Hdoop学习笔记(HDP)-Part.02 核心组件原理
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
二、核心组件原理
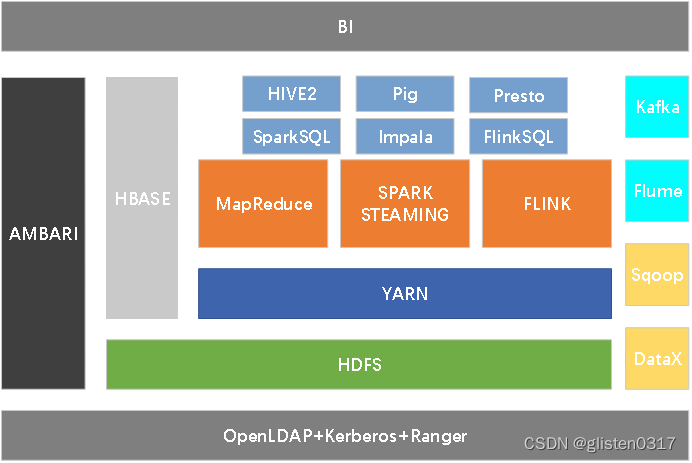
1.分布式协调ZooKeeper
(1)应用场景
使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了。
应用场景:
- 统一配置管理:比如现在有A.yml,B.yml,C.yml配置文件,里面有一些公共的配置,但是如果后期对这些公共的配置进行修改,就需要修改每一个文件,还要重启服务器。比较麻烦,现在将这些公共配置信息放到ZK中,修改ZK的信息,会通知A,B,C配置文件。
- 统一命名服务:这个的理解其实跟域名一样,在某一个节点下放一些ip地址,我现在只需要访问ZK的一个Znode节点就可以获取这些ip地址。
- 同一集群管理:分布式集群中状态的监控和管理,使用Zookeeper来存储。
分布式协调:比如把多个服务提供者的信息放在某个节点上,服务的消费者就可以通过ZK调用。-
- 服务节点动态上下线:如何提供者宕机,就会删除在ZK节点,然后ZK通知消费者
-
- 软负载均衡
(2)实现原理
zookeeper=文件系统+通知机制
① 文件系统
ZooKeeper的数据结构,跟Unix文件系统非常类似,可以看做是一颗树,每个节点叫做Znode。每一个Znode只能存1MB数据。数据只是配置信息。每一个节点可以通过路径来标识,结构图如下:
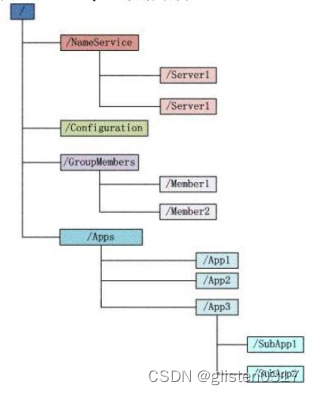
1)每个子目录项如NameService都被称作为znode,这个znode是被它所在的路径唯一标识,如Server1这个znode的标识为/NameService/Server1。
2)znode可以有子节点目录,并且每个znode可以存储数据,注意EPHEMERAL(临时的)类型的目录节点不能有子节点目录。
3)znode是有版本的(version),每个znode中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据,version号自动增加。
4)znode的类型:
- Persistent节点,一旦被创建,便不会意外丢失,即使服务器全部重启也依然存在。每个Persist节点即可包含数据,也可包含子节点。
- Ephemeral节点,在创建它的客户端与服务器间的Session结束时自动被删除。服务器重启会导致Session结束,因此Ephemeral类型的znode此时也会自动删除。
- Non-sequence节点,多个客户端同时创建同一Non-sequence节点时,只有一个可创建成功,其它匀失败。并且创建出的节点名称与创建时指定的节点名完全一样。
- Sequence节点,创建出的节点名在指定的名称之后带有10位10进制数的序号。多个客户端创建同一名称的节点时,都能创建成功,只是序号不同。
5)znode可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是Zookeeper的核心特性,Zookeeper的很多功能都是基于这个特性实现的。
6)ZXID:每次对Zookeeper的状态的改变都会产生一个zxid(ZooKeeper Transaction Id),zxid是全局有序的,如果zxid1小于zxid2,则zxid1在zxid2之前发生。
② 通知机制(监听机制)
ZooKeeper可以提供分布式数据的发布/订阅功能,依赖的就是Wather监听机制。
客户端可以向服务端注册Wather监听,服务端的指定事件触发之后,就会向客户端发送一个事件通知。
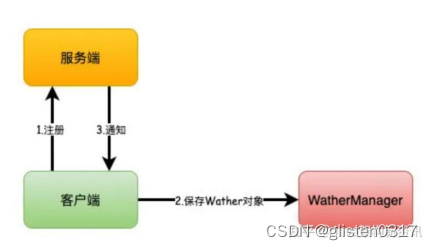
1)客户端向服务端注册Wather监听
2)保存Wather对象到客户端本地的WatherManager中
3)服务端Wather事件触发后,客户端收到服务端通知,从WatherManager(watcher管理器)中取出对应Wather对象执行回调逻辑
主要监听内容:
1)监听Znode节点的数据变化:就是哪个节点信息更新了
2)监听子节点的增减变化:就是增加了一个Znode或者删除了一个Znode
几个特性:
1)一次性:一旦一个Wather触发之后,Zookeeper就会将它从存储中移除
2)客户端串行:客户端的Wather回调处理是串行同步的过程,不要因为一个Wather的逻辑阻塞整个客户端
3)轻量:Wather通知的单位是WathedEvent,只包含通知状态、事件类型和节点路径,不包含具体的事件内容,具体的时间内容需要客户端主动去重新获取数据
(3)角色
| 角色 | 描述 | |
|---|---|---|
| 领导者(leader) | 负责进行投票的发起和决议,更新系统状态 | |
| 学习者(learner) | 跟随者(follower) | 接受客户端请求并想客户端返回结果,在选主过程中参与投票 |
| 观察者(observer) | 接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度 | |
| 客户端(client) | 请求发起方 | |
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
(4)集群
Leader选举算法采用了Paxos协议;
Paxos核心思想:当多数Server写成功,则任务数据写成功如果有3个Server,则两个写成功即可;如果有4或5个Server,则三个写成功即可。
Server数目一般为奇数(3、5、7)如果有3个Server,则最多允许1个Server挂掉;如果有4个Server,则同样最多允许1个Server挂掉。由此,我们看出3台服务器和4台服务器的的容灾能力是一样的,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数。
(5)Leader选举
假设现在ZooKeeper集群有五台服务器,它们myid分别是服务器1、2、3、4、5
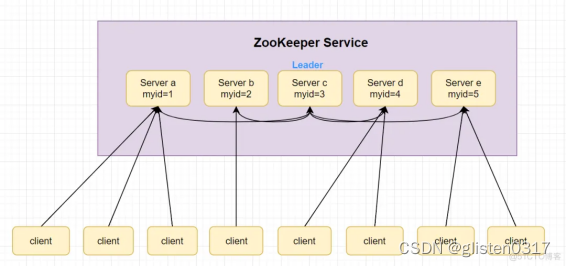
zookeeper集群初始化阶段,服务器(myid=1-5)依次启动,开始zookeeper选举Leader
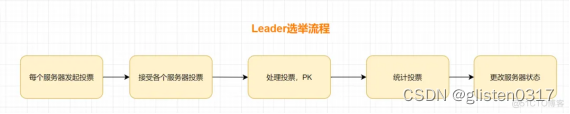
服务器1(myid=1)启动,当前只有一台服务器,无法完成Leader选举
服务器2(myid=2)启动,此时两台服务器能够相互通讯,开始进入Leader选举阶段
- 每个服务器发出一个投票
