基于scrapy框架的腾讯招聘信息网络爬虫设计与实现
基于scrapy框架的腾讯招聘信息网络爬虫设计与实现
摘要:随着网络科技技术的快速增长,网络数据已经成为一种极其重要的资源。如今的一个研究热点是如何快速和有效率地寻找、提取、分析数据。对于这些方法,运用Python的Scrapy框架可以设计出网络爬虫,对网络数据进行提取分析。先分析网站源代码,之后设计出相应的表达式来提取需要用到的数据,提取结束之后将数据保存进数据库里。
本课题是一个基于scrapy分布式爬虫针对腾讯招聘网站数据的抓取系统,为数据进一步操作做数据支持。设计系统使用Python的Scrapy框架,根据网页分析得到json数据包,然后使用json.load()对下载的网页数据转化为python数据再提取,依靠Redis数据库实现分布式的功能,将数据存储进mysql数据库里,设计以及完成了针对腾讯招聘职位信息的分布式网络爬虫。
关键词:爬虫,scrapy框架,腾讯招聘
The Design and Implementation of Website Crawler of the Tencent Recruitment Information which Basic on Scrapy Distributed
Abstract: With the rapid growth of information technology, network data has become more and more important resource. Nowadays, a research hotspot is how to search, extract and analyze data quickly and efficiently. For these methods, at present, we can use scrapy framework to design web crawler to operate data. At first, it introduces the application of scrapy in python, then analyzes the target website, designs the corresponding expression to extract the required data, and finally saves the data to a file to realize the storage persistence.
Based on scrapy distributed of website data what tencent recruitment scraping system, for the further application of data that is job search and recommendation system to do data support.The project is a distributed crawler based on scrapy in python, according to web page analysis, json.load() is used to convert the downloaded web page data into python data for extraction. The system use Redis database for distribution and use mysql database for data storage, it was designed and implemented a distributed crawler system for tencent‘s recruitment and job data.
Keywords:Crawler, Scrapy, Tencent recruitment
目 录
第1章 绪 论 1
1.1 研究背景和意义 1
1.1.1 选题的目的及意义 1
1.1.2 国内外发展状况 1
1.2 研究的基本内容与拟解决的主要问题 1
1.3 研究的方法与技术路线 2
1.3.1 研究方法 2
1.3.2 研究手段 2
第2章 基于python的网络爬虫 4
2.1 python语言简介 4
2.2 网络爬虫 4
2.2.1 网络爬虫的定义 4
2.2.2 网络爬虫的基本流程 5
2.3 scrapy框架 5
2.3.1 scrapy框架的基本原理 5
2.3.2 scrapy框架的基本流程 7
2.4 分布式网络爬虫原理 8
第3章 网络爬虫模型的设计和实现 9
3.1 网络爬虫的爬取对象 9
3.2 网络爬虫系统功能架构 9
3.3 网络爬虫流程设计 10
3.4 腾讯招聘网页分析 11
3.4.1 判断网页的静/动态加载 11
3.4.2 分析一级网页获取相应数据 12
3.4.3 分析二级网页获取相应数据 14
3.5 网络爬虫的具体实现 15
3.5.1 创建spider项目文件 15
3.5.2 定义Item容器 15
3.5.3 编写爬虫程序 16
3.5.4 编写pipelines.py 19
3.5.5 修改setting.py 20
第4章 第4章 系统功能测试与实现 22
4.1 爬虫运行测试 22
4.2 选择要爬取的地区 22
4.3 爬虫爬取过程 22
4.4 数据库存储数据 23
4.5 爬虫爬取结束 23
结束语 25
参考文献 26
致 谢 27
第1章 绪 论
1.1 研究背景和意义
1.1.1 选题的目的及意义
在早期的互联网时代,人们主要通过筛选网络上大量数据,然后来获取需要信息,互联网技术发展的落后使得搜索技术影响了所需数据的速度和品质,与此同时,互联网一直在快速发展着,信息的质量也变得更加重要。因此,网络信息的传播面临着巨大的机遇和挑战[1]。
如今的大规模数据在不同领域的相同或类似的关键词的模糊性、搜索系统的整体结果都包含着复杂的信息。这是为了让必要的信息出现在画面上,需要做出额外的努力。在时间上,尤其是网络快速发展的情况下,服装、食品、住宅和旅行与网络有着密切的关系。如果想找到好的、满意的工作,在网上招聘信息中也有选择。需要有关招聘新员工的信息将在网上公开。寻找最合适的工作,要求工作地点、工资和其他适当条件,工作经验和培训将使他们掌握有关各领域工作的最合适信息[2]。然而在海量数据里能够自由自在的获取自己所需要的信息,爬虫就是一个不错的选择。
1.1.2 国内外发展状况
上世纪九十年代起,网络爬虫技术便开始被研发。到现在为止,网络爬虫技术已经逐步成熟。网络爬虫主要包括了网页搜索策略和网页分析策略,其中网页搜索策略包含了广度优先法和最佳度优先法;网页分析策略包含了基于网络拓扑的分析算法和基于网页内容的网页分析算法[3]。
1.2 研究的基本内容与拟解决的主要问题
本项目主要抓取腾讯招聘网站里有价值的数据,利用Scapy框架爬取腾讯招聘官方网站主页上刊登的招聘信息。例如,其中网页链接、职位名称、职位职责、职位职责、职位利用现有技术在项目中免除注册,实现了多个目标,如要求、地点和发布时间等。同时对爬取得的数据进行初步筛选,除去多余的信息,除了可以节省当地空间外,数据科学家对数据进行两次清洗、精制,从而得到更有价值的信息。本项目对爬虫类的作用机构和设计模式进行了优化。同时采用了适当的设计模式,可以及时将内存数据导入数据库,大幅减少了内存资源的占用。
1.3 研究的方法与技术路线
1.3.1 研究方法
如今很多爬虫都是运用后台脚本类语言来进行编写,毫无疑问地,按使用次数来衡量,比较多的便是运用Python语言。Python发展了许多优秀的库和框架。本项目将采用Python中的scrapy框架作为爬虫实现语言对爬虫进行编写。
爬虫的工作流程通常是非常复杂的,它需要运用网页数据分析算法去删除一些毫无作用的链接,将需要用到的链接保存并且放入url队列中等待提取,之后根据编写的搜索策略从队列中选择进一步要获取的链接,重复这个过程直到程序停止。还有,系统往往会保存爬虫爬取到的所有网页,然后进行网页分析、过滤数据。如果一个网站不愿意网站数据流出,就会根据爬虫的特征进行识别,拒绝爬虫的访问[4]。一个完整的网络爬虫会包括四个模块:网络请求模块、爬取流程控制模块、内容分析提取模块、反爬虫模块。
1.3.2 研究手段
1.研究的主要任务
(1)使用python的scrapy框架来设计爬虫系统。
(2)网络爬虫需要对有用的数据进行提取,再之后筛选出职位名称等需要的数据。
(3)最终完成的网络爬虫一开始要网页地址进行分析之后再得到有用的数据。
(4)最后设计完成的网络爬虫要提取需要的数据。
2.研究各阶段要求:
(1)总体阶段要根据所需的要求来设计出方案。
(2)具体阶段要对有疑惑的问题进行解答并设计出详细方案,然后选择最佳的设计方案。
(3)编码阶段要选取适合的开发工具以及适合的技术标准。
(4)测试阶段要进行预测系统的运行结果,之后通过编译来测试是否达到需求。
3.设计开发
学习各种网络爬虫相关的文献资料,模拟网络上面关于爬虫开发的开源项目,在环境为windows操作系统下进行开发和测试。
第2章 基于python的网络爬虫
2.1 python语言简介
作为开源编程语言,Python可以实现很多功能,其语法相对简单易懂,有很多优点,它广泛使用于各种通用操作系统。此外,由于具有直接面对编程对象的特性,因此可以简化编程过程,并且可以大大提高编程效率。最重要的是,Pytohon语言有很多优点的网络协议库。这可以为独立识别、分层存储、程序员创造各种类型的编程逻辑[5]。
2.2 网络爬虫
2.2.1 网络爬虫的定义
网络爬虫是一个可以根据某些设定的逻辑,自动从网络上进行数据抓取。与传统的浏览器信息搜索方式相比,网络爬虫通过搜索网址及时或定期地搜索用户需求的内容并将搜索结果发送给用户的过程更准确、信息量更大、更符合用户的在线需求[6]。
对于python而言,它是被广泛应用于爬虫系统设计的语言之一,这不仅是因为Python在库的设计过程中承载了爬虫系统设计的必要基础,而且更重要的是在Python语言里开发了的一个名为Scrapy的框架被广泛应用于爬虫系统中,该框架被广泛应用于当前的计算机操作系统中,它的主要优点是能够有效解决抓取网页因被多次编写而产生大量 HTML 源代码从而造成信息堆积的问题,运用这一框架,只需要在框架中设置爬虫模块即可以爬取该网页的数据[7]。
根据系统的结构功能,网络爬虫可以分为四种类型:
(1)通用型网络爬虫
通用型网络爬虫主要用于搜索引擎,之所以对爬取的速度和存储空间要求比较高是因为它爬取的范围广,数量多。
(2)聚焦型网络爬虫
聚焦型网络爬虫是选择性地爬取一开始便定义好的需求的数据,它不仅节省了网络资源,也满足特定人员的特定需求。
(3)增量型网络爬虫
增量型网络爬虫只会产生新的爬取页面或数据页面被更改时来进行数据抓取,它有效降低数据量下载,减少了时间和空间的浪费。
(4)深度网络爬虫
深度网络爬虫需要先经过注册用户登录,或者是提交相应的表单之后才可以开始不断地爬取网页的数据[8]。
2.2.2 网络爬虫的基本流程
网络爬虫一般由四个流程进行:
a). 发送请求
通过http库将请求发送到目标网站,即发送给目标站点一个Request,这个Request可以包含headers等信息,然后等待服务器响应。
b). 获取响应内容
请求发送结束之后,等待服务器正常响应,响应结束会返回一个响应内容response,这个response可以是结构化数据,如html、json数据包等,也可以是非结构化数据,如图片或视频等。
c). 解析内容
一旦接受到响应内容时,便可以提取里面的数据。当解析的是html数据,则可以使用正则表达式或第三方解析库如Beautifulsoup,pyquery等来提取数据;若是解析json数据,则可以导入json模块,将数据转化为python类型数据然后进行提取;若是非结构化数据的,直接进行提取后保存。
d). 保存数据
从response中解析到数据一般可写入数据库或者写入文本保存。
2.3 scrapy框架
2.3.1 scrapy框架的基本原理
在开发python的网络爬虫中可以优先选择scrapy。它主要包括引擎(Engine),调度器(Scheduler),下载器(Downloader),爬虫(Spider),项目管道(Pipeline),下载器中间件(Downloader-Middlewares),爬虫中间件(Spider-Middlewares)等七个组件。如图2-1所示。

