python@可变对象和不可变对象@按值传递和引用传递@python运行可视化工具
文章目录
- 可变对象和不可变对象🎈
- 可视化工具🎈
- 可变对象和id
- eg
- eg
- 变量名和内存地址🎈
- 函数调用对参数的修改😂
- Note
- 按值传递vs引用传递
- note🎈
- 如何借助函数修改外部变量的值?
- Note
可变对象和不可变对象🎈
-
在Python中,对象可以分为可变对象和不可变对象两种类型。
不可变对象:在创建后无法被修改的对象,例如数字、字符串、元组等。
可变对象:在创建后可以被修改的对象,例如列表、字典、集合等。
可变对象和不可变对象的区别主要在于它们的赋值和传递方式不同。对于不可变对象,赋值或传递时会创建一个副本,而对副本的修改不会影响原对象,例如:
a = 1 b = a # 创建a的副本赋值给b b = 2 # 修改b的值,不会影响a的值 print(a) # 输出:1 print(b) # 输出:2而对于可变对象,赋值或传递时只是创建了一个引用,即两个变量指向同一个对象,因此对其中一个变量的修改会影响另一个变量,例如:
a = [1, 2, 3] b = a # 创建a的引用赋值给b b[0] = 0 # 修改b中的元素,会影响a中的元素 print(a) # 输出:[0, 2, 3] print(b) # 输出:[0, 2, 3] -
Python官方文档中有一些关于可变对象和不可变对象的说明,可以参考以下链接:
- Python官方文档:数据模型
- Python官方文档:不可变序列
- Python官方文档:可变序列
可视化工具🎈
- Python Tutor: Learn Python, JavaScript, C, C++, and Java programming by visualizing code
- Online Python compiler and debugger - Python Tutor - Learn Python by visualizing code
- Python Preview - Visual Studio Marketplace
- Debug Visualizer - Visual Studio Marketplace
可变对象和id
-
id()|Built-in Functions — Python documentation
-
在Python中,
id()函数用于获取对象的唯一标识符。每个对象都有一个唯一的标识符,可以用于比较对象是否相等。这个标识符是一个整数,可以被认为是对象的内存地址。以下是一些示例代码,演示如何使用
id()函数:# 获取整数对象的标识符 x = 10 print(id(x)) # 输出一个整数 # 获取字符串对象的标识符 s = "hello" print(id(s)) # 输出一个整数 # 获取列表对象的标识符 lst = [1, 2, 3] print(id(lst)) # 输出一个整数 # 获取自定义对象的标识符 class MyClass: pass obj = MyClass() print(id(obj)) # 输出一个整数在上面的代码中,我们分别定义了一个整数、一个字符串、一个列表和一个自定义类对象,并使用
id()函数获取它们的标识符。需要注意的是,即使两个对象的值相同,它们的标识符也可能不同,因为它们可能位于不同的内存位置。id()函数通常用于比较对象是否相等。如果两个对象的标识符相同,则它们是同一个对象。如果两个对象的标识符不同,则它们是不同的对象。例如:a = [1, 2, 3] b = [1, 2, 3] c = a print(id(a)) # 输出一个整数 print(id(b)) # 输出一个不同的整数 print(id(c)) # 输出与a相同的整数 print(a == b) # 输出True,因为a和b的值相等 print(a is b) # 输出False,因为a和b是不同的对象 print(a is c) # 输出True,因为a和c是同一个对象在上面的代码中,我们定义了三个列表对象
a、b和c,其中a和b的值相同,但它们是不同的对象。c与a相同,是同一个对象。我们使用id()函数获取它们的标识符,并使用is运算符比较它们是否相同。需要注意的是,==运算符比较的是值是否相等,而is运算符比较的是对象是否相同。