服务器1和服务器2都将自己作为Leader服务器进行投票,投票的基本元素包括:服务器的myid和ZXID,我们以(myid,ZXID)形式表示。初始阶段,服务器1和服务器2都会投给自己,即服务器1的投票为(1,0),服务器2的投票为(2,0),然后各自将这个投票发给集群中的其他所有机器。 - 接受来自各个服务器的投票
每个服务器都会接受来自其他服务器的投票。同时,服务器会校验投票的有效性,是否本轮投票、是否来自LOOKING状态的服务器。 - 处理投票
收到其他服务器的投票,会将被人的投票跟自己的投票PK,PK规则如下:
zookeeper集群中只有超过了半数以上的服务器启动,此集群才能正常工作;
在集群正常工作之前,myid小的服务器会给myid大的服务器投票,这种投票会一直持续到集群开始正常工作,即,选出了leader。
选出leader之后,之前的服务器节点的状态要由looking转为following从节点,以后的服务器不管是不是新加进来的都会变成follower从节点。
服务器1的投票是(1,0),它收到投票是(2,0),两者zxid都是0,因为收到的myid=2,大于自己的myid=1,所以它更新自己的投票为(2,0),然后重新将投票发出去。对于服务器2呢,即不再需要更新自己的投票,把上一次的投票信息发出即可。 - 统计投票
每次投票后,服务器会统计所有投票,判断是否有过半的机器接受到相同的投票信息。服务器2收到两票,少于3(n/2+1,n为总服务器),所以继续保持LOOKING状态
服务器3(myid=3)启动,继续进入Leader选举阶段。跟前面流程一致,服务器1和2先投自己一票,因为服务器3的myid最大,所以大家把票改投给它。此时,服务器为3票(大于等于n/2+1),所以服务器3当选为Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
服务器4(myid=4)启动,发起一次选举。
此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。选票信息结果:服务器3为3票,服务器4为1票。服务器4并更改状态为FOLLOWING;
服务器5(myid=5)启动,发起一次选举。
同理,服务器也是把票投给服务器3,服务器5并更改状态为FOLLOWING;
投票结束,服务器3当选为Leader
2.分布式存储HDFS
(1)组件功能
① NameNode:HDFS的管理节点,负责客户端的请求响应,存放元数据;
② SecondaryNameNode:(辅助节点)当编辑日志和映像文件需要合并时,在同一个NameNode上执行合并操作会耗费大量内存和计算能力,因此合并操作一般会在另一台机器上执行,即(SecondaryNamenode);
③ DataNode:HDFS的工作节点,受客户端和NameNode的调度,检索并存放数据块。没有NameNode,DataNode将无法使用;
(2)关于nn、2nn和nn HA
① NameNode
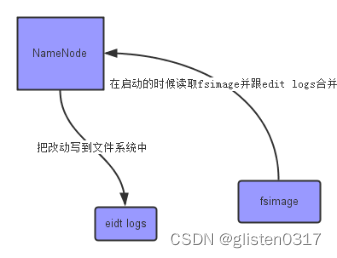
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的,但是这些信息也可以持久化到磁盘上。
Fsimage:是在NameNode启动时对整个文件系统的快照
edit logs:是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。
但是在生产集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。
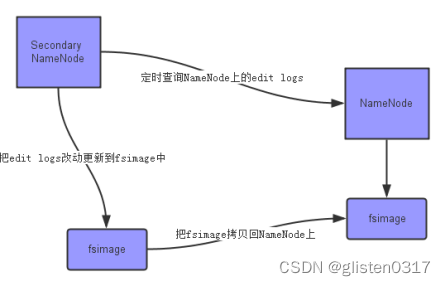
② 2nn/Secondary NameNode
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
首先,它定时到NameNode去获取edit logs,并更新到fsimage上(Secondary NameNode自己的fsimage)。
一旦它有了新的fsimage文件,它将其拷贝回NameNode中。NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
所以2nn并不是nn的备份,而是给nn提供了一个检查点。
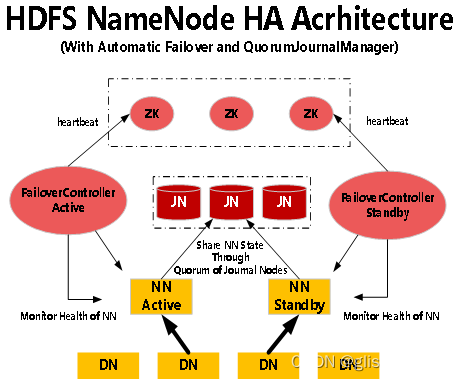
③ nn HA
在hadoop2.0之前,namenode只有一个,存在单点问题(虽然hadoop1.0有secondarynamenode,checkpointnode,buckcupnode这些,但是单点问题依然存在),在hadoop2.0引入了HA机制。
hadoop2.0的HA机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。
两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。
active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
(3)HDFS块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数 ( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
如果使用的是机械硬盘,可以设置块大小为128M;如果使用的是固态硬盘,则可以设置为256M
默认是这样的,数据的寻址时间要约等于传输时间的1%,即最佳状态,如果硬盘的传输速度较快,在寻址时间变化不大的条件下,我们传输的数据块可以大一点,所以设置为256M
如果设置块太小,会增加我们的寻址时间,程序会一直找数据块的位置
如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢
总结:HDFS块的大小设置主要取决于磁盘传输速率。
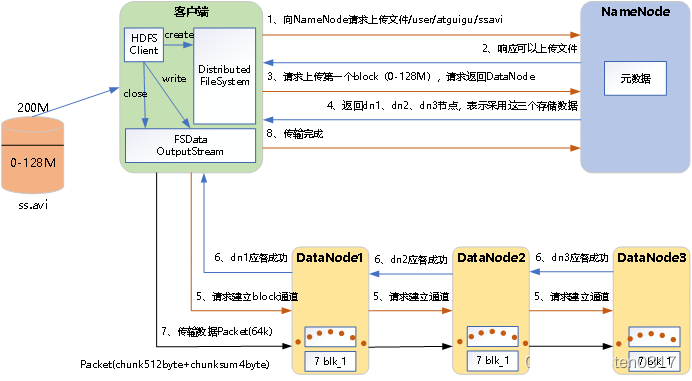
(4)HDFS写数据流程
①客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
②NameNode检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录)
③客户端按128MB的块切分文件,并请求第一个Block上传到哪几个DataNode服务器上。
④NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
⑤客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
⑥dn1、dn2、dn3逐级应答客户端。
⑦客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
