LASSO vs GridSearchCV
LASSO VS GridSearchCV
- LASSO
- 定义
- 目的
- 使用方法
- 原理
- 示例
- 总结
- GridSearchCV
- 定义
- 目的
- 使用方法
- 原理
- 网格搜索(Grid Search)
- 交叉验证(Cross-Validation)
- 总结
- 示例
- 总结
- 总结
LASSO
定义
LASSO(Least Absolute Shrinkage and Selection Operator)是一种在统计学和机器学习中常用的回归分析方法。
目的
主要目的是增强模型的预测精度和可解释性,通过对系数进行收缩来实现变量的选择和复杂度的控制。LASSO特别适合于处理具有多重共线性(即输入变量高度相关)或者数据特征数量远大于样本数量的情况。
使用方法
- **数据准备:**首先,你需要准备你的数据集,包括自变量(特征)和因变量(目标变量)。
- **选择模型:**在适用的软件或编程语言(如Python、R等)中选择LASSO回归模型。
- **参数设置:**LASSO的关键参数是正则化参数λ(有时也称为α)。这个参数控制着模型对系数的收缩程度。λ值越大,收缩越强,更多的系数被设置为零,从而实现特征选择。
- **模型训练:**使用你的数据来训练LASSO模型。在这个过程中,模型会学习数据特征和目标变量之间的关系,并决定哪些特征是重要的。
- **交叉验证:**为了找到最佳的λ值,通常需要通过交叉验证来评估不同λ值下模型的性能。
- **模型评估:**一旦选择了最优的λ值,就可以使用这个参数来训练最终模型,并评估其在测试数据集上的性能。
- **解释结果:**最后,你可以解释模型的输出,查看哪些变量被选中,以及它们对预测的贡献程度。
原理
ASSO回归是一种线性回归的形式,它在损失函数中加入了一个正则化项。这个正则化项是系数的绝对值之和,乘以一个调整参数λ。LASSO的目的是最小化以下公式:
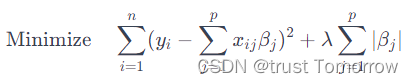
其中,
y
i
y_i
yi是观测值,
x
i
j
x_{ij}
xij是特征值,
β
j
\beta_j
βj是系数,
λ
\lambda
λ是正则化参数。通过调整λ的值,可以控制正则化的强度。LASSO倾向于将一些系数完全压缩至零,从而实现特征选择。
示例
# 导入必要的库
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 创建虚构数据集
np.random.seed(0) # 确保可重复性
X = np.random.rand(100, 10) # 100个样本,10个特征
y = np.dot(X, np.array([1.5, -2., 0., 0., 3., 0., 0., 0., 0., 0.])) + np.random.randn(100) * 0.5
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 创建LASSO回归模型
lasso = Lasso(alpha=0.1) # alpha是λ的同义词
# 训练模型
lasso.fit(X_train, y_train)
# 预测测试集
y_pred = lasso.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# 查看选择的特征(非零系数)
print(f"Coefficients: {lasso.coef_}")
在这个示例中,我们首先创建了一个虚构的数据集,其中一些特征是有影响的(具有非零系数),而其他特征则是无关的(系数为零)。通过使用LASSO回归,我们试图识别出有影响的特征。 a l p h a alpha alpha参数是 λ \lambda λ的同义词,在这里我们设置为0.1。LASSO模型会试图将一些系数减少到零,从而实现特征选择。最后,我们计算了模型在测试集上的均方误差,并打印出非零系数来查看哪些特征被选中。
总结
- 性质: LASSO是一种线性回归技术,它通过引入一个正则化项(即系数的绝对值之和)来惩罚模型的复杂性。这种正则化有助于减少过拟合,特别是在特征数量多于样本数量的情况下。
- 目的: LASSO的主要目标是特征选择和模型简化。它通过将一些回归系数减少到零来实现这一点,从而简化模型并突出显示最重要的特征。
- 应用: LASSO用于建立线性模型,特别适合于高维数据集。
GridSearchCV
定义
GridSearchCV 是一个强大的工具,用于在机器学习模型中自动寻找最佳的超参数。
目的
通过遍历所有给定的超参数组合,并使用交叉验证来评估每一组合的性能,从而找到最佳的超参数设置。
使用方法
- 选择模型:首先确定你要使用的机器学习模型,例如决策树、SVM、线性回归等。
- 定义参数网格:列出你想要优化的超参数,以及你想要尝试的它们的值。这些值将构成一个“网格”。
- 配置 GridSearchCV:设置 GridSearchCV,指定模型、参数网格、评分方法以及交叉验证的细节。
