Elasticsearch底层原理分析——新建、索引文档
es版本
8.1.0
重要概念回顾
Elasticsearch Node的角色
与下文流程相关的角色介绍:
| Node Roles | 配置 | 主要功能说明 |
|---|---|---|
| master | node.roles: [ master ] | 有资格参与选举成为master节点,从而进行集群范围的管理工作,如创建或删除索引、跟踪哪些节点是集群的一部分以及决定将哪些分片分配给哪些节点等 |
| data | node.roles: [ data ] | 数据节点保存已索引的文档的分片。处理数据相关操作,例如 CRUD、搜索和聚合。 |
| node.roles: [ ] | 节点不填任何角色,则是协调节点,换言之每个节点,也都有协调节点功能。具备路由请求、对搜索结果合并和分发批量索引等功能。本质上,协调节点的行为就像智能负载均衡器 |
详见:https://www.elastic.co/guide/en/elasticsearch/reference/8.9/modules-node.html
分片
- 一个分片是一个 Lucene 的实例,是一个完整的搜索引擎
- 主分片的数量决定了索引最多能存储多少数据,多分片机制,带来存储量级提升
- 主分片数不可更改,和数据路由算法有关
- 副本分片可以防止硬件故障导致的数据丢失,同时可以提供读请求,增大能处理的搜索吞吐量
- 对文档的新建、索引和删除请求都是写操作,必须在主分片上面完成,之后才能被复制到相关的副本分片
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_add-an-index.html
新建、索引和删除文档
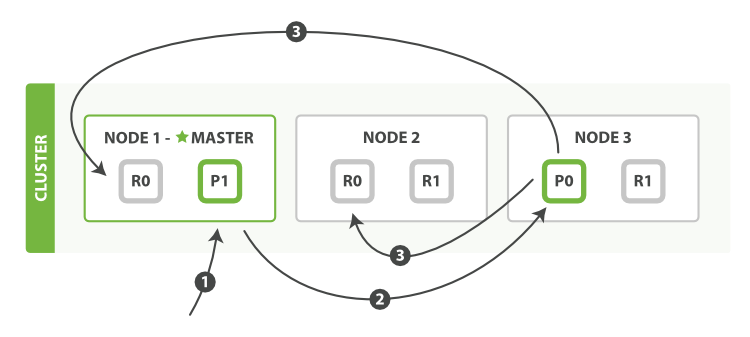
以官网(https://www.elastic.co/guide/cn/elasticsearch/guide/current/distrib-write.html)例子分析,es集群有3个节点,其中有个索引有两分片(P0、P1),两副本(P0、R0、R0,P1、R1、R1),如创建索引时:
PUT /blogs
{
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 2
}
}
再对一些前提知识回顾一下:
- 每个节点都具备协调节点功能,也即路由请求、对搜索结果合并和分发批量索引等功能
- 对文档的新建、索引和删除请求等写操作,必须在主分片上面完成,之后才能被复制到相关的副本分片
这个例子中的两个假设:
- 请求集群时,es采用的是随机轮询方法进行负载均衡,每个节点都有可能被请求到。在这个例子中,假设先请求到node1
- 节点使用文档的 _id 确定文档属于分片 0
所以(直接引用官网步骤):
- 客户端向 Node 1 发送新建、索引或者删除请求。
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
源码理解
如何确定文档属于哪个分片,请求转发哪个节点
获取分片ID是从TransportBulkAction类中开始调用开始
int shardId = docWriteRequest.route(indexRouting);
具体实现在IndexRouting类中。简述步骤就是:
- 对routing值进行Murmur3Hash运算(如果没有设置routing,值默认是doc id值)
- 对hash后的值进行取模运算,routingNumShards默认1024,routingFactor默认512
protected int shardId(String id, @Nullable String routing) {
return hashToShardId(effectiveRoutingToHash(routing == null ? id : routing));
}
protected final int hashToShardId(int hash) {
return Math.floorMod(hash, routingNumShards) / routingFactor;
}
private static int effectiveRoutingToHash(String effectiveRouting) {
return Murmur3HashFunction.hash(effectiveRouting);
}
为何需要路由,以及路由带来什么问题
- 为何需要路由
总的来说,就是多分片设计,可以承载更大量级数据,而分片预分配设计,可以简单的获取文档位置,能减少数据分裂风险,以及对数据重新索引友好
https://www.elastic.co/guide/cn/elasticsearch/guide/current/overallocation.html - 带来的问题:
创建索引的时候就需要确定好主分片的数量,并且永远不会改变这个数量。因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/routing-value.html
如何根据分片ID确定节点
代码在TransportReplicationAction#doRun方法中,简单概括就是state中存有集群信息,通过传入分片ID,先获取主分片信息,再通过主分片节点ID,获取对应节点信息。
final ShardRouting primary = state.getRoutingTable().shardRoutingTable(request.shardId()).primaryShard();
if (primary == null || primary.active() == false) {
