【ChatGLM3-6B】Docker下部署及微调
【ChatGLM2-6B】小白入门及Docker下部署
- 注意:Docker基于镜像中网盘上上传的有已经做好的镜像,想要便捷使用的可以直接从Docker基于镜像安装看
- Docker从0安装
- 前提
- 下载
- 启动
- 访问
- Docker基于镜像安装
- 容器打包操作(生成镜像时使用的命令)
- 安装时命令
- 微调
- 前提
- 微调和验证文件准备
- 微调和验证文件格式转换
- 修改微调脚本
- 执行微调
- 微调完成
- 结果推理验证
- 报错解决
- 出现了$‘\r’: command not found错误
- 加载微调模型
- API接口调用
注意:Docker基于镜像中网盘上上传的有已经做好的镜像,想要便捷使用的可以直接从Docker基于镜像安装看
Docker从0安装
前提
- 安装好了docker
- 安装好了NVIDIA
- 显卡16G
下载
-
新建一个文件夹,用来存放下载下来的ChatGLM3代码和模型
-
右键,打开一个git窗口,拉取模型(会很慢,耐心等待)
- 地址: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
-
右键,打开一个git窗口,拉取源代码
- 地址:https://github.com/THUDM/ChatGLM3
git clone https://github.com/THUDM/ChatGLM3或
git clone https://ghproxy.com/https://github.com/THUDM/ChatGLM3
- 注意:将下载好的模型(chatglm3-6b-models)和代码放到一个目录里面,并上传到服务器上
