【数据结构】拆分详解 - 堆
文章目录
- 前言
- 一、堆是什么?
- 二、堆的接口实现(以小堆为例)
- 0.声明
- 1. 创建,初始化
- 2. 销毁
- 3. 插入
- 3.1 向上调整
- 4. 删除
- 4.1 向下调整
- 5. 获取堆顶元素值
- 6. 获取有效元素个数
- 7. 判断是否为空
- 三、两种建堆算法分析
- 1. 向上调整算法
- 2. 向下调整算法
- 3. 时间复杂度分析
- 总结
前言
文章细分了各个知识点,可在目录中快速跳转。
手机端用户在查看代码块时建议点击代码右上角放大查看,每一段代码均有完整注释。
本文介绍堆的定义及接口实现。如果对顺序表和二叉树还不熟悉的可以参考【数据结构】拆分详解 - 顺序表;树与二叉树
一、堆是什么?
- 定义:堆是二叉树的顺序存储结构。
本质上就是一个顺序表(数组),但逻辑上是一颗完全二叉树。就像人一样,我们都是人,但人与人之间差异明显,我们要关注的是堆的逻辑内在。需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
- 分类
- 大堆:任意一个父亲 <= 孩子(数值大小)
- 小堆: 任意一个父亲 >= 孩子(数值大小)
- 性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值
- 堆总是一棵完全二叉树
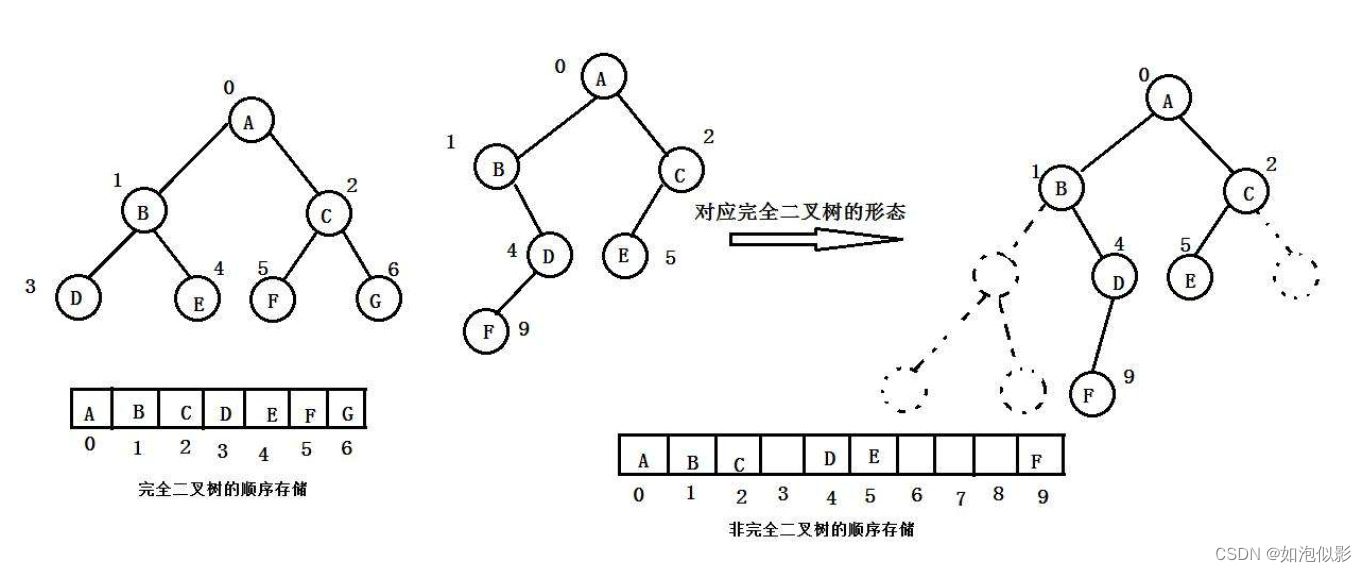
二、堆的接口实现(以小堆为例)
0.声明
typedef int HPDataType; //注释1
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP; //注释2
注释:
-
由于后期我们可能会改变结构体存储数据的类型,而一但更改,我们需要对每一个调用该类型的地方进行修改,十分麻烦,使用typedef对数据的类型进行重命名,这样以后要更换类型只需要更改此处就可以达到全文替换的目的。
-
重命名简便后续输入,注意我们为什么不直接命名简便一点呢?每个命名都是基于英文单词的释义,这样可以增加在多人协作,以及后续维护代码时的可读性。
1. 创建,初始化
void HeapInit(HP* php)
{
php->a = NULL;
php->size = 0;
php->capacity = 0;
}
2. 销毁
void HeapDestory(HP* php)
{
free(php->a);
php->a = NULL;
php->size = 0;
php->capacity = 0;
}
3. 插入
- 思路:
- 尾插
- 向上调整
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
