阅读文献总结2023
- 阅读文献
- 基于卷积神经网络多源融合的网络安全态势感知模型
阅读文献
基于卷积神经网络多源融合的网络安全态势感知模型
| 题目 | 基于卷积神经网络多源融合的网络安全态势感知模型 |
|---|---|
| 文章信息: | |
| 年份 | 2023 |
| 发文单位 | 山西财经大学 |
| 收录刊会 | 计算机科学 (北大核心) |
| 作者 | 刘秀娟 |
| 引用量 | 5 |
| 摘要: | |
| 摘要目的 | 为了准确获取整个网络的安全态势 |
| 摘要方法 | 采用多源融合算法提升攻击识别准确率 多源融合指采用指数加权的D-S融合方法有效地融合各决策引擎的输出结果 决策引擎指以属性提炼生成的各探测器的核心属性数据为输入,以卷积神经网络为引擎识别各种攻击 |
| 摘要结果 | 多源融合算法可将攻击识别的准确率提升到92.76% |
| 摘要结论 | 多源融合算法可以提高识别工具的准确率 |
| 引言: | |
| 引言背景 | 网络带来了新的安全威胁 |
| 引言需要解决的问题 | 为了应对多样的网络攻击 |
| 引言已有研究不足 | gan和li只进行了纵向对比,没有进行横向对比。 zhao召回率低 liu探测率还有进一步提升 qian依赖于前期学者态势值的计算结果的准确性 chang准确率低 he研究成果针对特定的情景,具有一定局限性 zhang攻击识别准确率低 li模型参数多达50213个 |
| 引言本文开展研究 | (1)立足流量基本特征,选取netflow,snort和suricata这3个探测器来多方位地监测网络,提炼恶意活动的核心属性 (2)聚焦攻击识别性能不足,通过CNN+多源融合,提升攻击识别能力 (3)为了消除态势计算中主观因素的影响,采用层次化网络分析方法,客观高效地评估网络安全态势 |
| 框架: | |
| 框架图 | 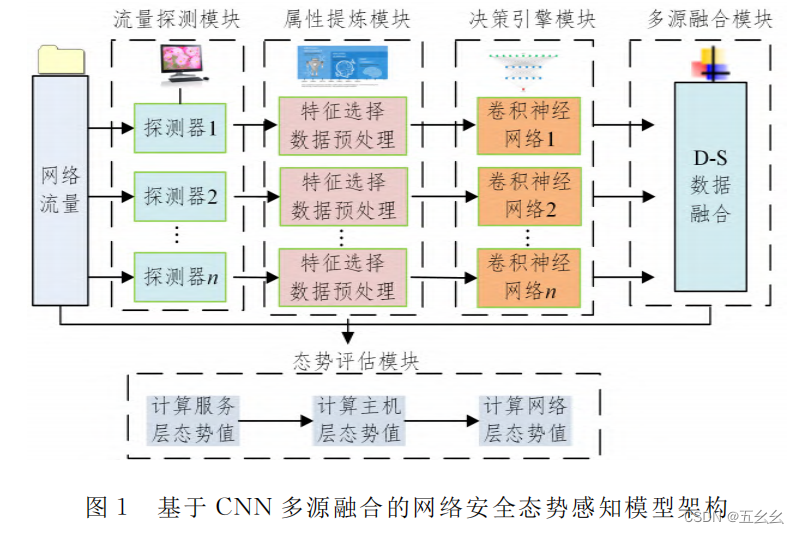 |
| 框架方法 | (1)流量探测,netflow手机流量包,并发送到指定的服务器上。suricata和snort利用规则匹配,检测恶意流量 (2)属性提炼,说了提取结果,但没有说提取的依据。数据预处理,数值化,归一化。 (3)CNN获取各类攻击发生的概率。维度42维,较少,加池化层效果不佳,所以没加池化层。两层全连接层。relu激活函数。 (4)多源融合,求第i种攻击的概率 m ( A i ) = ∏ x = 1 j m x ( A i ) w i , x ∑ i = 1 n ( ∏ x = 1 j m x ( A i ) w i , x ) m( A_{i})=\frac{\prod_{x=1}^{j}m_{x}\left ( A_{i} \right ) ^{w_{i,x}}}{\sum_{i=1}^{n}\left ( \prod_{x=1}^{j}m_{x}\left ( A_{i} \right ) ^{w_{i,x}} \right )} m(Ai)=∑i=1n(∏x=1jmx(Ai)wi,x)∏x=1jmx(Ai)wi,xj是证据源数目,n是攻击种类数目。