CPU 使用率和负载Load
优质博文:IT-BLOG-CN
一、CPU 使用率
CPU使用率是 CPU处理非空闲任务所花费的时间百分比 。例如单核CPU 1s内非空闲态运行时间为0.8s,那么它的CPU使用率就是80%;双核CPU 1s内非空闲态运行时间分别为0.4s和0.6s,那么,总体CPU使用率就是(0.4s + 0.6s) / (1s * 2) = 50%,其中2表示CPU核数,多核CPU同理。CPU使用率只能在指定的时间间隔内测量。我们可以通过将空闲时间的百分比从100中减去来确定CPU使用率。
在
Linux中,进程分为三种状态,一种是阻塞的进程blocked process,一种是可运行的进程runnable process,另外就是正在运行的进程running process。

使用率这个要结合时间片来说,从上图的演变可以看出影响使用率高低的因素不是load的多少,而是在分配给某个进程时间片时,这个进程是否使用了CPU的计算能力。在第四分钟时候,分配给蓝人1分钟,但是它什么也没干,这1分钟内电话是闲置的没有被使用,所以这一分钟内的电话使用率就是0%。但是load是3。
当然这里就存在一个统计周期的问题,上图我们的统计周期是1分钟,而分配给每个人的最小时间单位也是1分钟。从计算机角度来说,单核心CPU,假设1秒钟分为100个时间片,如果2个任务,第一个任务用了5个时间片执行完成,另外一个任务用了15个时间片执行完成,所以如果统计周期是1秒,那么这1秒内的CPU使用率就是20%。CPU利用率高不一定负载高,CPU利用率是一段时间内CPU被占用的情况。
二、CPU Load
CPU负载定义为在单个时间点使用或等待使用一个内核的进程数。在单核系统,我们的CPU平均负载始终低于0.7。这表明每个需要使用CPU的进程都可以立即使用它,而无需等待。如果CPU平均负载大于1,则表示有进程需要使用CPU,但由于CPU不可用,目前无法使用。在多处理器系统中高于1的平均负载不会成为问题,因为有更多内核可用。
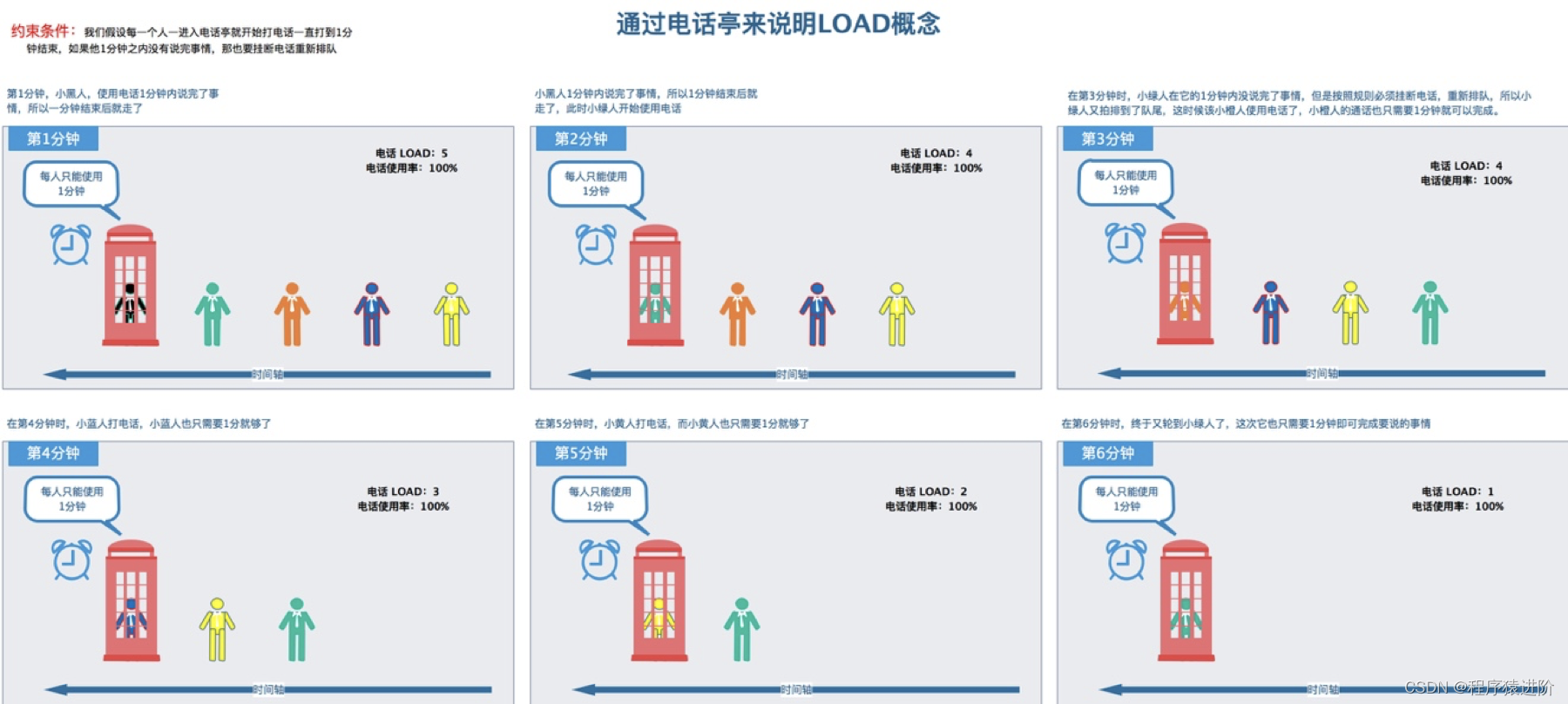
上图的电话亭可以理解为一个CPU核心。从上图的过程中可以看到load的概念,而使用率始终100%。
理想的CPU load是多少:这个跟你的CPU核心数量有关,理想情况下一个核心被一个进程占用,如果你是4个核心,那么跑4个进程,此时Load是4但是也不高,如果你只有2个核心,依然跑4个进程,这就意味着有一半进程在某一个时刻抢不到CPU,这时候Load还是4,如果是短期状态还无所谓,如果长期是这个状态你就要注意了。
一般来说只要每个CPU的当前活动进程数不大于3那么系统的性能就是良好的,如果每个CPU的任务数大于5,那么就表示这台机器的性能有严重问题。
三、CPU 使用率和负载常用命令
top命令查看CPU使用率
通常,top命令通常用于显示系统上的活动进程以及这些进程消耗了多少资源。不过,我们可以使用这个命令来测量CPU的状态:
[root@localhost ~]# top
top - 07:08:31 up 2:41, 1 user, load average: 1.09, 1.11, 1.30
Tasks: 322 total, 2 running, 320 sleeping, 0 stopped, 0 zombie
%Cpu(s): 10.0 us, 15.0 sy, 0.0 ni, 97.8 id, 0.0 wa, 5.0 hi, 0.0 si, 0.0 st
MiB Mem : 3709.4 total, 1483.1 free, 1402.0 used, 824.4 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 2053.4 avail Mem
参数说明:
【1】us(user):表示CPU在用户态运行的时间百分比,通常用户态CPU高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web服务器等;
【2】sy(sys):表示CPU在内核态运行的时间百分比(不包括中断),通常内核态CPU越低越好,否则表示系统存在某些瓶颈;
【3】ni(nice):表示用nice修正进程优先级的用户态进程执行的CPU时间。nice是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计CPU开销;
【4】id(idle):表示CPU处于空闲态的时间占比,此时,CPU会执行一个特定的虚拟进程,名为System Idle Process空闲时间;
【5】wa(iowait):表示CPU在等待I/O操作完成所花费的时间,通常该指标越低越好,否则表示I/O存在瓶颈,可以用iostat等命令做进一步分析;
【6】hi(hardirq):表示CPU处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行;
【7】si(softirq):表示CPU处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行;
【8】st(steal):表示CPU被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常;
【9】load average:表示CPU的平均负载,这3个数字分别表示1分钟、5分钟、15分钟内系统的平均负载。该值越小,表示系统工作量越少,负荷越低;反之负荷越高;
平均负载Load Average:指单位时间内,系统处于可运行状态(Running / Runnable)和不可中断态的平均进程数,也就是平均活跃进程数。
可运行态进程包括正在使用CPU或者等待CPU的进程;不可中断态进程是指处于内核态关键流程中的进程,并且该流程不可被打断。比如当进程向磁盘写数据时,如果被打断,就可能出现磁盘数据与进程数据不一致。不可中断态,本质上是系统对进程和硬件设备的一种保护机制。
理想情况下,每个CPU应该满负荷工作,并且没有等待进程,此时,平均负载 = CPU逻辑核数。但是,在实际生产系统中,不建议系统满负荷运行。通用的经验法则是:平均负载 = 0.7 * CPU逻辑核数。
1、当平均负载持续大于0.7 * CPU逻辑核数,就需要开始调查原因,防止系统恶化;
2、当平均负载持续大于1.0 * CPU逻辑核数,必须寻找解决办法,降低平均负载;
3、当平均负载持续大于5.0 * CPU逻辑核数,表明系统已出现严重问题,长时间未响应,或者接近死机。
除了关注平均负载值本身,也应关注平均负载的变化趋势,这包含两层含义。一是load1、load5、load15之间的变化趋势;二是历史的变化趋势。
1、当load1、load5、load15三个值非常接近,表明短期内系统负载比较平稳。此时,应该将其与昨天或上周同时段的历史负载进行比对,观察是否有显著上升。
2、当load1远小于load5或load15时,表明系统最近1分钟的负载在降低,而过去5分钟或15分钟的平均负载却很高。
3、当load1远大于load5或load15时,表明系统负载在急剧升高,如果不是临时性抖动,而是持续升高,特别是当load5都已超过0.7 * CPU逻辑核数时,应调查原因,降低系统负载。
如果1个CPU的系统平均负载=1.7:如果CPU每分钟最多处理100个进程,意味着除了CPU正在处理的100个进程以外,还有70个进程正排队等着CPU处理。2个CPU表明系统负荷可以达到2.0。
此外,需要注意的是,top命令显示了单个内核的CPU百分比。在多处理器系统中,CPU百分比可能超过100%。例如,如果4个核心为75%,top命令将显示CPU为300%。由于CPU有多种非空闲态,因此,CPU使用率计算公式可以总结为:CPU使用率 = (1 - 空闲态运行时间/总运行时间) * 100%。根据经验法则, 建议生产系统的CPU总使用率不要超过70%。
