自定义类型:结构体、联合、枚举
目录
一、⾃定义类型:结构体
1.结构体类型
1. 1结构体类型的声明
结构体变量的创建和初始化
1.2 结构的特殊声明
1.3 结构的自引用
2. 结构体内存对齐
①:对齐规则
②:offsetof函数
③:为什么存在内存对⻬?
④ 修改默认对⻬数
3. 结构体传参
4. 结构体实现位段
① 位段
② 位段的内存分配
③ 位段的跨平台问
⑤ 位段的应⽤与使⽤的注意事项
二、⾃定义类型:联合
1. 联合体类型的声明
2. 联合体的特点
编辑
3. 相同成员的结构体和联合体对⽐
4. 联合体⼤⼩的计算
5. 联合的⼀个练习
三、自定义类型:枚举类型
1. 枚举类型的声明
一、⾃定义类型:结构体
1.结构体类型
1. 1结构体类型的声明
struct tag { member-list; }variable-list;例如描述⼀个学⽣:
struct Stu { char name[20];//名字 int age;//年龄 char sex[5];//性别 char id[20];//学号 }; //分号不能丢结构体变量的创建和初始化
#include <stdio.h> struct Stu { char name[20];//名字 int age;//年龄 char sex[5];//性别 char id[20];//学号 }; int main() { //按照结构体成员的顺序初始化 struct Stu s = { "张三", 20, "男", "20230818001" }; printf("name: %s\n", s.name); printf("age : %d\n", s.age); printf("sex : %s\n", s.sex); printf("id : %s\n", s.id); //按照指定的顺序初始化 struct Stu s2 = { .age = 18, .name = "lisi", .id = "20230818002", .sex = "⼥ printf("name: %s\n", s2.name); printf("age : %d\n", s2.age); printf("sex : %s\n", s2.sex); printf("id : %s\n", s2.id); return 0; }或者我们打印的时候,
按照 :printf("%s %d %s %s\n", s1.name,sl.age, s1.sex,s1.id);
1.2 结构的特殊声明
在声明结构的时候,可以不完全的声明。
⽐如: 匿名结构体类型(//匿名结构体类型 只能使用一次)
//匿名结构体类型 struct { int a; char b; float c; }x; struct { int a; char b; float c; }a[20], *p;上⾯的两个结构在声明的时候省略掉了结构体标签(tag)。
// 在上⾯代码的基础上,下⾯的代码合法吗?p = &x;如:int main() { p = &x;//? return 0; }程序运行,不可以;会报警,编译器认为两种不同、
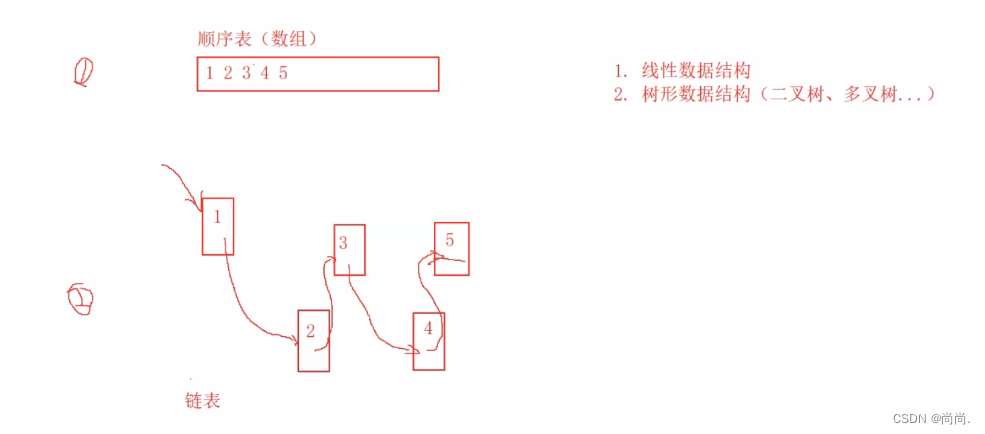
1.3 结构的自引用
在结构中包含⼀个类型为该结构本⾝的成员是不可以的。
链表的解释图:
⽐如,定义⼀个链表的节点:struct Node { int data;;//存放数据 struct Node next; };
这样是不正确的,因为⼀个结构体中再包含⼀个同类型的结构体变量,这样结构体变量的⼤⼩就会⽆穷的大,是不合理的。
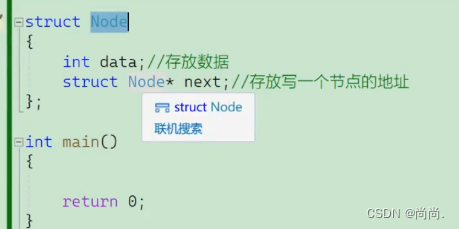
正确的自引用方式 :struct Node { int data;//存放数据 struct Node* next;//存放写一个节点的地址 };
