正则表达式及文本三剑客grep,awk,sed
目录
正则表达式
前瞻
代表字符
表示次数
位置锚定
分组或其他
grep
选项
范例
awk
前瞻
awk常见的内置变量
范例
sed
前瞻
sed格式
范例
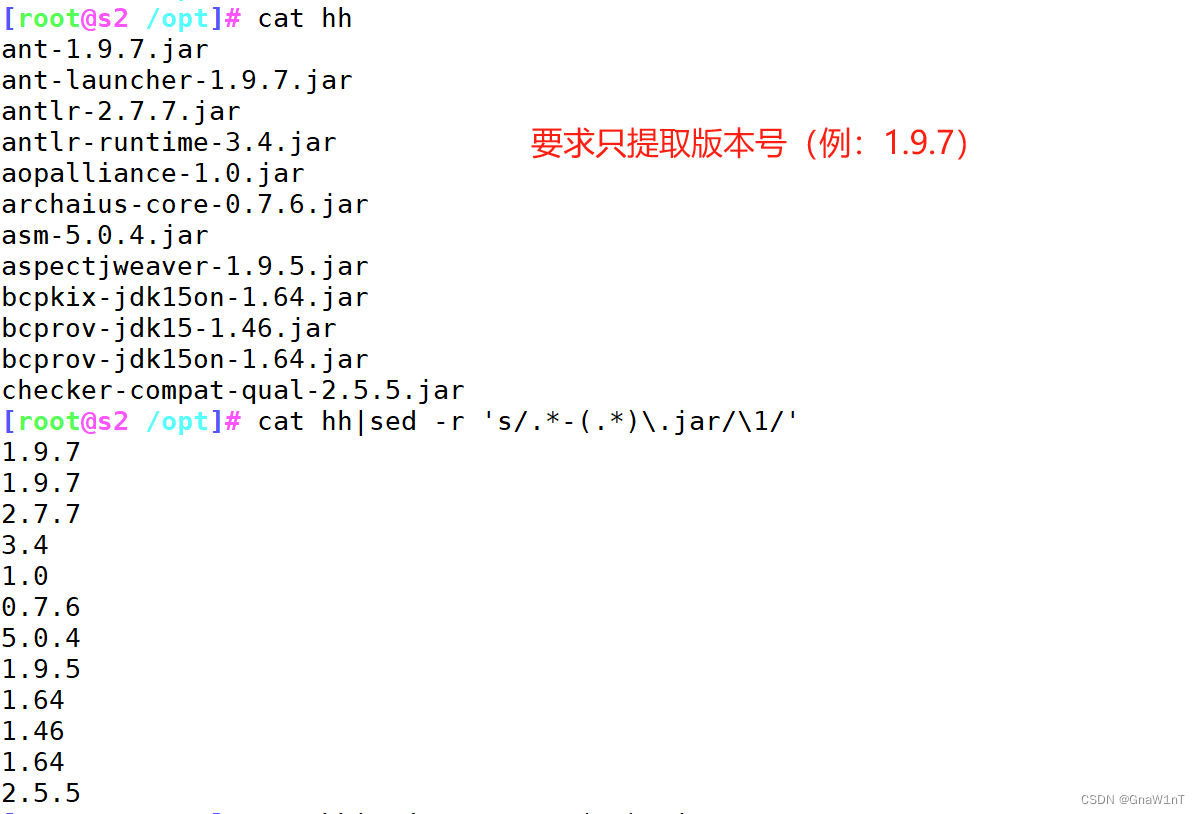
搜索替代
格式
范例
分组后项引用
格式
范例
正则表达式
前瞻
通配符:匹配的是文件名
正则表达式:匹配的是文章中的字符
元字符:不代表本来的含义,在正则表达式中有特殊含义的字符
正则表达式的表现
- 代表字符
- 表示次数
- 位置锚定
- 分组或其他
代表字符
. 匹配任意单个字符,可以是一个汉字

[ ] 匹配指定范围内的任意单个字符

[^ ] 匹配指定范围外的任意单个字符

[:lower:] = [a-z] :小写字母


[:upper:] = [A-Z] :大写字母

[:alpha:] = [a-zA-Z] :所有字母(大小写)