⑧当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
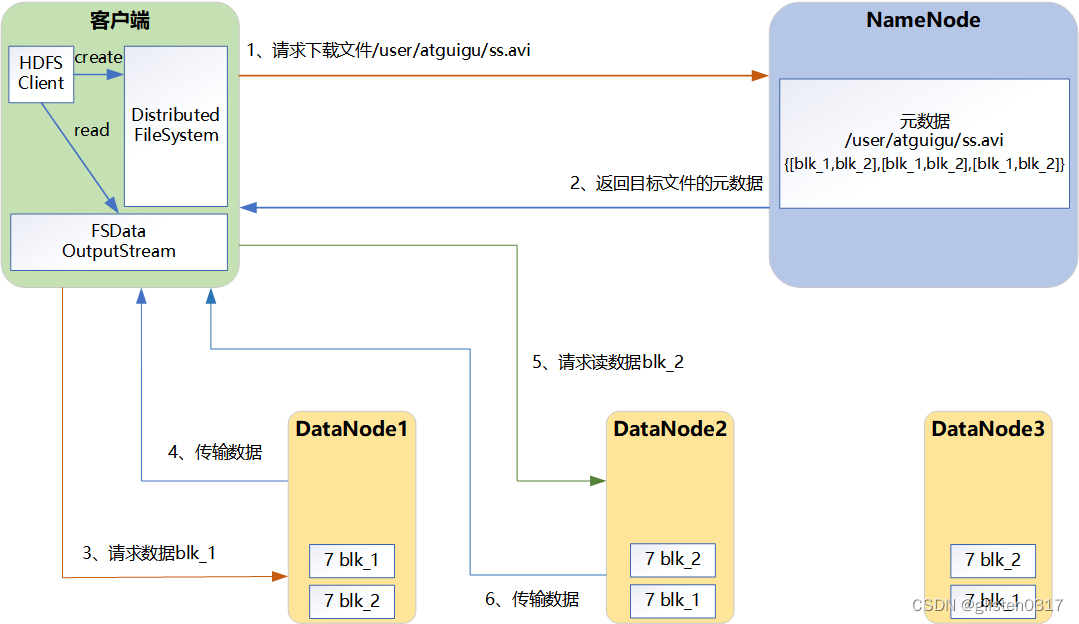
(5)HDFS读数据流程
①客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
②挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
③DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
④客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
(6)关于Fsimage和Edits
NameNode被格式化之后,将在…/hadoop/hdfs/namenode/current/目录中产生如下文件
①Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息
②Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
③seen_txid文件保存的是一个数字,就是最后一个edits_的数字
④每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并
(7)关于JournalNode
从Hadoop2.x版本后,HDFS采用了一种全新的元数据共享机制,即通过Quorum Journal Node(JournalNode)集群或者network File System(NFS)进行数据共享。NFS是操作系统层面的,而JournalNode是Hadoop层面的,成熟可靠、使用简单方便,一般采用JournalNode集群进行元数据共享。
JournalNode集群以及与NameNode之间共享元数据如下图所示。
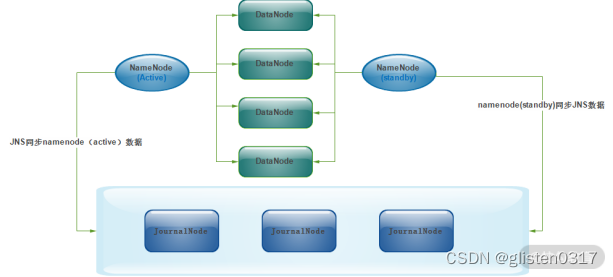
JournalNode集群可以几乎实时的去NameNode上拉取元数据,然后保存元数据到JournalNode集群;同时,处于standby状态的NameNode也会实时的去JournalNode集群上同步JNS数据,通过这种方式,就实现了两个NameNode之间的数据同步。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当Active状态的NameNode元数据有任何修改时,会告知大部分的JournalNodes进程。同时,Standby状态的NameNode也会读取JNs中的变更信息,并且一直监控EditLog(事务日志)的变化,并把变化应用于自己的命名空间。Standby可以确保在集群出错时,元数据状态已经完全同步了。
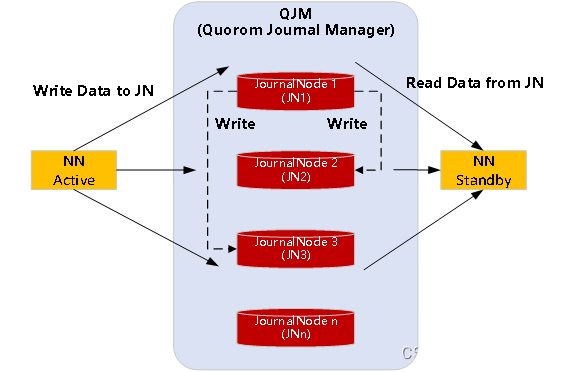
JN1、JN2、JN3等是JournalNode集群的节点,QJM(Quorom Journal Manager)的基本原理是用2N+1台JournalNode存储EditLog,每次写数据操作有N/2+1个节点返回成功,那么本次写操作才算成功,保证数据高可用。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,算法就会失效。
ZooKeeper也是作为分布式协调的组件,namenode HA用了JournalNode,而没有用ZooKeeper,原因是Zookeeper不适合存储,znode中可以存储的默认最大数据大小为1MB。
(8)关于zkfc
健康检测:zkfc会周期性的向它监控的namenode(只有namenode才有zkfc进程,并且每个namenode各一个)发生健康探测命令,从而鉴定某个namenode是否处于正常工作状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于不健康的状态。
会话管理:如果namenode是健康的,zkfc机会保持在zookeeper中保持一个打开的会话,如果namenode是active状态的,那么zkfc还会在zookeeper中占有一个类型为短暂类型的znode,当这个namenode挂掉时,这个znode将会被删除,然后备用的namenode得到这把锁,升级为主的namenode,同时标记状态为active,当宕机的namenode,重新启动,他会再次注册zookeeper,发现已经有znode了,就自动变为standby状态,如此往复循环,保证高可靠性,但是目前仅支持最多配置两个namenode。
master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断哪个namenode为active状态。
(9)安全模式
在安全模式下集群在进行恢复元数据,即在合并fsimage和edits log,并且接受datanode的心跳信息,恢复block的位置信息,将集群恢复到上次关机前的状态。
3.资源调度器YARN
(1)RM/AM/NM/Container
在MRv1中,JobTracker由资源管理(由TaskScheduler模块实现)和作业控制(由JobTracker中多个模块共同实现)两部分组成,由于Hadoop对JobTracker赋予的功能过多而造成负载过重。从设计角度上看,Hadoop未能够将资源管理相关的功能与应用程序相关的功能分开,造成Hadoop难以支持多种计算框架。
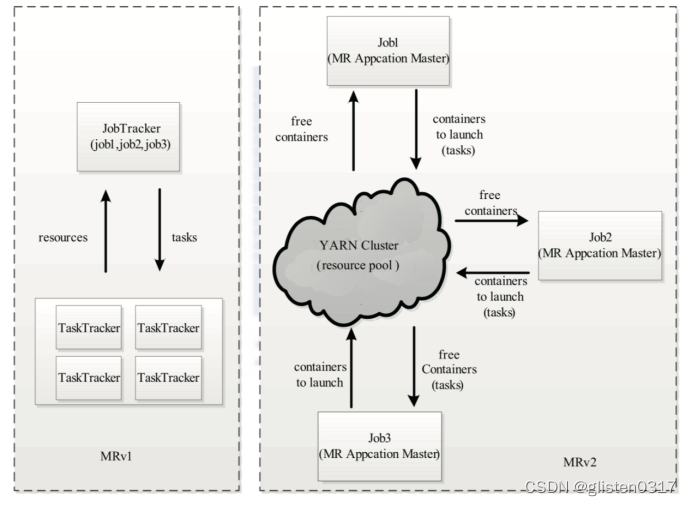
YARN的基本设计思想是将JobTracker的两个主要功能,即资源管理和作业控制(包括作业监控、容错等),分拆成两独立的进程,资源管理进程与具体应用程序无关,它负责整个集群的资源(内存、CPU、磁盘等)管理,而作业控制进程则是直接与应用程序相关的模块,且每个作业控制进程只负责管理一个作业。YARN的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。这样,通过将原有JobTracker中与应用程序相关和无关的模块分开,不仅减轻JobTracker负载,也使得Hadoop支持更多的计算框架。
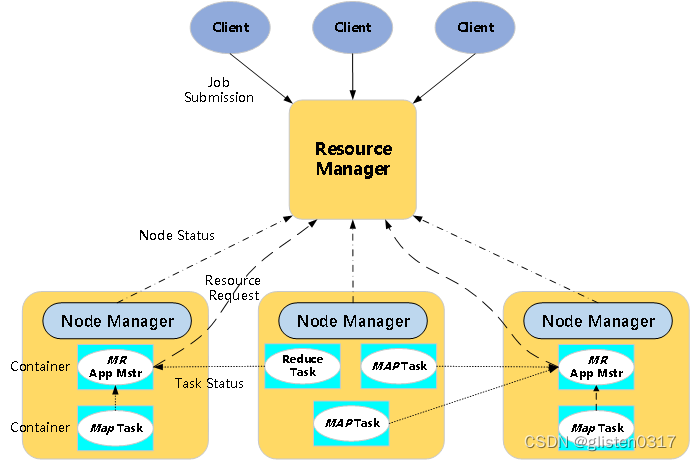