在结构体⾃引⽤使⽤的过程中,夹杂了 typedef 对匿名结构体类型重命名,也容易引⼊问题,看看下⾯的代码,接下来的代码是不行的typedef struct { int data; Node* next;//Node先用了,但是重命名在他之后,并在这一步并没有重新完成重命名 }Node;Node先用了,但是重命名在他之后,在这一步并没有重新完成重命名
解决⽅案如下:定义结构体不要使⽤匿名结构体了typedef struct Node { int data; struct Node* next; }Node;
2. 结构体内存对齐
①:对齐规则
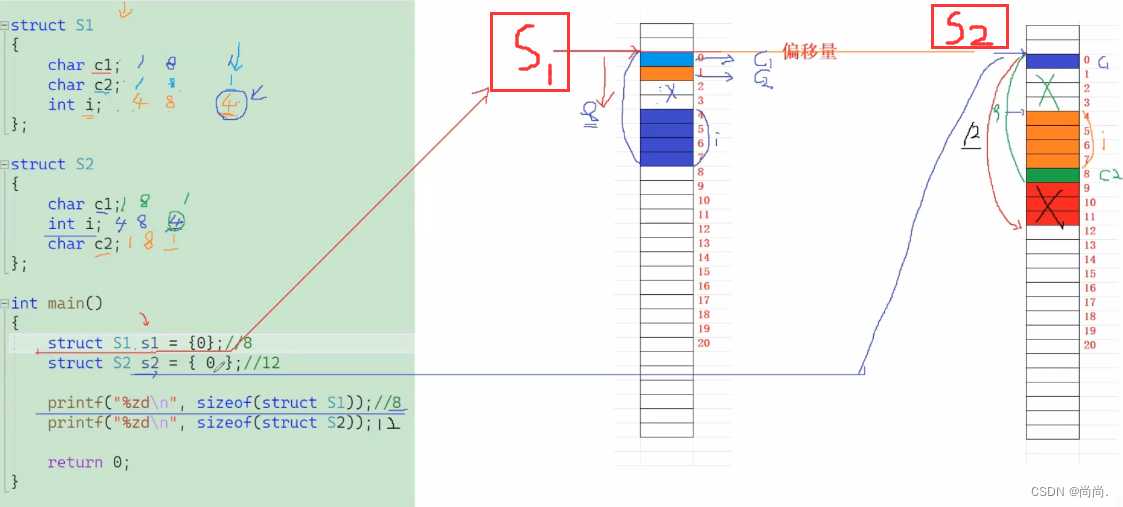
//练习1 struct S1 { char c1; int i; char c2; }; printf("%d\n", sizeof(struct S1)); //练习2 struct S2 { char c1; char c2; int i; }; printf("%d\n", sizeof(struct S2));
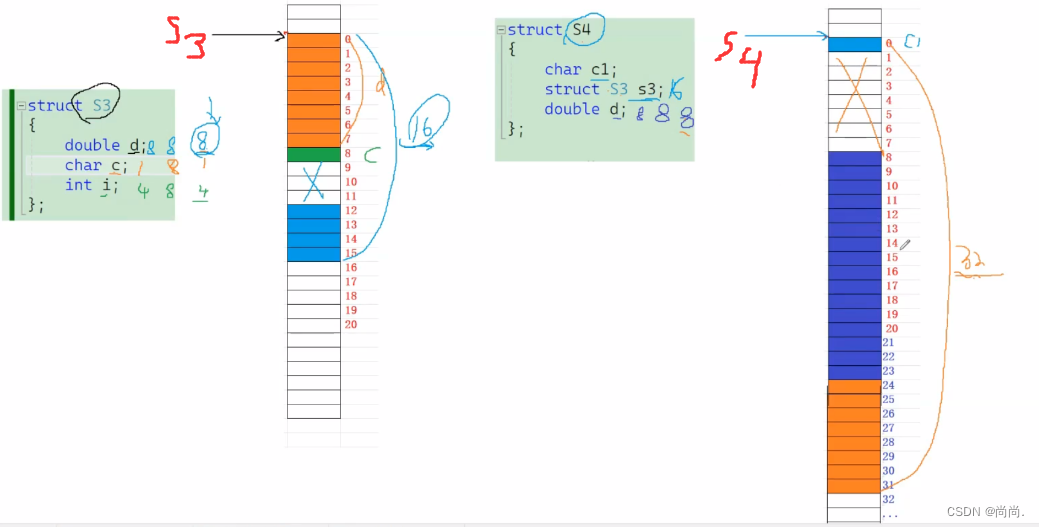
//练习3 struct S3 { double d; char c; int i; }; printf("%d\n", sizeof(struct S3)); //练习4-结构体嵌套问题 struct S4 { char c1; struct S3 s3; double d; }; printf("%d\n", sizeof(struct S4));
②:offsetof函数
//宏
//offsetof 计算结构体成员相较于起始位置的偏移量//头文件: #include <stddef.h>
计算一下s1个成员的偏移量:
再计算一下s4各成员的偏移量:
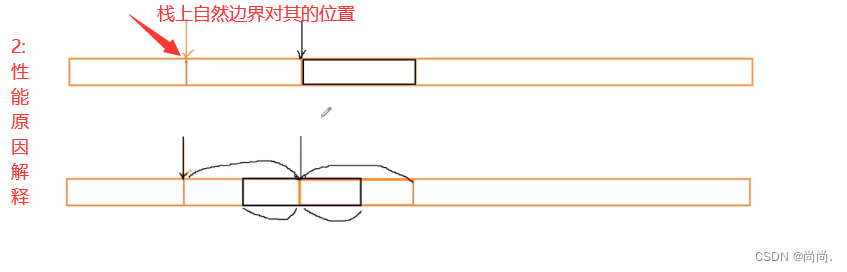
③:为什么存在内存对⻬?
