TCP 重传、滑动窗口、流量控制、拥塞控制
1:重传机制
超时重传

快速重传
SACK 方法

Duplicate SACK

1:重传机制
超时重传:重传机制的其中一个方式,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的ACK确认应答报文或者数据包丢失,
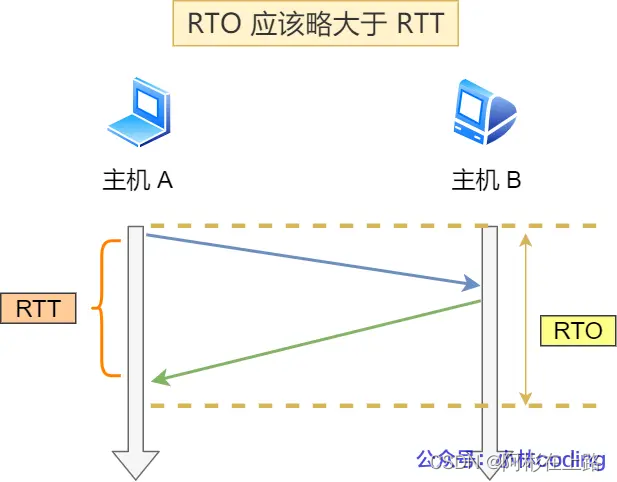
就会重发该数据,也就是我们常说的超时重传。超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
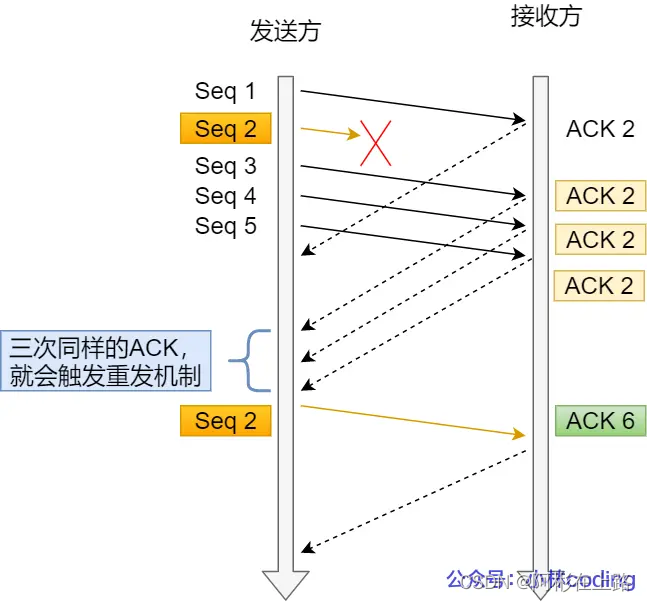
快速重传:不以时间为驱动,而是以数据驱动重传。工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传一个,还是重传所有的问题。