启动
docker run -itd --name chatglm3 -v `pwd`/ChatGLM3:/data \
--gpus=all -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all \
-p 8501:8501 pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
# 进入启动好的容器
docker exec -it chatglm3 bash
# 设置pip3下载路径为国内镜像
cd /data
pip3 config set global.index-url https://mirrors.aliyun.com/pypi/simple
pip3 config set install.trusted-host mirrors.aliyun.com
# 安装基础依赖
pip3 install -r requirements.txt
修改模型路径
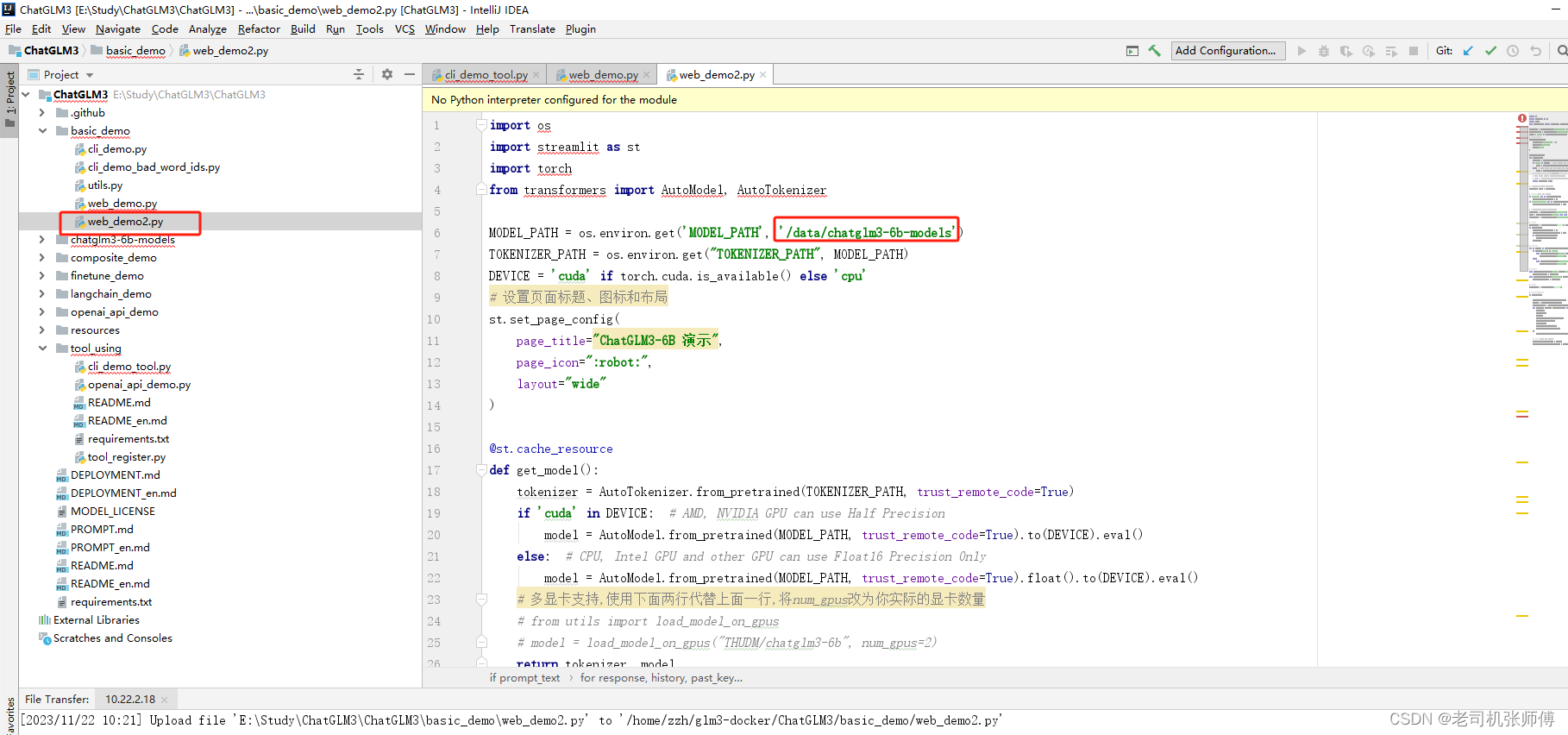
启动
streamlit run basic_demo/web_demo2.py
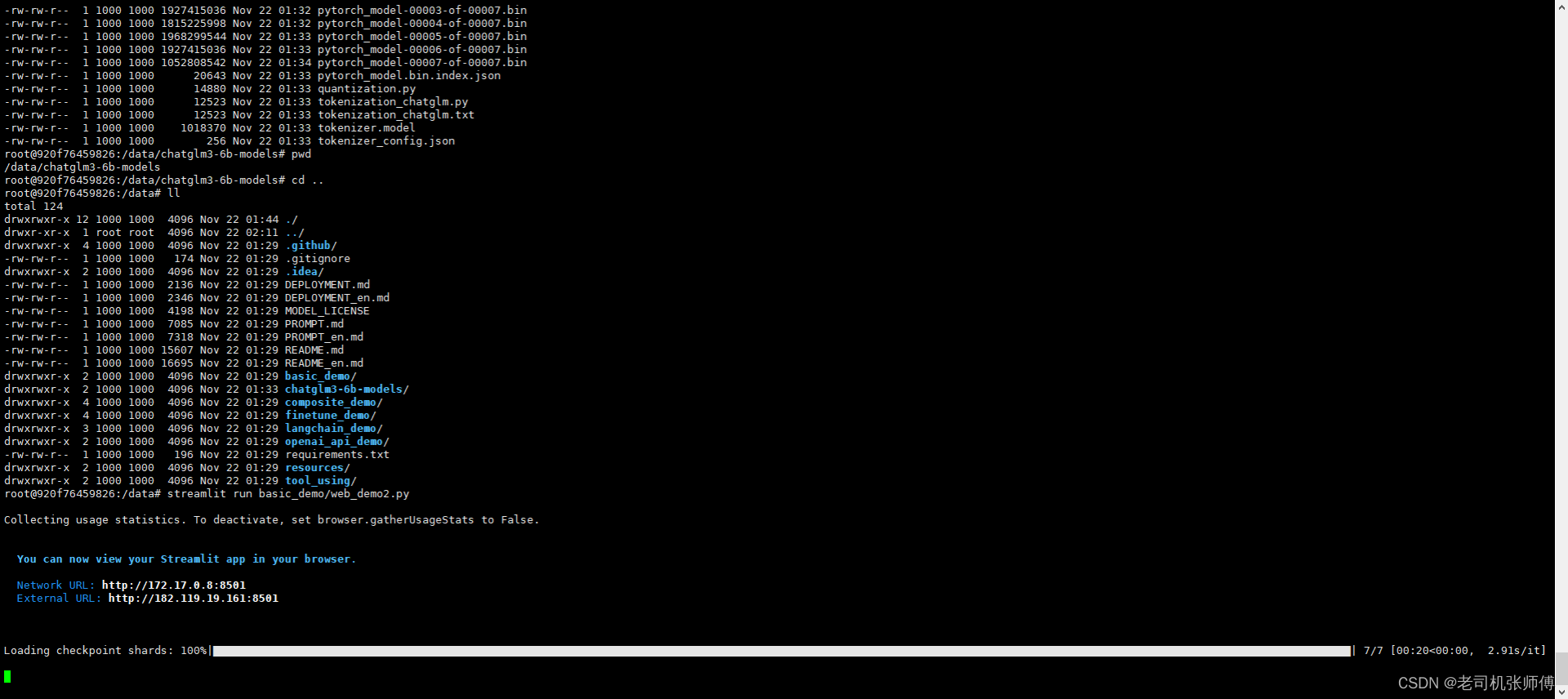
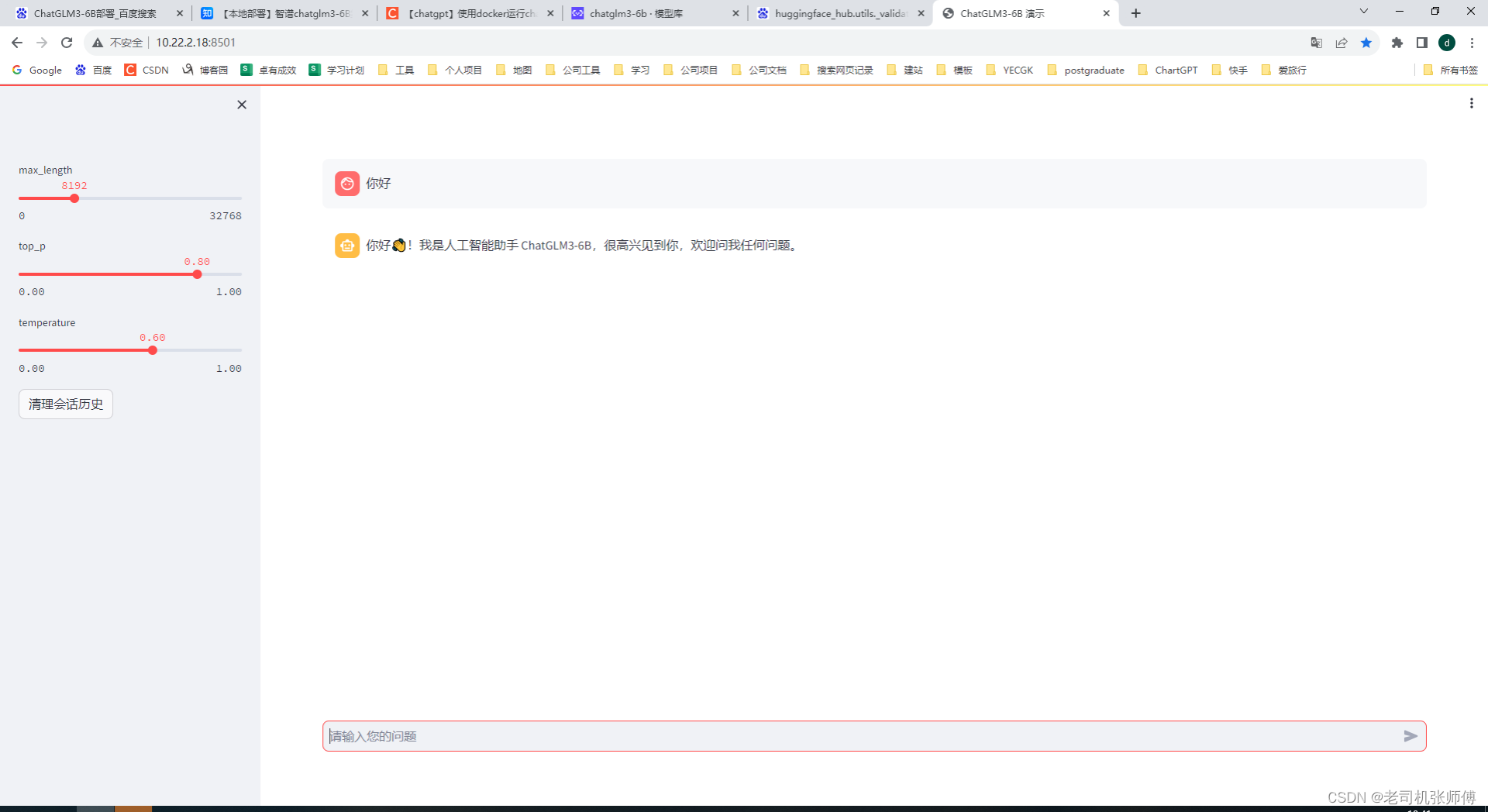
访问
http://10.22.2.18:8501/
Docker基于镜像安装
容器打包操作(生成镜像时使用的命令)
-
将安装好、启动好的容器打包成镜像
docker commit -m='glm3 commit' -a='zhangzh' chatglm3 chatglm3-6b:1.1 -
