FLASK博客系列7——我要插入数据库
我们来继续上次的内容,实现将数据插入数据库。
我们先更改下models.py,由于上次笔误,把外键关联写错了。在这里给大家说声抱歉。不过竟然没有小伙伴发现。
models.py
from app import db
class User(db.Model): # 表名将会是 user(自动生成,小写处理)
id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 主键
name = db.Column(db.String(20)) # 用户名
# 给这个article模型添加一个author属性(关系表),User为要连接的表,backref为定义反向引用
# lazy表示禁止自动查询,后面可以直接操作这个对象。只可以用在一对多和多对多关系中,不可以用在一对一和多对一中
articles = db.relationship('Article', backref=db.backref('user'), lazy='dynamic')
class Article(db.Model):
# 也可以自定义表名
__tablename__ = 'article'
# id 主键 自增
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
# 文章标题 非空
title = db.Column(db.String(100), nullable=False)
# 文章正文 非空
content = db.Column(db.Text, nullable=False)
# 关联表,这里要与相关联的表的类型一致, user.id 表示关联到user表下的id字段
author_id = db.Column(db.Integer, db.ForeignKey('user.id'))
接着我们在根目录下创建一个scripts文件夹,用来存放我们一些脚本文件。在scripts文件夹下新建一个insert_sql.py,用来插入测试数据。
insert_sql.py
from app import db
from models import User, Article
def insert_data():
username = "clannadhh"
articles =[
{"title": "石正丽新研究:需持续监控蝙蝠", "detail": "石正丽新研究:需持续监控蝙蝠"},
{"title": "建议增设火车青年票", "detail": "建议增设火车青年票"},
{"title": "审议现场人大代表张伯礼哭了", "detail": "审议现场人大代表张伯礼哭了"},
{"title": "31省区市首次确诊病例0新增", "detail": "31省区市首次确诊病例0新增"},
{"title": "世界首个新冠疫苗人体临床数据", "detail": "世界首个新冠疫苗人体临床数据"},
]
# 新建一个用户
user = User(name=username)
db.session.add(user)
# 提交
db.session.commit()
# 从测试数据中添加文章。
for article in articles:
article_post = Article(author_id=user.id, title=article['title'], content=article['detail'], )
db.session.add(article_post)
# 提交
db.session.commit()
if __name__ == '__main__':
insert_data()
然后我们运行 python insert_sql.py ,测试数据来源于我们上节课的内容。
我们查看下article表,可以看到数据已经插入了。
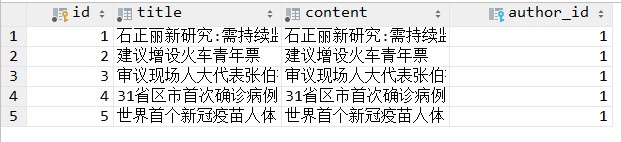
我们接着看下user表。可以看到新增了一个用户clannadhh。
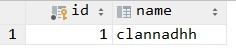
我们再更改下app.py
import os
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy # 导入扩展类
import models
