普通表计读数开发思路
一、普通表计类型介绍🍉
常见的普通表计有SF6,压力表,油位表(指针类)等。

图1:( 压力表)

图2:(油位表-指针类)

图3:(SF6表)

图4:(单指针油温表)

图5:(泄漏电流表-表盘2)
好了,普通表计的类型大概就是有这些了。那么看到这里我们不经有一个疑问——为什么把他们归为普通表计?
答案其实很简单,因为“单指针”。
单指针的表计是很好识别的,如果有表计读数开发经验的伙计应该都知道。多指针的表计读数开发,分割指针的后处理是有多麻烦,为了应对各种各样的情况,后处理的代码可能多达几千行。
二、思路🍉
我们不得不以一个图片为例子,那么就选取最经典,也是最容易的压力表吧!
2.1 对点位进行打点(略)🎈。
2.2 对表盘进行检测🎈。
在此之前我们需要训练一个yolo目标检测模型,用于检测表盘以及表计的类型。假设我们已经拥有了他detection_meter,使用它对输入的图片进行检测,检测结果大致如下:

我们将得到两个重要的信息:
- 标签<str>——表计类型:meter_type。
- 矩形框<xmin, ymin, xmax, ymax>——表盘位置 : rectangle_meter。
根据此可以裁剪得到表盘和根据表盘的类型进行分类别预处理。(略)
。。。
2.3 对指针进行分割🎈。
此时我们需要一个必不可缺的指针分割模型对上一步裁剪出来的表盘进行分割,这里可以推荐一下:百度飞桨paddle的工业表计指针分割模型,开源可商用。(太久了,链接一下子找不着了。)
效果大致如下:
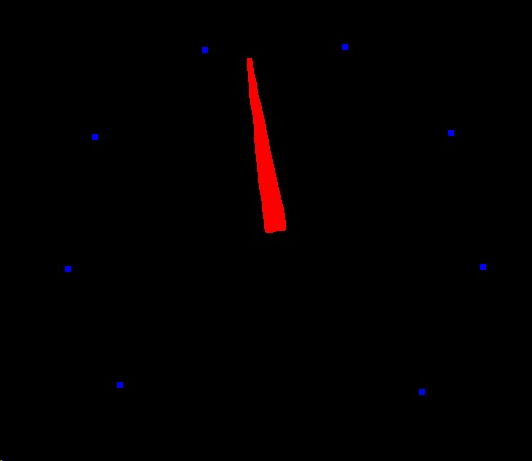
2.4 矩形展开指针和点位🎈。
NOTE:当然也可以不展开,直接根据点位的[<x1,y1>,<x2,y2>,...,]坐标和指针顶端的位置<x,y>,进行一个角度的位置判断。但是这里我们只探究展开矩形的方式。
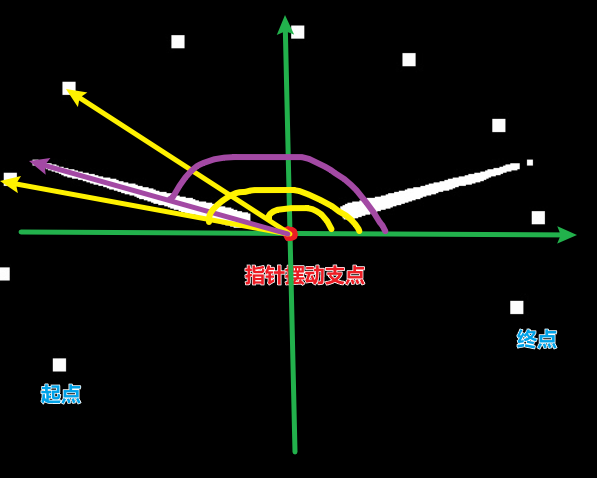
将呈圆形的点位连带指针一起展开成矩形 :
根据此展开图,获取指针分割图普通坐标轴中x轴方向的位置:
- point_location<float>: 483.4
同样的得到点位x所处的位置:
- scale_location<list>: [43.0, 136.5, 231.5, 325.5, 466.0, 574.0, 678.5, 811.0, 936.0, 1083.5]
<展开原理如下:>
def circle_to_rectangle(self, seg_result):
"""将圆形表盘的预测结果label_map转换成矩形
圆形到矩形的计算方法:
因本案例中两种表盘的刻度起始值都在左下方,故以圆形的中心点为坐标原点,
从-y轴开始逆时针计算极坐标到x-y坐标的对应关系:
x = r + r * cos(theta)
y = r - r * sin(theta)
注意:
1. 因为是从-y轴开始逆时针计算,所以r * sin(theta)前有负号。
2. 还是因为从-y轴开始逆时针计算,所以矩形从上往下对应圆形从外到内,
可以想象把圆形从-y轴切开再往左右拉平时,圆形的外围是上面,內围在下面。
参数:
seg_results (list[dict]):分割模型的预测结果。
返回值:
rectangle_meters (list[np.array]):矩形表盘的预测结果label_map。
"""
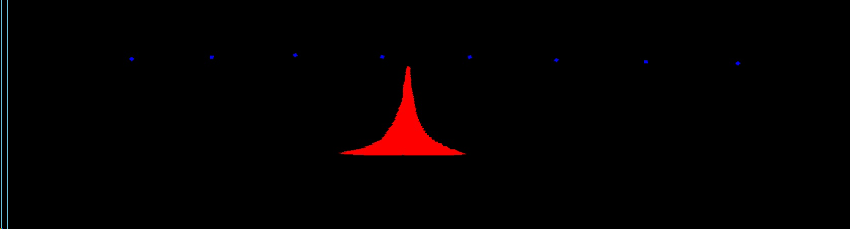
...(不可知)到这里恐怕很多人已经想到使用cv2.connectedComponetsWithStats来做了。但是我们不能只考虑理想的情况下,其中对于获取指针顶点的位置,状况百出,分割出来的红指针可能是不规则类型的,可能是歪着的,甚至可能是只有一半。
如果单纯通过cv2的连通域得到的左上角坐标和右下角坐标,很多时候其实会出现错误情况:比如这样的:
我们需要从上向下找到位置最低的那些像素块选取最中间那个,代码块如下:
def get_connected_components(self, image):
# 二值化处理
ret, binary = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 获取连通域信息
output = cv2.connectedComponentsWithStats(binary, connectivity=8, ltype=cv2.CV_32S)
num_labels = output[0]
labels = output[1]
stats = output[2]
centroids = output[3]
# 获取每个连通域的最高点和最低点坐标
result = []
highest_points = []
for i in range(1, num_labels):
x, y, w, h, area = stats[i]
top_left = (x, y)
bottom_right = (x + w - 1, y + h - 1)
result.append((top_left, bottom_right))
label = i
points = np.argwhere(labels == label)
# print(points)
# 找到x轴最小的点
max_x = np.min(points[:, 0])
max_x_points = points[points[:, 0] == max_x]
# 找到y轴最中的点
max_y = np.median(max_x_points[:, 1])
# 添加最高点坐标到列表中
highest_points.append((max_y, max_x))
sorted_result = sorted(result, key=lambda x: (x[0][0]+x[1][0])/2)
highest_points = [ele[0] for ele in sorted(highest_points, key=lambda x:x[0])]
print("highest_points:", highest_points)
return sorted_result, highest_points2.5 根据点位x_list和指针顶端x便可计算出读数🎈。
这是显而易见的,因为只需要计算指针顶端x在点位x_list中的位置,再加上每一个点位代表的读数,便可以轻松得到读数结果。
三、点位纠偏🥒
当然实际的情况远远不会如此理想,比如对于摄像头的点位偏移问题,比如多指针问题,更比如模糊问题等等。这时候就需要其他多种技术,例如这里以仿射变换进行点位纠偏来作为一个示例:

点位偏差一直是一个很头疼的问题,但是由于摄像头和实际环境的局限性,我们不得不面对这个问题。对此,使用判别的方式进行一个仿射变换,是一种非常有效的方式,下图中图1是基准图,图2是目标图,图3是目标图仿射变换后得到的结果图。

可以看出效果非常的nice。
import cv2
import numpy as np
def get_good_match(des1,des2):
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append(m)
return good
def sift_kp(image):
'''SIFT特征点检测'''
height, width = image.shape[:2]
size = (int(width * 0.2), int(height * 0.2))
shrink = cv2.resize(image, size, interpolation=cv2.INTER_AREA)
gray_image = cv2.cvtColor(shrink,cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT.create()
kp, des = sift.detectAndCompute(gray_image, None)
return kp,des
def siftImageAlignment(img1,img2):
"""
img1: cv2.imread后读取的图片数组,标准图;
img2: cv2.imread后读取的图片数组,测试图。
函数作用:把img2配准到img1上,返回变换后的img2。注意:img1和img2的size一定要相同。
"""
kp1,des1 = sift_kp(img1)
kp2,des2 = sift_kp(img2)
goodMatch = get_good_match(des1,des2)
if len(goodMatch) > 4:
ptsA= np.float32([kp1[m.queryIdx].pt for m in goodMatch]).reshape(-1, 1, 2)
ptsB = np.float32([kp2[m.trainIdx].pt for m in goodMatch]).reshape(-1, 1, 2)
ptsA = ptsA / 0.2
ptsB = ptsB / 0.2
ransacReprojThreshold = 4
H, status =cv2.findHomography(ptsA,ptsB,cv2.RANSAC,ransacReprojThreshold)
imgOut = cv2.warpPerspective(img2, H, (img1.shape[1],img1.shape[0]),flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
return imgOut
else:
return img2
def cv_imread(file_path):
"""
能读取中文路径的cv2读图函数。
"""
cv_img = cv2.imdecode(np.fromfile(file_path,dtype=np.uint8),-1)
return cv_img
def align(t0_path, t1_path):
"""
测试函数,分别输入标准图和测试图的路径,输出变换后的图和对比图。
"""
t0 = cv_imread(t0_path)
t1 = cv_imread(t1_path)
t1_img_align, _, _, ptsA, ptsB = siftImageAlignment(t0, t1)
# # 把配准图写到本地
# t1_new_bn = 'align_' + os.path.basename(t1_path)
# cv2.imwrite('./pics/' + t1_new_bn, t1_img_align)
# new_img = np.vstack((t0, t1, t1_img_align))
# com_bn = 'compare_' + os.path.basename(t1_path)
# cv2.imwrite('./pics/' + com_bn, new_img)
return t1_img_align
if __name__ == "__main__":
t0_path = r".\_1723957234138288128.jpg"
t1_path = r".\1723957234138288128_20231115_200243.jpg"
align(t0_path, t1_path)注意着仍然会出现一些不好的状况,但相似点寻找错误或者过小的时候。