//注意tmp只有在需要扩容时才会创建,赋值a应该放在分支内,否则会在不需要扩容时出问题
php->a = tmp;
php->capacity = newcapacity;
}
php->a[php->size] = x;
php->size++;
AdjustUp(php->a, php->size - 1);
}
3.1 向上调整
从下往上,找父亲,比较父亲与孩子的值大小,不符合堆的定义就进行调整(互换)
- 利用父亲与孩子的下标关系,找到当前孩子对应的父亲,比较调整
- 调整完继续向上找父亲的父亲,不断调整,直到找到根,或者符合堆的定义(父亲 >= 孩子 或 父亲 <= 孩子,本文以小堆为例,则为父亲 <= 孩子时停止)
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2; //完全二叉树数组实现性质:双亲与孩子的下标关系
//child == 0 结束,不论child为奇为偶,最后一次都是(1-1)/2 = 0,即找到根
while (child > 0)
{
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
child = parent;
parent = (parent - 1) / 2; //同上,下标关系
}
else //向上调整的前提是除了新插入的数据,其他部分为堆,因此只要找到符合的堆的父亲就可以跳出循环了
{
break;
}
}
}
4. 删除
- 目的性:之前我们所学的顺序表和链表没有很强的目的性,只是选择容易实现的方式进行接口实现,但我们应当认识到数据结构发明出来是有目的的,如堆可以进行堆排序,TopK问题(选出最大/最小的前K个数),如删除接口的实现,我们知道顺序表的尾删比较简单,时间复杂度低,但在堆中直接尾删会破坏子数的堆性质,使得结构混乱。堆的目的是为了对数据进行选择排序,子树不再为堆,后续排序也就无从谈起了。后续我们会讲解堆的应用,读者会更好的认识到这一点。
- 思路:
- 交换头尾
- 尾删
- 向下调整
void HeapPop(HP* php)
{
assert(php);
assert(php->size > 0);
swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
AdjustDown(php->a, php->size, 0);
}
4.1 向下调整
从上往下,找孩子,比较父亲与孩子的值大小,不符合堆的定义就进行调整(互换)
- 利用父亲与孩子的下标关系,找到当前父亲对应的孩子,比较调整
- 调整完继续向下找孩子的孩子,不断调整,直到遍历堆,或者符合堆的定义(父亲 >= 孩子 或 父亲 <= 孩子,本文以小堆为例,则为父亲 <= 孩子时停止)