⼤部分的参考资料都是这样说的:
那在设计结构体的时候,我们既要满⾜对⻬,⼜要节省空间,如何做到:让占⽤空间⼩的成员尽量集中在⼀起1 //例如: 2 struct S1 3 { 4 char c1; 5 int i; 6 char c2; 7 }; 8 9 struct S2 10 { 11 char c1; 12 char c2; 13 int i; 14 };S1 和 S2 类型的成员⼀模⼀样,但是 S1 和 S2 所占空间的⼤⼩有了⼀些区别。
④ 修改默认对⻬数
#pragma 这个预处理指令,可以改变编译器的默认对⻬数。
#include <stdio.h> #pragma pack(1)//设置默认对⻬数为1 struct S { char c1; int i; char c2; }; #pragma pack()//取消设置的对⻬数,还原为默认 int main() { //输出的结果是什么? printf("%d\n", sizeof(struct S)); return 0; }
结构体在对⻬⽅式不合适的时候,我们可以⾃⼰更改默认对⻬数
3. 结构体传参
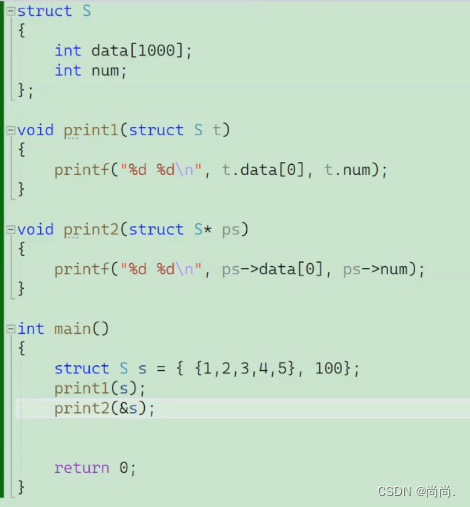
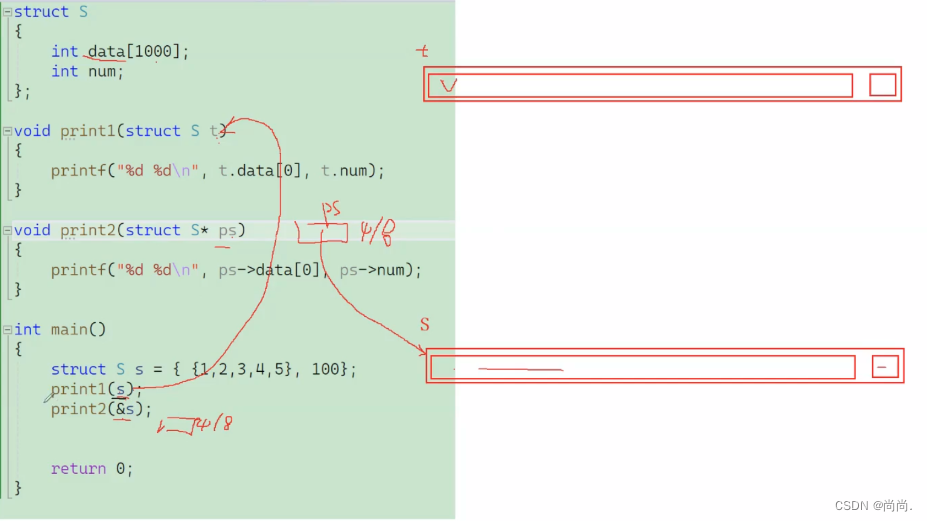
struct S { int data[1000]; int num; }; struct S s = {{1,2,3,4}, 1000}; //结构体传参 void print1(struct S s) { printf("%d\n", s.num); } //结构体地址传参 void print2(struct S* ps) { printf("%d\n", ps->num); } int main() {