logger.trace(
"primary shard [{}] is not yet active, scheduling a retry: action [{}], request [{}], "
+ "cluster state version [{}]",
request.shardId(),
actionName,
request,
state.version()
);
retryBecauseUnavailable(request.shardId(), "primary shard is not active");
return;
}
if (state.nodes().nodeExists(primary.currentNodeId()) == false) {
logger.trace(
"primary shard [{}] is assigned to an unknown node [{}], scheduling a retry: action [{}], request [{}], "
+ "cluster state version [{}]",
request.shardId(),
primary.currentNodeId(),
actionName,
request,
state.version()
);
retryBecauseUnavailable(request.shardId(), "primary shard isn't assigned to a known node.");
return;
}
final DiscoveryNode node = state.nodes().get(primary.currentNodeId());
if (primary.currentNodeId().equals(state.nodes().getLocalNodeId())) {
performLocalAction(state, primary, node, indexMetadata);
} else {
performRemoteAction(state, primary, node);
}
主分片执行流程
1. 写一致性
默认写成功一个主分片即可,源码在ActiveShardCount#enoughShardsActive方法中
https://www.elastic.co/guide/en/elasticsearch/client/curator/current/option_wait_for_active_shards.html
public boolean enoughShardsActive(final IndexShardRoutingTable shardRoutingTable) {
final int activeShardCount = shardRoutingTable.activeShards().size();
if (this == ActiveShardCount.ALL) {
// adding 1 for the primary in addition to the total number of replicas,
// which gives us the total number of shard copies
return activeShardCount == shardRoutingTable.replicaShards().size() + 1;
} else if (this == ActiveShardCount.DEFAULT) {
return activeShardCount >= 1;
} else {
return activeShardCount >= value;
}
}
2. 具体写流程
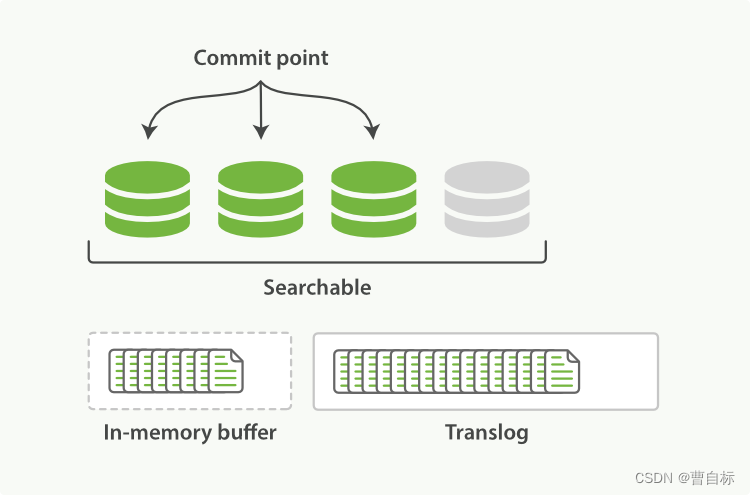
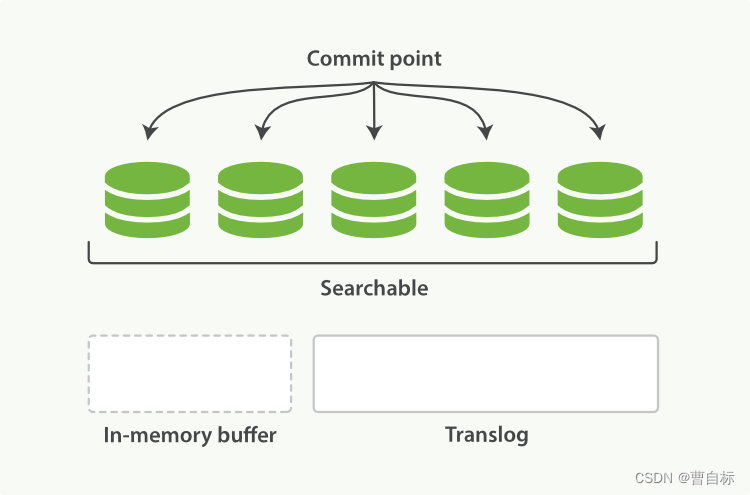
参考官网(https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html)理解。图片所示是一个lucene索引,lucene索引下面有三个段(segment),图中Searchable表示从内存(In-memory buffer,也叫Indexing Buffer)刷新到磁盘,写入物理文件,不可更改,其中fsync操作将新文档刷新到磁盘的操作,性能代价是很大的。所以会先将文档写入文件系统缓存中,也即图中In-memory buffer中,对应的是 Indexing Buffer(https://www.elastic.co/guide/en/elasticsearch/reference/8.10/indexing-buffer.html)。
所以流程是:
- 将文档写入Indexing Buffer中
- 将操作追加写入 translog 中,以便确保即便在刷盘时异常,也能从失败中恢复数据
- 将内存中的数据刷新持久化到磁盘中(默认情况下每个分片会每秒自动刷新一次)
- 在刷新(flush)之后,段被全量提交,并且事务日志被清空
相关源码
主要在InternalEngine类中:
- index方法包含写入In-memory buffer对应生成IndexResult(?)和写translog;
- 将内存中的数据刷新持久化到磁盘中在refresh方法;
- 段被全量提交,和事务日志被清空在flush方法。
index方法
public IndexResult index(Index index) throws IOException {
// 确保传入的文档的唯一标识是 IdFieldMapper
assert Objects.equals(index.uid().field(), IdFieldMapper.NAME) : index.uid().field();