[:alnum:] :字母和数字

[:blank:] :空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广

表示次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配

.* #任意长度的任意字符,不包括0次

\? #匹配其前面的字符出现0次或1次,即:可有可无

\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次

\{n\} #匹配前面的字符n次

\{m,n\} #匹配前面的字符至少m次,至多n次

\{,n\} #匹配前面的字符至多n次,<=n
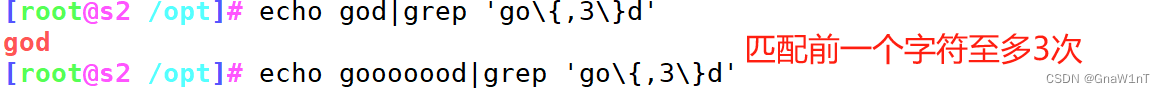
\{n,\} #匹配前面的字符至少n次
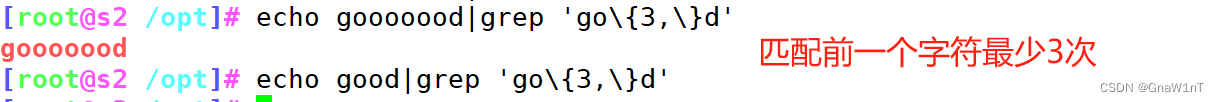
位置锚定
^ :行首锚定, 用于模式的最左侧

$ :行尾锚定,用于模式的最右侧

^......$ #用于模式匹配整行

^$ #空行
^[[:space:]]*$ # 空白行

\< 或 \b #词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)


\> 或 \b #词尾锚定,用于单词模式的右侧
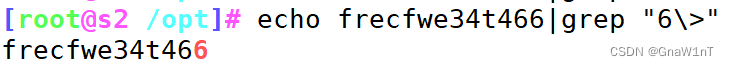

\<PATTERN\> #匹配整个单词

注:除了字母,数字,下划线,其他都算单词的分隔符

分组或其他
分组:( ) 将多个字符捆绑在一起,当作一个整体处理

grep
选项
-m # 匹配#次后停止
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 显示不被pattern匹配到的行,即取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
grep -E root|bash /etc/passwd
-w 匹配整个单词
grep -w root /etc/passwd
useradd rooter
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
范例

awk
前瞻
vim:文本处理工具,内存不足,打不开超大文件,把整个文件加载到内存中,如果内存不够大,或者文件过大,就打不开文件
awk:文本处理工具,加载一行,处理一行
格式:awk 选项 `表达式(处理动作)`
表达式:awk的语言的表达式
- 不写没有
- 找到特定的行
处理动作:
- print:打印
- printf:打印
常见选项:
- -F :指定分隔符
- -v:指定变量
- -f:脚本
awk常见的内置变量
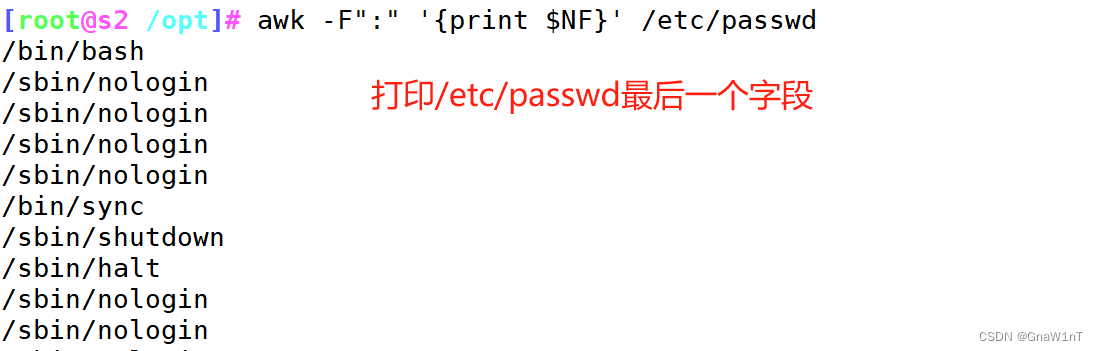
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)
$0:当前处理的行的整行内容
$n:当前处理行的第n个字段(第n列)
范例