print1 没有 print2 函数好⾸选print2函数。原因:函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递⼀个结构体对象的时候,结构体过⼤,参数压栈的的系统开销⽐较⼤,所以会导致性能的下 降。结论:结构体传参的时候,要传结构体的地址 。
4. 结构体实现位段
位段是基于结构体的,结构体拥有实现位段的能⼒。① 位段
⽐如:
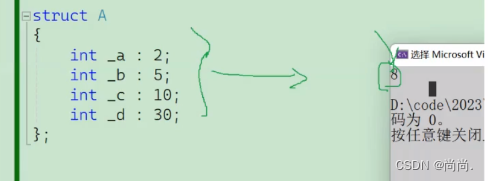
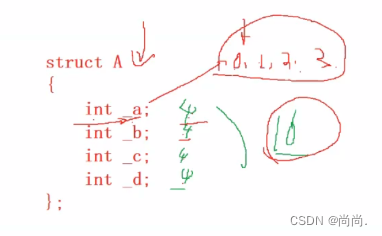
struct A { int _a:2;//2表示bit位为2 int _b:5;//bit位有5位 int _c:10; //2+5+10+30=47 一共47个比特位 int _d:30; //打印为8字节 }; //注意 //变量名: //1.数字、名称、下划线 //2.开头不能为数字
注意 :
变量名:
//1.数字、名称、下划线
//2.开头不能为数字我们打印:
printf("%d\n", sizeof(struct A));A就是⼀个位段类型。那位段A所占内存的⼤⼩是为8字节
对比一下正常情况,不用位段:
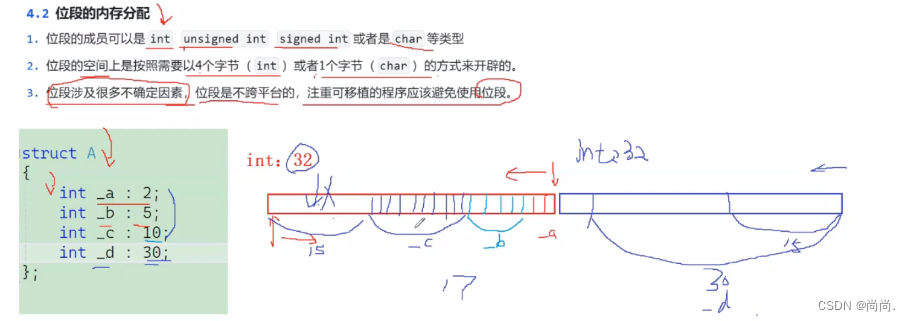
② 位段的内存分配
接下来的实现仅在vs情况下。
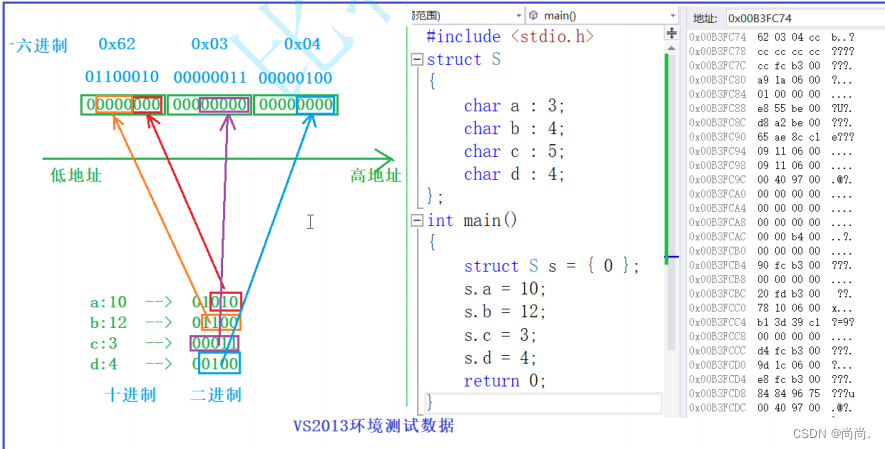
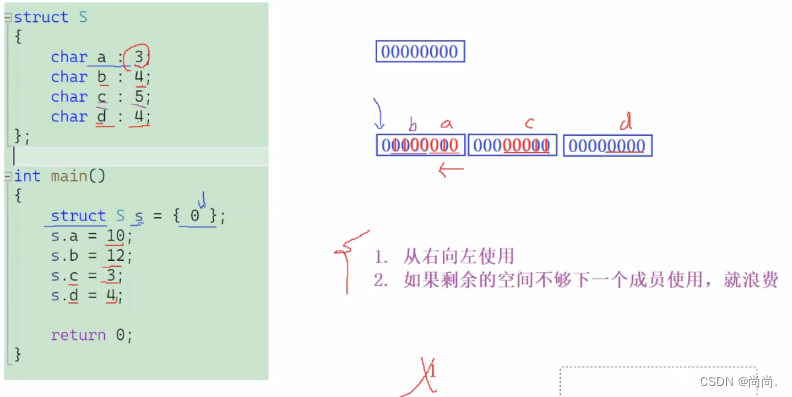
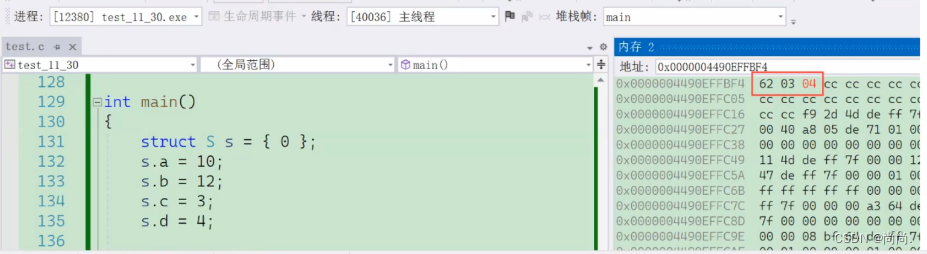
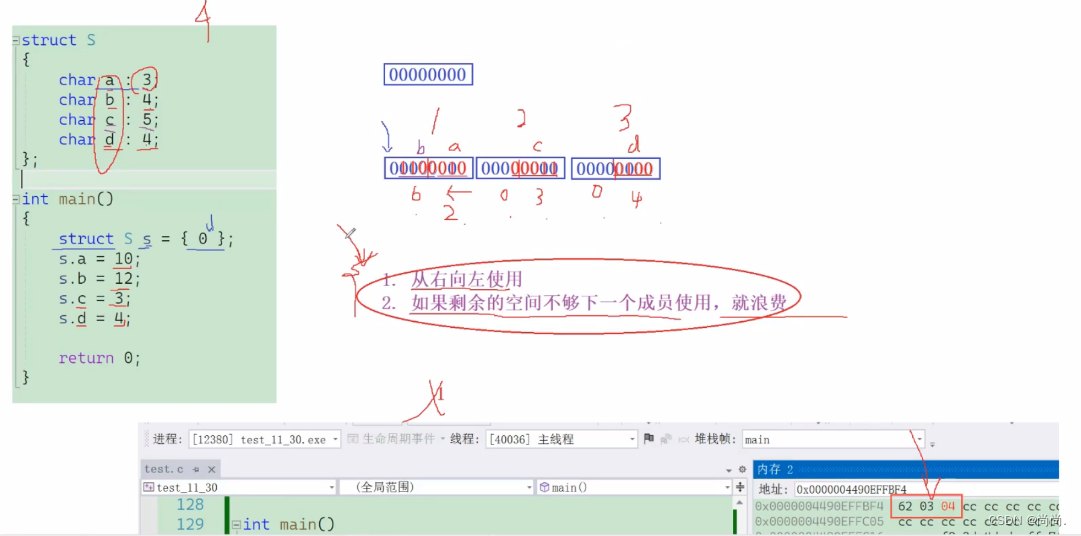
//⼀个例⼦ struct S { char a:3; char b:4; char c:5; char d:4; }; struct S s = {0}; s.a = 10; s.b = 12; s.c = 3; s.d = 4; //空间是如何开辟的?