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器根据容量、队列等限制条件将系统中的资源分配给各个正在运行的应用程序。需要注意的是,调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成,调度器仅根据各个应用程序的资源需求进行资源分配。该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM,主要用来与RM调度器协商以获取资源,得到的任务进一步分配给内部的任务,与NM通信以启动/停止任务,监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。当前YARN自带了两个AM实现,一个是用于演示AM编写方法的实例程序distributedshell,它可以申请一定数目的Container以并行运行一个Shell命令或者Shell脚本,另一个是运行MapReduce应用程序的MRAppMaster。此外,一些其他的计算框架例如Spark也有对应的AM。
NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态,另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。需要注意的是,Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。
(2)工作流程
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一个阶段是启动ApplicationMaster。第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
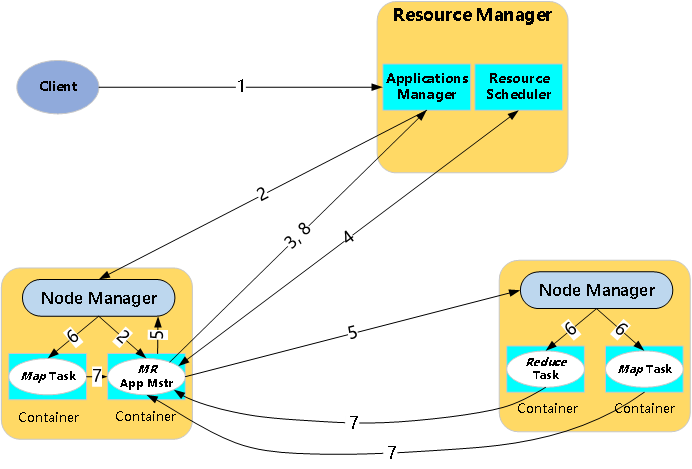
①用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
②ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
③ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复4~7。
④ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
⑤ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
⑥NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
⑦各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
⑧应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
(3)其他
①JobHistory
YARN提供的一个查看已经完成的任务的历史日志记录的服务,可查询每个job运行完以后的历史日志信息,比如map个数、reduce个数等。
②Timeline Serivce
Hadoop 2.4.0以后出现的新特性,主要是为了监控运行在YARN平台上的所有任务(例如MR、Storm、Spark、HBase等),JobHistoryServer只能查看mr任务的信息,不能查看spark、flink的信息,针对这个问题,spark、flink都要提供自己的server,为了统一,yarn提供了timelineserver,功能更强大,但不是替代jobhistory,两者是功能间的互补关系。
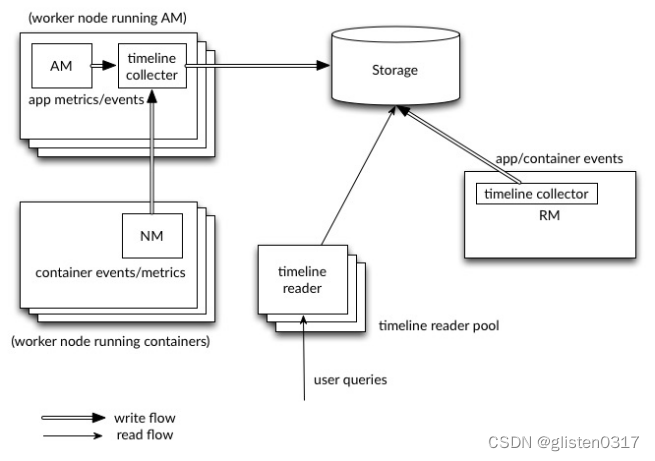
Collector将数据写入后端存储
Reader是与Collector分开的独立守护进程,专用于通过REST API提供查询
③Registry DNS
由Yarn服务注册表支持的Yarn DNS服务器,可通过其标准DNS在Yarn上查找服务
通过DNS向外提供已有的service-discovery信息,将YARN Service registry records转换为DNS记录,从而使用户可以通过标准的DNS客户端机制(例如DNS SRV记录,描述host:port)查询YARN Applciation信息
4.分布式计算引擎
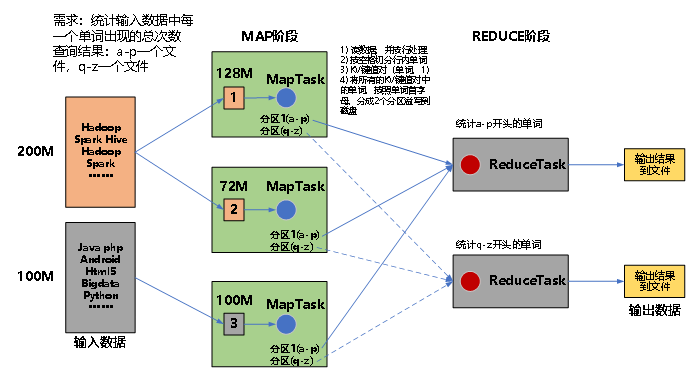
(1)MapReduce
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
①MRAppMaster:负责整个程序的过程调度及状态协调
②MapTask:负责Map阶段的整个数据处理流程
③ReduceTask:负责Reduce阶段的整个数据处理流程
MapReduce运算程序一般需要分成2个阶段:Map阶段和Reduce阶段
①Map阶段的并发MapTask,完全并行运行,互不相干
②Reduce阶段的并发ReduceTask,完全互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出
③MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行
(2)Spark
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。
①核心模块
【Spark Core】
Spark由Scala语言开发的,Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX,MLlib都是在Spark Core的基础上进行扩展的。
SparkCore是Spark的基础,底层的最小数据单位是:RDD。主要是处理一些离线(可以通过结合Spark Streaming来处理实时的数据流)、非格式化数据。它与Hadoop的MapReduce的区别就是,spark core基于内存计算,在速度方面有优势,尤其是机器学习的迭代过程。
【Spark SQL】
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
Spark SQL底层的数据处理单位是:DataSet。主要是通过执行标准SQL来处理一些离线(可以通过结合Spark Streaming来处理实时的数据流)、格式化数据。就是Spark生态系统中一个开源的数据仓库组件,可以认为是Hive在Spark的实现,用来存储历史数据,做OLAP、日志分析、数据挖掘、机器学习等等。可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是HIVE、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。
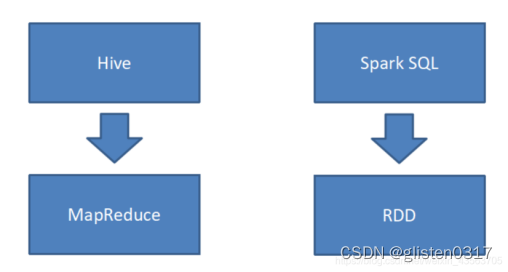
Hive是将SQL转为MapReduce
SparkSQL可以理解成是将SQL解析成RDD+优化再执行
【Spark Streaming】