我们需要获取空闲时间的值,以便我们可以从100中减去它来获得使用情况:
[root@localhost ~]# top -bn2 | grep '%Cpu' | tail -1 | grep -P '(....|...) id,'|awk '{print "CPU Usage: " 100-$8 "%"}'
CPU Usage: 2.2%
-n选项是top命令在结束前应该使用的迭代次数。我们避免使用第一个循环,因为我们检索的指标将是自启动以来的值。因此,我们进行了第二次迭代。或者,在多处理器系统中,我们必须将给定的id值除以内核数,然后从100中减去该值。例如,如果我们在四核系统上运行,并且id值为304%,我们将CPU使用率计算为:
CPU 使用率 % = 100 – (304/4)
[root@localhost ~]# top -bn2 | grep '%Cpu' | tail -1 | grep -P '(....|...) id,'|awk '{print "CPU Usage: " 100-($8/4) "%"}'
vmstat命令查看CPU的使用率
[root@localhost ~]# vmstat 3 4
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 0 1347080 6120 941464 0 0 68 11 72 137 1 2 97 0 0
1 0 0 1347080 6120 941464 0 0 0 0 84 157 1 2 97 0 0
1 0 0 1347080 6120 941464 0 0 0 0 59 107 1 1 98 0 0
1 0 0 1347080 6120 941464 0 0 0 1 59 104 1 1 98 0 0
id列是我们感兴趣的。延迟一秒,我们使用vmstat计算CPU使用率:
[root@localhost ~]# echo "CPU Usage: "$[100-$(vmstat 1 2|tail -1|awk '{print $15}')]"%"
CPU Usage: 2%
没有提供任何参数的vmstat命令将给出自引导以来的CPU时间。这不会提供准确的CPU使用百分比。因此,参数只能是1和2,我们采用一秒钟后计算的指标:
vmstat 1 2
/proc/stat命令查看CPU使用率
CPU活动也可以从/proc/stat文件中提取。该文件包含自启动以来有关系统的各种指标:
[root@localhost ~]# cat /proc/stat
cpu 3020 28 1863 22404 35 432 47 0 0 0
cpu0 3020 28 1863 22404 35 432 47 0 0 0
intr 96468 28 100 0 0 0 0 0 0 1 0 0 0 1263 0 0 0 3696 0 153 928 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 207 0 41 14600 0 0 0 0 0 0 0 0 0 0 0 0 0 0 343 97 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ctxt 340950
btime 1628404433
processes 3276
procs_running 2
procs_blocked 0
softirq 112867 1 16857 56 269 510 0 261 0 0 94913
第一行,cpu是系统所有核心指标的聚合。在具有4个内核的系统上,将有4条cpu线——cpu0、cpu1、cpu2和cpu3。cpu行中的列表示处理不同任务所花费的时间:
【1】user在用户模式下花费的时间;
