Python小知识
个人学习笔记,用于记录使用过程中好用的技巧、好用的库。
1 小知识
1.1 相对路径

1.2 打包Exe文件
命令:
pyinstaller -F main.py
其中-F:覆盖之前打包的文件
mian.py:需要打包的Python文件
PS:使用pyinstaller 5.10.0以上的版本,低于5.10.0以下会出现一些稀奇古怪的问题(Python版本为3.10)
1.3 字符串对齐ljust()|rjust()|center()
在生成C代码时,需要对齐备注等的要求,使用较多。
具体参考:https://blog.csdn.net/qdPython/article/details/111559495
1.4 正则表达式
1.4.1 普通字符
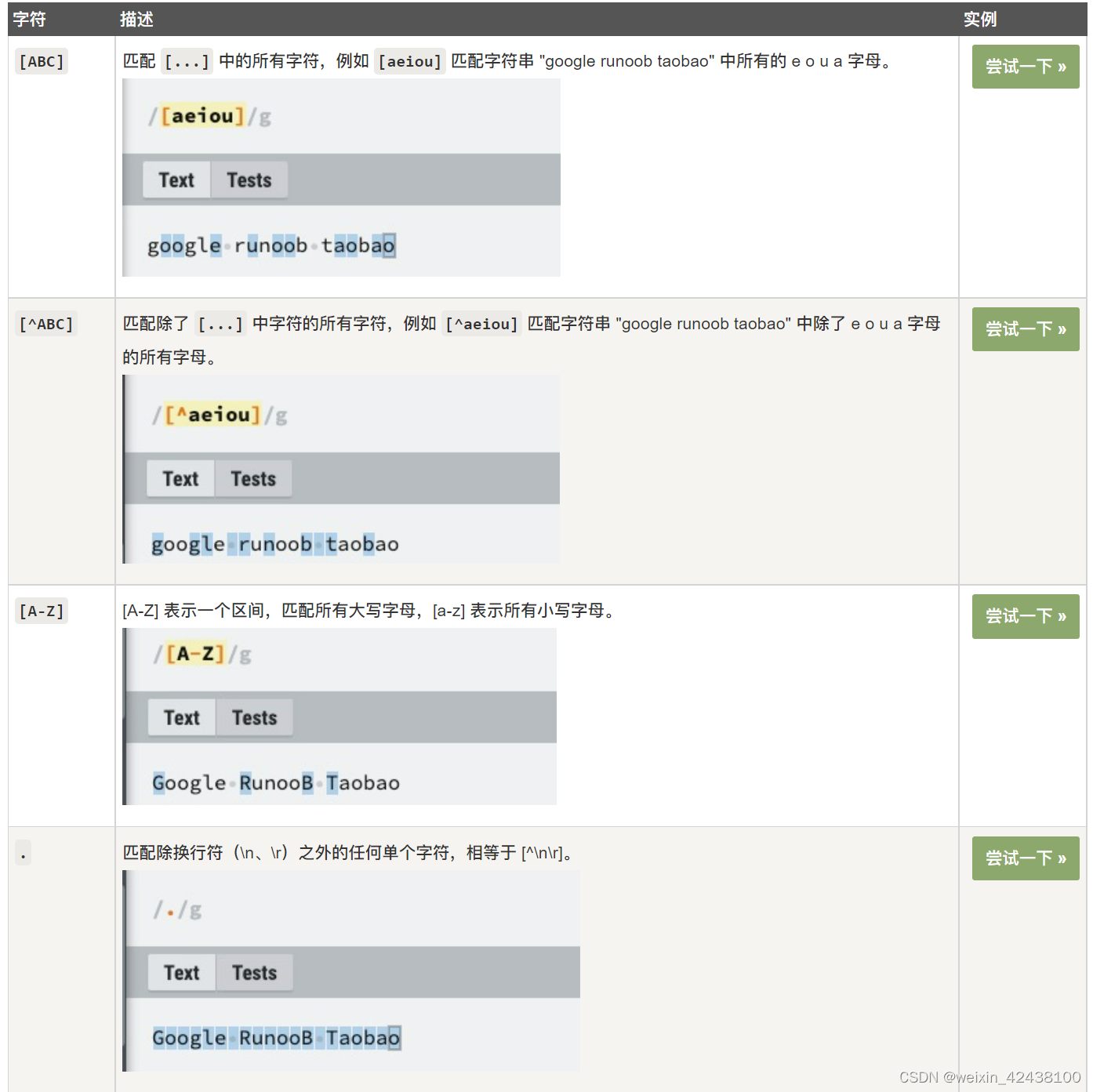

1.4.2 非打印字符

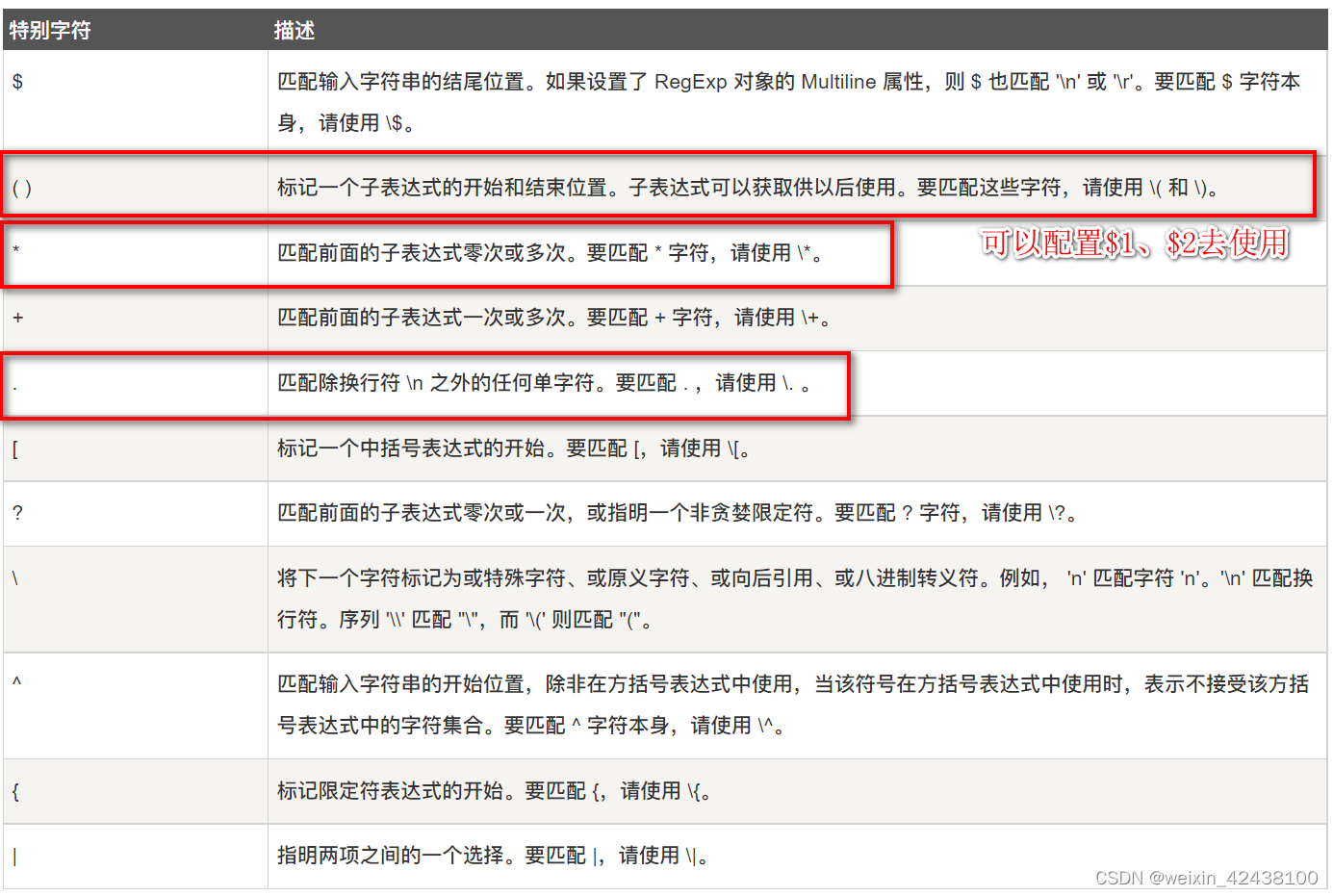
1.4.3 特殊字符