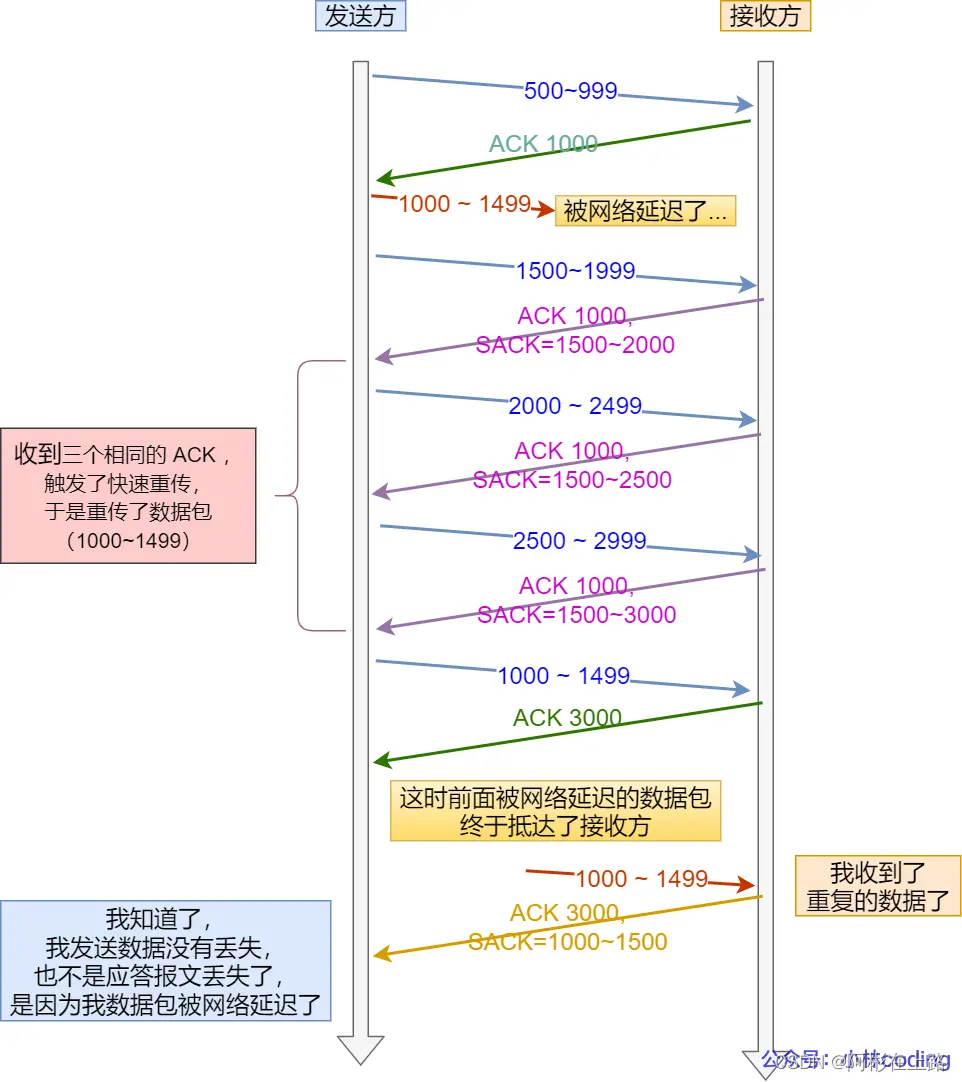
SACK(解决快速重传的缺点):在TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已收到的数据的信息发送给「发送方」。就可以只重传丢失的数据。
如果要支持 SACK,必须双方都要支持。在 Linux 下,可以通过 net.ipv4.tcp_sack 参数打开这个功能(Linux 2.4 后默认打开)。
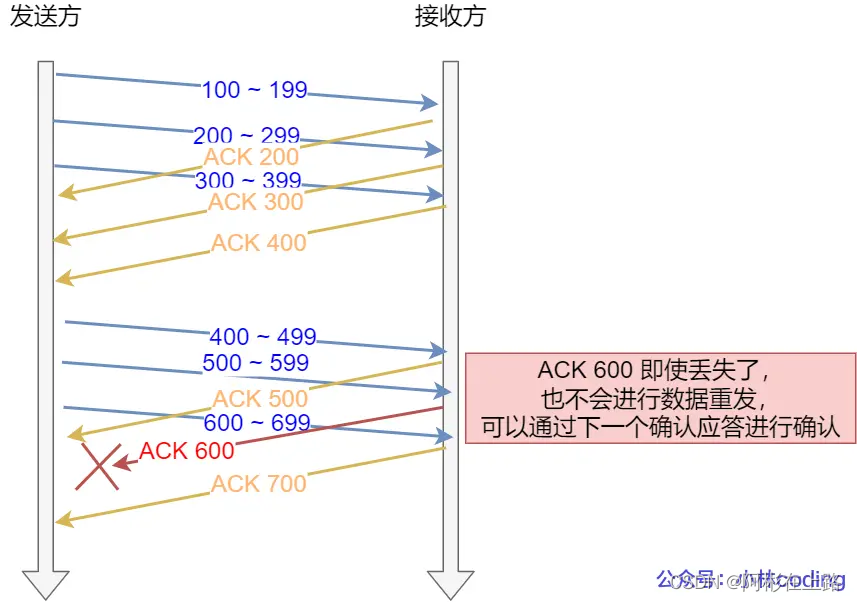
D-SACK:主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。D-SACK 有这么几个好处:
可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
可以知道是不是「发送方」的数据包被网络延迟了;
可以知道网络中是不是把「发送方」的数据包给复制了;
在Linux 下可以通过 net.ipv4.tcp_dsack 参数开启/关闭这个功能(Linux 2.4 后默认打开)。
2:滑动窗口
2:滑动窗口
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。TCP 头里有一个字段叫 Window,也就是窗口大小。
这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
3:流量控制
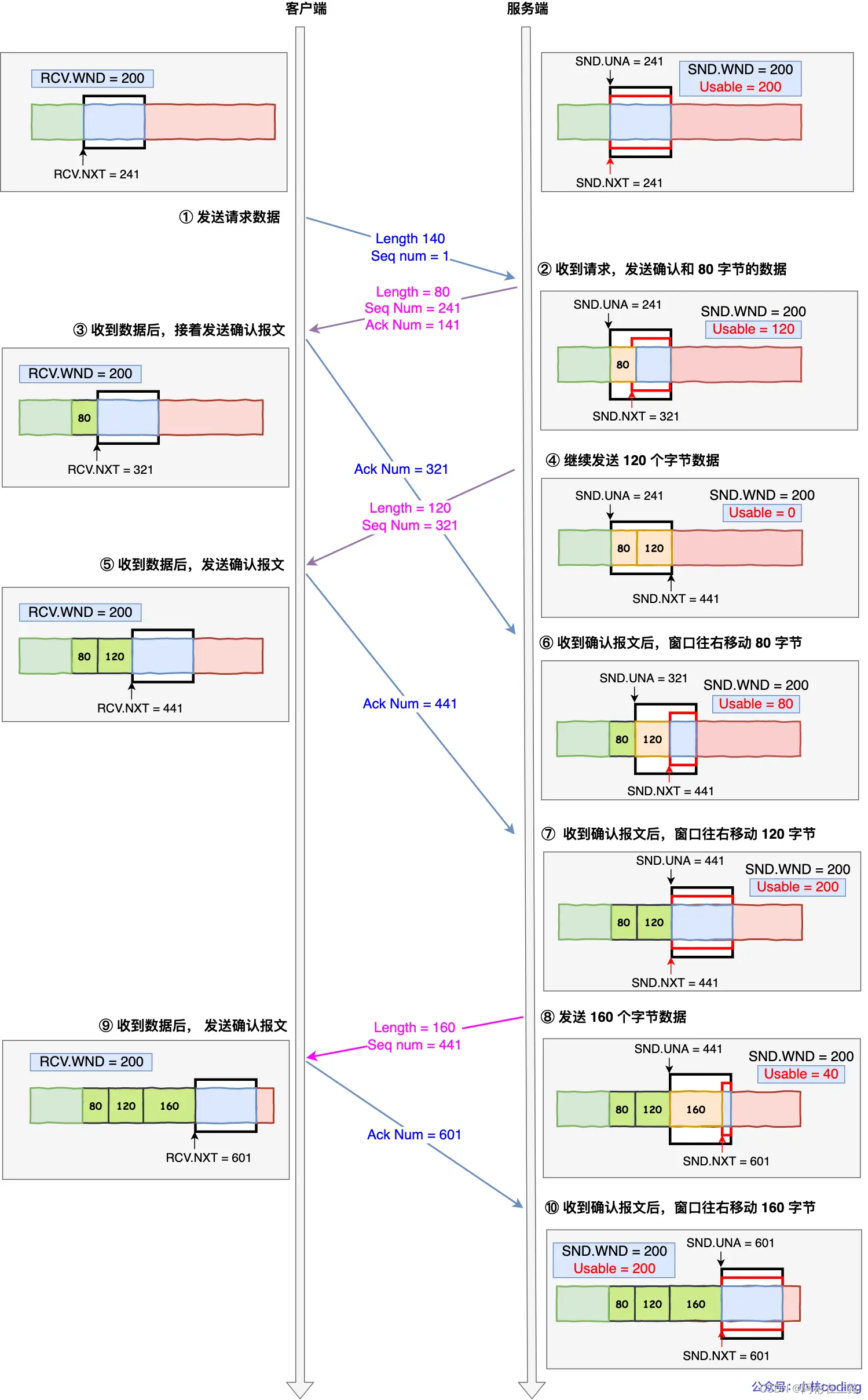
那操作系统的缓冲区,是如何影响发送窗口和接收窗口的呢?