// 检查 index 的来源是否不是恢复操作
final boolean doThrottle = index.origin().isRecovery() == false;
// 获取读锁
try (ReleasableLock releasableLock = readLock.acquire()) {
// 确保引擎处于打开状态
ensureOpen();
// 断言传入的 index 的序列号符合预期
assert assertIncomingSequenceNumber(index.origin(), index.seqNo());
int reservedDocs = 0;
try (
Releasable ignored = versionMap.acquireLock(index.uid().bytes());
Releasable indexThrottle = doThrottle ? throttle.acquireThrottle() : () -> {}
) {
lastWriteNanos = index.startTime();
// 代码中有一段注释,描述了关于追加(append-only)优化的注意事项。根据注释所述,如果引擎接收到一个带有自动生成的ID的文档,
// 可以优化处理并直接使用 addDocument 而不是 updateDocument,从而跳过版本和索引查找。此外,还使用文档的时间戳来检测是否可能已经添加过该文档。
// 获取索引策略
final IndexingStrategy plan = indexingStrategyForOperation(index);
reservedDocs = plan.reservedDocs;
final IndexResult indexResult;
if (plan.earlyResultOnPreFlightError.isPresent()) {
assert index.origin() == Operation.Origin.PRIMARY : index.origin();
indexResult = plan.earlyResultOnPreFlightError.get();
assert indexResult.getResultType() == Result.Type.FAILURE : indexResult.getResultType();
} else {
// generate or register sequence number
// 生成或注册文档的序列号。对于主分片的操作,会生成新的序列号。
if (index.origin() == Operation.Origin.PRIMARY) {
index = new Index(
index.uid(),
index.parsedDoc(),
// 生成新的序列号
generateSeqNoForOperationOnPrimary(index),
index.primaryTerm(),
index.version(),
index.versionType(),
index.origin(),
index.startTime(),
index.getAutoGeneratedIdTimestamp(),
index.isRetry(),
index.getIfSeqNo(),
index.getIfPrimaryTerm()
);
// 检查了当前操作是否应该追加到 Lucene 索引中
final boolean toAppend = plan.indexIntoLucene && plan.useLuceneUpdateDocument == false;
if (toAppend == false) {
// 更新主分片的最大序列号
advanceMaxSeqNoOfUpdatesOnPrimary(index.seqNo());
}
} else {
// 对于副本分片的操作,会标记已经见过的序列号,序列号已经被使用。
markSeqNoAsSeen(index.seqNo());
}
assert index.seqNo() >= 0 : "ops should have an assigned seq no.; origin: " + index.origin();
if (plan.indexIntoLucene || plan.addStaleOpToLucene) {
// 写到 Lucene 中
indexResult = indexIntoLucene(index, plan);
} else {
indexResult = new IndexResult(
plan.versionForIndexing,
index.primaryTerm(),
index.seqNo(),
plan.currentNotFoundOrDeleted
);
}
}
// 判断索引操作是否来自 Translog。如果是来自 Translog 的操作,就不再处理,因为这已经是一个已经被记录的操作
if (index.origin().isFromTranslog() == false) {
final Translog.Location location;
if (indexResult.getResultType() == Result.Type.SUCCESS) {
// 如果索引操作成功, 将该操作添加到 Translog 中,并获取 Translog 的位置
location = translog.add(new Translog.Index(index, indexResult));
