深度学习:什么是知识蒸馏(Knowledge Distillation)
1 概况
1.1 定义
知识蒸馏(Knowledge Distillation)是一种深度学习技术,旨在将一个复杂模型(通常称为“教师模型”)的知识转移到一个更简单、更小的模型(称为“学生模型”)中。这一技术由Hinton等人在2015年提出,主要用于提高模型的效率和可部署性,同时保持或接近教师模型的性能。
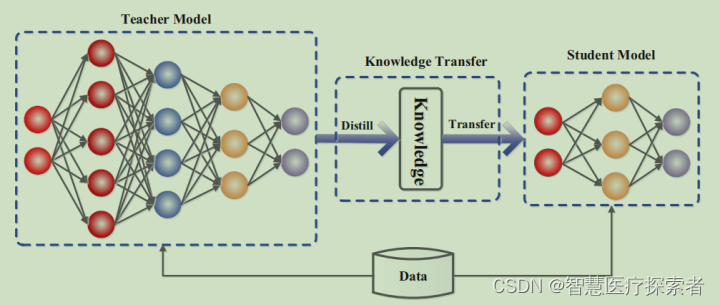
1.2 理论基础
-
教师-学生框架
教师模型: 通常是一个大型、复杂、训练良好的模型,能够提供高精度的预测。
学生模型: 相对较小、更易部署的模型,目标是学习教师模型的行为。
- 软标签
软标签的概念: 与硬标签(即传统的类别标签)不同,软标签包含了对每个类别的概率分布信息,通常由教师模型的输出构成。
信息丰富: 软标签提供了更多关于类别间关系的信息,有助于学生模型学习更细致的决策边界。
1.3 技术实现
- 训练过程
模型训练: 学生模型的训练既考虑了真实标签(硬标签),也考虑了教师模型的输出(软标签)。
损失函数: 通常包括两部分:一部分针对硬标签的传统损失(如交叉熵损失),另一部分针对软标签的损失(如KL散度)。
- 温度缩放
温度参数: 在计算软标签时引入温度参数,以调整类别概率分布的平滑程度。
作用: 通过温度缩放,可以调节教师模型输出的“软度”,有助于学生模型更好地学习。
1.4 实施步骤
知识蒸馏是一种将大型、复杂模型(教师模型)的知识迁移到小型、更高效模型(学生模型)的技术。这一过程主要涉及训练两个模型,并通过特定的方式传递知识。以下是实施知识蒸馏的主要步骤:
- 选择合适的教师模型
预训练大型模型: 选择或训练一个大型的、性能良好的模型作为教师模型。这个模型通常是深度网络,拥有较高的准确率。
- 设计学生模型
构建小型模型: 设计一个结构更简单、参数更少的学生模型。学生模型的目标是在保持较小规模的同时,尽可能模仿教师模型的输出。
- 准备训练数据
使用相同的数据集: 通常使用与训练教师模型相同的数据集来训练学生模型。
- 教师模型的软标签生成
获取软标签: 使用教师模型对训练数据进行预测,生成软标签。这些标签代表了教师模型对每个类别的预测概率分布。
- 学生模型的训练
蒸馏损失函数: 定义一个损失函数,结合教师模型的软标签和真实的硬标签。这个损失函数通常是硬标签的交叉熵损失和软标签的KL散度损失的组合。
训练学生模型: 使用上述损失函数训练学生模型,使其学习模仿教师模型的输出。
-
调整温度参数
温度缩放: 在计算软标签时,可以引入一个温度参数来调整类别概率分布的平滑程度,有助于学生模型更好地学习。
- 评估和优化
性能评估: 测试学生模型的性能,并与教师模型进行比较。
调整优化: 可能需要调整学生模型的架构或训练过程中的参数,以达到更好的蒸馏效果。
- 部署学生模型
模型部署: 将训练好的学生模型部署到目标平台,如移动设备、嵌入式系统等。
知识蒸馏的实施涉及精心设计的训练过程,目的是使简单的学生模型能够复制复杂教师模型的行为。这一技术特别适用于那些对模型大小和计算效率有严格要求的应用场景。通过知识蒸馏,可以在保持模型性能的同时,显著减少模型的大小和推理时间。
2 应用场景
知识蒸馏作为一种提高模型效率的技术,已被广泛应用于多种场景。其核心优势在于能够将大型复杂模型的知识迁移到更小的模型中,既保持了一定的性能,又提高了计算效率。以下是知识蒸馏的一些主要应用场景:
2.1 模型压缩和加速
-
移动和嵌入式设备: 在资源受限的设备上部署深度学习模型时,知识蒸馏可以用来压缩模型,减少模型的大小和计算要求,从而使其适用于移动设备、智能手机或IoT设备。
2.2 实时应用
-
视频监控和分析: 实时视频处理要求高速的模型推理。知识蒸馏可以将复杂的视频分析模型简化,实现快速处理。
-
游戏和交互式应用: 在游戏和实时交互应用中,需要快速响应的AI模型。通过知识蒸馏,可以使模型在保持高性能的同时具有较低的延迟。
2.3 资源节约
-
云计算和数据中心: 知识蒸馏有助于减少云服务和数据中心的计算负载,降低能耗和成本。
2.4 教育和研究
-
学术研究: 在教育和学术研究中,知识蒸馏可以用于教学和演示,特别是在计算资源有限的情况下。
2.5 医疗影像处理
-
快速诊断: 在医疗影像分析中,知识蒸馏有助于快速诊断,特别是在需要在设备上直接处理影像的场景。
2.6 自然语言处理
-
文本分析和机器翻译: 对于需要快速处理大量文本的应用,如机器翻译或情感分析,知识蒸馏可以优化模型以实现更高效的处理。
2.7 自动驾驶和机器人技术
-
快速决策: 自动驾驶车辆和机器人需要快速作出决策。知识蒸馏有助于简化决策模型,减少处理时间。
2.8 边缘计算
-
边缘设备上的AI: 对于需要在边缘设备上执行的AI任务,知识蒸馏可以减少对带宽和中心处理单元的依赖。
知识蒸馏作为一种有效的模型优化技术,能够在不牺牲过多性能的情况下显著提高模型的效率和实用性。它在移动部署、实时处理、资源节约等多个领域都有广泛应用,是深度学习领域的重要进展之一。
3 优势与挑战
3.1 优势
-
提高部署灵活性:
适应不同环境: 轻量级模型更适合于资源受限的环境,如移动设备。
-
保持性能:
接近原始性能: 即使模型规模缩小,学生模型的性能仍可接近甚至有时超过教师模型。
-
降低计算成本:
减少资源需求: 更小的模型意味着更低的内存占用和计算成本。
3.2 挑战
-
教师和学生模型的选择
模型匹配: 选择合适的教师和学生模型对知识蒸馏的成功至关重要。
-
调整蒸馏策略
策略优化: 需要调整蒸馏过程中的参数和策略以达到最佳效果。
-
处理不均衡和复杂数据
数据多样性: 面对复杂和不均衡的数据集时,蒸馏过程可能变得更加困难。
4 总结
知识蒸馏是深度学习领域的一项重要技术,它通过将大型模型的知识迁移到小型模型来实现模型压缩和性能优化。这一技术在模型部署、效率提升和隐私保护等方面展现出巨大的潜力。随着深度学习技术的不断发展,知识蒸馏在未来将在更多领域发挥重要作用。