我们再详细解释一下:
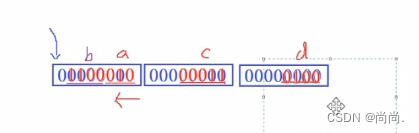
内存中的存储方式更显而易见:
③ 位段的跨平台问题
注意:
int - 4个字节 - 32bit
但是在16位的机器上
int - 2个字节 - 16bit⑤ 位段的应⽤与使⽤的注意事项
应用:下图是⽹络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要⼏个bit位就能描述,这⾥使⽤位段,能够实现想要的效果,也节省了空间,这样⽹络传输的数据报⼤⼩也会较⼩⼀些,对⽹络的畅通是有帮助的。 打印"呵呵"
打印"呵呵"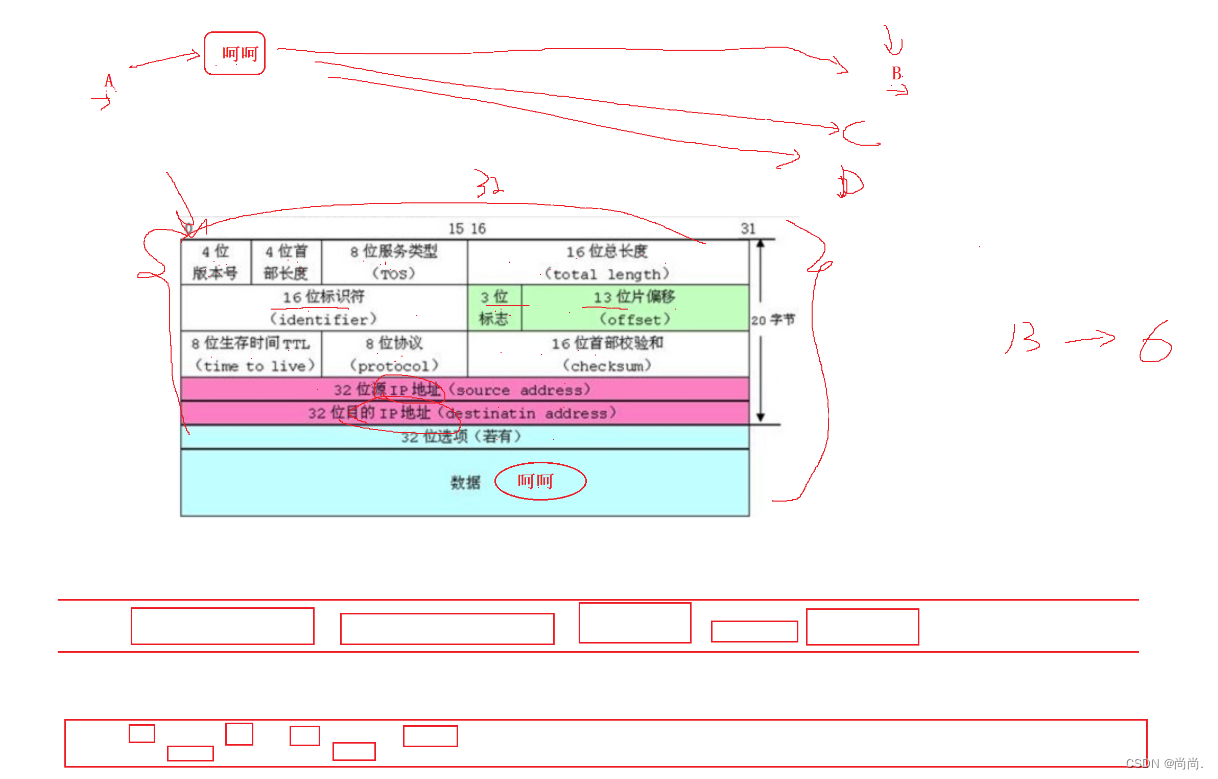 位段使⽤的注意事项:
位段使⽤的注意事项:
struct A { int _a : 2; int _b : 5; int _c : 10; int _d : 30; }; int main() { struct A sa = {0}; scanf("%d", &sa._b);//这是错误的 //正确的⽰范 int b = 0; //先初始化一个变量 scanf("%d", &b); //再赋值给它 sa._b = b; //再把这个变量赋值给它 return 0; }














二、⾃定义类型:联合
1. 联合体类型的声明
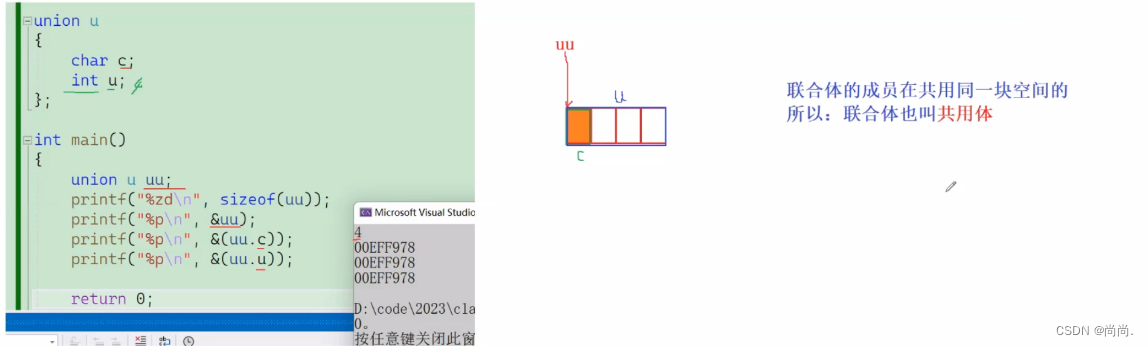
#include <stdio.h> //联合类型的声明 union Un { char c; int i; }; int main() { //联合变量的定义 union Un un = {0}; //计算连个变量的⼤⼩ printf("%d\n", sizeof(un)); return 0; }输出的结果:1 4
2. 联合体的特点
//代码1 #include <stdio.h> //联合类型的声明 union Un { char c; int i; }; int main() { //联合变量的定义 union Un un = {0}; // 下⾯输出的结果是⼀样的吗? printf("%p\n", &(un.i)); printf("%p\n", &(un.c)); printf("%p\n", &un); return 0; }输出的结果:001AF85C 001AF85C 001AF85C联合体的成员在共用同一块空间的所以: 联合体也叫共用体