} else if (indexResult.getSeqNo() != SequenceNumbers.UNASSIGNED_SEQ_NO) {
// if we have document failure, record it as a no-op in the translog and Lucene with the generated seq_no
// 如果索引操作失败,并且具有序列号, 则将失败的操作记录为一个 no-op 操作
final NoOp noOp = new NoOp(
indexResult.getSeqNo(),
index.primaryTerm(),
index.origin(),
index.startTime(),
indexResult.getFailure().toString()
);
location = innerNoOp(noOp).getTranslogLocation();
} else {
// 如果索引操作失败,并且没有序列号,将 location 设置为 null
location = null;
}
// 设置Translog 位置
indexResult.setTranslogLocation(location);
}
// 如果索引操作成功且需要写入 Lucene, 则获取 Translog 的位置信息,用于更新版本映射
if (plan.indexIntoLucene && indexResult.getResultType() == Result.Type.SUCCESS) {
final Translog.Location translogLocation = trackTranslogLocation.get() ? indexResult.getTranslogLocation() : null;
versionMap.maybePutIndexUnderLock(
index.uid().bytes(),
new IndexVersionValue(translogLocation, plan.versionForIndexing, index.seqNo(), index.primaryTerm())
);
}
// 本地 Checkpoint 的更新, 标记当前序列号已经被处理
localCheckpointTracker.markSeqNoAsProcessed(indexResult.getSeqNo());
if (indexResult.getTranslogLocation() == null) {
// the op is coming from the translog (and is hence persisted already) or it does not have a sequence number
// 如果 Translog 的位置信息为 null,说明该操作来自于 Translog,已经被持久化,或者该操作没有序列号。
// 在这种情况下,标记当前序列号已经被持久化
assert index.origin().isFromTranslog() || indexResult.getSeqNo() == SequenceNumbers.UNASSIGNED_SEQ_NO;
localCheckpointTracker.markSeqNoAsPersisted(indexResult.getSeqNo());
}
indexResult.setTook(System.nanoTime() - index.startTime());
// 将操作结果冻结,确保其不可变
indexResult.freeze();
return indexResult;
} finally {
releaseInFlightDocs(reservedDocs);
}
} catch (RuntimeException | IOException e) {
try {
if (e instanceof AlreadyClosedException == false && treatDocumentFailureAsTragicError(index)) {
failEngine("index id[" + index.id() + "] origin[" + index.origin() + "] seq#[" + index.seqNo() + "]", e);
} else {
maybeFailEngine("index id[" + index.id() + "] origin[" + index.origin() + "] seq#[" + index.seqNo() + "]", e);
}
} catch (Exception inner) {
e.addSuppressed(inner);
}
throw e;
}
}
自动sync条件translog条件:
相关配置:
- index.translog.sync_interval: 默认5s
- index.translog.durability:默认配置的是request,即每次写请求完成之后执行(e.g. index, delete, update, bulk)
- index.translog.flush_threshold_size:默认512mb
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.11/index-modules-translog.html
private void maybeSyncTranslog(final IndexShard indexShard) throws IOException {
if (indexShard.getTranslogDurability() == Translog.Durability.REQUEST