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark Streaming底层的数据处理单位是:DStream。主要是处理流式数据(数据一直不停的在向Spark程序发送),这里可以结合Spark Core和Spark SQL来处理数据,如果来源数据是非结构化的数据,那么我们这里就可以结合Spark Core来处理,如果数据为结构化的数据,那么可以结合Spark SQL来进行处理。

Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL)。即Spark SQL是Spark Core封装而来的!Spark SQL在Spark Core的基础上针对结构化数据处理进行很多优化和改进。
②Spark架构
Driver Program
相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
一个SparkApplication仅有一个;
Executors
相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task运行需要1 Core CPU,所有可以认为Executor中线程数就等于CPU Core核数;
一个Spark Application可以有多个,可以设置个数和资源信息;
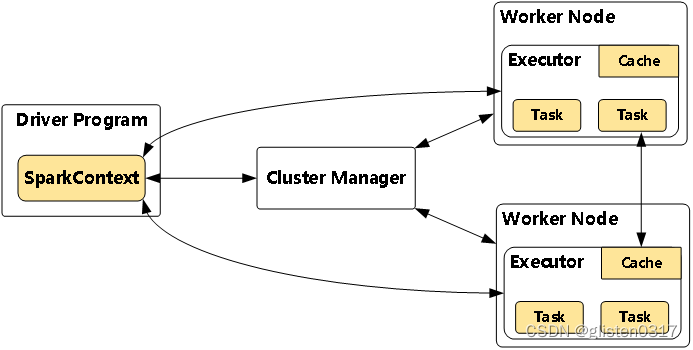
Driver Program是用户编写的数据处理逻辑,这个逻辑中包含用户创建的SparkContext。SparkContext是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager交互,包括向它申请计算资源等。**Cluster Manager负责集群的资源管理和调度,现在支持Standalone、Apache Mesos和Hadoop的YARN。**Worker Node是集群中可以执行计算任务的节点。**Executor是在一个Worker Node上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。**Task是被送到某个Executor上的计算单元,每个应用都有各自独立的Executor,计算最终在计算节点的Executor中执行。
③Spark on Yarn
Spark可以跑在很多集群上,比如跑在local上,跑在Standalone上,跑在Apache Mesos上,跑在Hadoop YARN上等等。不管Spark跑在什么上面,它的代码都是一样的,区别只是master的时候不一样。其中Spark on YARN是工作中或生产上用的非常多的一种运行模式。
Spark可以和Yarn整合,将Application提交到Yarn上运行,Yarn有两种提交任务的方式。
- yarn-client提交任务方式
1.客户端提交一个Application,在客户端启动一个Driver进程
2.Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)
3.RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点
4.AM启动后,会向RS请求一批container资源,用于启动Executor
5.RS会找到一批NM返回给AM,用于启动Executor。AM会向NM发送命令启动Executor
6.Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端
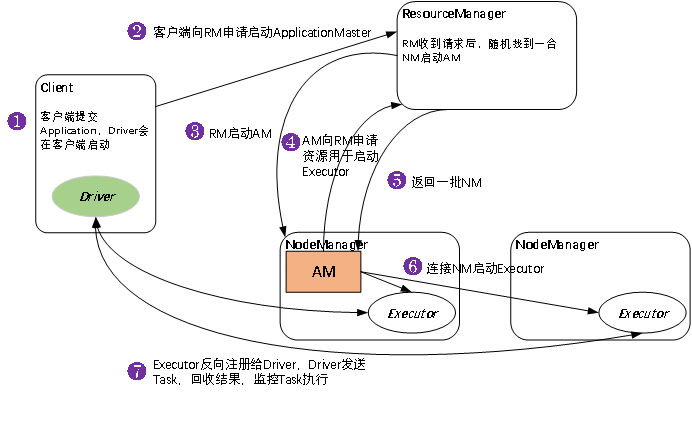
Yarn-client模式适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
- yarn-cluster提交任务方式
1.客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)
2.RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)
3.AM启动,AM发送请求到RS,请求一批container用于启动Executor
3.RS返回一批NM节点给AM
4.AM连接到NM,发送请求到NM启动Executor
5.Executor反向注册到AM所在的节点的Driver,Driver发送task到Executor
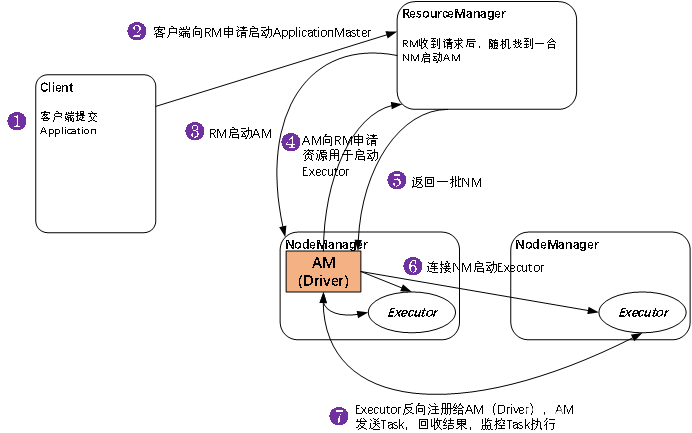
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台NodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
④SparkSQL数据抽象
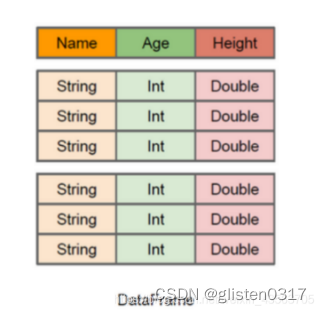
DataFrame是一种以RDD为基础的带有Schema元信息的分布式数据集,类似于传统数据库的二维表格。
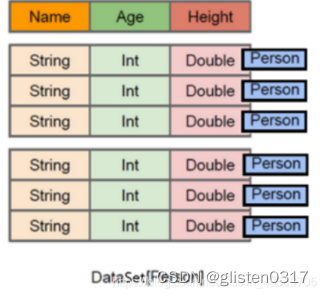
DataSet是保存了更多的描述信息,类型信息的分布式数据集。
与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查,调用Dataset的方法先会生成逻辑计划,然后被spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行!
DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。DataFrame其实就是Dateset[Row]。
RDD、DataFrame、DataSet的区别
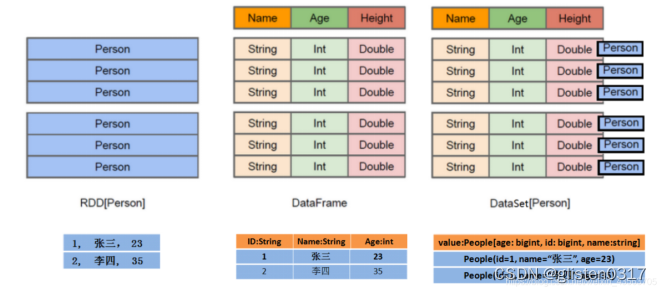
RDD[Person]:以Person为类型参数,但不了解其内部结构
DataFrame:提供了详细的结构信息schema列的名称和类型,更像是一张表
DataSet[Person]:不光有schema信息,还有类型信息
(3)Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
①运行模式
- local 本地测试
- Standallone Cluster 独立集群(做实时计算,不需要hadoop)
- Flink on Yarn
- Kubernetes
②有界流和无界流
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。
数据可以作为无界或有界流处理。
无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