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'blog.db')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app) # 初始化扩展,传入程序实例 app
@app.route('/')
def index():
user = models.User.query.first() # 查询第一个用户,因为我们只有一个用户
articles = models.Article.query.filter_by(author_id=user.id) # 根据用户ID查询文章
return render_template("article/list.html",
username=user.name,
articles=articles
)
if __name__ == '__main__':
app.run()
记得修改list.html。将 {{ article.detail}} 改为 {{ article.content }}。
接着打开链接 http://127.0.0.1:5000。可以看到文章渲染出来了。
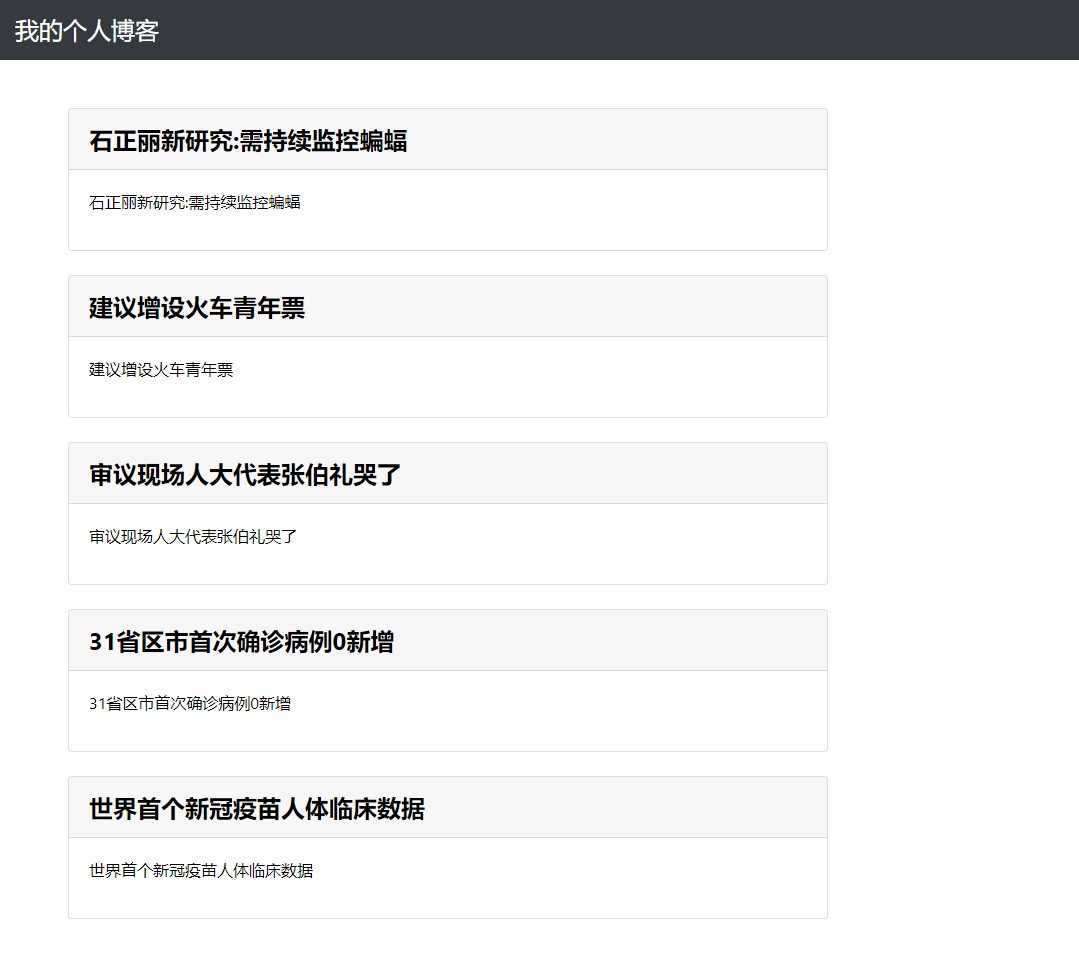
上面我们简单对数据库进行了操作,下面给大家送上一些基本操作的总结。
读取
>>>from models import User, Article # 导入模型类
>>>article = Article.query.first() # 获取Article模型的第一条记录
>>>article.user # 获取该文章的作者
<User 1>
>>>article.user.name # 获取该文章的作者的名字
'clannadhh'
>>>article.title # 获取文章标题
'石正丽新研究:需持续监控蝙蝠'
>>>article.content # 获取文章内容
'石正丽新研究:需持续监控蝙蝠'
>>>Article.query.all() # 查询所有的文章
[<Article 1>, <Article 2>, <Article 3>, <Article 4>, <Article 5>]
>>>Article.query.count() # 统计文章的数量
5
>>>Article.query.get(1) # 获取id为1的文章
<Article 1>
>>>Article.query.filter_by(author_id=1) # 查询用户id为1的文章
<flask_sqlalchemy.BaseQuery object at 0x000002889475BCC0>
>>>Article.query.filter_by(author_id=1).first() # 查询用户id为1的文章的第一条记录
<Article 1>
>>>Article.query.filter(Article.author_id==1).first() # 查询用户id为1的文章的第一条记录
<Article 1>下面是一些常用的过滤方法:
| 过滤方法 | 说明 |
| filter() | 使用指定的规则过滤记录,返回新产生的查询对象 |
| filter_by() | 使用指定规则过滤记录(以关键字表达式的形式),返回新产生的查询对象 |
| order_by() | 根据指定条件对记录进行排序,返回新产生的查询对象 |
| group_by() | 根据指定条件对记录进行分组,返回新产生的查询对象 |
下面是一些常用的查询方法:
| 查询方法 | 说明 |
| all() | 返回包含所有查询记录的列表 |
| first() | 返回查询的第一条记录,如果未找到,则返回None |
| get(id) | 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回None |
| count() | 返回查询结果的数量 |
| first_or_404() | 返回查询的第一条记录,如果未找到,则返回404错误响应 |
| get_or_404(id) | 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回404错误响应 |
| paginate() | 返回一个Pagination对象,可以对记录进行分页处理 |
今天的内容就到这里,想了解什么,记得给我留言。