图2-1. Scrapy框架架构图
(1)引擎(Engine)
引擎负责和进行管理控制整个系统框架所有一切组件之间的数据流信息,而且在某些动作发生时触发相应的事务,整个scrapy框架的核心控制组件便是引擎。
(2)调度器(Scheduler)
通过调度器,scrapy框架可以控制哪个网页优先爬取,即控制网页的爬取优先级。它也含有去重功能,能够去掉重复的网页。当接受引擎传过来的请求后便按照排序传递给下载器。
(3)下载器(Downloader)
下载器采用异步方式与远程服务器建立连接,下载网页数据并将数据返回给引擎。它也可以接收调度器传过来的请求,再根据要求从互联网中下载网页内容,并将数据传送给爬虫。
(4)爬虫(Spider)
爬虫是Scrapy框架核心之一,网页解析是它的主要工作,然后从目标网页的数据里来进行提取。一个爬虫项目通常可以拥有多个爬虫,而且每个爬虫r可以解析多个网站,爬取多个网站的数据。它由编码人员负责编写来解析请求网页后返回数据的代码,从数据中提取出Item和新的网页地址,并把Item传给Item pipeline组件。
(5)项目管道(Pipeline)
项目管道负责处理爬虫提取的数据,常见的处理如验证有效性、清理不需要的信息及数据存储等。通常需要多个数据管道,每个管道进行一种数据处理。
(6)下载器中间件(Downloader-Middlewares)
下载中间件位于引擎和下载器之间,是处理引擎和下载器之间的请求和响应的重要部分之一。
(7)爬虫中间件(Spider-Middlewares)
爬虫中间件位于引擎和爬虫之间,是处理引擎和爬虫之间的请求和响应的重要部分之一[9]。
2.3.2 scrapy框架的基本流程
如图2-2所示,是scrapy框架的流程图,主要包含8个流程:

图2-2. Scrapy框架流程图
(1)引擎向爬虫文件索要第一个要爬取的网页地址。
(2)引擎将网页地址信息交给调度器,调度器将网页地址入队列。
(3)url地址出队列,这时候的url地址为要爬取的内容的网页地址,由调度器传递给引擎。
(4)引擎传递给下载器地址,下载器开始爬取。
(5)获取到响应之后,下载器将响应的内容传递给引擎。
(6)引擎将响应传递给爬虫,爬虫开始解析数据。
(7)爬虫提取数据之后,将所需的数据传递给引擎。若此时还有必须继续跟进的网页地址(即二级页面等),则重复第一个步骤直至结束。
(8)引擎将所需信息数据传递给管道,由管道进行保存等操作。
2.4 分布式网络爬虫原理
Scrapy-redis是scrapy实现分布式功能的主要部分。
依靠主从关系,在这里将核心服务器称为主服务器,将用于运行爬虫项目的称为从服务器。爬取网页数据运用scrapy方式,第一步给爬虫文件一个或一些初始地址start_urls,然后爬虫文件开始访问里面的网络地址,再根据编码人员设计的表达式来提取里面的数据,也可以是解析和抓取其它二级网页信息数据等。
运用redis数据库,在这里redis数据库只需要存储url,不需要存储爬取到的数据,redis数据库会特殊设定不一样的列表字段,来标记这些不同的网站地址,这样可以达到爬取不重复网络地址的效果。
在主服务器上运用redis数据库,不管有多少个从服务器,从服务器只能获取主服务器里面redis数据库存储的网络地址。
由于scrapy-redis自身的队列拥有特殊的机制,从服务器得到的网络地址是不会相互冲突的。在每个从服务器结束数据抓取之后,会把爬取到的数据汇合并传输到到主服务器上,这个时候爬取到的数据不再是存进redis数据库里,而是存进mysql等储存数据的数据库。
这种措施的另一个优点便是程序的移植性很强,只需要修改路径问题,把从服务器上的爬虫项目复制粘贴到到其他从服务器上,便可以运行相同的爬虫程序[10]。
第3章 网络爬虫模型的设计和实现
3.1 网络爬虫的爬取对象
本文实现的网络爬虫是爬取腾讯招聘网站招聘信息,爬取招聘网站的的一级页面,里面包含职位名称、职位类别以及工作地点等,之后再通过分析将每个职位的二级页面爬取下来,之后再爬取二级页面数据,包含职位责任和职位要求。
3.2 网络爬虫系统功能架构
分布式爬虫抓取系统,如图3-1所示,主要包含以下功能:

图3-1 分布式爬虫抓取系统架构图
(1)爬虫:爬取策略的设计、提取数据设计、增量爬取、请求去重
(2)中间件:爬虫防屏蔽中间件
(3)数据存储:抓取字段设计、数据存储
本文将腾讯招聘网站为主题的网络爬虫划为爬虫模块、中间件模块、数据存储模块3个部分。其中爬虫模块用来分析提取url地址,实施招聘主题信息网页的抓取,在满足爬取规则的范围内抓取符合招聘主题信息的网页数据;中间件模块主要负责添加user-agent请求头信息模拟浏览器登录,实现爬虫防屏蔽功能;数据存储模块主要将抓取的网页数据存入到数据库中。
3.3 网络爬虫流程设计
由scrapy的结构分析可知,网络爬虫从start_url开始,根据设计爬虫并定义的url地址,得到积极响应后,若是html数据,则可以运用正则表达式或者Xpath去提取数据;若是json类型的,则导入json模块加以提取。若是从一级页面中获取到更多链接,则将这些链接添加进待下载队列当中,对它们进行去重和排序操作,然后等待调度器的调度。
在整个系统中,链接可以分为两类:一类是目录页链接,里面包含着岗位名称和岗位类型,以及其它链接,此时我们需要提及岗位名称、岗位类型和下一页的链接;一类是内容详情页链接,里面包含着岗位职责和岗位要求的信息。网络需要从每一个目录页链接当中来提取所需要的数据之后,加入到待下载队列并准备进一步爬取。爬取流程如图3-2所示。

图3-2. 爬虫流程设计图
由此流程图便知,首先要先获取一个start_url地址,才可以进行爬取任务。所以需要开始进行网页分析。
3.4 腾讯招聘网页分析
3.4.1 判断网页的静/动态加载
首先进入腾讯招聘网站(https://careers.tencent.com/),我们可以看到如图3-3所示的腾讯招聘网站主页,点击“查看工作岗位”即可得到此招聘网站的大量信息。