将镜像,打成可以传到其他地方的tar包
docker save -o chatglm3-6b.tar chatglm3-6b:1.1
安装时命令
-
网盘地址
这里因为网盘上传文件有大小限制,所以使用了分卷压缩的方式进行了上传,全部下载下来就可以。
链接:https://pan.baidu.com/s/1wY3QqaWrMyBR39d2ZhN_Kg?pwd=9zdd 提取码:9zdd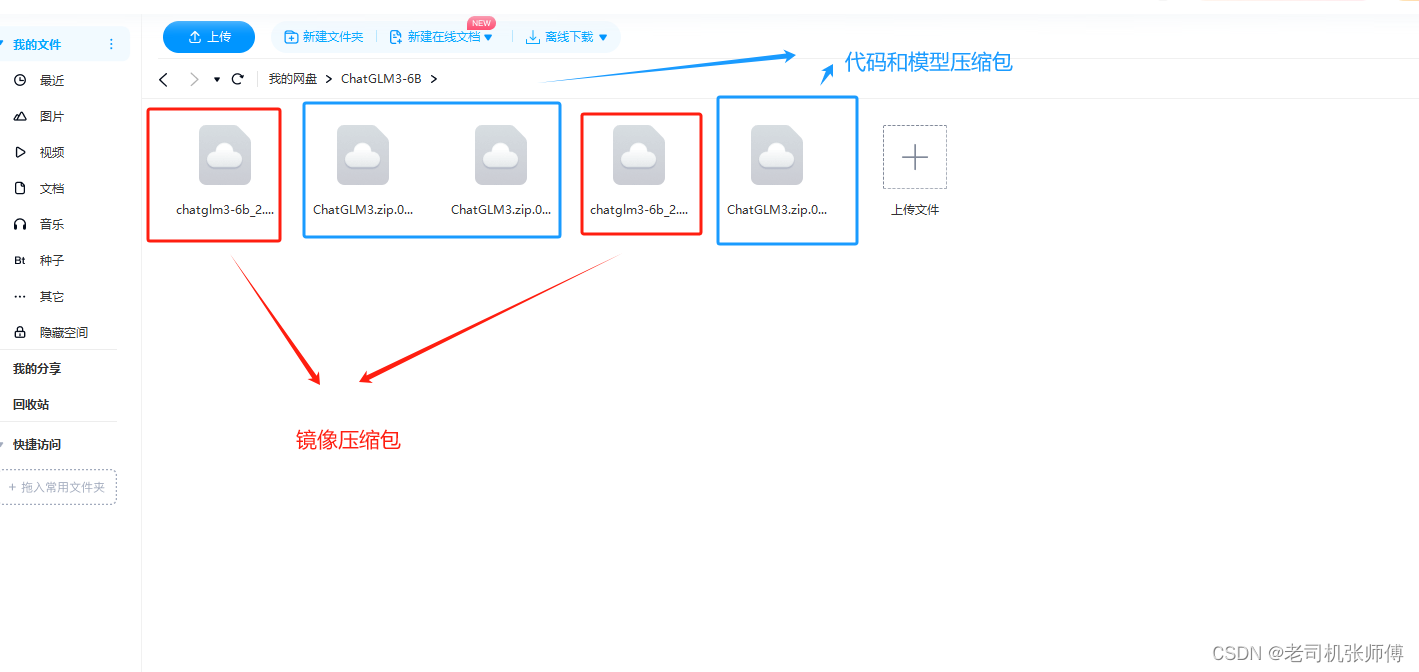
-
将下载好的镜像文件和代码模型文件上传到服务器上,并进行解压,然后在该目录进行操作。
-
在其他的docker服务器加载镜像
docker load -i chatglm3-6b.tar -
启动
docker run -itd --name chatglm3 -v `pwd`/ChatGLM3:/data \ --gpus=all -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all \ -p 8501:8501 -p 8000:8000 chatglm3-6b:1.1 -
进入容器
docker exec -it chatglm3 bash -
启动
cd /data streamlit run basic_demo/web_demo2.py -
访问:http://10.22.2.18:8501/
微调
微调操作直接在docker内进行
docker exec -it chatglm3 bash
前提
运行示例需要 python>=3.9,除基础的 torch 依赖外,示例代码运行还需要依赖
pip install transformers==4.30.2 accelerate sentencepiece astunparse deepspeed