&& indexShard.getLastSyncedGlobalCheckpoint() < indexShard.getLastKnownGlobalCheckpoint()) {
indexShard.sync();
}
}
refresh源码:
final boolean refresh(String source, SearcherScope scope, boolean block) throws EngineException {
// both refresh types will result in an internal refresh but only the external will also
// pass the new reader reference to the external reader manager.
// 获取当前的本地检查点
final long localCheckpointBeforeRefresh = localCheckpointTracker.getProcessedCheckpoint();
boolean refreshed;
try {
// refresh does not need to hold readLock as ReferenceManager can handle correctly if the engine is closed in mid-way.
// 尝试增加存储的引用计数,以确保在刷新期间没有人关闭存储
if (store.tryIncRef()) {
// increment the ref just to ensure nobody closes the store during a refresh
try {
// even though we maintain 2 managers we really do the heavy-lifting only once.
// the second refresh will only do the extra work we have to do for warming caches etc.
ReferenceManager<ElasticsearchDirectoryReader> referenceManager = getReferenceManager(scope);
// it is intentional that we never refresh both internal / external together
if (block) {
referenceManager.maybeRefreshBlocking();
refreshed = true;
} else {
refreshed = referenceManager.maybeRefresh();
}
} finally {
// 减少存储的引用计数
store.decRef();
}
if (refreshed) {
lastRefreshedCheckpointListener.updateRefreshedCheckpoint(localCheckpointBeforeRefresh);
}
} else {
refreshed = false;
}
} catch (AlreadyClosedException e) {
failOnTragicEvent(e);
throw e;
} catch (Exception e) {
try {
failEngine("refresh failed source[" + source + "]", e);
} catch (Exception inner) {
e.addSuppressed(inner);
}
throw new RefreshFailedEngineException(shardId, e);
}
assert refreshed == false || lastRefreshedCheckpoint() >= localCheckpointBeforeRefresh
: "refresh checkpoint was not advanced; "
+ "local_checkpoint="
+ localCheckpointBeforeRefresh
+ " refresh_checkpoint="
+ lastRefreshedCheckpoint();
// TODO: maybe we should just put a scheduled job in threadPool?
// We check for pruning in each delete request, but we also prune here e.g. in case a delete burst comes in and then no more deletes
// for a long time:
maybePruneDeletes();
mergeScheduler.refreshConfig();
return refreshed;
}
flush源码:
执行条件主要在这段注释里面:
// Only flush if (1) Lucene has uncommitted docs, or (2) forced by caller, or (3) the
// newly created commit points to a different translog generation (can free translog),
// or (4) the local checkpoint information in the last commit is stale, which slows down future recoveries.