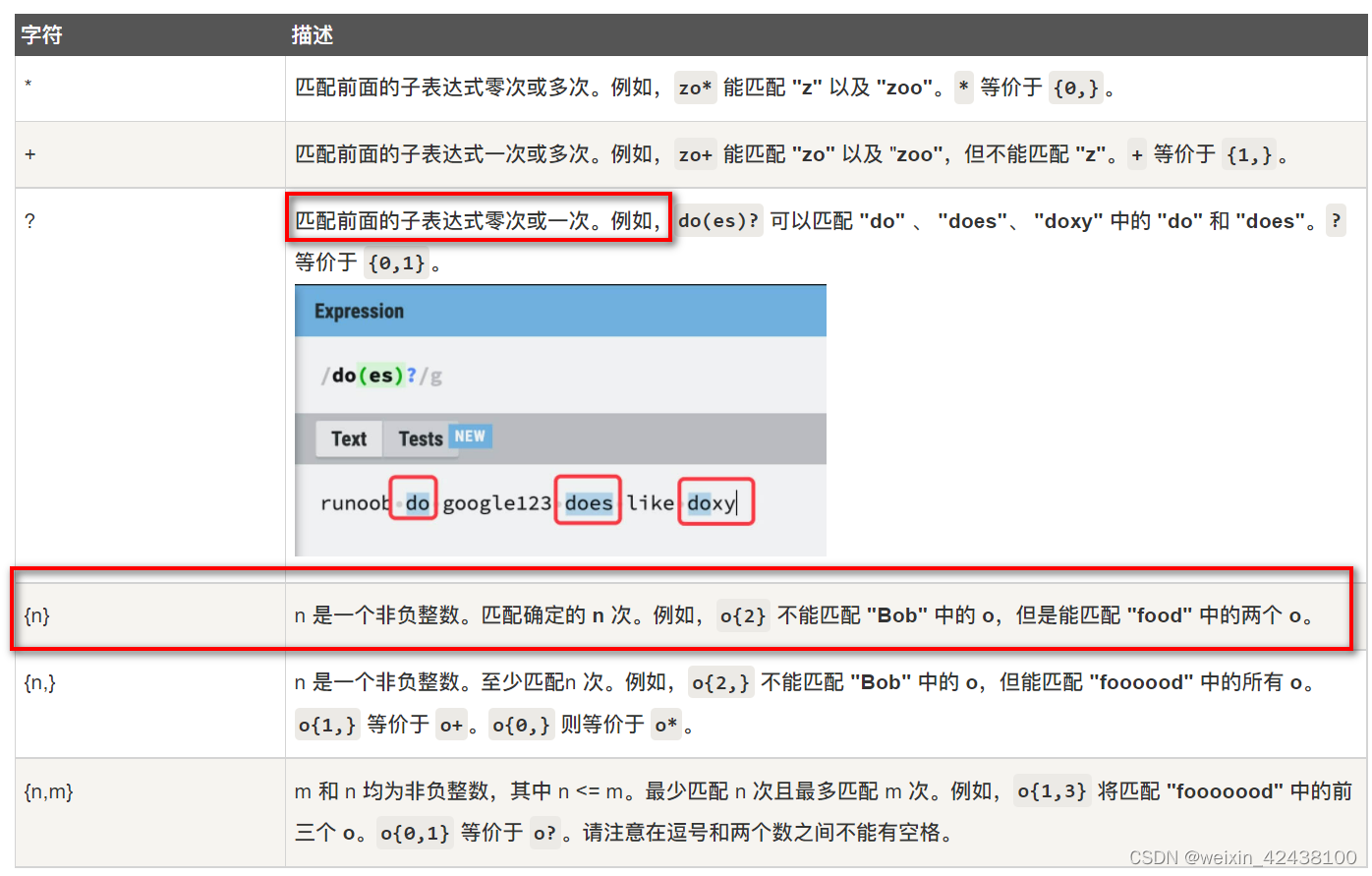
1.4.4 限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
参考资料:https://www.runoob.com/regexp/regexp-syntax.html
1.5 除法取整
1.5.1 向下取整
x = 1
y = 2
r = x // y
输出:0
1.5.2 向下取整
import math
x = 1
y = 2
math.ceil(x / y)
输出1
1.6 替换字符 - 删除指定字符
Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
1.6.1 语法
str.replace(old, new[, max])
1.6.2 参数
old -- 将被替换的子字符串。
new -- 新字符串,用于替换old子字符串。
max -- 可选字符串, 替换不超过 max 次
1.6.3 返回值