微调和验证文件准备
微调参数文件为.json文件,先将你的微调数据和验证数据处理成如下格式:
{"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤", "summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"}
{"content": "类型#裙*风格#简约*图案#条纹*图案#线条*图案#撞色*裙型#鱼尾裙*裙袖长#无袖", "summary": "圆形领口修饰脖颈线条,适合各种脸型,耐看有气质。无袖设计,尤显清凉,简约横条纹装饰,使得整身人鱼造型更为生动立体。加之撞色的鱼尾下摆,深邃富有诗意。收腰包臀,修饰女性身体曲线,结合别出心裁的鱼尾裙摆设计,勾勒出自然流畅的身体轮廓,展现了婀娜多姿的迷人姿态。"}
{"content": "类型#上衣*版型#宽松*颜色#粉红色*图案#字母*图案#文字*图案#线条*衣样式#卫衣*衣款式#不规则", "summary": "宽松的卫衣版型包裹着整个身材,宽大的衣身与身材形成鲜明的对比描绘出纤瘦的身形。下摆与袖口的不规则剪裁设计,彰显出时尚前卫的形态。被剪裁过的样式呈现出布条状自然地垂坠下来,别具有一番设计感。线条分明的字母样式有着花式的外观,棱角分明加上具有少女元气的枣红色十分有年轻活力感。粉红色的衣身把肌肤衬托得很白嫩又健康。"}
{"content": "类型#裙*版型#宽松*材质#雪纺*风格#清新*裙型#a字*裙长#连衣裙", "summary": "踩着轻盈的步伐享受在午后的和煦风中,让放松与惬意感为你免去一身的压力与束缚,仿佛要将灵魂也寄托在随风摇曳的雪纺连衣裙上,吐露出<UNK>微妙而又浪漫的清新之意。宽松的a字版型除了能够带来足够的空间,也能以上窄下宽的方式强化立体层次,携带出自然优雅的曼妙体验。"}
