MIT6.824-Raft笔记:Raft初探、副本间log时序
从宏观角度说明raft在程序中的作用,和客户端的关系,以及多个副本之间的关系;从微观角度说明多个副本之间raft对日志处理的流程。
1. Raft 初探
宏观角度说明raft在程序中的作用,和客户端的关系,以及多个副本之间的关系。
Raft会以库(Library)的形式存在于服务中。如果你有一个基于Raft的多副本服务,那么每个服务的副本将会由两部分组成:应用程序代码和Raft库,应用程序代码接收RPC或者其他客户端请求,不同节点的Raft库之间相互合作,来维护多副本之间的操作同步。从软件的角度来看一个Raft节点的上层,是应用程序代码。应用程序通常都有状态,Raft层会帮助应用程序将其状态拷贝到其他副本节点。例如:Key-Value数据库对应的状态就是Key-Value Table。应用程序往下,就是Raft层。Key-Value数据库需要对Raft层进行函数调用,来传递自己的状态和Raft反馈的信息。Raft本身也会保持状态,Raft的状态中,最重要的就是Raft会记录操作的日志。
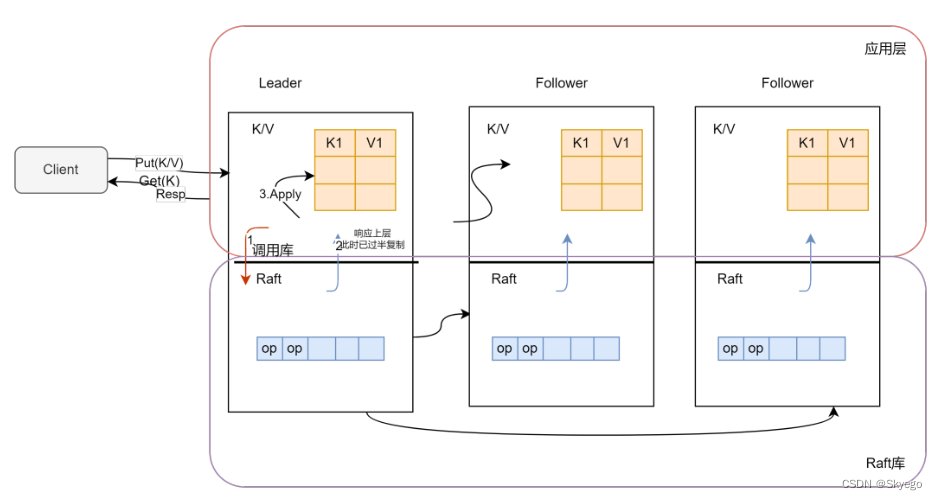
对于一个拥有三个副本的系统来说,很明显我们会有三个服务器,这三个服务器有完全一样的结构(上面是应用程序层,下面是Raft层)。理想情况下,也会有完全相同的数据分别存在于两层(应用程序层和Raft层)中。除此之外,还有一些客户端,假设我们有了客户端1(C1),客户端2(C2)等等。客户端就是一些外部程序代码,它们想要使用服务,同时它们不知道,也没有必要知道,它们正在与一个多副本服务交互。从客户端的角度来看,这个服务与一个单点服务没有区别。
客户端会将请求发送给当前Raft集群中的Leader节点对应的应用程序。这里的请求就是应用程序级别的请求,例如一个访问Key-Value数据库的请求。这些请求可能是Put也可能是Get。Put请求带了一个Key和一个Value,将会更新Key-Value数据库中,Key对应的Value;而Get向当前服务请求某个Key对应的Value。看起来似乎没有Raft什么事,就像是普通的客户端服务端交互。一旦一个Put请求从客户端发送到了服务端,对于一个单节点的服务来说,应用程序会直接执行这个请求,更新Key-Value表,之后返回对于这个Put请求的响应。但是对于一个基于Raft的多副本服务,就要复杂一些。
假设客户端将请求发送给Raft的Leader节点,在服务端程序的内部,应用程序只会将来自客户端的请求对应的操作向下发送到Raft层,并且告知Raft层,请把这个操作提交到多副本的日志(Log)中,并在完成时通知我。之后Raft节点之间相互交互,直到过半的Raft节点将这个新的操作加入到它们的日志中,也就是说这个操作被过半的Raft节点复制了。当且仅当Raft的Leader节点知道了过半副本都有了这个操作的拷贝之后。Raft的Leader节点中的Raft层,会向上发送一个通知到应用程序,也就是Key-Value数据库,来说明:刚刚你提交给我的操作,我已经提交给过半副本,并且已经成功拷贝给它们了,现在你可以真正的执行这个操作了。
客户端发送请求给Key-Value数据库,这个请求不会立即被执行,当且仅当这个请求存在于过半的副本中时,Raft才会通知Leader节点,只有在这个时候,Leader才会实际的执行这个请求。对于Put请求来说,就是更新Value,对于Get请求来说,就是读取Value。最终,请求返回给客户端,这就是一个普通请求的处理过程。
为了严格保证Get请求的结果,可以也和写数据一样,走一遍raft log,但是也可以采用ReadIndex的方案;当然如果不需要特别严格,使用leaderRead即可。
学生提问:除了Leader节点,其他节点的应用程序层会有什么样的动作?