图3-3. 腾讯招聘网站主页
单击点开之后便是招聘网站的分页,如图3-4所示,这时候可以依据不同的地区选择想要了解的职位信息。以中国的四个一线城市(北京、上海、广州、深圳)为例,主要分析这四大地区的网页地址。

图3-4. 腾讯招聘网站分页
判断网页静/动态加载,主要依据是查看网页源代码中有没有具体数据,有数据则为静态加载,无数据则为动态加载。静态加载的数据主要是html数据,提取数据可以使用正则表达式或xpath方法。动态加载则需要利用控制台并根据页面的动作来抓取网络数据包,即json数据包的url地址。
以腾讯招聘网站为例,由于网页源代码中没有具体数据,则为Ajax动态加载,根据控制台和页面刷新可以在XHR上面得到三个异步加载的数据包,在Query文件的Preview中发现了需要爬取的数据,如图3-5所示。

图3-5.招聘网站网页信息
3.4.2 分析一级网页获取相应数据
在XHR得到json数据包,此时需要在Headers上面查找有用的信息。如图3-6所示,需要提取到的url地址便是图中RequestURL。

图3-6. 一级页面Headers信息
RequestURL(一级页面):
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1584696974713&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
然而此url地址比较复杂,所以需要分析每个参数。在Headers底端的Query String Parameters(查询参数)栏便有着这个网页地址的所有参数。在获取到北京、上海、广州、深圳以及不分地区的招聘网页地址后,分别得到它们的参数区别,如图3-7所示。

图3-7. 北京、上海、广州、深圳以及不分地区的招聘网页地址参数
在这些参数中,可分析得到,如表3-1所示。
表3-1 一级页面各参数所代表的含义
timestamp: 时间戳
cityId: ‘2’为北京,‘3’为上海,‘5’为广州,‘1’为深圳, ‘ ’为不分地区
pageIndex: 页数
pageSize: 10个(招聘职位)
由于删去timestamp这个参数后依然可以得到json数据包,所以重要的参数分别为cityId、pageIndex、pageSize。可得到一级页面one_url:
https://careers.tencent.com/tencentcareer/api/post/Query?&countryId=&cityId={}&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn
最后再运用format方法即可将字符串分别带入,得到一个完整的url。代入参数后打开此链接,所得到的信息便是我们需要的json数据包,里面包含所有招聘职业的职业名称、职业类别和工作地点等大量数据,如图3-8所示。

图3-8. 一级页面Json数据包
在这个json数据包中,我们可以分析得到想要的数据,如表3-2所示。
表3-2 一级页面各参数所代表的含义
RecruitPostName: 职位名称
CategoryName: 职位类别
LocationName: 工作地点
根据图3-8展示的json数据包,我们可以知道这些数据是需要根据字典的方式来进行提取,首先由一个大字典含有的‘Data’键来对应值,这个值为所需要提取的第二个字典,根据第二个字典的键‘Posts’来获取数据。‘Posts’对应的值为一个列表,在列表中提取字典,所以我们可以根据以上信息,运用for循环来编写提取数据的代码:
for job in html[‘Data’][‘Posts’]:
#职位名称 = job[‘RecruitPostName’]
#职位列别 = job[‘CategoryName’]
#工作地点 = job[‘LocationName’]
在这个数据包中没有我们想要的职位职责和职位要求,所以就需要分析二级网网页来获取。
3.4.3 分析二级网页获取相应数据
二级页面,是在一级页面中点开一个招聘职位得到的网页,同理可以得到二级页面的相应数据,如图3-9所示。

图3-9. 二级页面Headers信息
RequestURL(二级页面):
https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1584717244516&postId=1237234611482791936&language=zh-cn
分析三个不同职位的网页链接参数,如图3-10所示,将参数进行对比,可以得到postId是不一致的,可以发现不同职位间都有着不同的postId来于此对应,而且这个postId在一级页面的json数据包中也有包含,所以可以根据一级页面得到的postId来获取二级页面的数据。

图3-10. 网页参数对比
因此得到二级页面地址为:
https://careers.tencent.com/tencentcareer/api/post/ByPostId?&postId={}&language=zh-cn
利用format方法代入一个职位的postId,即可得到相应的json数据包,如图3-11所示。