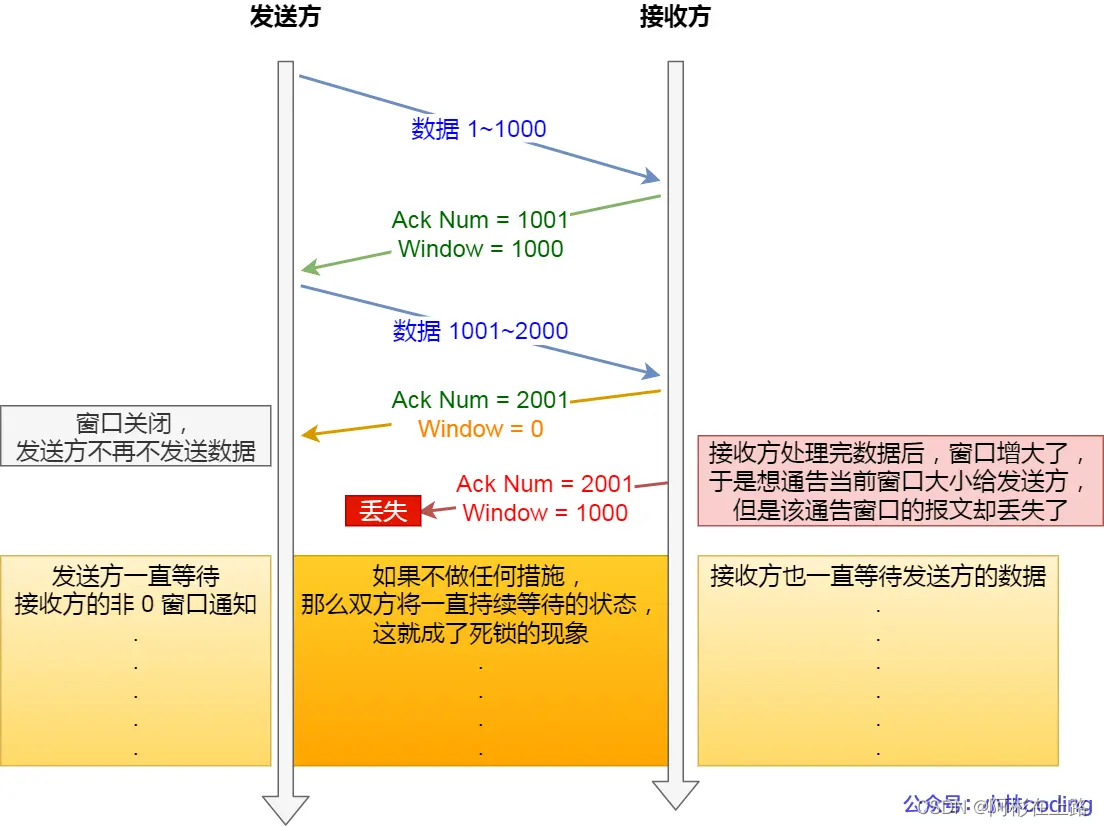
窗口关闭
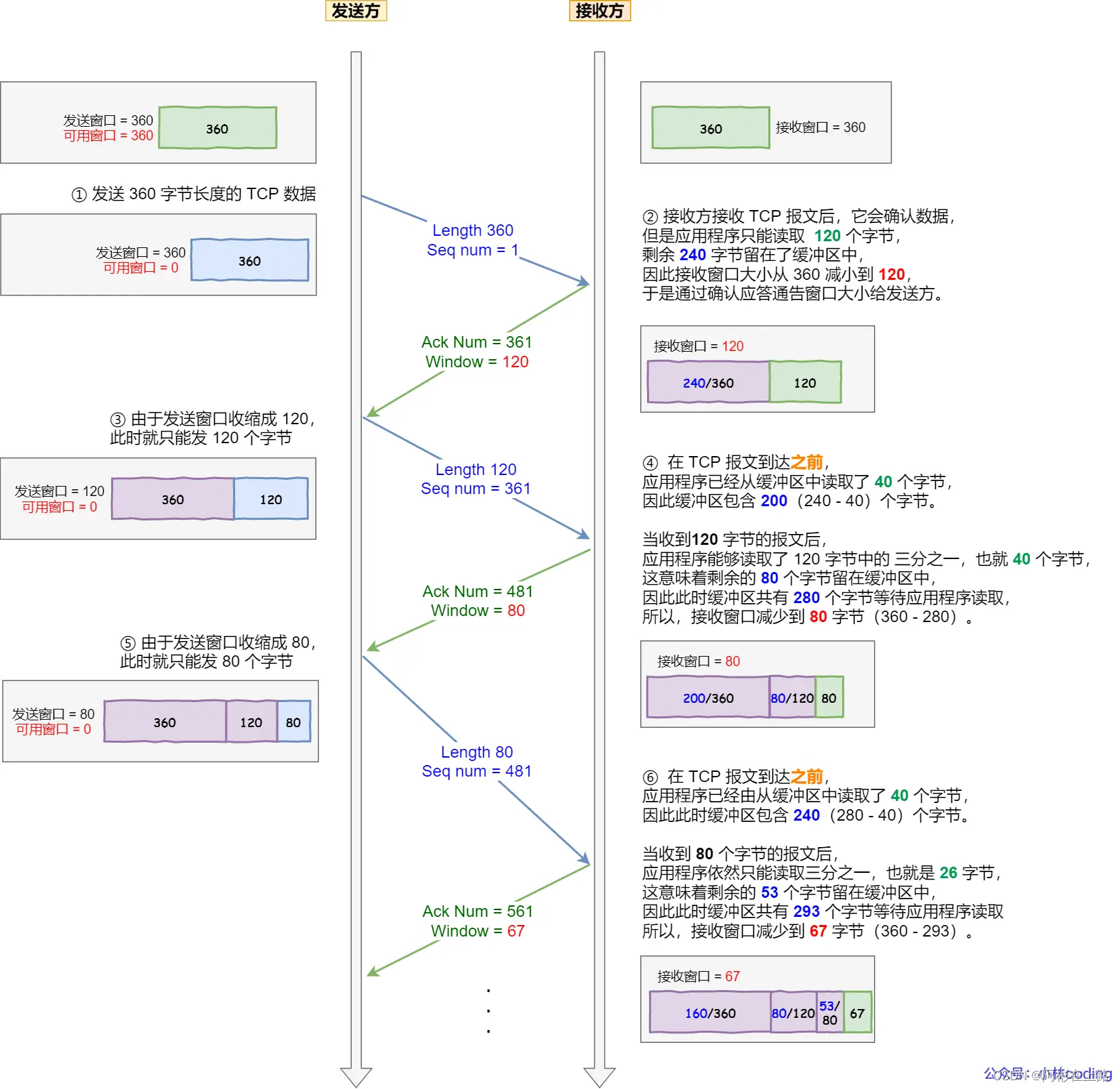
糊涂窗口综合症
3:流量控制
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。
发送窗口和接收窗口中所存放的字节数,都是放在操作系统内存缓冲区中的,而操作系统的缓冲区,会被操作系统调整。
:如果发生了先减少缓存,再收缩窗口,就会出现丢包的现象