其中content是向模型输入的内容,summary为模型应该输出的内容。
其中微调数据是通过本批数据对模型进行调试(文件是train.json),验证数据是通过这些数据验证调试的结果(文件是dev.json)。
微调和验证文件格式转换
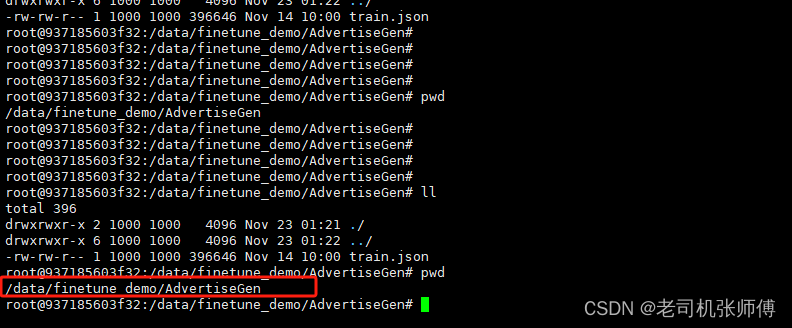
1、在项目代码的finetune_demo目录下新建一个AdvertiseGen目录,并将你的文件上传上去。
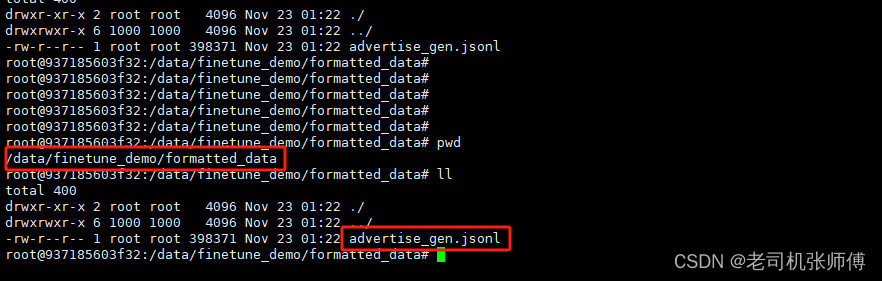
2、然后回到finetune_demo目录,执行以下脚本进行转换,转换后的文件放在formatted_data目录下。
python ./scripts/format_advertise_gen.py --path "AdvertiseGen/train.json"
修改微调脚本
本方法使用的微调脚本是finetune_demo/scripts/finetune_pt.sh,修改各个参数为自己的环境,其中:
PRE_SEQ_LEN: 模型长度,后续使用微调结果加载时要保持一直
MAX_SOURCE_LEN:模型输入文本的长度,超过该长度会截取,会影响占用GPU,我这里GPU为16G基本吃满
MAX_TARGET_LEN:模型输出文本的最大长度,会影响占用GPU,我这里GPU为16G基本吃满
BASE_MODEL_PATH:原模型的地址
DATASET_PATH:模型微调参数文件的地址
OUTPUT_DIR:模型微调结果存放的地址
MAX_STEP:调试的步数,主要跟微调需要的时间有关,越小则时间越短,但微调的准确度(影响度)越小