图3-11. 二级页面json数据包
在这个json数据包中,我们可以分析得到想要的数据如表3-3所示。
表3-3 二级页面各参数所代表的含义
Responsibility: 职位责任
Requirement: 职位要求
在这些json数据包中,利用提取字典的方式便可以从中爬取到想要的数据。分析完一级页面和二级页面,即刻开始设计爬虫的具体实现。
3.5 网络爬虫的具体实现
3.5.1 创建spider项目文件
第一步需要建立一个Scrapy项目文件,即在终端中运行更改目录的命令,把当前位置切换到将要用于保存爬虫代码的文件夹中,运行命令“scrapy start project+自定义的爬虫目录名称”,文件夹中会自动生成爬虫的项目框架。第二步切换到该爬虫目录,可以看到该目录文件夹里的内容:项目配置文件、python模块、item文件、pipelines管道文件、setting文件和spider目录文件夹等几个部分。最后在终端输入命令“scrapy genspider+爬虫文件名+爬虫对象域名”,即可开始进行爬虫项目设计。
3.5.2 定义Item容器
Item负责定义以及储存获取的网络数据,而且定义Item容器是为了消除由于拼写错误带来的麻烦,而且它也增加了额外的保护机制。依据实际情况在item.py中对提取到的数据编写相关的字段,比如职业名称、职业类别、工作地点、职业责任和职业要求。
Item.py关键代码如下:
import scrapy
class TcrecruitItem(scrapy.Item):
# 名称
tc_name = scrapy.Field()
# 类别
tc_type = scrapy.Field()
#工作地点
tc_location = scrapy.Field()
# 职责
tc_duty = scrapy.Field()
# 要求
tc_require = scrapy.Field()
pass
3.5.3 编写爬虫程序
爬虫程序spider.py用于爬取一级页面及其包含的数据、二级页面及其包含的数据,它的实现内容包括:初始下载的链接地址即start_urls、后续跟进网页的URL链接即two_url、采用的算法、提取数据生成item。
在这里,以中国四大一线城市(北京、上海、广州、深圳)以及全国范围为例,根据腾讯招聘网站地址可以得到这五个地区的参数,再用format()方法将参数代入进网站地址里便可以得到地区对应的json数据包,相关代码如下:
class TcrecruitSpider(scrapy.Spider):
name = ‘tcrecruit’
allowed_domains = [‘careers.tencent.com’]
a = ‘’
city_url = ‘https://careers.tencent.com/tencentcareer/api/post/’
‘Query?timestamp=1584608233122&countryId=&cityId=’
#选择要爬取的地区
choice = input(‘1. 深圳 2. 北京 3. 上海 4. 广州 5. 全部 \n请选择:’)
if choice == ‘1’:
a = 1
elif choice == ‘2’:
a = 2
elif choice == ‘3’:
a = 3
elif choice == ‘4’:
a = 5
else:
a = ‘’
#将网络地址合并
one_url =
city_url+str(a)+‘&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn’
two_url =
‘https://careers.tencent.com/tencentcareer/api/post/ByPostId?&postId={}&language=zh-cn’
start_urls = [one_url.format(1)]
得到json数据包后,要编写翻页的函数以便能获取大量的职位信息,这里运用for循环进行翻页操作,相关代码如下:
def parse(self, response):
for page_index in range(1,21):
url = self.one_url.format(page_index)
yield scrapy.Request(
url = url,
callback = self.parse_one
)
分析招聘主题信息爬虫要爬取的数据信息包括职位名称、职位类别、工作地点、职位责任和职位要求;观察分析腾讯招聘页面的json数据包,再根据python自带的json.loads()方法将json类型的数据变成python的数据类型,然后用字典提取数据方式将所需要的数据提取出来。在一级页面能够获取到二级页面的必备参数post Id,然后将postId拼接到two_url便可以进入二级页面的json数据包去提取数据。重要代码如下:
def parse_one(self, response):
html = json.loads(response.text)
for job in html[‘Data’][‘Posts’]:
item = TcrecruitItem()
#职位名称、职位类别、工作地点
item[‘tc_name’] = job[‘RecruitPostName’]
item[‘tc_type’] = job[‘CategoryName’]
item[‘tc_location’] = job[‘LocationName’]
#postID: 拼接二级页面的地址
post_id = job[‘PostId’]
two_url = self.two_url.format(post_id)
#交给调度器
yield scrapy.Request(
url = two_url,
meta = {‘item’:item},
callback = self.parse_two
)
def parse_two(self,response):
item = response.meta[‘item’]
html = json.loads(response.text)
#职位责任
item[‘tc_duty’] = html[‘Data’][‘Responsibility’]
#职位要求
item[‘tc_require’] = html[‘Data’][‘Requirement’]
yield item
3.5.4 编写pipelines.py
若要在函数里面加上可以在终端输出数据的功能,只需要添加相关代码:
class TcrecruitPipeline(object):
def process_item(self, item, spider):
print(dict(item))
return item
接着便是保存数据,首先要导入pymysql库,然后依次编写自己数据库信息,例如用户名、密码、表名等;然后再将爬取的数据插入相对于的位置,需要定义一个列表,然后用列表来进行传递参数;接着提交到数据库去自动执行代码;最后关闭数据库。相关代码如下:
import pymysql
class TcrecruitMysqlPipeline(object):
def open_spider(self, spider):
#打开数据库并输入端口号账号密码等信息
self.db = pymysql.connect(
‘127.0.0.1’, ‘root’, ‘moon631166427’,
‘tencentdb’, charset=‘utf8’
)
self.cursor = self.db.cursor()
def process_item(self, item, spider):
ins = ‘insert into tcrecruitdata values(%s, %s, %s, %s, %s)’
job_list = [
item[‘tc_name’], item[‘tc_type’],
item[‘tc_location’], item[‘tc_duty’], item[‘tc_require’]
]
self.cursor.execute(ins, job_list)
self.db.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.db.close()
当然,保存数据的前提需要在数据库创建能与存储爬虫数据相对应的表格。如图3-12所示。