@Override
public void flush(boolean force, boolean waitIfOngoing) throws EngineException {
// 确保引擎是打开的
ensureOpen();
if (force && waitIfOngoing == false) {
// 如果强制执行 flush 但不等待正在进行的 flush 操作,抛出异常
assert false : "wait_if_ongoing must be true for a force flush: force=" + force + " wait_if_ongoing=" + waitIfOngoing;
throw new IllegalArgumentException(
"wait_if_ongoing must be true for a force flush: force=" + force + " wait_if_ongoing=" + waitIfOngoing
);
}
// 获取读锁
try (ReleasableLock lock = readLock.acquire()) {
ensureOpen();
if (flushLock.tryLock() == false) {
// if we can't get the lock right away we block if needed otherwise barf
if (waitIfOngoing == false) {
return;
}
logger.trace("waiting for in-flight flush to finish");
flushLock.lock();
logger.trace("acquired flush lock after blocking");
} else {
logger.trace("acquired flush lock immediately");
}
try {
/**
* 1. Lucene 有未提交的文档: 如果 Lucene 索引中存在未提交的文档,即有尚未写入磁盘的更改。
* 2. 被调用者强制执行: 如果调用者明确要求执行 flush 操作,即 force 参数为 true。
* 3. 新创建的提交指向不同的 translog 生成: 当新创建的提交(commit)指向不同的 translog 生成时,执行 flush 操作。
* 这可能是因为 translog 已经占用了一定的空间,需要释放这些旧的 translog。
* 4. 上一次提交的本地检查点信息已过期: 如果上一次提交的段信息中的本地检查点信息已过期,这可能会导致未来的恢复操作变慢。
* 因此,需要执行 flush 操作来更新本地检查点信息。
*/
// 检查 Lucene 是否有未提交的更改。
boolean hasUncommittedChanges = indexWriter.hasUncommittedChanges();
// 检查是否应定期执行 flush 操作
boolean shouldPeriodicallyFlush = shouldPeriodicallyFlush();
if (hasUncommittedChanges
|| force
|| shouldPeriodicallyFlush
// 检查是否本地检查点信息在上一次提交的段信息中过期,如果是,则触发 flush
|| getProcessedLocalCheckpoint() > Long.parseLong(
lastCommittedSegmentInfos.userData.get(SequenceNumbers.LOCAL_CHECKPOINT_KEY)
)) {
ensureCanFlush();
try {
// 滚动 translog 的生成
translog.rollGeneration();
logger.trace("starting commit for flush; commitTranslog=true");
// 提交索引写入器,包括在 Lucene 中提交未提交的文档,并将 translog 提交到持久存储。
commitIndexWriter(indexWriter, translog);
logger.trace("finished commit for flush");
// a temporary debugging to investigate test failure - issue#32827. Remove when the issue is resolved
logger.debug(
"new commit on flush, hasUncommittedChanges:{}, force:{}, shouldPeriodicallyFlush:{}",
hasUncommittedChanges,
force,
shouldPeriodicallyFlush
);
// we need to refresh in order to clear older version values
// 强制刷新索引以清除旧的版本信息。
refresh("version_table_flush", SearcherScope.INTERNAL, true);
translog.trimUnreferencedReaders();
} catch (AlreadyClosedException e) {
failOnTragicEvent(e);
throw e;
} catch (Exception e) {
throw new FlushFailedEngineException(shardId, e);
}
// 刷新最后提交的段信息
refreshLastCommittedSegmentInfos();
}
} catch (FlushFailedEngineException ex) {
maybeFailEngine("flush", ex);
throw ex;
} finally {
flushLock.unlock();
}
}
// We don't have to do this here; we do it defensively to make sure that even if wall clock time is misbehaving
// (e.g., moves backwards) we will at least still sometimes prune deleted tombstones:
if (engineConfig.isEnableGcDeletes()) {