为了防止这种情况发生,TCP 规定是不允许同时减少缓存又收缩窗口的,而是采用先收缩窗口,过段时间再减少缓存,这样就可以避免了丢包情况。
:如果窗口大小为 0 时,就会阻止发送方给接收方传递数据,直到窗口变为非 0 为止,这就是窗口关闭。
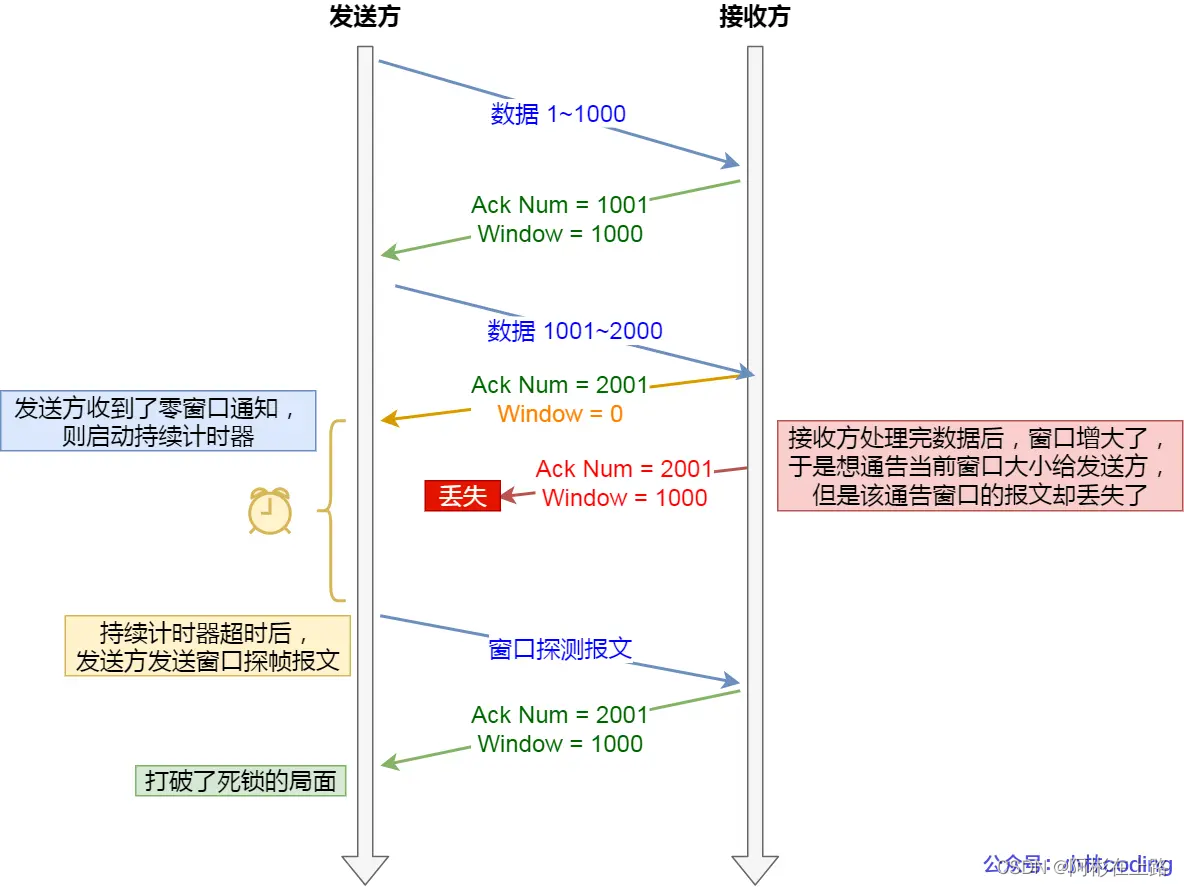
TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器。持续计时器超时,就会发送窗口探测报文。防止窗口关闭造成死锁。