SAVE_INTERVAL:多少步保存一个微调结果
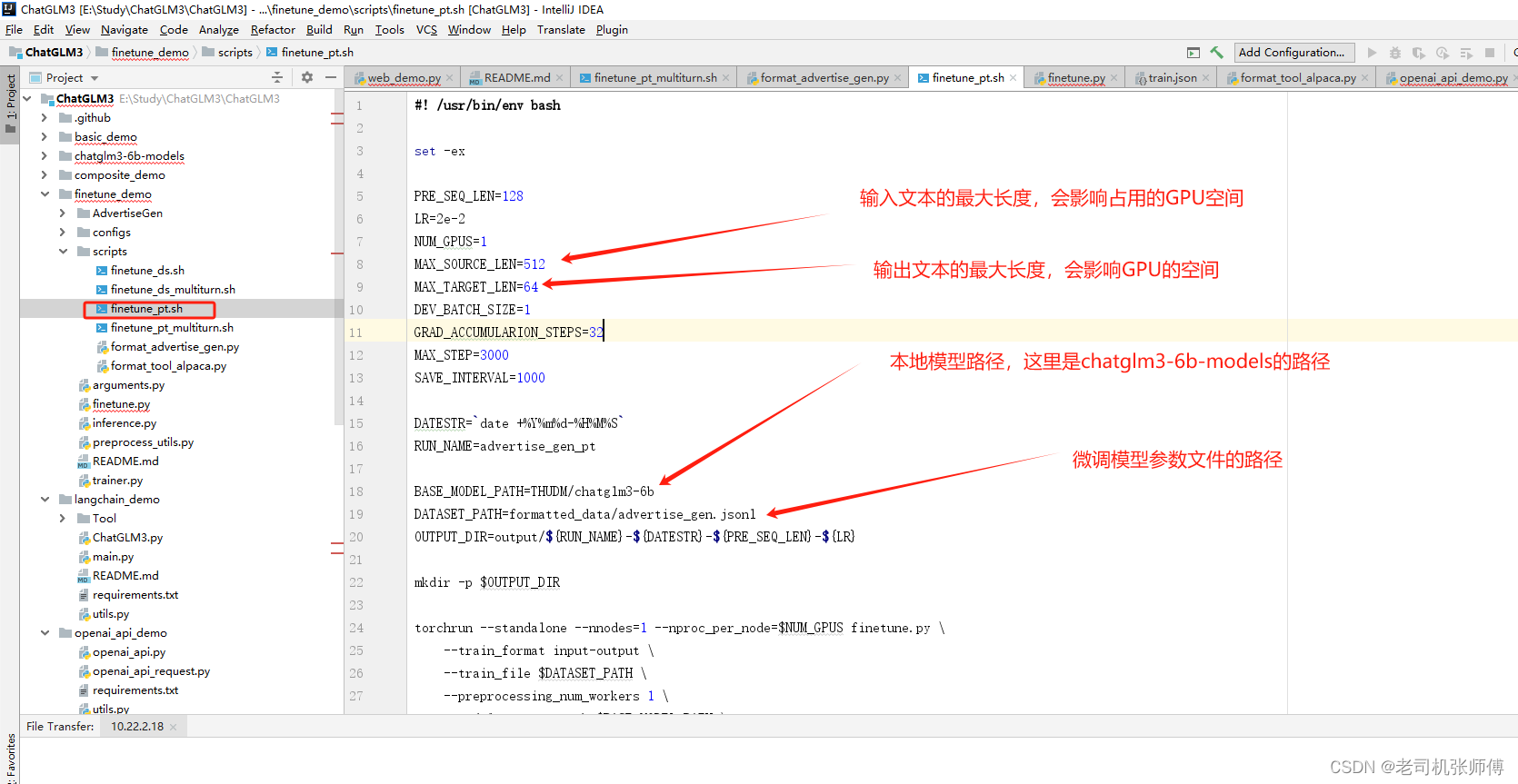
脚本如下:
#! /usr/bin/env bash
set -ex
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
MAX_SOURCE_LEN=512
MAX_TARGET_LEN=64
DEV_BATCH_SIZE=1
GRAD_ACCUMULARION_STEPS=32
MAX_STEP=1500
SAVE_INTERVAL=500
DATESTR=`date +%Y%m%d-%H%M%S`
RUN_NAME=advertise_gen_pt
BASE_MODEL_PATH=/data/chatglm3-6b-models
DATASET_PATH=formatted_data/advertise_gen.jsonl
OUTPUT_DIR=output/${RUN_NAME}-${DATESTR}-${PRE_SEQ_LEN}-${LR}
mkdir -p $OUTPUT_DIR
torchrun --standalone --nnodes=1 --nproc_per_node=$NUM_GPUS finetune.py \
--train_format input-output \
--train_file $DATASET_PATH \
--preprocessing_num_workers 1 \
--model_name_or_path $BASE_MODEL_PATH \
--output_dir $OUTPUT_DIR \