【2】nice在用户模式下处理 nice 进程所花费的时间;
【3】system执行内核代码所花费的时间;
【4】idl空闲时间;
【5】iowait等待I/O所花费的时间;
【6】irq服务中断所花费的时间;
【7】softirq服务软件中断所花费的时间;
【8】steal从虚拟机中窃取的时间;
【9】guest为来宾操作系统运行虚拟CPU所花费的时间;
【10】guest_nice为“不错的”客户操作系统运行虚拟CPU所花费的时间;
我们将使用这些指标来计算平均空闲百分比。随后,我们将使用计算值来计算CPU使用率。需要注意的是,较旧的Linux发行版不计算窃取、来宾或来宾_nice指标。如果我们使用的是旧系统,我们会在计算中忽略这些指标:
平均空闲时间 (%) = (idle * 100) / (user + nice + system + idle + iowait + irq + softirq +steal + guest + guest_nice)
cat /proc/stat |grep cpu |tail -1|awk '{print ($5*100)/($2+$3+$4+$5+$6+$7+$8+$9+$10)}'|awk '{print "CPU Usage: " 100-$1}'
CPU Usage: 2.4219
由于我们正在开发单核系统,因此cpu行将与cpu1相同。因此,tail -1的使用是 只检索其中一行。然而,我们会在多处理器系统上使用cpu行,因为它是所有内核上的指标的集合。
uptime查看平均负载
uptime命令为我们提供了以1、5和15分钟为间隔的平均负载视图:
[root@localhost ~]# uptime
12:40:05 up 2:29, 1 user, load average: 0.37, 0.08, 0.03
如果不知道系统的核心数,就无法解释平均负载:
[root@localhost ~]# cat /proc/cpuinfo |grep core
core id : 0
cpu cores : 2
四、总结
CPU利用率低负载高: 说明等待执行的任务很多,但是通常任务多CPU使用率也会比较高,如果低就说明CPU根本没工作,那些很多的任务处于等待状态,可能进程僵死了。
CPU利用率高负载低: 说明任务少,但是任务执行时间长,有可能是程序本身有问题,如果没有问题那么计算完成后则利用率会下降。
CPU 使用率与平均负载的关系: CPU使用率是单位时间内CPU繁忙程度的统计。平均负载不仅包括正在使用CPU的进程,还包括等待CPU或I/O的进程。因此,两者不能等同,有两种常见的场景如下所述:
【1】CPU密集型应用,大量进程在等待或使用CPU,此时CPU使用率与平均负载呈正相关状态。
【2】I/O密集型应用,大量进程在等待I/O,此时平均负载会升高,但CPU使用率不一定很高。
生产CPU使用率低而平均负载高的场景: 等待磁盘I/O完成的进程过多,队列长度大,导致负载高,但此时CPU被分配执行别的任务或空闲,具体如:
【1】磁盘读写请求过多导致大量I/O等待: CPU的工作效率要高于磁盘,而进程在CPU上面运行需要访问磁盘文件,这个时候CPU会向内核发起调用文件的请求,让内核去磁盘取文件,这个时候会切换到其他进程或者空闲,这个任务就会转换为不可中断睡眠状态。当这种读写请求过多就会导致不可中断睡眠状态的进程过多,从而导致负载高,CPU低的情况。
【2】数据库抖动: 造成线程队列hang住,负载升高。
【3】外接硬盘故障: 常见有挂了NFS,但是NFS server故障了。比如系统挂载了外接硬盘如NFS共享存储,经常会有大量的读写请求去访问NFS存储的文件,如果这个时候NFS Server故障,那么就会导致进程读写请求一直获取不到资源,从而进程一直是不可中断状态,造成负载很高。
Reference:
CPU load 过高问题排查
CPU 如何正确理解 CPU 使用率和平均负载的关系?