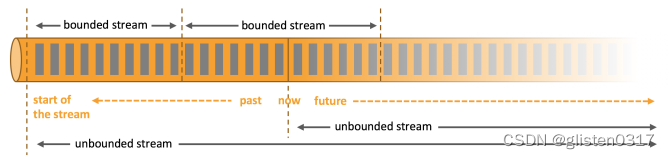
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
③随处部署应用程序
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
Flink旨在很好地适用于之前列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,这些模式允许Flink以其惯用的方式与每个资源管理器进行交互。
部署Flink应用程序时,Flink会根据应用程序配置的并行性自动识别所需资源,并从资源管理器请求它们。如果发生故障,Flink会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都通过REST调用进行。这简化了Flink在许多环境中的集成。
④以任何比例运行应用程序
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink可以轻松维护非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
⑤利用内存中的性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保留在内存中,或者,如果状态大小超过可用内存,则保存在访问高效的磁盘上数据结构中。因此,任务通过访问本地(通常是内存中)状态来执行所有计算,从而产生非常低的处理延迟。Flink通过定期和异步检查本地状态到持久存储来保证在出现故障时的一次状态一致性。
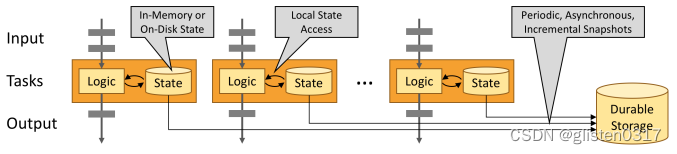
⑥架构
用户通过DataStream API、DataSet API、SQL和Table API编写Flink任务,它会生成一个JobGraph。JobGraph是由source、map()、keyBy()/window()/apply()和Sink等算子组成的。当JobGraph提交给Flink集群后,能够以Local、Standalone、Yarn和Kubernetes四种模式运行。
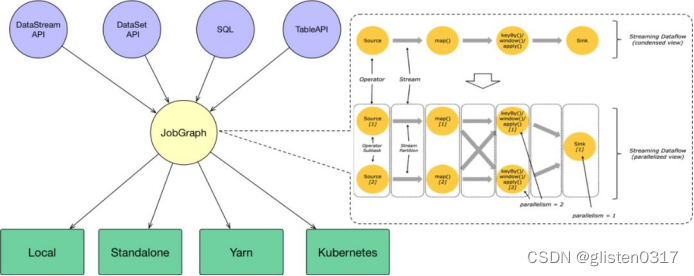
Client:Flink Client用于与JobManger建立连接,进行Flink任务的提交。Client会将Flink任务组装为一个JobGraph并进行提交。一个JobGraph是一个flink dataflow,其中包含了一个Flink程序的:JobID、Job名称、配置信息、一组JobVertex等;
JobManger:Flink系统协调者,负责接收job任务并调度job的多个task执行。同时负责job信息的收集和管理TaskManger;
TaskManger:负责执行计算的Worker,同时进行所在节点的资源管理(包括内存、cup、网络),启动时向JobManger汇报资源信息。
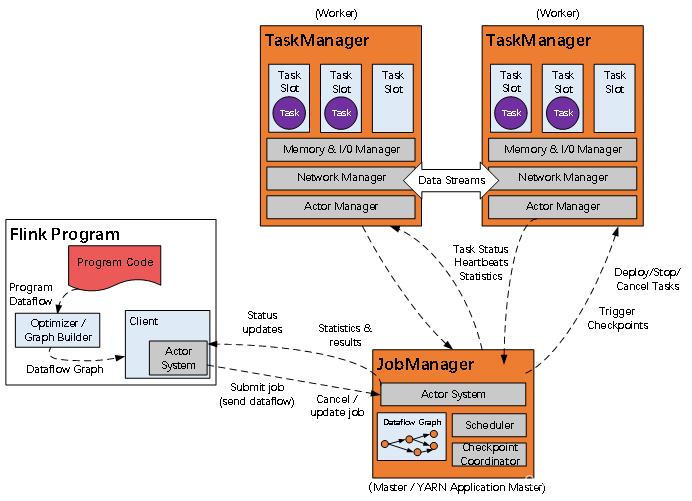
JobManager的功能主要有:
- 将JobGraph转换成Execution Graph,最终将Execution Graph拿来运行;
- Scheduler组件负责Task的调度;
- Checkpoint Coordinator组件负责协调整个任务的Checkpoint,包括Checkpoint的开始和完成;
- 通过Actor System与TaskManager进行通信;
- 其它的一些功能,例如Recovery Metadata,用于进行故障恢复时,可以从Metadata里面读取数据。
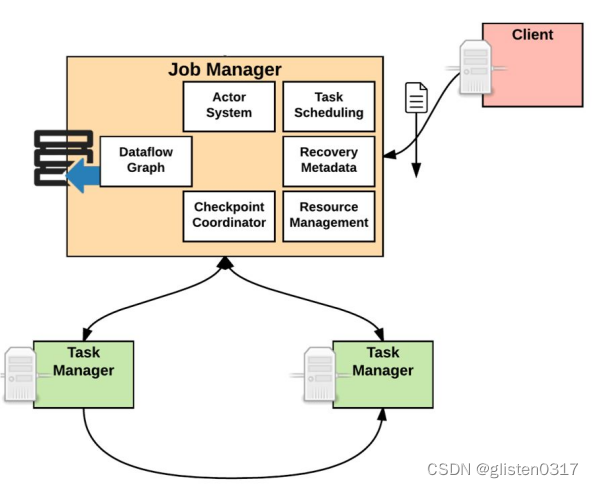
TaskManager的功能主要有:
负责具体任务的执行过程,在JobManager申请到资源之后开始启动。TaskManager里面的主要组件有: - Memory & I/O Manager,即内存I/O的管理;
- Network Manager,用来对网络方面进行管理;
- Actor system,用来负责网络的通信;
TaskManager被分成很多个TaskSlot,每个任务都要运行在一个TaskSlot里面,TaskSlot是调度资源里的最小单位。
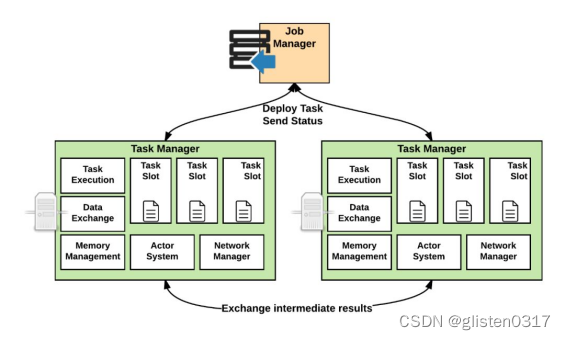
⑦Flink on yarn
flink yarn client负责与yarn RM进行通信及资源申请;
JobManger和TaskManger分别申请Container资源运行各自的进程;
JobManger和YARN AM属于同一个Container中,从而YARN AM可进行申请Container及调度TaskManger;
HDFS用于数据的存储,如checkpoints、savepoints等数据。
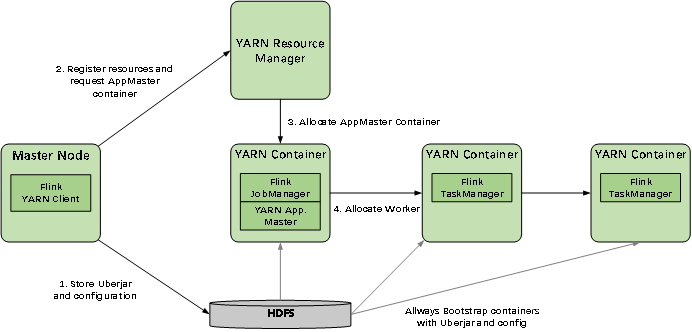
Flink与Yarn的关系与MapReduce和Yarn的关系是一样的。Flink通过Yarn的接口实现了自己的App Master。当在Yarn中部署了Flink,Yarn就会用自己的Container来启动Flink的JobManager(也就是AppMaster)和TaskManager。
启动新的Flink YARN会话时,客户端首先检查所请求的资源(容器和内存)是否可用。之后,它将包含Flink和配置的jar上传到HDFS(步骤1)。
客户端的下一步是请求(步骤2)YARN容器以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定机器上运行的YARN的NodeManager将负责准备容器(例如,下载文件)。完成后,将启动ApplicationMaster(AM)。
该JobManager和AM在同一容器中运行。一旦它们成功启动,AM就知道JobManager(它自己的主机)的地址。它正在为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
之后,AM开始为Flink的TaskManagers分配容器,这将从HDFS下载jar文件和修改后的配置。完成这些步骤后,即可建立Flink并准备接受作业。
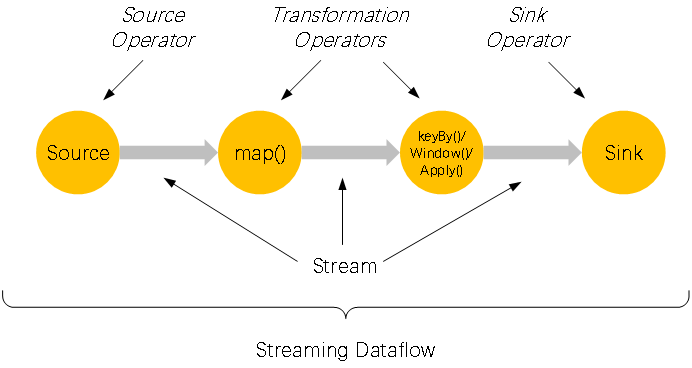
⑧任务执行流程
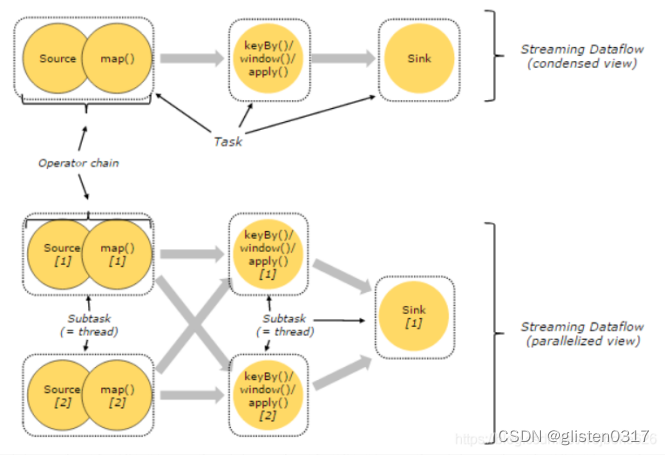
一个flink程序执行时,都会映射为一个Streaming Dataflow 进行处理,类似一个DAG图。从Source开始到Sink结束。
flink程序由一个或多个输入流Stream(Source)经过计算(Transformation), 最终输出到一个或多个输出流Stream中(Sink)。