sed
前瞻
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。
sed格式
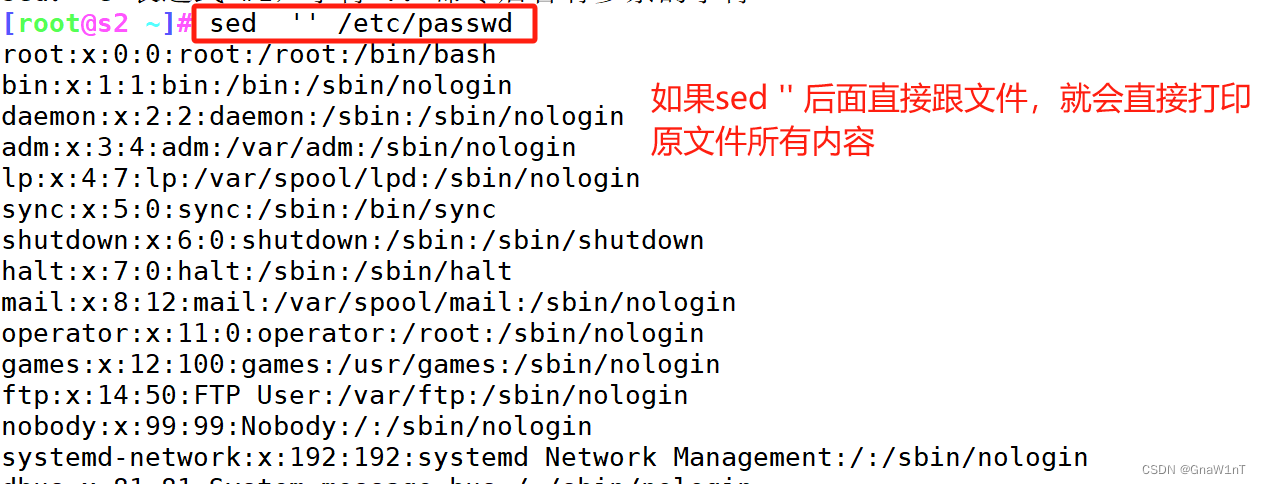
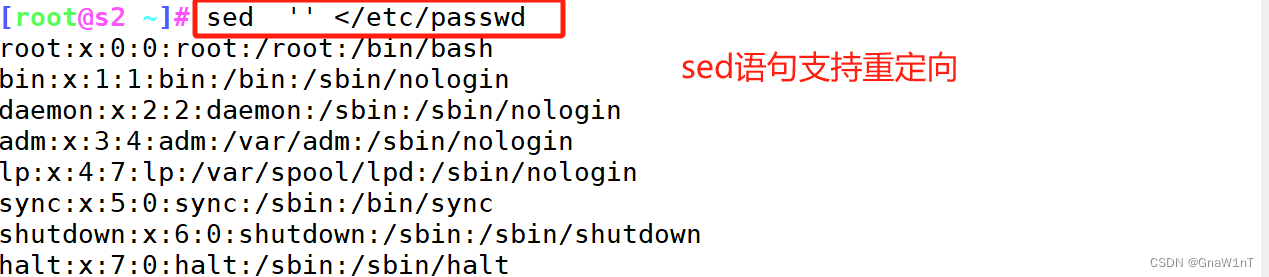
sed 命令选项 '自身脚本语法'常见命令选项
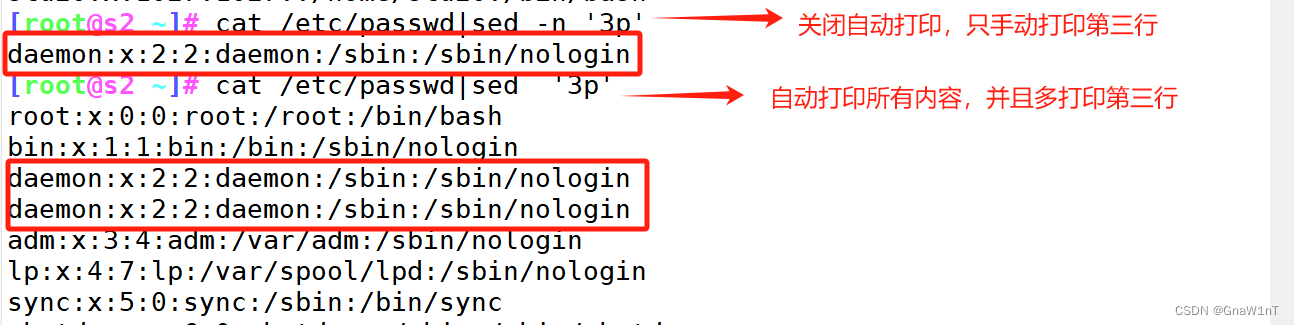
- -n :不输出模式空间内容到屏幕,即不自动打印
- -e :多点编辑
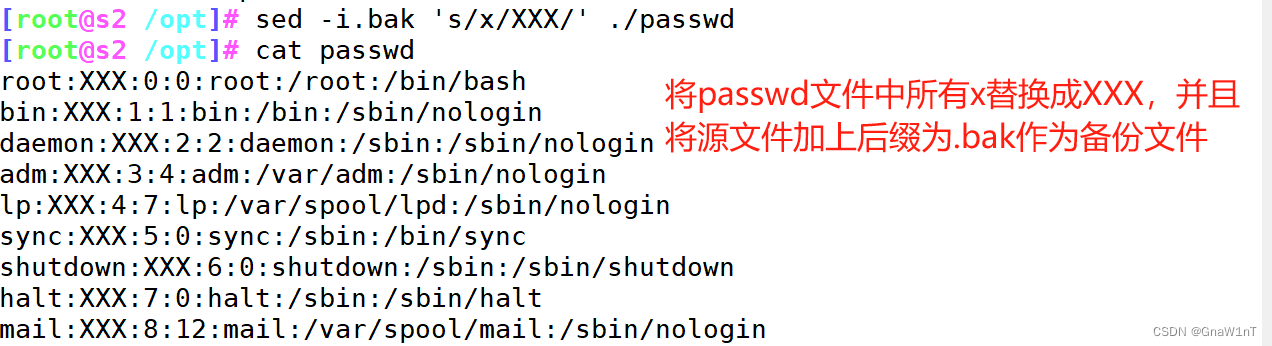
- -i :实际修改
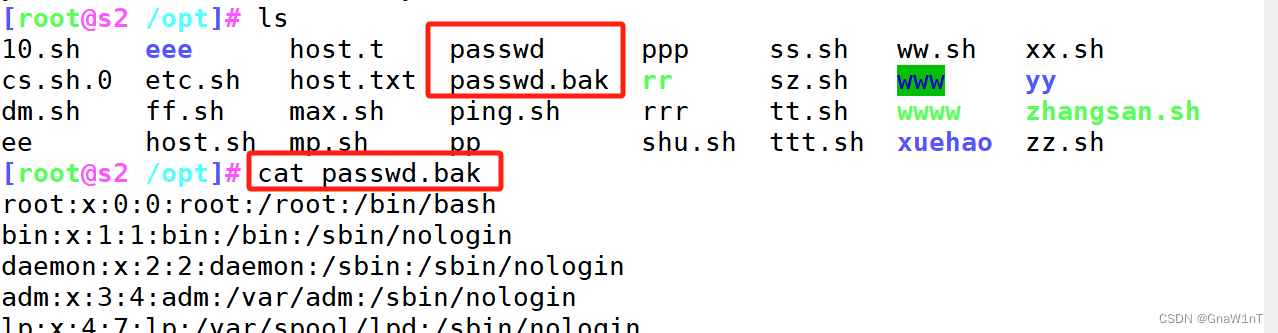
- -i.abc :实际修改前先备份源文件,产生以源文件名字为前缀,以.abc为后缀的备份文件
- -r:使用拓展正则表达式
注:
- -ir 不支持
- -i -r 支持
- -ri 支持
- -ni 会清空文件
常见脚本自身语法选项
- p:手动打印
- q:退出
- d:删除
- a:在下一行追加
- i:在前一行插入
- c:替换
范例