图3-12. 创建数据库
3.5.5 修改setting.py
离编写完scrapy网络爬虫程序只差最后一步,便是修改setting.py的参数和添加scrapy-redis。
(1)修改最大并发量,最好将并发量修改小一点,这个参数越小,爬虫程序便越安全,但爬取时间会变长一些。
CONCURRENT_REQUESTS = 10
(2)修改下载延迟参数,这里将延迟参数调至0.3s:
DOWNLOAD_DELAY = 0.3
(3)修改REQUEST_HEADERS请求头,这里是由下载中间件完成,添加user-agent模拟浏览器浏览爬取对象的网络地址:
DEFAULT_REQUEST_HEADERS = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Language’: ‘en’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0’
}
(4)修改item_pipeline项目管道,添加数据库(若想将数据存储进redis,也可以在这里添加redis相对应的管道):
ITEM_PIPELINES = {
‘Tcrecruit.pipelines.TcrecruitPipeline’: 300,
‘Tcrecruit.pipelines.TcrecruitMysqlPipeline’: 250,
#‘scrapy_redis.pipelines.RedisPipeline’: 250,
}
(5)添加scrapy-redis:
使用scrapy_redis的调度器
SCHEDULER = “scrapy_redis.scheduler.Scheduler”
使用scrapy_redis自带的去重机制
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
爬取结束后清除请求指纹(也可以不清除):
SCHEDULER_PERSIST = True
定义redis主机的地址和端口号(这里REDIS_HOST为空时,处理器会自己寻找本机电脑的地址):
REDIS_HOST = ’ ’
REDIS_PORT = 6379
第4章
第4章 系统功能测试与实现
4.1 爬虫运行测试
在CPU为CORE(TM)i5-3317,内存为8G,操作系统为WIN10-64位的戴尔笔记本,pycharm版本为2019.2,python版本为3.7.3的环境下,通过在pycharm建立一个run.py,导入cmdline库,编写命令“cmdline.execute(‘scrapy crawl tcrecruit‘.split())”,运行run.py来启动爬虫进行腾讯招聘信息爬取测试
4.2 选择要爬取的地区
如图4-1所示,爬虫开始运行,总共可以爬取5个地区。以深圳地区为例子,输入深圳地区的相应数字,即可开始爬取腾讯深圳地区招聘职业的数据。

图4-1.选择深圳地区
4.3 爬虫爬取过程
如图4-2所示,为爬虫爬取腾讯深圳地区招聘职业的信息,从图中可以看到‘tc_name’正确对应了招聘职位的职位名称;‘tc_type’正确对应了职位类别;‘tc_location’正确对应了工作地点,即为深圳地区;‘tc_duty’正确对应了职位责任;‘tc_require’正确对应了职位要求。

图4-2. 爬虫爬取过程
4.4 数据库存储数据
如图4-3所示,进入数据库并查询数据表里面的数据;