--max_source_length $MAX_SOURCE_LEN \
--max_target_length $MAX_TARGET_LEN \
--per_device_train_batch_size $DEV_BATCH_SIZE \
--gradient_accumulation_steps $GRAD_ACCUMULARION_STEPS \
--max_steps $MAX_STEP \
--logging_steps 1 \
--save_steps $SAVE_INTERVAL \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN 2>&1 | tee ${OUTPUT_DIR}/train.log
执行微调
先给脚本执行权限
chmod -R 777 ./scripts/finetune_pt.sh
执行脚本
./scripts/finetune_ds.sh # 全量微调
./scripts/finetune_pt.sh # P-Tuning v2 微调
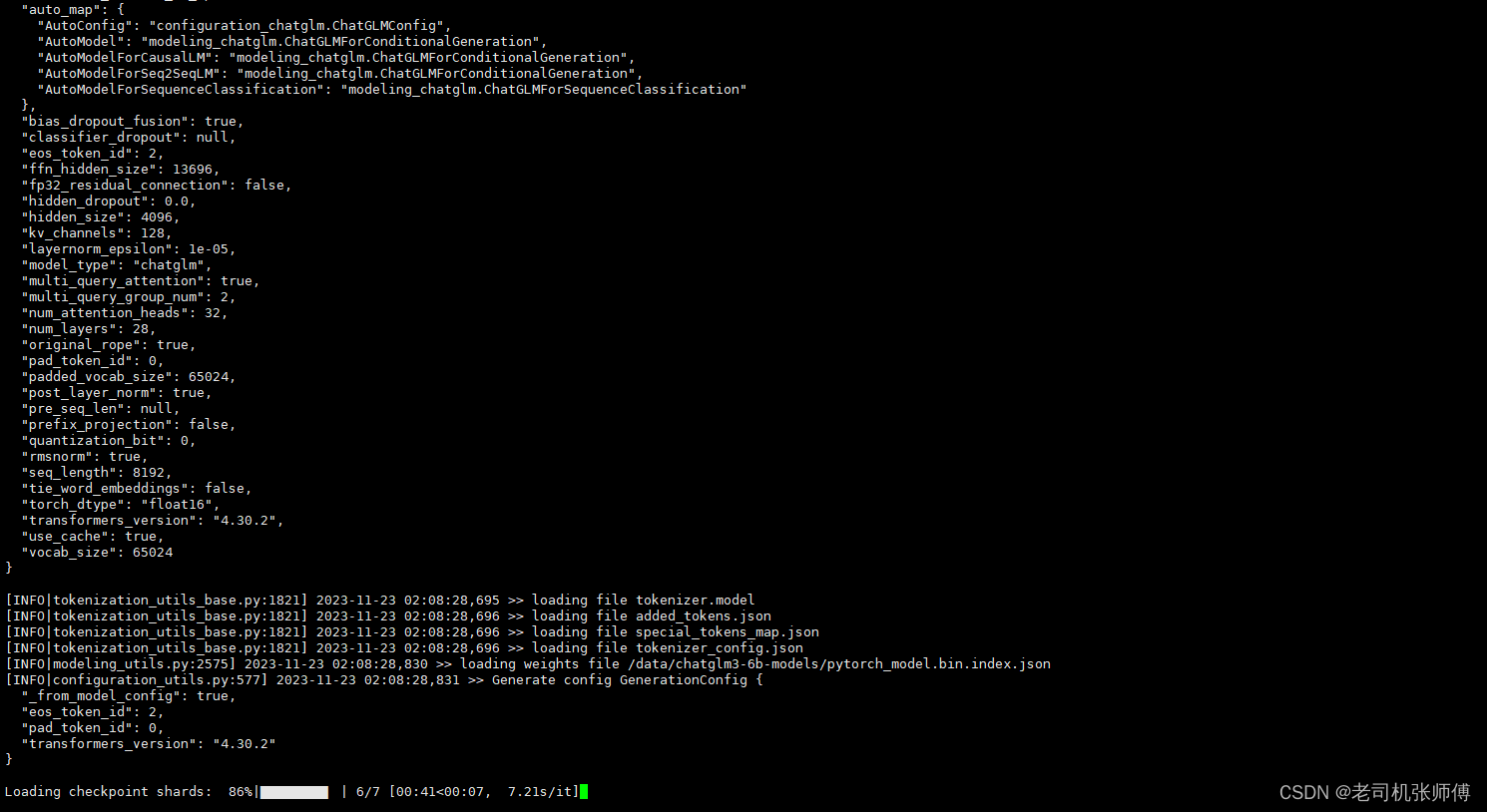
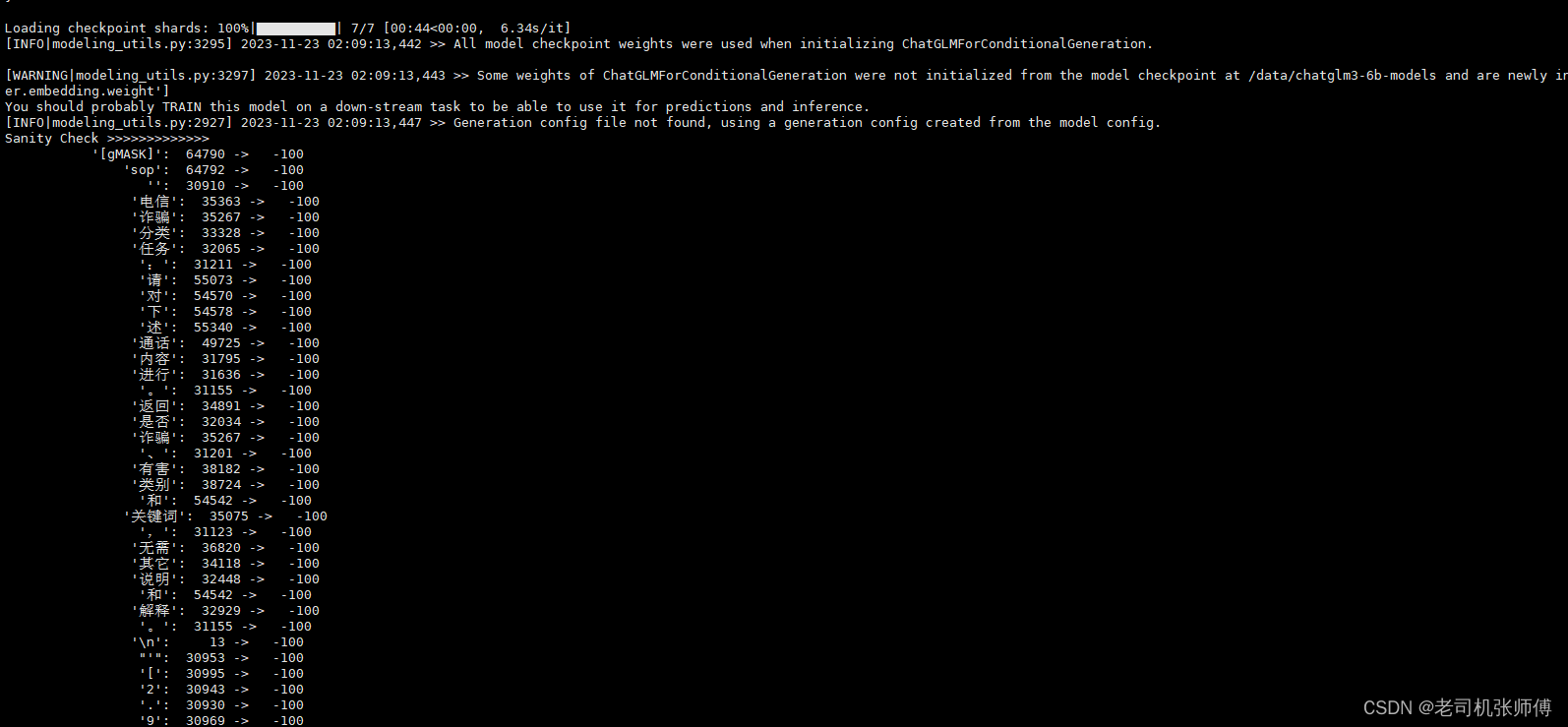
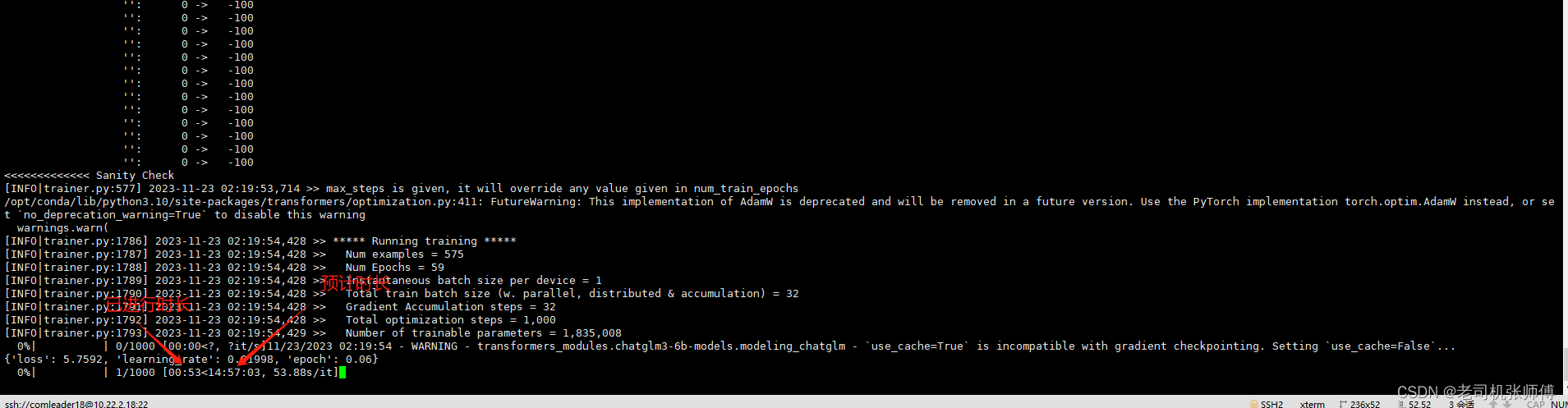
微调完成
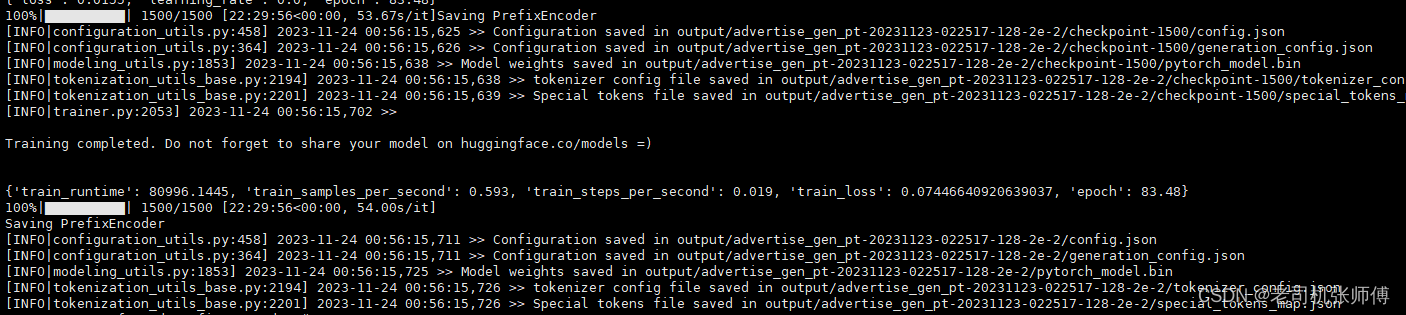
结果推理验证
python inference.py \
--pt-checkpoint "/data/finetune_demo/output/advertise_gen_pt-20231123-022517-128-2e-2/checkpoint-1500" \