糊涂窗口综合症(如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节,这就是糊涂窗口综合症。)
解决:让接收方不通告小窗口给发送方、让发送方避免发送小数据
4:拥塞控制
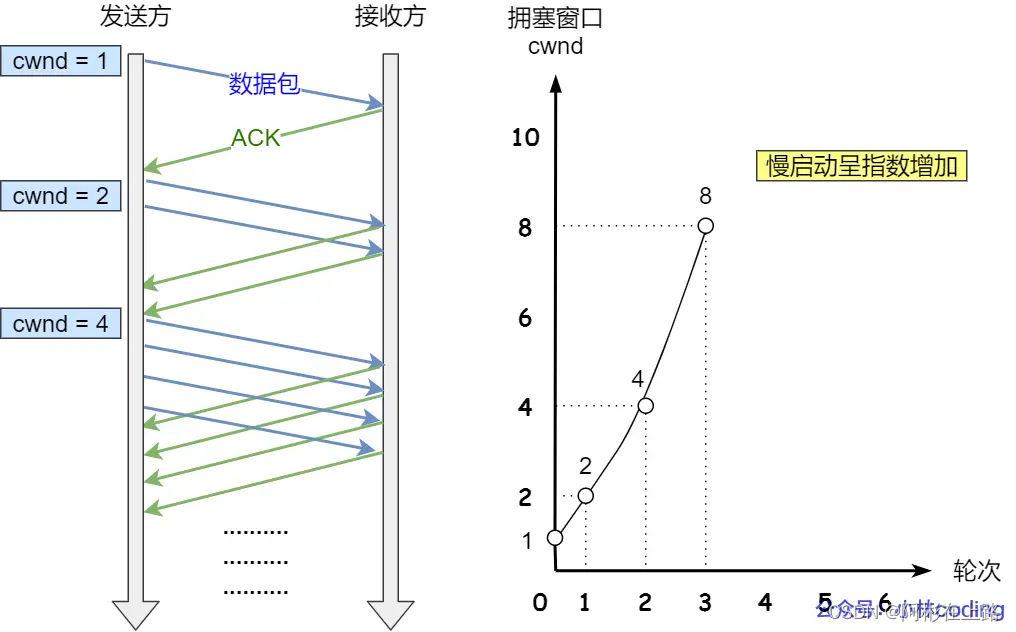
慢启动
拥塞避免算法
- 超时重传
快速重传和快速恢复算法一般同时使用
4:拥塞控制(控制的目的就是避免「发送方」的数据填满整个网络)
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大....
拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的
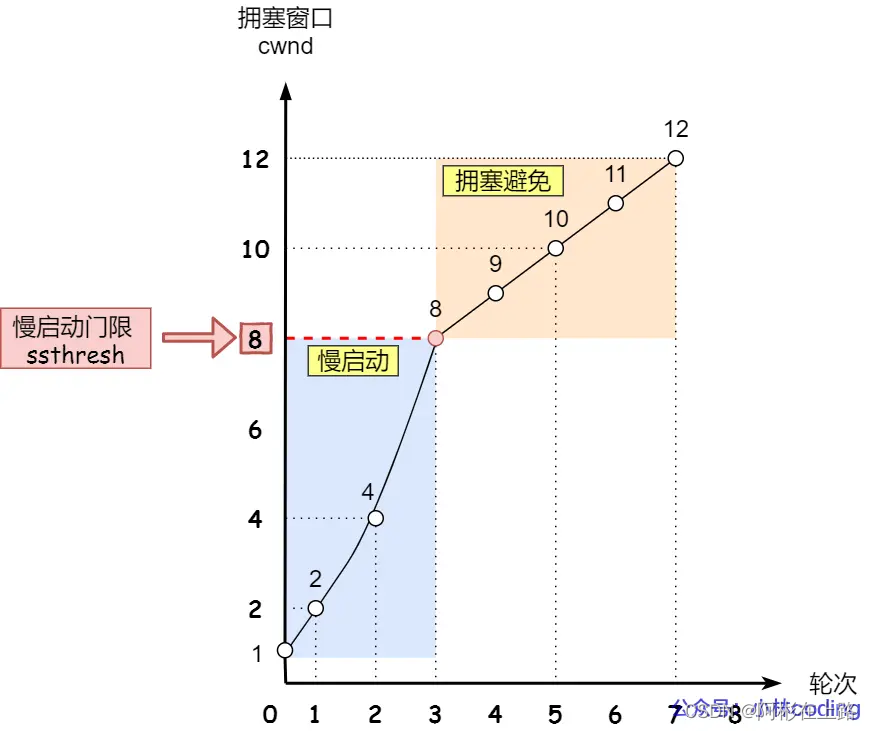
慢启动:cwnd < ssthresh时,当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1,指数性的增长
拥塞避免:cwnd >= ssthresh时,每当收到一个 ACK 时,cwnd 增加 1/cwnd,线性增长
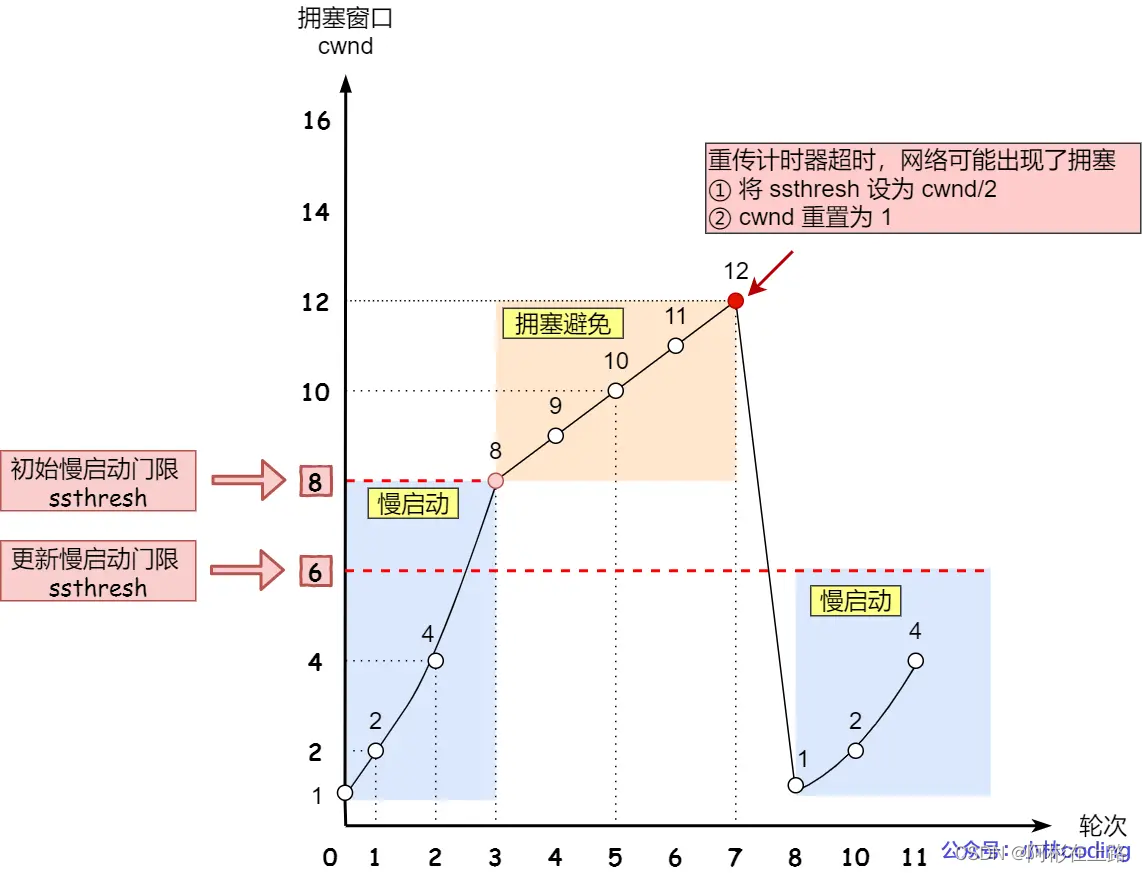
拥塞发生:超时重传,ssthresh 设为 cwnd/2、cwnd 重置为初始化值(ss -nli | grep cwnd)。快速重传,cwnd = cwnd/2、ssthresh = cwnd。