pruneDeletedTombstones();
}
}
protected void commitIndexWriter(final IndexWriter writer, final Translog translog) throws IOException {
// 确保引擎的状态是允许刷新的
ensureCanFlush();
try {
// 获取已处理的本地检查点
final long localCheckpoint = localCheckpointTracker.getProcessedCheckpoint();
writer.setLiveCommitData(() -> {
final Map<String, String> commitData = new HashMap<>(8);
// 添加 translog 的 UUID 到提交数据中
commitData.put(Translog.TRANSLOG_UUID_KEY, translog.getTranslogUUID());
// 添加本地检查点到提交数据中
commitData.put(SequenceNumbers.LOCAL_CHECKPOINT_KEY, Long.toString(localCheckpoint));
// 添加最大序列号到提交数据中
commitData.put(SequenceNumbers.MAX_SEQ_NO, Long.toString(localCheckpointTracker.getMaxSeqNo()));
// 添加最大不安全自动生成的 ID 时间戳到提交数据中
commitData.put(MAX_UNSAFE_AUTO_ID_TIMESTAMP_COMMIT_ID, Long.toString(maxUnsafeAutoIdTimestamp.get()));
// 添加历史 UUID 到提交数据中
commitData.put(HISTORY_UUID_KEY, historyUUID);
final String currentForceMergeUUID = forceMergeUUID;
if (currentForceMergeUUID != null) {
// 如果强制合并 UUID 存在,则添加到提交数据中
commitData.put(FORCE_MERGE_UUID_KEY, currentForceMergeUUID);
}
// 添加最小保留序列号到提交数据中
commitData.put(Engine.MIN_RETAINED_SEQNO, Long.toString(softDeletesPolicy.getMinRetainedSeqNo()));
commitData.put(ES_VERSION, Version.CURRENT.toString());
logger.trace("committing writer with commit data [{}]", commitData);
return commitData.entrySet().iterator();
});
shouldPeriodicallyFlushAfterBigMerge.set(false);
// 调用Lucene 会将所有未提交的文档写入磁盘,生成新的段
writer.commit();
} catch (final Exception ex) {
try {
failEngine("lucene commit failed", ex);
} catch (final Exception inner) {
ex.addSuppressed(inner);
}
throw ex;
} catch (final AssertionError e) {
/*
* If assertions are enabled, IndexWriter throws AssertionError on commit if any files don't exist, but tests that randomly
* throw FileNotFoundException or NoSuchFileException can also hit this.
*/
if (ExceptionsHelper.stackTrace(e).contains("org.apache.lucene.index.IndexWriter.filesExist")) {
final EngineException engineException = new EngineException(shardId, "failed to commit engine", e);
try {
failEngine("lucene commit failed", engineException);
} catch (final Exception inner) {
engineException.addSuppressed(inner);
}
throw engineException;
} else {
throw e;
}
}
}
写副本
副本在写入数据到 translog 后就可以返回了。源码主要在ReplicationOperation类中
@Override
public void tryAction(ActionListener<ReplicaResponse> listener) {
replicasProxy.performOn(shard, replicaRequest, primaryTerm, globalCheckpoint, maxSeqNoOfUpdatesOrDeletes, listener);
}
处理结束给协调节点返回消息
@Override
public void onResponse(Void aVoid) {
successfulShards.incrementAndGet();
try {
updateCheckPoints(primary.routingEntry(), primary::localCheckpoint, primary::globalCheckpoint);
} finally {
decPendingAndFinishIfNeeded();
}
}
参考:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html
https://www.golangblogs.com/read/elasticsearch/date-2023.05.24.16.58.36?wd=Elasticsearch
《Elasticsearch源码解析与优化实战》