eg
-
下面提到的例子中的python指针仅仅标识地址(类比于c语言中的指针)
## a,b=[1,2],34 ## 利用成组赋值初始化c,d两个新变量(指针) #c和a指向相同内存区域,d和b指向相同区域 c,d=[a,b] ##尝试通过指针c来修改c,和a共同指向的区域,值从[1,2]变为[1,2,3,4] c+=[11,22] ##尝试将指针d指向另一个内存区域(保存着100)(不同于b所指向的内存区域(保存着34)) d=100 ## a,b,c,d #([1, 2, 11, 22], 34, [1, 2, 11, 22], 100) #可以发现,a,c由于始终指向同一片内存,所以通过其中的一个指针(c或a)来修改同一片内存,通过a,c访问到的内容是始终保持一样 #因为list是可变对象,对这类对象执行+=操作不会改变指针所指的内存区域(首地址) #(如果是str这类不可变对象,使用+=会导致指针指向其他内存区域!) ## #这几个变量指向的地址一致性分析:a,c指向相同的区域,b,d指向不同的区域 [id(x) for x in[a,b,c,d]] #[2363406317120, 2363321642320, 2363406317120, 2363321832912]-
s="abc" id(s)#2363326296880 s+="d" id(s)#2363407021040- 可以看到s指向的内存首地址(id)发生了改变
-
-
如果您对以下内容有所了解,那么理解起来回简单一些:
- 操作系统上的硬链接(hardlink)
- c语言中的指针
-
以硬链接为例,假设
- 您在A目录有一个文件
X(理解为名字或者指针),它在硬盘上的地址记为idx - B目录下建立了一个指向磁盘的idx的名为
X'的指针 - 但是通过
X或X'均可以找到磁盘上的位置idx,也就是说,通过X或X’都可以打开/修改idx开始的一片区域 - 也就是说,
X,X'访问到的内容始终是一样的 - 但是,您无法通过修改
X'指向到idy的新区域,同时将X也指向idy X,X'各自不知道对方的存在- 在python编程中(尤其是面向对象中),要注意这些东西
- 您在A目录有一个文件
-
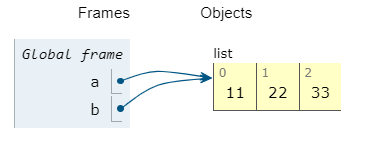
再形象点说,假设公司派了2个人(设为a,b)去一个同一个地方P1办事,a先受到具体通知(a=P1),a将地点告诉b(类似于执行语句b=a)
-
假设b再执行任务的过程中被公司紧急改派到另一个地方P2执行任务(b=P2)
-
此时a并没有因为b绑定的任务发生变化而跟着变化
-
假设公司由派遣了第3个人c去协助a到P1地方(对象)去工作
-
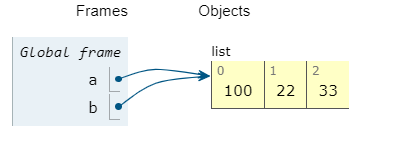
如果P1是一个可变对象(比如列表),比如修改P1的某个成员P[i],a,c两个人都可以看到相同的变化
-
- a[1]=100,c[1]=100,P1[1]=100效果是一样的,也就是说,修改对象内部的东西,对于所有引用了这个对象的变量是可见的,但是如果形如
c=P2这样的语句直接使得c不再指向P1,而是指向P2,那么对c的后续的任何使用和修改都对立与a,P1
- a[1]=100,c[1]=100,P1[1]=100效果是一样的,也就是说,修改对象内部的东西,对于所有引用了这个对象的变量是可见的,但是如果形如
eg
-
a,b=[1,2],34 t=[a,b] t[1] is b#true t[1]=8 id(t[1]),id(b)#(2363321641488, 2363321642320)t[1]和b最开始指向同一片区域,但是后来t[1]被修改指向其他区域,不再和b有相同的取值- b的取值也无法直接通过
t[1]来修改(只能是直接将b)作为左值,才能使其指向其他地方 - 反之也一样,修改b无法直接影响到
t[1](除非,b指向一个可变对象(比如list,同时做的是原地修改))
变量名和内存地址🎈
-
在 Python 中,变量名是用于引用对象的标识符,而对象则是存储在内存中的数据结构。
-
每个对象都有一个唯一的标识符,即对象的内存地址。
-
变量名引用了对象的内存地址,而不是对象本身。
-