返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次。
1.6.4 实例
ss = 'old old string'
ret = ss.replace('old', 'new', 1)
print(ret)
输出
new old string
参考资料:https://www.runoob.com/python/att-string-replace.html
1.7 打印进度条
import sys
import time
def progress_bar(finish_tasks_number, tasks_number):
"""
进度条
:param finish_tasks_number: int, 已完成的任务数
:param tasks_number: int, 总的任务数
:return:
"""
percentage = round(finish_tasks_number / tasks_number * 100)
print("\r进度: {}%: ".format(percentage), "▓" * (percentage // 2), end="")
sys.stdout.flush()
if __name__ == '__main__':
for i in range(0, 101):
progress_bar(i, 100)
time.sleep(0.05)
效果图

参考资料:https://blog.csdn.net/TaoismHuang/article/details/120747536
2 库
2.1 parsel
parsel这个库可以解析HTML和XML,并支持使用Xpath和CSS选择器对内容进行提取和修改,同时还融合了正则表达式的提取功能。parsel灵活且强大,同时也是python最流行的爬虫框架Scrapy的底层支持。
CSS选择器使用
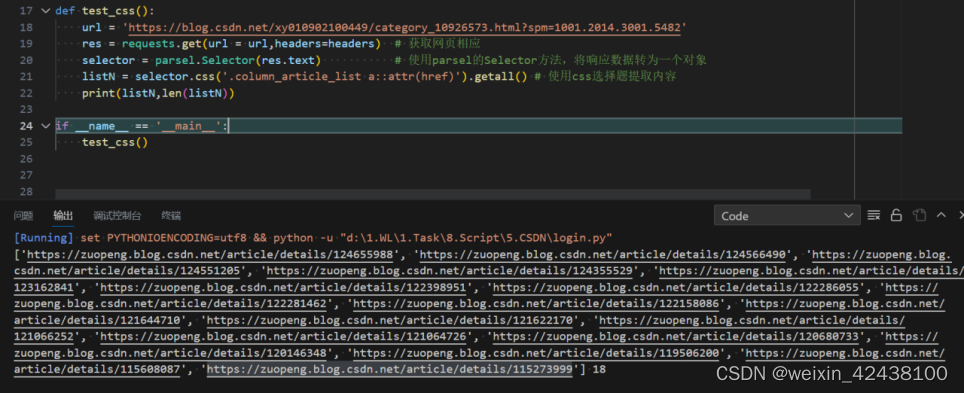
提取CSDN一个页面下面博客的所有链接。具体步骤如下:
①右键,选择“检查”,查看网页代码