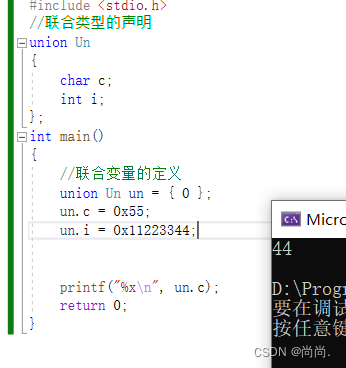
//代码2 #include <stdio.h> //联合类型的声明 union Un { char c; int i; }; int main() { //联合变量的定义 union Un un = {0}; un.i = 0x11223344; un.c = 0x55; printf("%x\n", un.i); return 0; }输出的结果:11223355代码1输出的三个地址⼀模⼀样,代码2的输出,我们发现将i的第4个字节的内容修改为55了。我们仔细分析就可以画出,un的内存布局图。
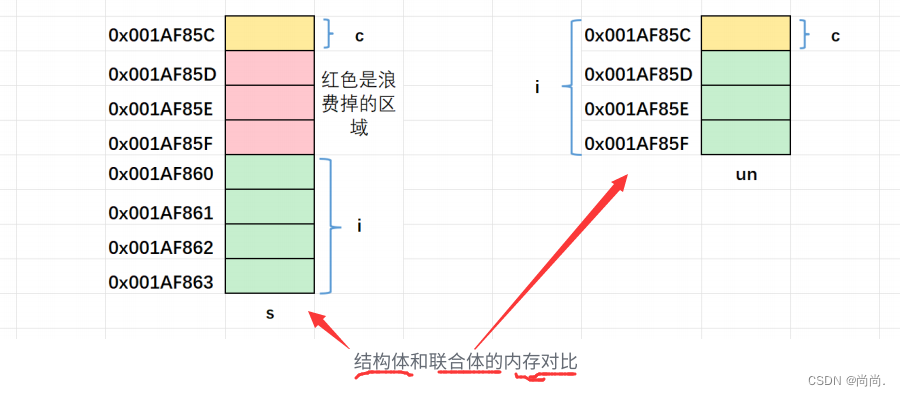
3. 相同成员的结构体和联合体对⽐
对⽐⼀下相同成员的结构体和联合体的内存布局情况。结构体:struct S { char c; int i; }; struct S s = {0};union Un { char c; int i; }; union Un un = {0};
4. 联合体⼤⼩的计算
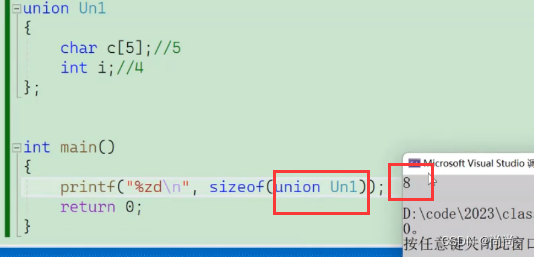
#include <stdio.h> union Un1 { char c[5]; int i; }; union Un2 { short c[7]; int i; }; int main() { //下⾯输出的结果是什么? printf("%d\n", sizeof(union Un1));//8 printf("%d\n", sizeof(union Un2));//16 return 0; }
