Java研学-IO流(三)
六 字节流 – 字节输出流系列 OutPutStream体系
1 OutPutStream系列 – 字节输出流
// 表示字节输出流所有类的超类,输出流接受输出字节并将其发送到某个接收器
public abstract class OutputStream
FileOutputStream/BufferedOutputStream
2 FileOutputStream类设计
// 用于写入如图像数据的原始字节流,可实例化OutPutStream对象
public class FileOutputStream
// 当前路径下创建指定名字的文件
public FileOutputStream(String name)
// 例子
public class Test {
public static void main(String[] args) {
FileOutputStream fo=null;
try {
fo=new FileOutputStream("play2.txt");
// public void write(byte[] bs) 写入字节数组
// public void write(int b) 写入一个字节
// public void write(byte[] bs,int start,int len) 写入字节数组,自指定位置始写指定长度
fo.write(97); // a
fo.write("\r\n".getBytes()); // 换行
fo.write("这里是一段文字通过字符串转换".getBytes(),0,12);
// 这里是一 2字节1汉字
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fo!=null){
try {
fo.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
由于计算机中底层操作的都是字节数据,而OutputStream正好也是字节流,因此可以直接将数据写入到指定文件中,不需flush
3 BufferedOutputStream类设计 需flush
// 该类实现缓冲输出流,可直接向底层输入流写入字节
public class BufferedOutputStream
// 通过传递OutputStream实现类对象完成对文件的操作
public BufferedOutputStream(OutputStream out)
// 例子
public class Test {
public static void main(String[] args) {
BufferedOutputStream bo=null;
try {
bo=new BufferedOutputStream(new FileOutputStream("play.txt"));
bo.write(66);
bo.write("\r\n".getBytes());
bo.write("烤鸡翅膀我最爱吃".getBytes(),0,12);
// 烤鸡翅膀 1汉字2字节
bo.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(bo!=null){
try {
bo.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
BufferedOutputStream不能直接将数据写入到指定文件中,因为其操作的是缓存区,需要将数据刷新到指定的文件中:,建议使用BufferedOutputStream操作字节流可降低内存资源的消耗
七 字节流 – 字节输入流系列 InputStream体系
1 InputStream系列 – 字节输入流
// InputStream 类设计
Class InputStream
FileInputStream/BufferedInputStream
2 FileInputStream类设计
// 用于读取图像等数据的原始字节流
public class FileInputStream
// 打开与实际文件的链接创建FileInputStream文件,由name命名读取文件中的数据,可实例化 InputStream类对象
public FileInputStream(String name)
// 例子
public class Test {
public static void main(String[] args) {
FileInputStream fi=null;
try {
fi=new FileInputStream("play.txt");
int data=0;
byte[] bs=new byte[1024*5];
while ((data=fi.read(bs))!=-1){
System.out.println(new String(bs,0,data));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fi.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
一个汉字(包括数字)在UTF-8编码下占用3个字节,在GBK编码下占用2个字节。因此,如果4个汉字存储需要12个字节,那么可以推断出这些汉字是在UTF-8编码下存储的。具体存储方式是将每个汉字转换为UTF-8编码下的3个字节,共计12个字节存储。
3 BufferedInputStream类设计
// 直接操作缓存区降低内存消耗
public class BufferedInputStream
// 读取InputStream 参数实现类指定的文件,创建一个BufferedInputStream并保存其参数,内部缓冲区数组创建并存在buf
public BufferedInputStream(InputStream in)
// 例子
public class Test {
public static void main(String[] args) {
BufferedInputStream bi=null;
try {
bi=new BufferedInputStream(new FileInputStream("play.txt"));
int data=0;
byte[] bs=new byte[1024*5];
while ((data=bi.read(bs))!=-1){
System.out.println(new String(bs,0,data));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(bi!=null){
bi.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
字节流小结
字节流高效流(带有Buffered缓存技术的流),没有像字符流那样提供高效的方法(newLine()和readLine());定义字节高效流的原因,就是操作缓存区代替直接操作系统底层,降低系统资源消耗;