公式的含义为收集所有证据源对第i种攻击的概率比上所有证据源对所有攻击的值。指数权值需要利用梯度下降算法迭代优化 (5)态势评估,根据snort对报警类型威胁等级划分的机理得到攻击威胁等级划分原则,利用权系数理论计算各类攻击的威胁值。 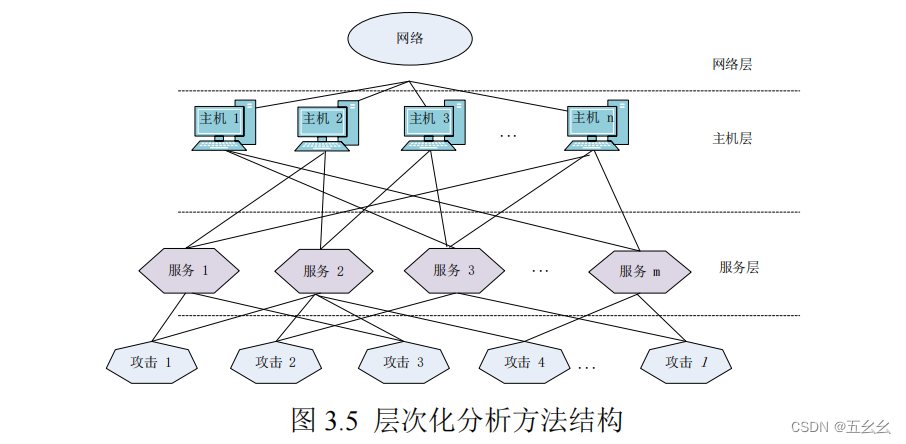 攻击威胁值与攻击概率与攻击次数->服务态势值。服务态势值与服务用户数量与服务使用频率->主机态势值。主机态势值与主机用户数量与主机使用频率->网络态势值 攻击威胁值与攻击概率与攻击次数->服务态势值。服务态势值与服务用户数量与服务使用频率->主机态势值。主机态势值与主机用户数量与主机使用频率->网络态势值 |
| 框架评价指标 | 准确率(ACC) 、误报率(FPR) 、漏报率(FNR) 和误警率(FAR) 作为衡量指标。 |
| 框架案例对象 | 本节实验选用的数据集有165925条,占总数据集的64.39%。 对经由属性提炼之后的数据集中的大样本Normal进行随机采样,其余样本类型进行全采样。训练集和测试集划分比例为 6:4,训练集 Normal 采样比例为 31.8%,测试集采样比例为 44.9%。,以5min作为一个时间窗口,共计112个时间窗口 |
| 实验结果: | |
| 收获论点(结论) | 决策级融合明显优于特征融合,特征融合优于各决策引擎的输出结果。决策级融合后攻击识别的准确率达到了 92.72%,攻击识别性能达到最优。 |
| 收获论据(消融实验图表) | 图7图8表4 |
| 收获论据(对比实验图表) | 表5 |
| 存在问题 | |
| 研究展望 | |
| 论文中有用的知识点 | |
| 启发 | 1可以通过缝合其他内容弄一个新的自编码器,然后换一个分类算法,就可以做评估了 |
| 看完论文的疑问 | |
| 句子积累 | 深入snort报警信息威胁等级划分机理,洞悉各类攻击原理,提炼威胁等级划分原则,以权系数理论量化威胁等级,采用层次化网络分析方法,客观高效地评估网络安全态势。 属性提炼坚持全面覆盖、聚焦恶意活动、有效数值化非数值特征、合理归一化数值特征的原则,构造有助于提升识别攻击类型的核心属性。 数据预处理主要包括非数值属性的数值化和数值属性的归一化。非数值属性的数值化包含两种常用的编码方式:One-HotEncoding和LabelEncoding。One-HotEncoding通常应用于类别之间没有顺序关系的特征;LabelEncoding通常应用于类别之间具有顺序关系的特征。基于本文非数值属性不存在显著性的顺序关系,采用One-HotEncoding 。 ReLU函数具有提升数据稀疏性、增强泛化能力、减轻参数依赖、防止梯度消失的优点。 前向传播:根据输入输出结果,计算与真实值之间的误差。反向传播:根据误差调整网络的参数 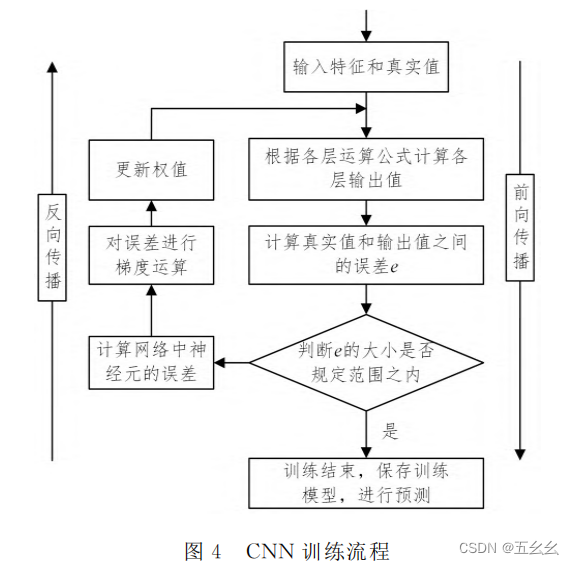 |