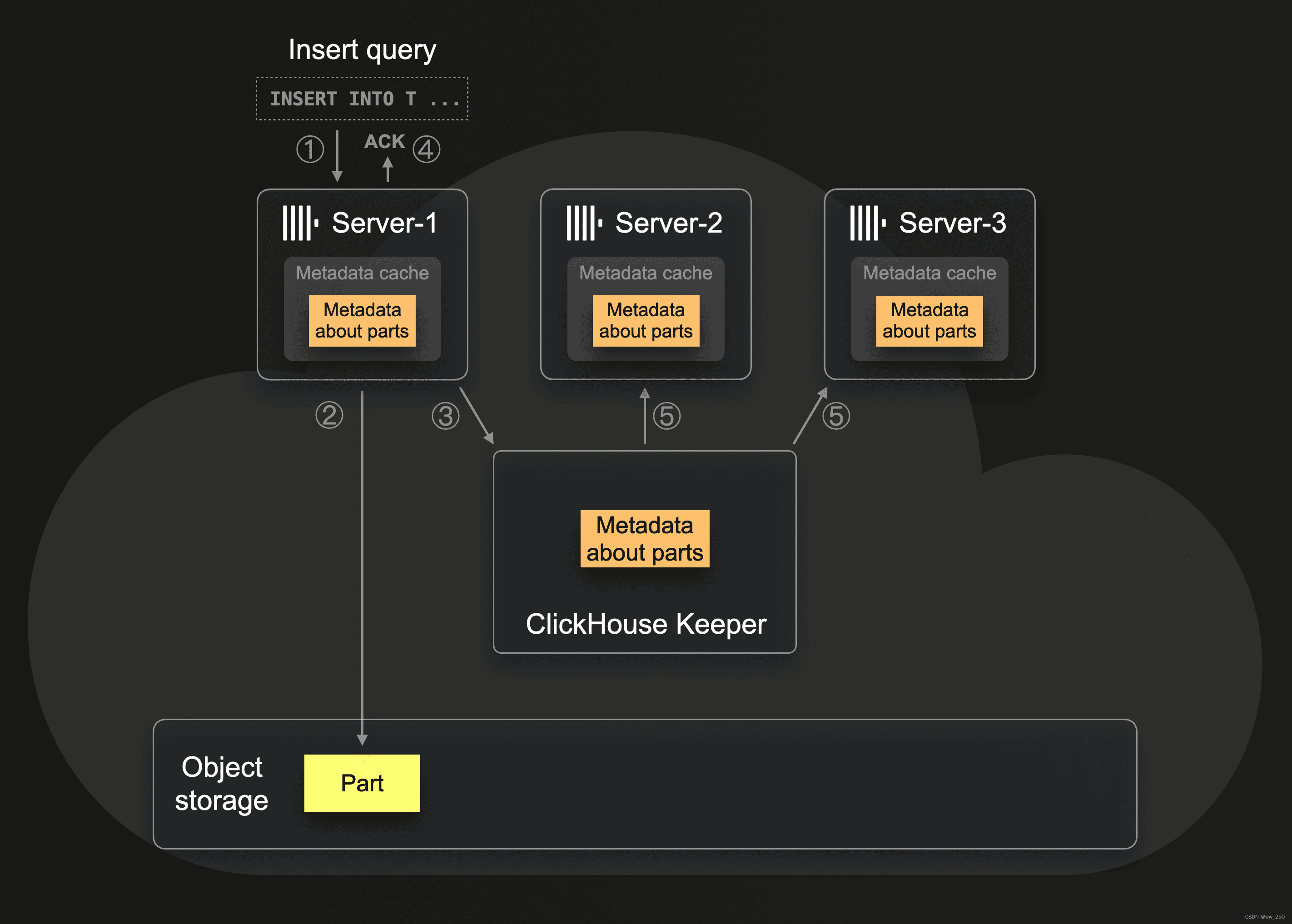
- server-1收到插入业务数据请求
- server-1把业务数据写入到远端的对象存储中
- server-1在本地磁盘和keeper中记录业务数据的元数据(例如,业务数据存储在对象存储中的位置)
- server-1向查询者确认插入
- server-2和server-3从keeper中收到元数据变更通知,更新元数据到本地磁盘
这种改动使得集群间的节点之间不需要再同步元数据,keeper充当集群的协调者。
新增一个节点,该节点只需要从keeper中同步完元数据后,即可参与数据处理。
移除一个节点,该节点从keeper中注销自己,即可优雅下线。
其实很多细节官方都没有描述出来,
比如数据的merge和update问题,节点越多,速度越快。节点间的merge和update协调如何做的?
再比如对一个单一查询,节点越多,速度越快。怎么做的任务切分和最终聚合?
如何既要又要
那么如何做到既要分布式弹性伸缩,又要不花钱?