图4-3. 查询数据表
如图4-4,为数据表里面呈现出来的内容,至此可以说明数据库成功存储来自爬虫项目爬取到的数据。

图4-4. 数据表格内容
4.5 爬虫爬取结束
如图4-5所示,为爬虫成功运行并结束之后显示的内容,由于设定爬取20页,每页20个职位,所以总计成功爬取到的职位个数为200个。

图4-5. 爬虫运行结束
如图4-6所示,打开RedisDesktopManager,也可以查到成功爬取的职位个数为200个,并且这200个职位在scrapy-redis的作用下是不会重复的。
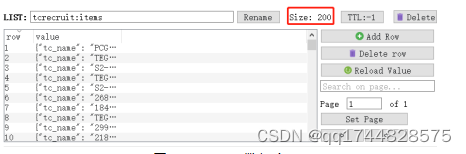
图4-6. Redis数据库
从以上爬虫项目运行的结果可以看出,爬虫爬取20页共计200条,与网页实际记录条数相符,运行稳定。爬虫获取的数据均为近期发布的、想要搜索的“深圳地区”范围内的腾讯职业招聘信息,搜集的职业招聘信息基本符合所要查询职位的相关信息,可以满足就业查询的基本需求。在今后的实际运行过程中可以添加其他地区的对应参数,运行后便可以选择其它乃至全国的相关招聘信息,以服务更多不同地区的人。因此,腾讯职业招聘的爬虫技术可以作为服务于选择就业人士的技术手段,帮助其以快速获取各类招聘信息。
结束语
在这个网络技术发达,数据充沛的时代,如何获取网络数据是一份很重要的工作。相关研究人员提出:网络上百分之六十的流量均为网络爬虫爬取的[11]。爬虫作为获取数据的重要手段之一,在各种网站数据中得到了广泛的应用。本文主要从网络爬虫、Python语言与Scrapy框架几个方面进行阐述,简单介绍了腾讯招聘信息主题网络爬虫的工作流程、开发与实现。
相较于一般的爬虫项目,招聘网络爬虫有明显的精确性特征,可以精准地搜索与主题相关的网页信息,增强了网络搜索的实效性。但本文的不足之处是只列举了一些简单的爬虫技术和反爬虫方法,光是这些技术还不足以提升到爬取更多复杂的数据。在今后的研究工作中,会继续改进本项目的设计,完善有关功能,提升爬取数据的效率,更好地为学生就业工作提供更多的帮助。
参考文献
[1] 李代祎,谢丽艳,钱慎一,吴怀广.基于Scrapy的分布式爬虫系统的设计与实现[J].湖北民族学院学报(自然科学版).2017(03)
[2]熊晟.知识库质量控制平台的设计与实现[D].北京:北京交通大学,2016.
[3]张凤龙.网络爬虫的设计与实现[D].天津:天津大学,2011.
[4]张牛.同步竞拍技术在代拍网站中的研究与应用[D].上海:东华大学,2014.
[5]Release notes — Scrapy documentation. doc.scrapy.org. [2018-08-13]
[6]Wang Jing, Guo Yuchun, Scrapy-Based Crawling and User-Behavior Characteristics Analysis on Taobao, 2012
[7]Hansong Wang, Preliminary study on design and development of a journal focused crawler system using EBD methodology: Part I — Design task and environment analysis, 2014
[8]刘石磊.对反爬虫网站的应对策略[J].电脑知识与技术,2017,13(15):19-21+23.
[9]李光敏,李平,汪聪.基于Scrapy的分布式数据采集与分析—以知乎话题为例[J].湖北师范大学学报(自然科学版),2019,39(03):1-7.
[10] 翁绍菲,廖翔宇,祝光仪,范雅静,甘宇健.基于Scrapy的分布式爬虫采集软件的实现[J].电脑知识与技术,2019,15(20):73-75.
[11]韩贝,马明栋,王得玉.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019(2):139-142.
致 谢
四年的学习生活即将结束,四年的日日夜夜,老师的教诲和指导,师兄师姐和同学的帮助,家长的支持和鼓励让我迈上一步。在本文的设计过程中,谢谢学校给了我学习的机会,感谢老师从选题指导、论文框架到细节修改,给予了详细的指导,提出了许多有价值的意见和建议,老师以其严谨求实的学习态度,高度的敬业精神、敬业、刻苦的工作作风和勇于创新进取的精神对我有着重要的影响,她渊博的学识、开阔的视野和敏锐的思维使我深受鼓舞。