八 例子
将指定盘符下的指定文件,复制粘贴到指定的盘符
public class FC {
// 实现盘符下文件的读写操作,startName原文件名,endName目标文件名
public void copy(String startName,String endName){
// 分别定义两个字符高效流对象
BufferedReader start=null;
BufferedWriter end=null;
try {
// 分别实例化对象
start=new BufferedReader(new FileReader(startName));
end=new BufferedWriter(new FileWriter(endName));
String data=null;
while ((data=start.readLine())!=null){
// 读一行写一行
end.write(data);
end.newLine();
end.flush();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 防止start.close();出现异常导致end.close();无法关闭
// 关闭多个异常时需要分别关,关闭资源操作是没有顺序的
if (start!=null){
try {
start.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (end!=null){
try {
end.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
九 序列化
1 流转换
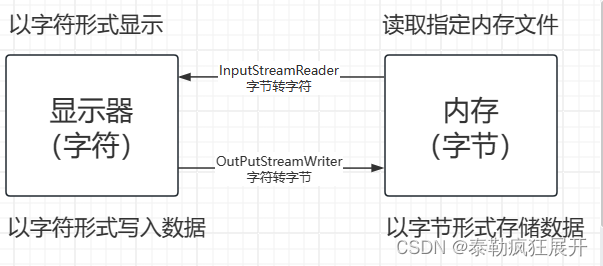
开发中可使用更高效的替代品
InputStreamReader – System.in — Scanner
OutPutStreamWriter – System.out.print()
2 序列化与反序列化
① 序列化:指使用指定的技术(OutputStream流,ObjectOutputStream类),将对象中的数据(通过对象调用方法获取的结果),存储到指定的文件中(也就是写的过程),或通过网络上传的过程
② 反序列化:将指定文件中或网络上的对象中的数据获取到(也就是读操作InputStream流,ObjectInputStream类)
// 创建序列化对象
public class Dog implements Serializable {
// 将序列化号固定为常量
private static final long serialVersionUID=1L;
// Serializable接口是一个声明接口,他没有任何抽象方法,但想实现序列化反序列化操作必须实现它
private String name;
private int kg;
public Dog(){
super();
}
public Dog(String name, int kg) {
super();
this.name = name;
this.kg = kg;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getKg() {
return kg;
}
public void setKg(int kg) {
this.kg = kg;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", kg='" + kg + '\'' +
'}';
}
}
// 序列化
public class DXTest {
public static void main(String[] args) {
// 声明序列化操作流对象
ObjectOutputStream oo=null;
try {
oo=new ObjectOutputStream(new FileOutputStream("play.txt"));
// 实例化需序列化的对象
Dog yellow = new Dog("大黄",24);
// public void writeObject(Object obj) 将序列化对象写入流中(需要flush)
oo.writeObject(yellow);
oo.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(oo!=null){
try {
oo.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("成功上传");
}
}
}
// 反序列化
public class DFTest {
public static void main(String[] args) {
// 声明反序列化对象
ObjectInputStream oi=null;
try {
oi=new ObjectInputStream(new FileInputStream("play.txt"));
// public Object readObject() 将文件中的对象读出来 序列化对象接收是Object因此需要强转
Dog yellow= (Dog) oi.readObject();
System.out.println(yellow.toString());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if(oi!=null){
try {
oi.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
上传数据(序列化),是将数据以字节码的形式存储到指定的文件中,打开文件之后,无法直接阅读,需要下载(反序列化)后才能阅读
在类的序列化过程中,如果添加新的属性,需要再次进行序列化和反序列化,这样同步操作才能不报错,如果一个没做,就会出现类无效异常 java.io.InvalidClassException
// 其中 stream classdesc serialVersionUID = 4216129340136042751 是本地读取类的序列化号
// local class serialVersionUID = 8800134341386811038 是本次已经存在的序列化号
java.io.InvalidClassException: com.Test.Dog; local class incompatible: stream classdesc serialVersionUID = 4216129340136042751, local class serialVersionUID = 8800134341386811038
读取就是反序列化操作;而已存在就是序列化操作,两个版本号不同就会出现异常
为了避免异常的出现,序列化后版本号进行固定;一般在实现序列化接口后,在类中(Dog类)将序列化号直接定义为常量