当我们创建一个变量并为其赋值时,Python 解释器会在内存中创建一个对象,并将变量名与对象的内存地址进行绑定。
- 注意访问变量/创建变量/给变量赋值的差异
-
当我们引用变量时,Python 解释器会查找变量名对应的内存地址,然后返回存储在该地址中的对象。
-
python中的变量名和c语言中的指针有所不同
-
print(f"{id(10)=}") a=10 print(f"{id(a)=}") def f(x): print(f"{id(x)=}") x=20 print(f"{id(20)=}") print(f"{id(x)=}") f(a) a print('a: ', a)#10-
id(10)=3207627500112 id(a)=3207627500112 id(x)=3207627500112 id(20)=3207627500432 id(x)=3207627500432 a: 10
-
-
上面的语句
b=a将a所引用的内存地址告诉了b,从而b指向的和a所指的空间一致- 尽管如此,b,a还是相对独立的
-
修改a,使其指向别处
函数调用对参数的修改😂
-
a=10 def f(x): x=20 f(a) a print('a: ', a)#10 -
初学者可能会认为最后打印的会是20,但实际上会是10
-
在这段代码中,首先将值
10赋给变量a。 -
然后定义了一个名为
f的函数,它有一个参数x,在函数内部,将值20赋给参数x。 -
当你以a做为实参,执行
f(a),python会分别一个变量x,并且x绑定到一个同为20的值 -
因此,当你调用函数后打印
a的值,你会得到10,也就是a的原始值。 -
print(f"{id(10)=}") a=10 print(f"{id(a)=}") def f(x): print(f"{id(x)=}") x=20 print(f"{id(20)=}") print(f"{id(x)=}") f(a) a print('a: ', a)#10
Note
-
在 Python 中,函数参数是按值传递的,因此在函数内部修改参数的值不会影响函数外部的变量。
-
但是,你可以使用可变对象作为参数来达到修改参数值的目的。
-
例如,你可以将参数
x设计成一个列表或字典,然后在函数内部修改列表或字典元素的值,这样就可以修改参数的值了。以下是一个示例代码:
def f(x): x[0] = 20 a = [10] f(a) print(a[0]) # 输出 20 -
在这个示例中,我们将参数
x设计成一个列表a。 -
在函数
f内部,我们将列表a的第一个元素修改为 20。这样,在函数外部打印a[0]的值时,会输出 20,因为参数a的值已经被修改了。 -
上述例子中,可以理解为,
f(a)执行了x=a,从而一个和a不同的变量x就被创建,他们此时指向相同的内存区域 -
进入函数内部这个过程中,只有x进入,而a没有受到影响,x被修改不会影响a
-
需要注意的是,这种方式修改参数值的做法并不是很常见,因为它可能会导致代码难以理解和维护。通常来说,我们更倾向于使用函数的返回值来传递函数处理后的结果。
按值传递vs引用传递
- 按值传递和引用传递是两种不同的函数参数传递方式。
- 按值传递(call by value)是将参数的值复制一份,然后传递给函数。
- 在函数内部,对参数进行修改不会影响函数外部的变量。这种方式是最常见的参数传递方式,也是 Python 中默认的参数传递方式。
- 引用传递(call by reference)是将参数的引用或地址传递给函数。
- 在函数内部,对参数进行修改会影响函数外部的变量。这种方式通常是通过指针或引用来实现的,比如在 C 语言中,可以通过指针来实现引用传递。
- 在 Python 中,函数参数默认是按值传递的
- 但是当参数是可变对象时(比如列表或字典),即使(看起来和按值传递一样),但可以在函数内部被修改参数的值,因为可变对象是引用传递的。
note🎈
-
注意区分:
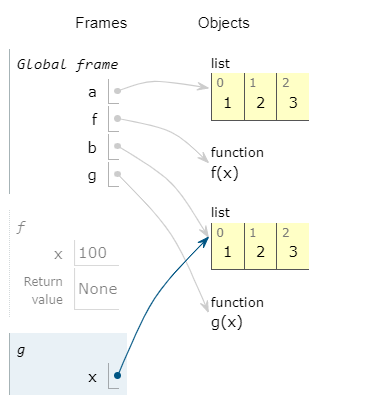
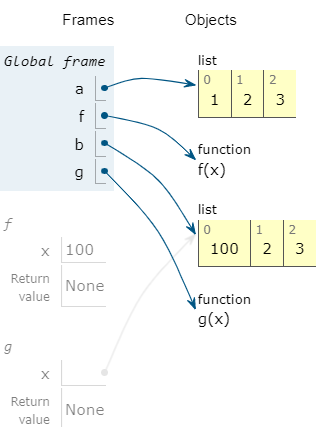
a=[1,2,3] def f(x): x=100 f(a) print(f"{a=}")#[1,2,3] b=[1,2,3] def g(x): x[0]=100 g(b) print(f"{b=}")#[100,2,3]-