支持的Source:kafka、hdfs、本地文件…
支持的Sink:kafka、mysql、hdfs、本地文件…
parallel Dataflow(并发原理)
flink程序天生就支持并行及分部署处理:
a、一个Stream支持分为多个Stream分区,一个Operate支持分成多个Operate Subtask,每个Subtask都执行在不同的线程中。
b、一个Operate并行度等于Operate Subtask个数,Stream并行度总等于Operate并行度。
parallel Dataflow示例:
Source并行度为2,Sink并行度为1。

上图展示了Operate与Stream之间存在的两种模式:
a、One-to-one模式:Source[1]–>Map[1]的数据流模式,该模式保持了Source的分区特性及数据处理的有序性。
b、Redistribution模式:map[1]–>apply()[2]的数据流模式,该模式会改变数据流的分区。其与选择的Operate操作有关。
Task & Operator Chain
flink在分布式环境中会将多个Operate Subtask串在一起作为一个Operate Chain的执行链。每个执行链在TaskManger上独立的线程中执行。多个Operate通过Stream进行连接。每个Operate对应一个task。
下图分别展示单个并发与多个并发的执行原理图。
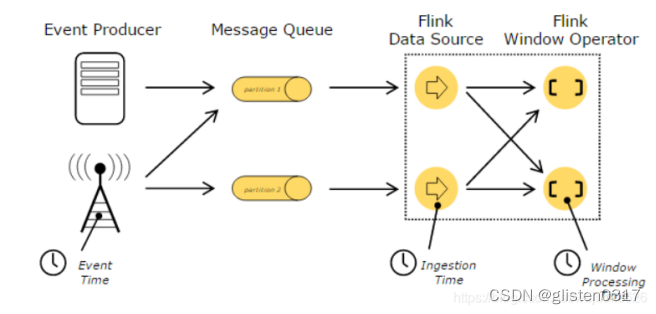
时间窗口
flink支持基于时间和数据的时间窗口。Flink支持基于多种时间的窗口。
a、基于事件的创建时间
b、基于事件进入Dataflow的时间
c、基于某Operate对事件处理时的本地时间
各种时间所处的位置及含义:
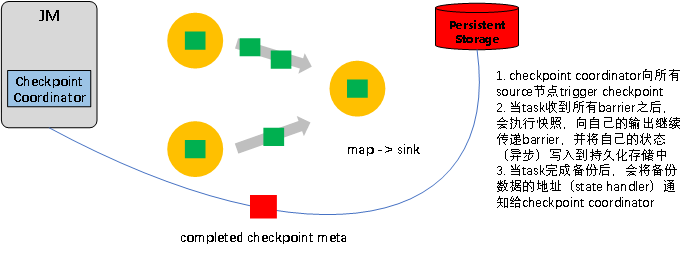
⑨checkpoint原理
flink是在Chandy–Lamport算法的基础上实现的一种分布式快照。通过不断的生成分布式Streaming数据流Snapshot,实现利用snapshot进行数据流的恢复处理。
checkpoint主要步骤
a、Checkpoint Coordinator向所有source节点trigger Checkpoint;
b、source节点向下游广播barrier(附带在数据流中,随DAG流动);
c、task收到barrier后,异步的执行快照并进行持久化处理;
d、sink完成快照后,表示本次checkpoint完成。并将所有快照数据进行整合持久化处理。
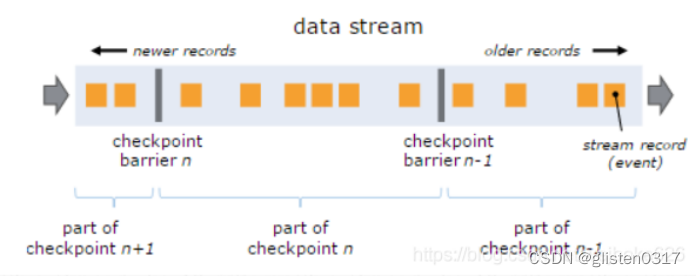
Barrier
a、Stream Barrier是Flink分布式Snapshotting中的核心元素,它会对数据流进行记录并插入到数据流中,对数据流进行分组,并沿着数据流的方向向前推进。
b、每个Barrier会携带一个Snapshot ID,属于该Snapshot的记录会被推向该Barrier的前方。Barrier非常轻量,不会中断数据流处理。
带有Barrier的数据流图:
Strean Aligning
当Operate具有多个数据输入流时,需在Snapshot Barrier中进行数据对齐处理。
具体处理过程:
a、Operator从一个incoming Stream接收到Snapshot Barrier n,然后暂停处理,直到其它的incoming Stream的Barrier n(否则属于2个Snapshot的记录就混在一起了)到达该Operator。
b、接收到Barrier n的Stream被临时搁置,来自这些Stream的记录不会被处理,而是被放在一个Buffer中
c、一旦最后一个Stream接收到Barrier n,Operator会emit所有暂存在Buffer中的记录,然后向Checkpoint Coordinator发送Snapshot n
d、继续处理来自多个Stream的记录
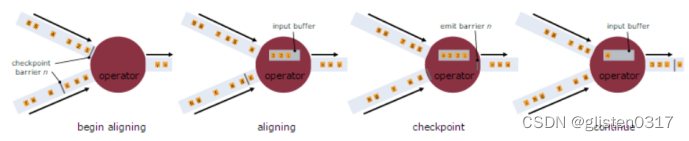
基于Stream Aligning操作能够实现Exactly Once语义,但是也会给流处理应用带来延迟,因为为了排列对齐Barrier,会暂时缓存一部分Stream的记录到Buffer中。通常以最迟对齐Barrier的一个Stream做为处理Buffer中缓存记录的时刻点。可通过开关,选择是否使用Stream Aligning,如果关掉则Exactly Once会变成At least once。
State Backend(数据持久化方案)
flink的State Backend是实现快照持久化的重要功能,flink将State Backend抽象成一种插件,支持三种State Backend。
a、MemoryStateBackend:基于内存实现,将数据存储在堆中。数据过大会导致OOM问题,不建议生产环境使用,默认存储的大小为4M。
b、FsStateBackend:将数据持久化到文件系统包括(本地,hdfs,Amazon,阿里云),通过地址进行指定。
c、RocksDBStateBackend:RocksDB是一种嵌入式Key-Value数据库,数据实际保存在本地磁盘上。比起FsStateBackend的本地状态存储在内存中,RocksDB利用了磁盘空间,所以可存储的本地状态更大。从RocksDB中读写数据都需要进行序列化和反序列化,读写成本更高。允许增量快照,每次快照时只对发生变化的数据增量写到分布式存储上,而不是将所有的本地状态都拷贝过去。
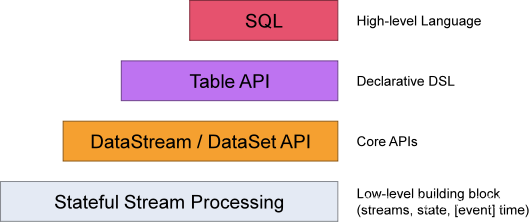
⑩Flink的编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序。
⑪Flink on YARN模式
flink on yarn主要有两种运行模式。一种是内存集中管理模式(即Session-Cluster模式),另一种是内存job管理模式(即Per-Job-Cluster模式)。
- Session-cluster模式
在Yarn中初始化一个Flink集群,开辟指定的资源,资源申请到之后,资源永远保持不变,之后我们提交的Flink Jon都在这个Flink yarn-session中,也就是说不管提交多少个job,这些job都会共用开始时在yarn中申请的资源。这个Flink集群会常驻在Yarn集群中,除非手动停止。
如果资源满了,下一个作业就无法提交(阻塞),只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。
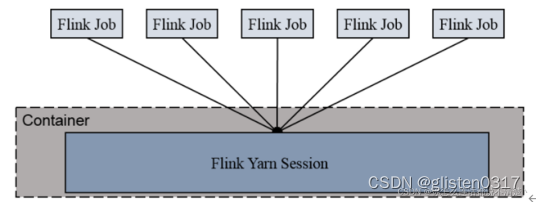
适用场景:
适合规模小、执行时间短的作业。