使⽤联合体是可以节省空间的,举例:⽐如,我们要搞⼀个活动,要上线⼀个礼品兑换单,礼品兑换单中有三种商品:图书、杯⼦、衬衫。每⼀种商品都有:库存量、价格、商品类型和商品类型相关的其他信息。图书:书名、作者、⻚数杯⼦:设计衬衫:设计、可选颜⾊、可选尺⼨那我们不耐⼼思考,直接写出⼀下结构:struct gift_list { //公共属性 int stock_number;//库存量 double price; //定价 int item_type;//商品类型 //特殊属性 char title[20];//书名 char author[20];//作者 int num_pages;//⻚数 char design[30];//设计 int colors;//颜⾊ int sizes;//尺⼨ };
上述的结构其实设计的很简单,⽤起来也⽅便,但是结构的设计中包含了所有礼品的各种属性,这样使得结构体的⼤⼩就会偏⼤,⽐较浪费内存。因为对于礼品兑换单中的商品来说,只有部分属性信息是常⽤的。⽐如:商品是图书,就不需要design、colors、sizes。所以我们就可以把公共属性单独写出来,剩余属于各种商品本⾝的属性使⽤联合体起来,这样就可以介绍所需的内存空间,⼀定程度上节省了内存。struct gift_list { int stock_number;//库存量 double price; //定价 int item_type;//商品类型 union{ struct { char title[20];//书名 char author[20];//作者 int num_pages;//⻚数 }book; struct { char design[30];//设计 }mug; struct { char design[30];//设计 int colors;//颜⾊ int sizes;//尺⼨ }shirt; }item; };5. 联合的⼀个练习
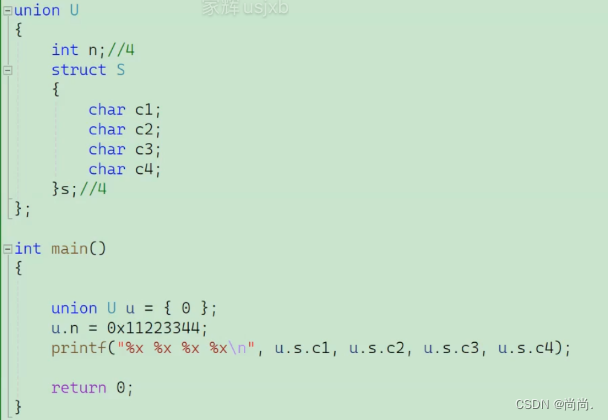
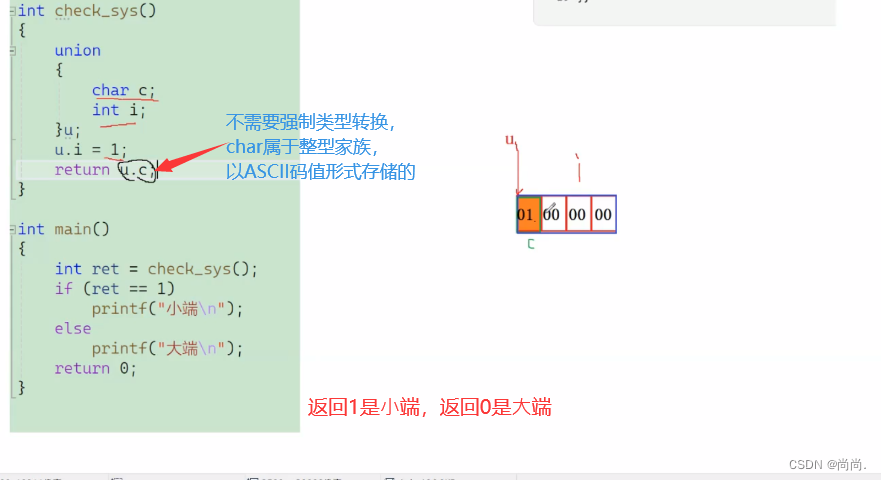
写⼀个程序,判断当前机器是⼤端?还是⼩端?int check_sys() { union { int i; char c; }un; un.i = 1; return un.c;//返回1是⼩端,返回0是⼤端 }
第一种方法:
第二种方法:





三、自定义类型:枚举类型
1. 枚举类型的声明