这里a,b是两个独立的列表,只是他们的内容是一样的,都是1,2,3
-
运行结果:
-
a=[1, 2, 3] b=[100, 2, 3] -
a没有被修改;而b被修改了
-
因为a是值,而b[0]是引用
-
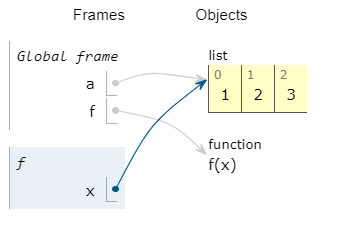
函数 g(x)的参数x传入实参列表对象b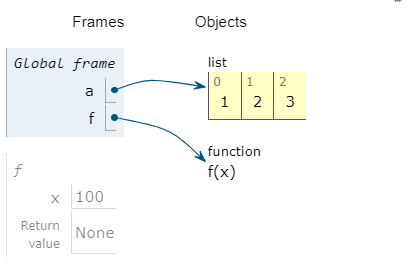
函数f内部执行了 x=100,x从list这个Object断开,而指向一个常量100
-
-
当我们将一个列表或字典等可变对象作为函数参数传递时,实际上传递的是对象的引用或地址,而不是对象的值。这意味着,在函数内部对参数进行修改时,实际上修改的是对象本身,而不是对象的副本。因此,修改后的对象的值将在函数外部可见。
当我们将一个整数、字符串等不可变对象作为函数参数传递时,实际上传递的是对象的值的副本。这意味着,在函数内部对参数进行修改时,实际上修改的是参数的副本,而不是原始对象。因此,在函数外部,原始对象的值不会受到影响。
-
在第一个示例中,函数
f接收参数x并将其赋值为 100,但是在函数外部调用f并不会改变变量a的值,因为在函数内部的赋值语句x=100只是将参数x的引用指向了一个新的对象(100),并不会影响变量a的引用。因此,变量a的值仍然是[1, 2, 3]。- 这里x,a都是指向同一个内存区域的指针
- 我们修改x指向其他地方,不会影响到a,a依然指向原来的内存
-
但是,如果a,x所指的是可变对象,那么a[i],x[i]始终是一样的(指向相同内存)
-
在第二个示例中,函数
g接收参数x并将其第一个元素赋值为 100,由于列表是可变对象,所以在函数内部修改参数x的第一个元素也会影响到变量b。因此,变量b的值被修改为[100, 2, 3]。需要注意的是,Python 中的列表、字典等可变对象是引用传递的,而整数、字符串等不可变对象则是按值传递的。在函数内部对可变对象进行修改时,可能会影响到函数外部的变量,而对不可变对象进行修改时则不会。
如何借助函数修改外部变量的值?
-
根据上述的讨论,如果您确实需要根据某个函数修改某个变量,在python中,使用返回值是一个不错的选择
-
例如:python中最常用的是
-
x=[] def square(n): res=[x**2 for x in range(n)] return res x=square(10) -
而不是:
-
x=[] def square(n,x): x=[x**2 for x in range(n)] square(10,x)
-
-
-
另一方面,有一个关键字叫
global,使用它可以修改外部变量-
x=[] def square(n): global x x=[x**2 for x in range(n)] square(10)
-
Note
-
a=[11,22,33] b=[11,22,33] print(id(a),"@{id(a)}") print(id(b),"@{id(b)}") ida=id(a[0]) idb=id(b[0]) ida,idb-
3207784112768 @{id(a)} 3207784126592 @{id(b)} (3207627500144, 3207627500144)
-
-
id(a[0])==id(b[0])#True a[0] is b[0]#True -
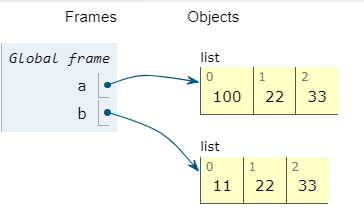
这个例子表示a,b是不同的两个列表对象,他们有共同点,就是内容是一样的
-
既然内容一样为什么还要强调a,b是不同对象?
-
因为对a的修改不会引起b的变化,反之也一样
- 就好像两个不同的平台a,b请了同一个专家x做同样的工作
- 后来其中的平台a请了专家y代替专家x,这不会影响平台b保持聘用专家x
-
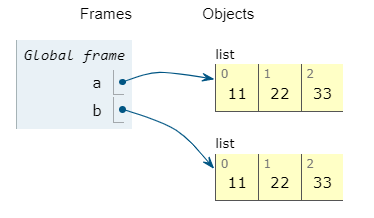
最后注意,这里是显式的各自为a赋值
[11,22,33],而不是通过b=a这种方式赋值,后者方式使得b对列表的修改对a是可见的 -
a=[11,22,33]
b=[11,22,33]
a[0]=100a=[11,22,33]
b=a
a[0]=100