- 训练模型:使用 GridSearchCV 对象训练模型。它将遍历所有的参数组合,并使用交叉验证来评估每个组合的性能。
- 评估结果:选择表现最佳的参数组合,并使用这些参数来构建最终模型。
原理
网格搜索(Grid Search)
-
参数网格定义:在网格搜索中,首先定义一个参数网格。这个网格包含了模型可能使用的各种超参数及其候选值。例如,对于支持向量机( S V M SVM SVM),参数网格可能包括不同的 C C C(正则化参数)、 g a m m a gamma gamma(核函数的参数)和 k e r n e l kernel kernel(核类型)的值。
-
遍历所有可能的参数组合:网格搜索的核心是遍历这个参数网格中的所有可能的参数组合。对于每一种组合,模型都会被训练并评估其性能。
交叉验证(Cross-Validation)
-
数据分割:交叉验证是一种评估模型泛化能力的方法。它将数据集分割成若干份(通常是相同大小的子集),例如 5 5 5份或 10 10 10份。
-
迭代训练与验证:在每一轮迭代中,一份子集被保留作为验证数据,其余的子集用于训练模型。这个过程重复多次,每次选择不同的子集作为验证数据。
-
性能度量:在每一轮迭代中,都会对模型进行评估(比如准确度、 F 1 F1 F1分数等),并且最终的性能度量是这些评估结果的平均值。这有助于减少模型因数据分割不同而产生的性能波动。
总结
G r i d S e a r c h C V GridSearchCV GridSearchCV 结合了网格搜索和交叉验证的优点。它通过网格搜索遍历所有的参数组合,并使用交叉验证来评估每一组合的性能。
- 全面性:通过系统地搜索所有的参数组合, G r i d S e a r c h C V GridSearchCV GridSearchCV确保了不会错过任何潜在的最佳参数组合。
- 稳健性:通过交叉验证, G r i d S e a r c h C V GridSearchCV GridSearchCV 能够评估模型在不同子集上的性能,从而提供关于模型泛化能力的更准确的估计。
总之, G r i d S e a r c h C V GridSearchCV GridSearchCV 的原理在于它提供了一种系统的方法来探索多种参数组合,并利用交叉验证来找出最能提高模型性能的参数设置。这种方法虽然计算量较大,但能够显著提高模型的准确性和可靠性。
示例
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
# 加载数据集(例如鸢尾花数据集)
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 创建SVM模型
model = svm.SVC()
# 定义要优化的参数网格
param_grid = {
'C': [0.1, 1, 10, 100], # SVM正则化参数
'gamma': [1, 0.1, 0.01, 0.001], # 核函数参数
'kernel': ['rbf', 'linear'] # 核类型
}
# 配置GridSearchCV
grid_search = GridSearchCV(model, param_grid, refit=True, verbose=2, cv=5)
# 训练模型
grid_search.fit(X, y)
# 查看最佳参数
print("Best Parameters Found: ")
print(grid_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_
predictions = best_model.predict(X)
# 这里可以添加评估模型性能的代码(例如准确率、混淆矩阵等)
在这个示例中,我们使用鸢尾花数据集,尝试不同的 C C C(正则化参数)、 g a m m a gamma gamma(核函数参数)和 k e r n e l kernel kernel(核类型)来优化 S V M SVM SVM模型。 G r i d S e a r c h C V GridSearchCV GridSearchCV遍历所有可能的参数组合,并使用 5 5 5折交叉验证来评估每个组合的性能。最后,我们输出最佳参数组合,并用这些参数构建最终模型。
总结
- 性质: GridSearchCV是一种模型超参数优化技术。它不是一种独立的统计或机器学习模型,而是一种用于确定最佳模型配置的方法。
- 目的: GridSearchCV的目的是通过系统地遍历多种参数组合来找到给定模型的最佳参数(例如,LASSO中的正则化强度λ)。它通常与交叉验证结合使用,以评估每组参数的效果,并选择表现最佳的一组。
- 应用: GridSearchCV可以应用于几乎任何类型的机器学习模型,包括LASSO。它帮助找到使模型性能最优化的参数设置。
总结
- LASSO 是一种特定类型的回归模型,用于数据分析和特征选择。
- GridSearchCV 是一种模型优化工具,用于自动寻找和验证最优的模型参数。