亚马逊云科技向量数据库助力生成式AI成功落地实践探秘(二)
向量数据库选择哪种近似搜索算法,选择合适的集群规模以及集群设置调优对于知识库的读写性能也十分关键,主要需要考虑以下几个方面:
向量数据库算法选择
在 OpenSearch 里,提供了两种 k-NN 的算法:HNSW (Hierarchical Navigable Small World) 和 IVF (Inverted File) 。
在选择 k-NN 搜索算法时,需要考虑多个因素。如果内存不是限制因素,建议优先考虑使用 HNSW 算法,因为 HNSW 算法可以同时保证 latency 和 recall。如果内存使用量需要控制,可以考虑使用 IVF 算法,它可以在保持类似 HNSW 的查询速度和质量的同时,减少内存使用量。但是,如果内存是较大的限制因素,可以考虑为 HNSW 或 IVF 算法添加 PQ 编码,以进一步减少内存使用量。需要注意的是,添加 PQ 编码可能会降低准确率。因此,在选择算法和优化方法时,需要综合考虑多个因素,以满足具体的应用需求。
向量数据库集群规模预估
选定了算法后,我们就可以根据公式,计算所需的内存进而推导出 k-NN 集群大小, 以 HNSW 算法为例:
占用内存 = 1.1 * (4*d + 8*m) * num_vectors * (number_of_replicas + 1)
其中 d:vector 的维度,比如 768;m:控制层每个节点的连接数;num_vectors:索引中的向量 doc 数
向量数据库批量注入优化
在向知识向量数据库中注入大量数据时,我们需要关注一些关键的性能优化,以下是一些主要的优化策略:
Disable refresh interval
在首次摄入大量数据时,为了避免生成较多的小型 segment,我们可以增大刷新的间隔,或者直接在摄入阶段关闭 refresh_interval(设置成 -1)。等到数据加载结束后,再重新启用 refresh_interval。

Disable Replicas
同样,在向量数据库首次加载大量数据时,我们可以暂时禁用 replica 以提升摄入速度。需要注意的是,这样做可能会带来向量数据库丢失数据的风险,因此,在向量数据库数据加载结束后,我们需要再次启用 replica。

增加 indexing 线程
处理 knn 的线程由 knn.algo_param.index_thread_qty 指定,默认为 1。如果你的设备有足够的 CPU 资源,可以尝试调高这个参数,会加快 k-NN 索引的构建速度。但是,这可能会增加 CPU 的压力,因此,建议先按节点 vcore 的一半进行配置,并观察 cpu 负载情况。

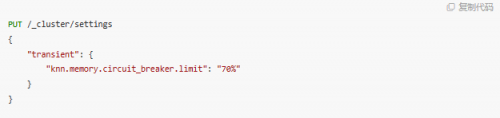
增加 knn 内存占比
knn.memory.circuit_breaker.limit 是一个关于内存使用的参数,默认值为 50%。如果需要,我们可以将其改成 70%。以这个默认值为例,如果一台机器有 100GB 的内存,由于程序寻址的限制,一般最多分配 JVM 的堆内存为 32GB,则 k-NN 插件会使用剩余的 68GB 中的一半,即 34GB 作为 k-NN 的索引缓存。如果内存使用超过这个值,k-NN 将会删除最近使用最少的向量。该参数在集群规模不变的情况下,提高 k-NN 的缓存命中率,有助于降低成本并提高检索效率。
本文对于向量数据库知识库构建部分展开了初步的讨论,基于实践经验对于知识库构建中的一些文档拆分方法,向量模型选择,向量数据库调优等一些主要步骤分享了一些心得,但相对来说比较抽象,如果你对此感兴趣,可以期待下一篇。