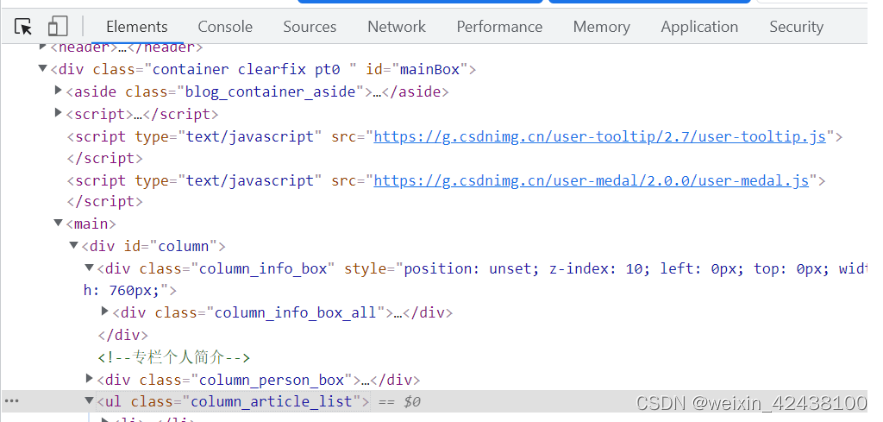
②复制第一篇文件链接,在网页代码中搜索,提取上一级标签的关键字,这里是“column_article_list”
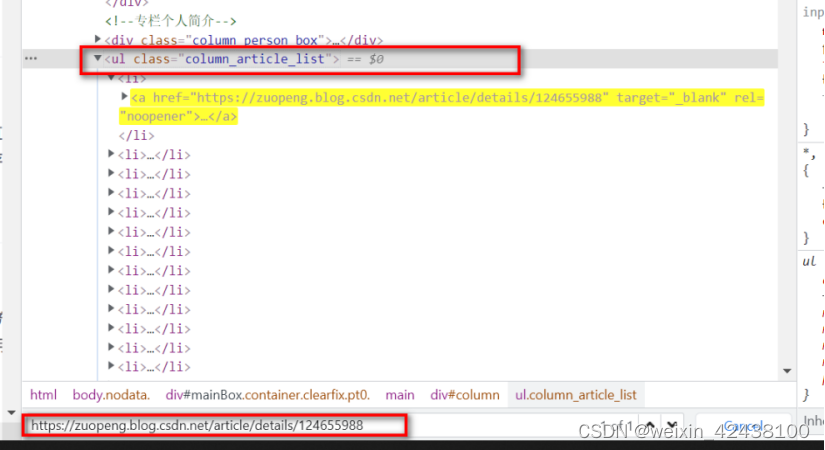
③复制上一级标签关键字,在搜索栏输入“.column_article_list”搜索
这里只会有唯一的一个匹配项
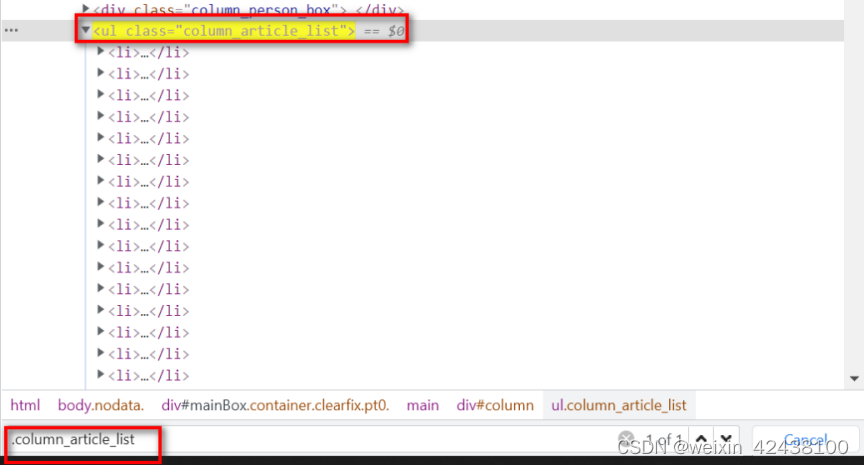
使用空格取下级标签,例如“.column_article_list a”表示取column_article_list下面的a标签,如果还需要往下取,继续加“空格+标签名”
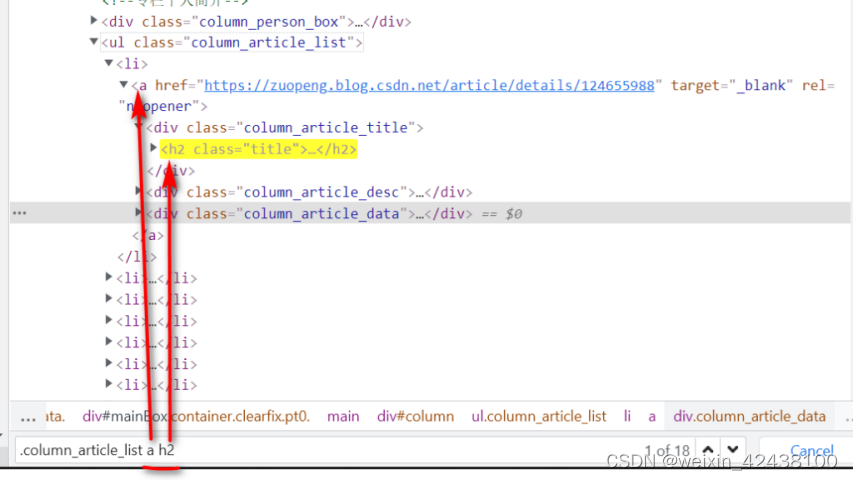
④回到代码
先使用parsel.Selector将响应的数据转换为一个对象,在对象中在使用css选择题提取内容。
这里“::attr(href)”表示去a标签的href属性
.getall():提取整个对象中符合要求的数据