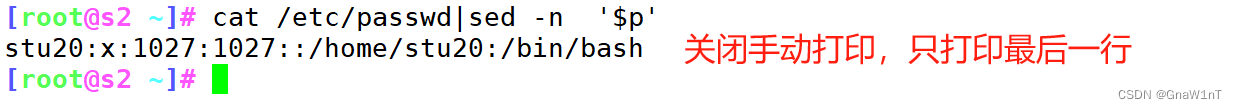






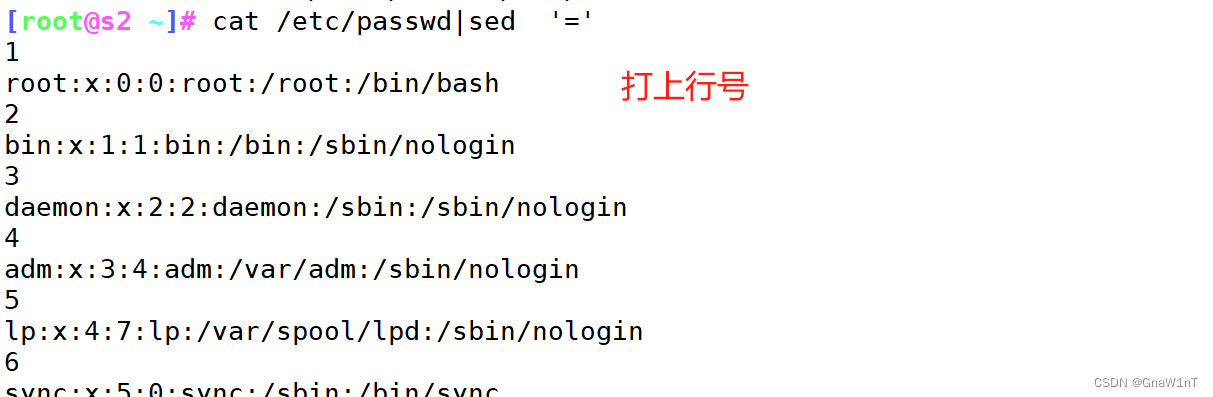
搜索替代
格式
sed 选项 '范围/旧字符/新字符/修饰符' 路径范例

分组后项引用
格式
sed 选项 '范围/定义的分组/\留下的组/修饰符' 文件路径范例