Robert教授:当一个操作最终在Leader节点被提交之后,每个副本节点的Raft层会将相同的操作提交到本地的应用程序层。在本地的应用程序层,会将这个操作更新到自己的状态。理想情况是所有的副本都将看到相同的操作序列,这些操作序列以相同的顺序出现在Raft到应用程序的upcall中,之后它们以相同的顺序被本地应用程序应用到本地的状态中。假设操作是确定的(比如一个随机数生成操作就不是确定的),所有副本节点的状态,最终将会是完全一样的。我们图中的Key-Value数据库,就是Raft论文中说的状态(也就是Key-Value数据库的多个副本最终会保持一致)。
2. Raft Log 同步时序
微观角度说明多个副本之间raft对日志处理的流程。
接下来我将画一个时序图来描述Raft内部的消息是如何工作的。假设我们有一个客户端,服务器1是当前Raft集群的Leader。同时,我们还有服务器2,服务器3。这张图的纵坐标是时间,越往下时间越长。假设客户端将请求发送给服务器1,这里的客户端请求就是一个简单的请求,例如一个Put请求。
服务器1的Raft层会发送一个添加日志(AppendEntries)的RPC到其他两个副本(S2,S3)。现在服务器1会一直等待其他副本节点的响应,一直等到过半节点的响应返回,这里的过半节点包括Leader自己。在一个只有3个副本节点的系统中,Leader只需要等待一个其他副本节点返回对于AppendEntries的正确响应。
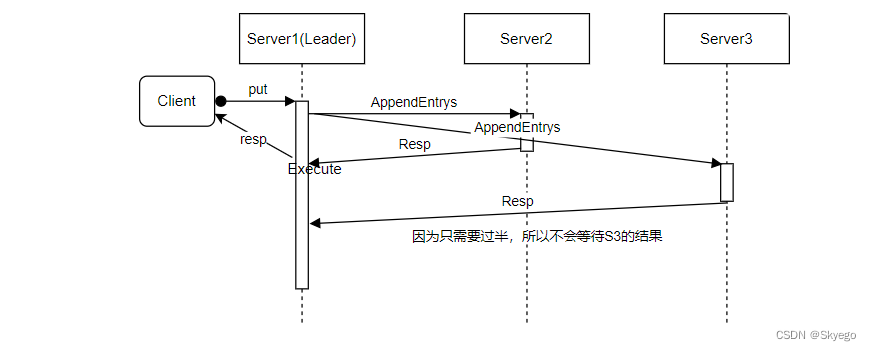
两点说明:
- Server1的Execute可以理解为Apply步骤
- 如图所示,只等了日志复制完成的结果,这里需要leaderRead或者ReadIndex。
当Leader收到了过半服务器的正确响应,Leader会执行(来自客户端的)请求,得到结果,并将结果返回给客户端。
与此同时,服务器3可能也会将它的响应返回给Leader,尽管这个响应是有用的,但是这里不需要等待这个响应,这一点对于理解Raft论文中的图2是有用的。
在Raft中,没有明确的committed消息。相应的,committed消息被夹带在下一个AppendEntries消息中,由Leader下一次的AppendEntries对应的RPC发出。任何情况下,当有了committed消息时,这条消息会填在AppendEntries的RPC中。下一次Leader需要发送心跳,或者是收到了一个新的客户端请求,要将这个请求同步给其他副本时,Leader会将新的更大的commit号随着AppendEntries消息发出,当其他副本收到了这个消息,就知道之前的commit号已经被Leader提交,其他副本接下来也会执行相应的请求,更新本地的状态。
学生提问:S2和S3的状态怎么保持与S1同步?
Robert教授:现在Leader知道过半服务器已经添加了Log,可以执行客户端请求,并返回给客户端。但是服务器2还不知道这一点,服务器2只知道:我从Leader那收到了这个请求,但是我不知道这个请求是不是已经被Leader提交(committed)了,这取决于我的响应是否被Leader收到。服务器2只知道,它的响应提交给了网络,或许Leader没有收到这个响应,也就不会决定commit这个请求。这里还有一个阶段,一旦Leader发现请求被commit之后,它需要将这个消息通知给其他的副本,这里有一个额外的消息。
学生提问:这里的内部交互有点多吧?
Robert教授:是的,这是一个内部需要一些交互的协议,它不是特别的快。实际上,客户端发出请求,请求到达某个服务器,这个服务器至少需要与一个其他副本交互,在返回给客户端之前,需要等待多条消息。一个客户端响应的背后有多条消息的交互。
学生提问:也就是说commit信息是随着普通的AppendEntries消息发出的?那其他副本的状态更新就不是很及时了。
Robert教授:是的,作为实现者,这取决于你在什么时候将新的commit号发出。如果客户端请求很稀疏,那么Leader或许要发送一个心跳或者发送一条特殊的AppendEntries消息。如果客户端请求很频繁,那就无所谓了。因为如果每秒有1000个请求,那么下一条AppendEntries很快就会发出,你可以在下一条消息中带上新的commit号,而不用生成一条额外的消息。额外的消息代价还是有点高的,反正你要发送别的消息,可以把新的commit号带在别的消息里。实际上,我不认为其他副本(非Leader)执行客户端请求的时间很重要,因为没有人在等这个步骤。至少在不出错的时候,其他副本执行请求是个不太重要的步骤。例如说,客户端就没有等待其他副本执行请求,客户端只会等待Leader执行请求。其他副本在什么时候执行请求,不会影响客户端感受的请求时延。