void AdjustDown(HPDataType* a, int size, int parent)
{
//不知道父亲的左右孩子谁小,故假设法假设左孩子较小,若假设错误则调整为右孩子
int child = parent * 2 + 1;
while (child < size)
{
//右孩子较小就改为右孩子
if (a[child] > a[child + 1])
{
child++;
}
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
parent = child;
child = child * 2 + 1;
}
else
{
break;
}
}
}
5. 获取堆顶元素值
HPDataType HeapTop(HP* php)
{
assert(php);
assert(php->size > 0);
return php->a[0];
}
6. 获取有效元素个数
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
7. 判断是否为空
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
三、两种建堆算法分析
上文我们在堆插入和堆删除时分别粗略介绍、被动使用了向上调整和向下调整算法进行调整,是建立在原先就已经为堆的基础上,准确地说是左右子树均为堆的前提下。如果给一个数组,让你直接建堆,即左右子树不为堆的情况下,应该如何操作?
1. 向上调整算法
从上往下。从第二层往下遍历堆,将所有节点都访问一次进行向上调整。
2. 向下调整算法
从下往上。从倒数第一个非叶子节点所在层次开始向上,将所有节点都访问一次进行向下调整,直到访问到根节点。
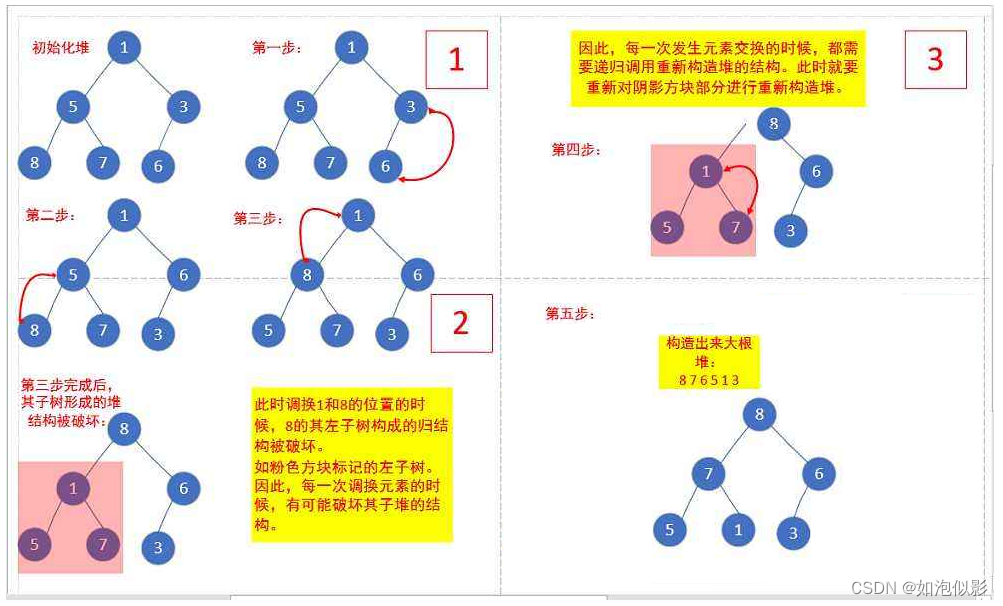
3. 时间复杂度分析
- 向下调整:
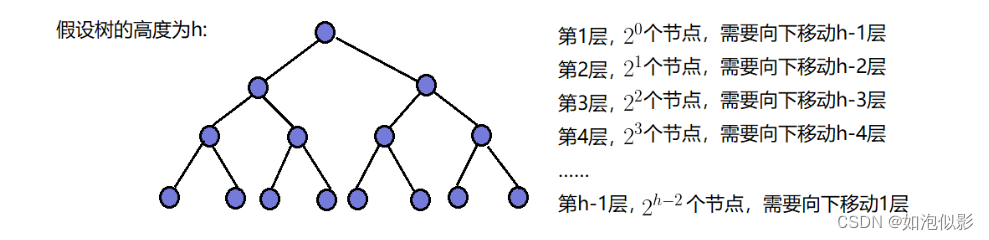
公式:【每层调整次数 = 节点数 * (倒数的层数-1)(即向下调整的次数)】
求和 :等差 * 等比 -> 错位相减
运算:
因此:建堆的时间复杂度为O(N)。
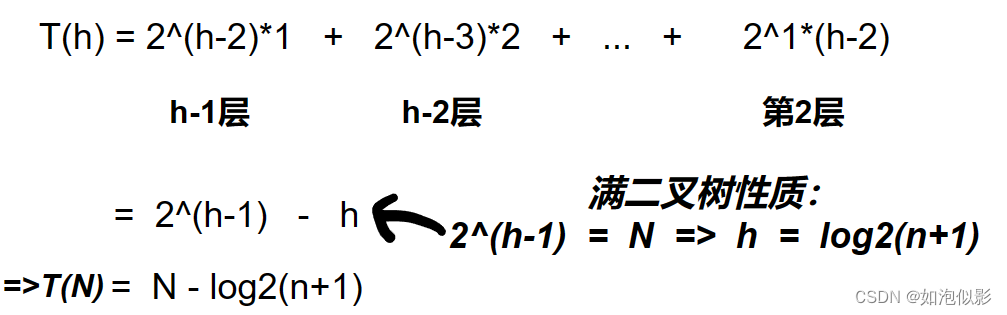
- 向上调整:
公式:【每层调整次数 = 节点数 * (层数-1)(即向上调整的次数)】
求和:等差 * 等比 => 错位相减
运算:
因此:建堆的时间复杂度为O(N*logN)。
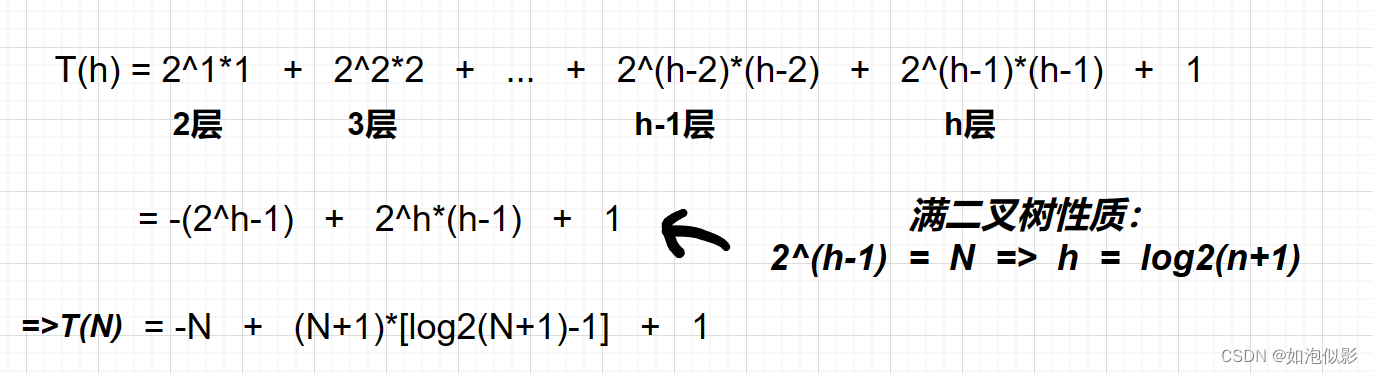
总结
知识逻辑框架可看文章开头的目录。
文章中有什么不对的丶可改正的丶可优化的地方,欢迎各位来评论区指点交流,博主看到后会一一回复。