--model /data/chatglm3-6b-models
报错解决
出现了$‘\r’: command not found错误
可能因为该Shell脚本是在Windows系统编写时,每行结尾是\r\n
而在Linux系统中行每行结尾是\n
在Linux系统中运行脚本时,会认为\r是一个字符,导致运行错误
使用dos2unix 转换一下就可以了
dos2unix <文件名>
# dos2unix: converting file one-more.sh to Unix format ...
-bash: dos2unix: command not found
就是还没安装,安装一下就可以了
apt install dos2unix
加载微调模型
cd ../composite_demo
MODEL_PATH="/data/chatglm3-6b-models" PT_PATH="/data/finetune_demo/output/advertise_gen_pt-20231123-022517-128-2e-2/checkpoint-1500" streamlit run main.py
重新访问页面,即可啦~
API接口调用
-
下载依赖
pip install openai==1.3.0 pip install pydantic==2.5.1 -
进入openai_api_demo目录
-
修改脚本
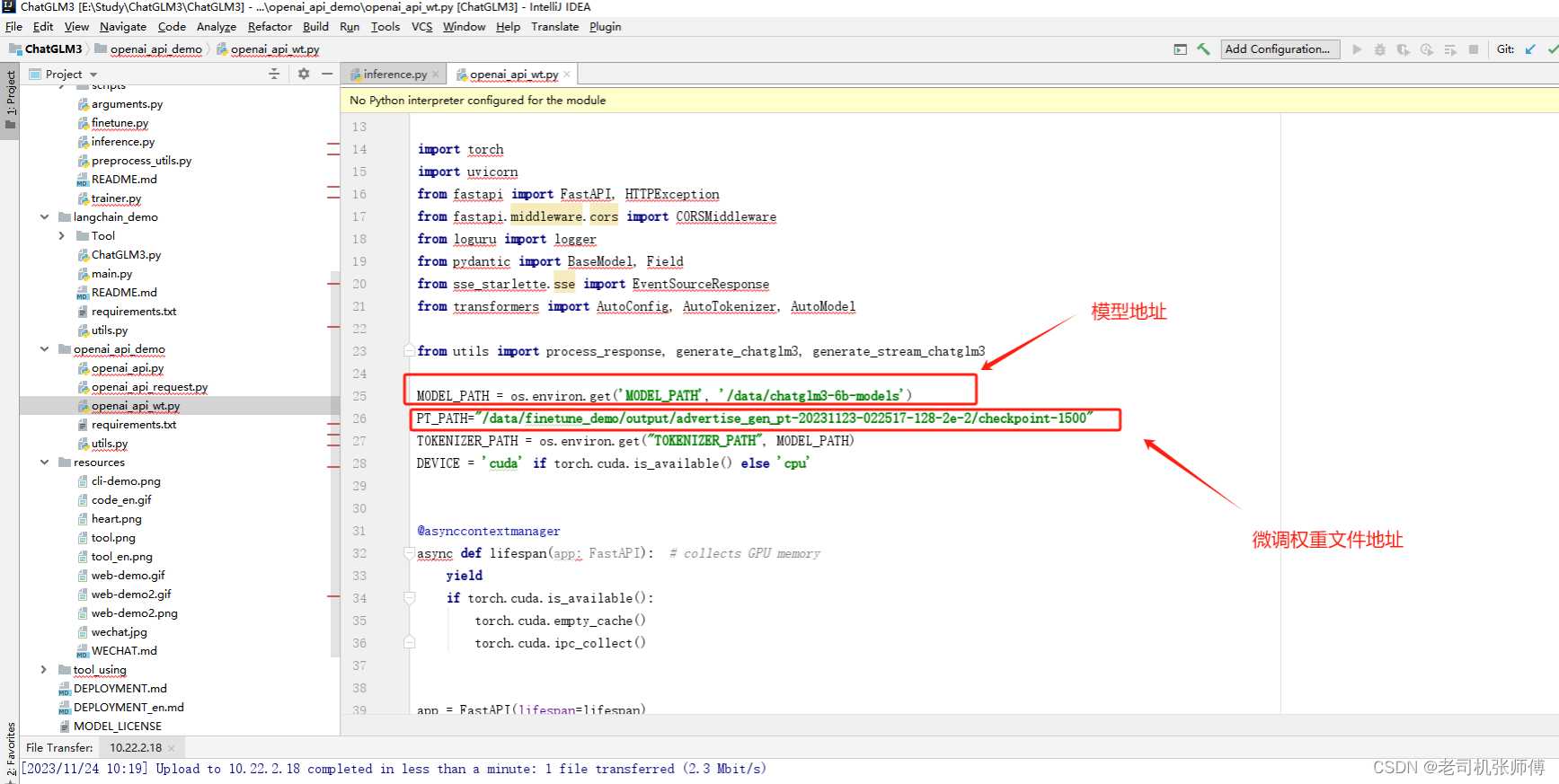
-
启动脚本
python openai_api_wt.py -
访问SwaggerUI地址
http://10.22.2.18:8000/docs#/default/list_models_v1_models_get
接口:http://10.22.2.18:8000/v1/chat/completions
参数:
{ "model": "chatglm3-6b", "messages": [ { "role": "user", "content": "你好,给我讲一个故事,大概100字" # 这里是请求的参数 } ], "stream": false, "max_tokens": 100, "temperature": 0.8, "top_p": 0.8 }