自己二次开发
就像上面说的,自己继承MergeTree,实现自己的SharedMergeTree。比较考验技术水平,同时需要的时间和精力比较多。
参考 redis cluster
redis3.0官方出的cluster方案,仔细分析就会发现,服务端其实没多少复杂改动,工作量基本都push到了客户端。但是并不妨碍这种集群方案的流行。
回归到clickhouse呢?相比较redis的客户端,clickhouse的客户端工作量要少一半,对于读取,分布式查询clickhouse天然支持的很完美,那么关注点只需要在写入上就可以了。
实现方案
下图演示如何针对clickhous集群做节点的扩缩容。此处写入用的是本地表,这也是官方建议的。写分布式表意味着集群越大,性能越差。
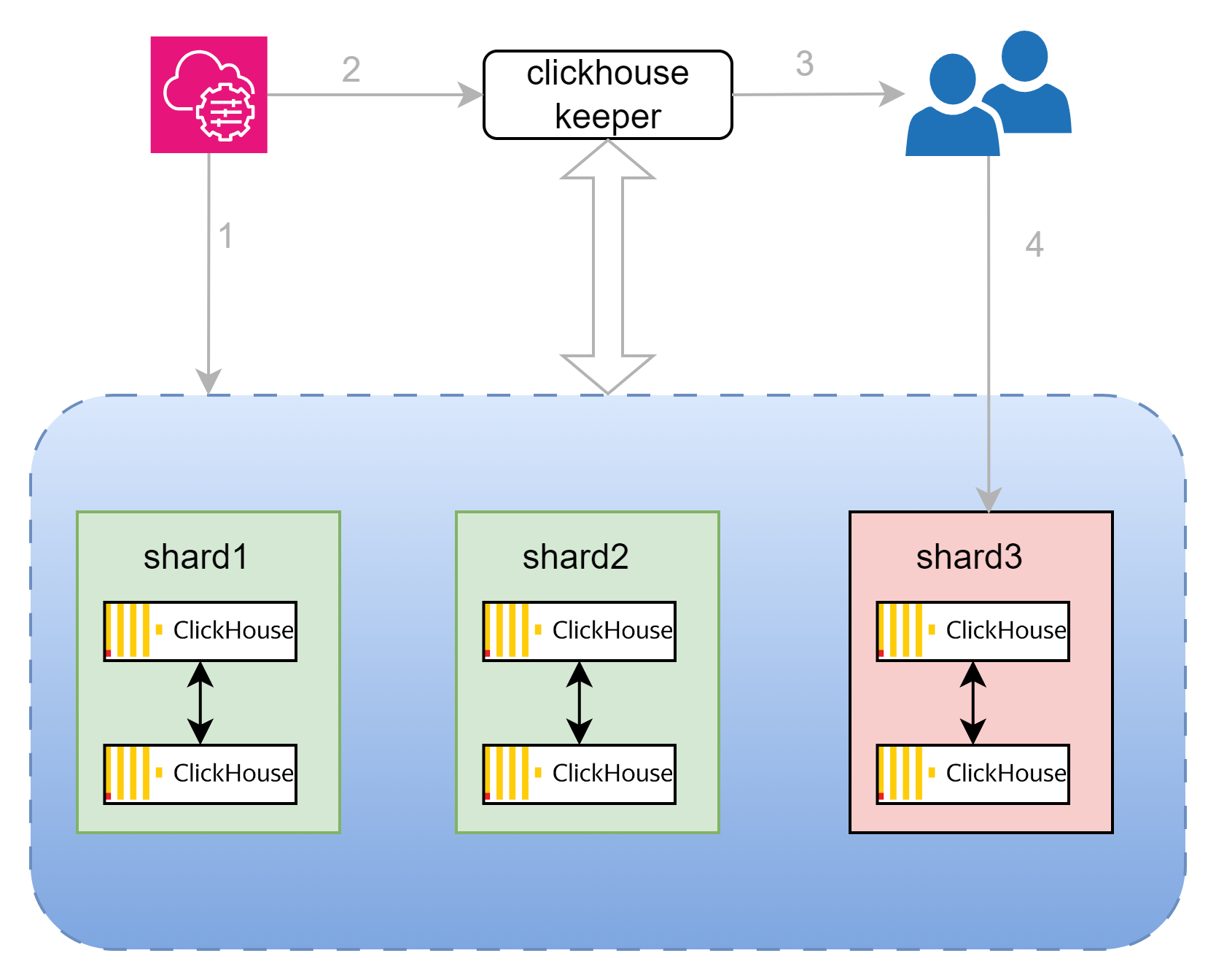
- 由于加入/移除分片shard3,需要在clickhouse管理平台上添加节点的信息,生成新的配置文件后,由管理平台分发到集群的6个节点上(如果是移除,则是4个节点)覆盖老的配置文件。无需重启服务,配置文件会被热加载。
- 把集群信息 全量/增量写入keeper中(此处复用集群的keeper)
- 业务系统收到集群信息变更后
- 如果是移除节点,则需要针对分片3的数据做再平衡。从节点3读取数据,均衡写入到分片1和2,完成此操作后,通知clickhouse管理平台,节点缩容成功。虽然缩容过程可能较为耗时,但是在非云服务环境下,缩容场景本身就不常见,此处只是给出一个可行方案。
此时,数据写入因为分片3被移除,所以需要动态调整写入。数据读取因为分布式查询无需做任何改动。
如果是添加节点,业务系统则需要对分片3的2个节点创建分布式表。此时数据写入因为分片3的新增,所以需要动态调整写入。数据读取因为分布式查询无需做任何改动。
总结
集群的变动带来的工作量基本都push到了客户端。缩容时,读取数据再平衡写入到其他分片。扩容时候,写入数据动态平衡。
这种replicateMergeTree+分片的架构,和sharedMergeTree在某些方面比较相似:
- 单个查询加速,节点越多速度越快,因为数据是分片的,每个分片都计算处理自己的数据,相互不干扰,最终聚合。
- merge和update也都是分片独立处理自己的数据
与sharedMergeTree在某些方面也有不同之处:
- 节点移除时,数据需要再均衡,需要时间
- 分片之间的副本需要同步数据,也会降低一些性能