LLM推理部署(三):一个强大的LLM生态系统GPT4All

GPT4All,这是一个开放源代码的软件生态系,它让每一个人都可以在常规硬件上训练并运行强大且个性化的大型语言模型(LLM)。Nomic AI是此开源生态系的守护者,他们致力于监控所有贡献,以确保质量、安全和可持续维护性。
GPT4All软件旨在优化运行在笔记本电脑、台式机和服务器CPU上的3-13亿参数的大型语言模型的推理性能。
GPT4All的软件生态系由以下部分组成:
-
gpt4all-backend:这是GPT4All的后端部分,维护并提供了一个通用的、性能优化的C API,专为运行具有多亿参数的Transformer解码器的推理而设计。这个C API可以被整合到许多高级编程语言中,如C++、Python、Go等。
-
gpt4all-bindings:这个部分包括实现C API的各种高级编程语言的GPT4All绑定。每个子目录都是一个绑定的编程语言。命令行界面(CLI)也包含在其中。
-
gpt4all-api:GPT4All API(初级开发阶段)公开了一些REST API端点,用于从大型语言模型中提取生成的输出和嵌入。
-
gpt4all-chat:GPT4All Chat是一个在macOS、Windows和Linux平台上运行的原生聊天应用程序。这是在常规硬件上运行本地、注重隐私的聊天助手的最佳方式。你可以在GPT4All网站上下载该应用程序,并在monorepo中查看其源代码。
GPT4All软件生态系兼容以下Transformer架构:
-
Falcon -
LLaMA(includingOpenLLaMA) -
MPT(includingReplit) -
GPT-J
你可以在官方网站或模型目录中查看支持的模型的完整列表。
GPT4All的模型是通过神经网络量化过程生成的。一般来说,一个具有多亿参数的Transformer解码器需要30+ GB的显存来执行一个前向传递。但大多数人并没有如此强大的计算机或使用GPU硬件的权限。因此,通过运行训练过的LLM经过量化算法,部分GPT4All模型能够在仅有4-8GB RAM的笔记本电脑上运行,从而让更多人能够使用。更大的模型可能需要更多的RAM。
所有使用这些架构进行训练的模型都可以被量化,并在所有GPT4All绑定和聊天客户端上本地运行。你还可以通过向gpt4all-backend贡献新的模型来扩大模型种类。
本地LLM的推理速度取决于两个因素:模型的大小以及作为输入的令牌数量。如果你想使用大于750个令牌的上下文窗口,你可能希望在GPU上运行GPT4All模型,因为大量的上下文提示可能会显著降低本地LLM的推理速度。GPT4All模型的本地GPU支持正在计划中。
关于推理性能:哪个模型最好?这个问题实际上取决于你的特定用途。LLM遵循指令的能力依赖于其训练的预训练数据的数量和多样性,以及LLM进行微调的数据的多样性、质量和准确性。GPT4All的目标是将最强大的本地助手模型带到你的桌面,而Nomic AI正在积极努力提升它们的性能和质量。
GPT4All Python Generation
GPT4All的Python生成API为您提供了与C/C++模型后端库的链接功能。源代码及本地构建指南可在此找到。
首先,您需要将GPT4All的Python包添加到您的项目中,可使用pip安装如下:
pip install gpt4all安装完毕后,您可以利用以下示例代码来生成文本:
from gpt4all import GPT4All
model = GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
output = model.generate("The capital of France is ", max_tokens=3)
print(output)除此之外,GPT4All还支持聊天模式,这可以通过重用既有的计算历史来优化本地LLM的对话交互。您可以使用GPT4All的chat_session上下文管理器进行与模型的对话会话:
model = GPT4All(model_name='orca-mini-3b.ggmlv3.q4_0.bin')
with model.chat_session():
response = model.generate(prompt='hello', top_k=1)
response = model.generate(prompt='write me a short poem', top_k=1)
response = model.generate(prompt='thank you', top_k=1)
print(model.current_chat_session)当在chat_session上下文中运行GPT4All模型时,模型将提供一个与聊天相关的提示模板,同时保留了先前对话历史的内部K/V缓存,从而提升了推理速度。
GPT4All的generate()函数接收以下参数:
-
prompt (str):作为模型的提示语。
-
max_tokens (int):生成的最大令牌数。
-
temp (float):模型的“温度”。值越大,生成的文本越有创意,但可能偏离事实。
-
top_k (int):在每次生成步骤中,从最可能的top_k个令牌中进行随机选取。设置为1以执行贪婪解码。
-
top_p (float):在每次生成步骤中,从总概率为top_p的最可能的令牌中进行随机选取。
-
repeat_penalty (float):对模型重复的惩罚。值越高,生成的文本重复程度越低。
-
repeat_last_n (int):指定在模型生成历史中应用重复惩罚的距离。
-
n_batch (int):并行处理的提示令牌数量。增加此值可以减少延迟,但会增加资源需求。
-
n_predict (Optional[int]):与max_tokens功能相同,主要为了向后兼容。
-
streaming (bool):如果设置为True,此方法将返回一个生成器,此生成器会在模型生成令牌时产生。
GPT4All还支持流式生成,您可以在生成时使用streaming = True参数与GPT4All的响应进行交互。当在聊天会话中流式传输令牌时,您需要手动处理聊天历史的收集和更新。
GPT4All Python Embeddings
GPT4All提供了使用CPU优化的对比训练的句子转换器生成不受长度限制的文本文档的高级嵌入的支持。这些嵌入的质量在众多任务上与OpenAI的相媲美。
首先,你需要安装GPT4All的Python包,具体操作如下,通过pip进行安装:
pip install gpt4all接下来,你可以按照下述示例代码来生成嵌入:
from gpt4all import GPT4All, Embed4All
text = 'The quick brown fox jumps over the lazy dog'
embedder = Embed4All()
output = embedder.embed(text)
print(output)若嵌入模型尚未安装,系统将自动完成下载。
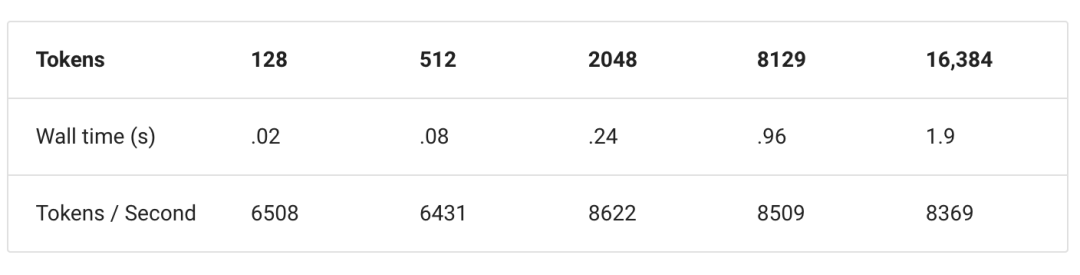
下表展示了嵌入生成的速度,这是在Intel i913900HX CPU上,采用DDR5 5600,运行8个线程以稳定负载状态下的文本文档生成速度:
参考文献:
[1] https://zhuanlan.zhihu.com/p/644426780
[2] https://github.com/nomic-ai/gpt4all
[3] https://docs.gpt4all.io/
[4] https://gpt4all.io/index.html