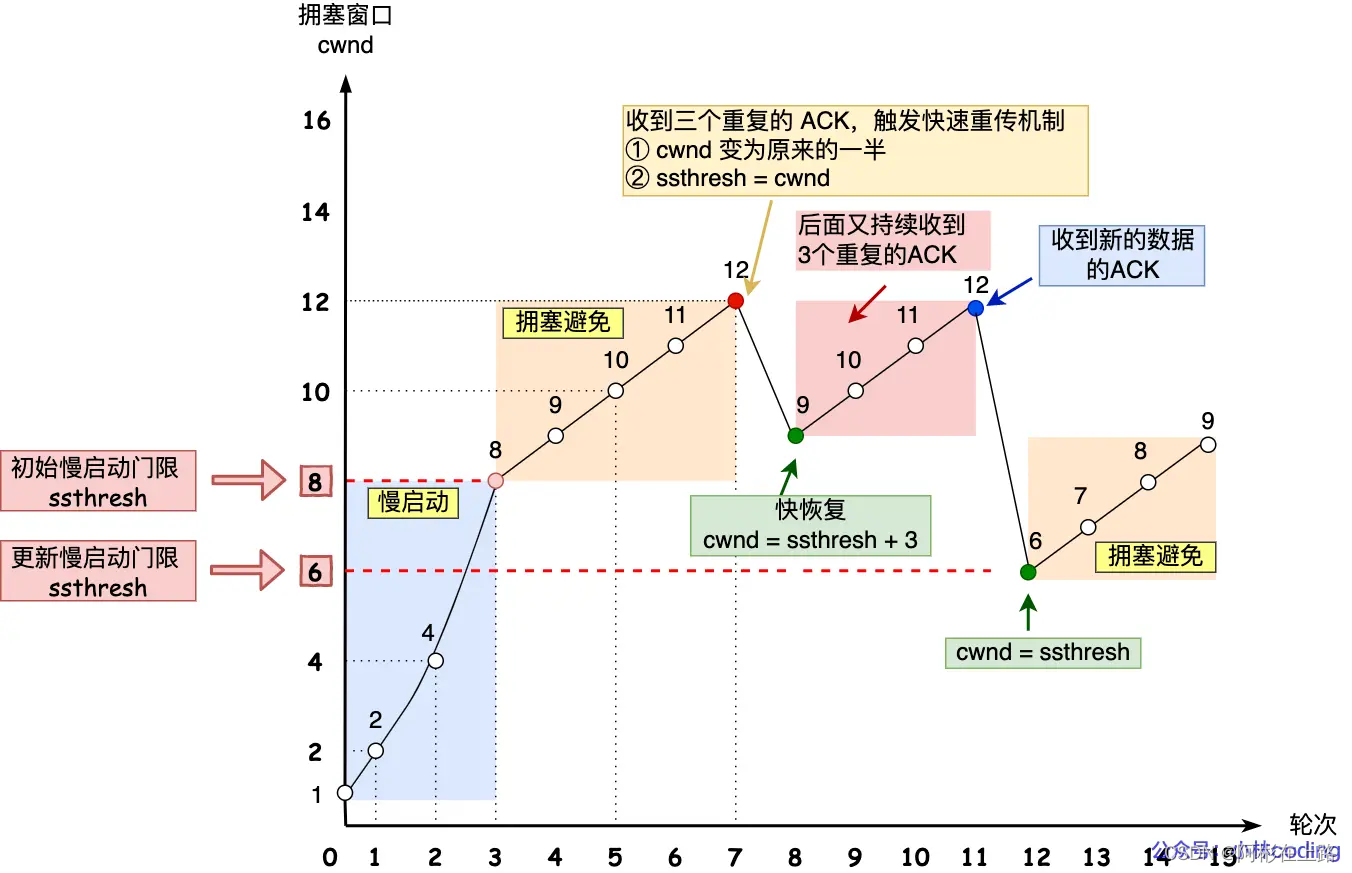
快速恢复:快速重传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈
cwnd = ssthresh + 3 、重传丢失的数据包、如果再收到重复的 ACK,那么 cwnd 增加 1、如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值
首先,快速恢复是拥塞发生后慢启动的优化,其首要目的仍然是降低 cwnd 来减缓拥塞,所以必然会出现 cwnd 从大到小的改变。
其次,过程2(cwnd逐渐加1)的存在是为了尽快将丢失的数据包发给目标,从而解决拥塞的根本问题(三次相同的 ACK 导致的快速重传),所以这一过程中 cwnd 反而是逐渐增大的