比如适合小的有界流,不适合无界流,因为无界流的Job 7*24小时运行,始终占用资源,如果Job多了资源不够用,导致Job阻塞
- Per-Job-Cluster模式
先提交job,再启动flink集群。一个job对应一个flink集群,每个flink集群单独向yarn申请资源,因此每个job之间资源不共享、每个job之间互相独立,互不影响,方便管理,一个作业的失败与否并不会影响下一个作业的正常提交和运行。
只有当整个yarn集群资源不足,才会造成任务无法提交了。
job执行完成之后对应的集群也会消失。
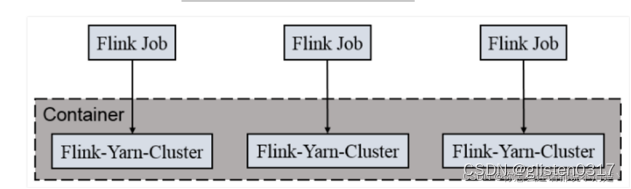
由于每个job独享一个flink集群,每个job独享Dispatcher和ResourceManager,按需接受资源申请。
适用场景:规模大,时间长的任务,无界流任务可用。
5.安全框架
(1)LDAP
轻量目录访问协议,Lightweight Directory Access Protocol,作为目录服务系统,实现了Hadoop的集中账号管理
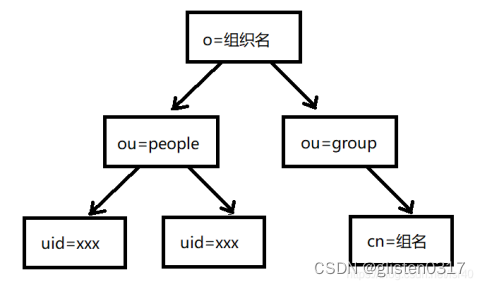
LDAP目录是一种树型结构数据库,适用于一次写入多次查询的场景
域名dc(Domain Component):类似于关系型数据库的中的Database
组织单位ou(Organization Unit):类似于Database中的table的集合
用户uid(User ID):类似于table中的主键
对象名称cn(Common Name):类似于table中的单位数据的名称
LDAP在制作层级的时候,可以在people下创建user,然后在group下创建公司不同的组,然后把uid加到对应的组里面(通过LDAP脚本实现)
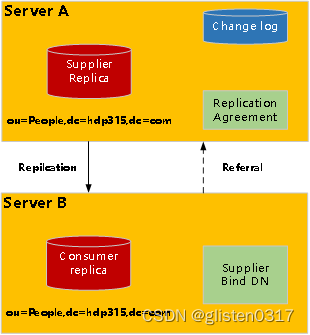
OpenLDAP高可用
当在主服务器上更新数据时,该更新通过更新日志记录,并将更新复制到从服务器上。当在从服务器上更新数据时,该更新请求将重定向给主服务器,然后主服务器将更新数据复制到从服务器。
HA共有5种模式
| 模式 | 特点 |
|---|---|
| Syncrepl | 从(slave)服务器到主(master)服务器以拉的模式同步目录树。当主服务器对某个条目或更多条目修改条目属性时,从服务器会把修改的整个条目进行同步,而不是单独地同步修改的属性值。 |
| Delta-syncrepl | 当主服务器对目录树上的相关条目进行修改时,会产生一条日志信息,于是这时候,从服务器会通过复制协议,将主服务器记录的日志应用到从服务器本地,完成数据同步的过程。但每个消费者获取和处理完全改变的对象,都执行同步操作。 |
| Syncrepl Proxy | 代理同步,它将主服务器隐藏起来,而代理主机上边通过syncrepl从主服务器上以拉的方式同步目录树数据,当代理主机数据发生改变时,代理服务器又以推的方式将数据更新到下属的从LDAP服务器上,且从LDAP服务器只有对代理LDAP服务器有读权限。 |
| N-Way Mulit-Master | 主要用于多台主服务器之间进行LDAP目录树信息的同步,更好的提供了服务器的冗余性。 |
| MirrorMode | 镜像模式,主服务器互相以推的方式实现目录树条目同步,最多只允许且两台机器为主服务器。如果要添加更多的节点,此时只能增加多台从服务器,而不能将添加的节点配置为主服务器。 当一台服务器出现故障时,另一台服务器立即对外提供验证服务。当异常服务器恢复正常时,会自动通过另一个节点所添加或修改的条目信息进行同步,并应用在本地。 |
(2)Kerberos
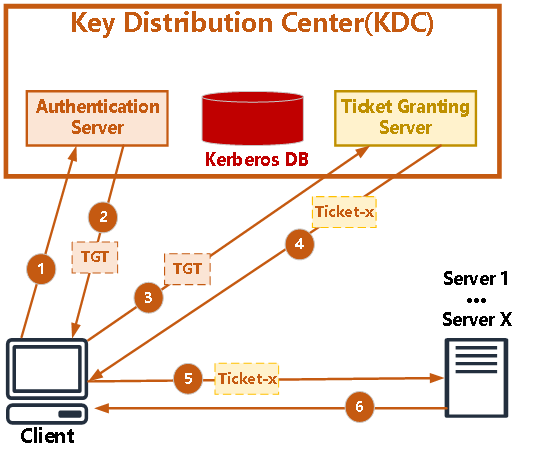
Kerberos是一种身份认证协议,被广泛运用在大数据生态中,甚至可以说是大数据身份认证的事实标准。
KDC由AS和TGS组成,AS进行身份认证发放TGT(Ticket Granting Tickets),TGT是用来避免多次请求而需要重复认证的凭证;TGS发放ST,ST用来访问某个service时的凭证,ST相当于告诉service你的身份被KDC认证为合法的一个凭证。
Kerberos核心概念:
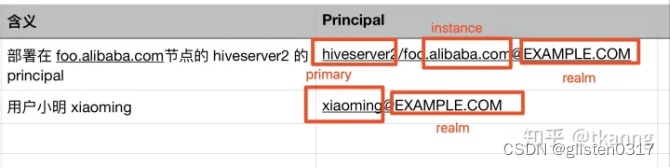
Principal:大致可以认为是Kerberos世界的用户名,用于标识身份。principal主要由三部分构成:primary,instance(可选)和realm。
- 包含instance的principal,一般会作为server端的principal,如:NameNode,HiverServer2,Presto Coordinator等;
- 不含有instance的principal,一般会作为客户端的principal,用于身份认证。
Keytab:“密码本”。包含了多个principal与密码的文件,用户可以利用该文件进行身份认证。
Ticket Cache:客户端与KDC交互完成后,包含身份认证信息的文件,短期有效,需要不断renew。
Realm:Kerberos系统中的一个namespace。不同Kerberos环境,可以通过realm进行区分。
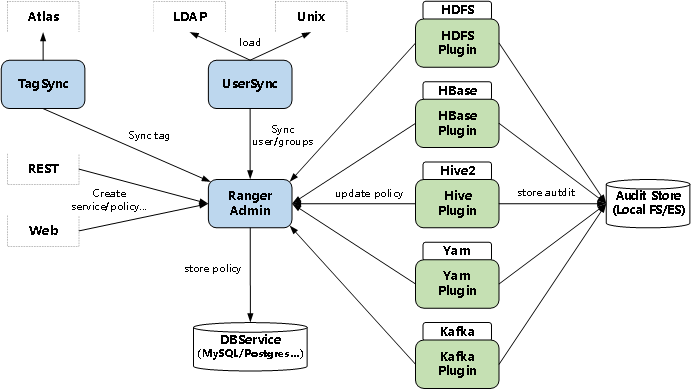
(3)Ranger
Ranger Admin:用于管理安全策略、用户/组的UI门户并提供Rest Server。
Ranger UserSync:定期将Unix系统或LDAP或Active Directory中的用户/组同步到RangerAdmin中。也可用作RangerAdmin的身份验证服务器,以使用linux用户/密码登陆到RangerAdmin。
Ranger TagSync:将资源分类与访问授权分开,只要资源附加相同的标签,就可以有一个标签策略应用于多个组件。可以有助于减少Ranger所需的策略数量,需要Apache Atlas管理元数据(Hive DB/Tables、HDFS路径、Kafka主题和标签/分类等)
Agent Plugin:插件是嵌入到Hadoop各个组件的轻量级java程序。插件定期从AdminServer拉取策略,存储在本地文件中。当用户访问Hadoop组件时,插件会拦截请求根据策略进行安全评估,并且定期发送数据到审计服务器做记录。
6.SQL查询引擎
(1)HIVE2
Hive是一个SQL解析引擎,将SQL语句转译成MR Job,然后再Hadoop平台上运行,达到快速开发的目的。
Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件,达到了元数据与数据存储分离的目的
Hive本身不存储数据,它完全依赖HDFS和MapReduce。
Hive的内容是读多写少,不支持对数据的改写和删除。
① 特点
- Hive采用类SQL开发,简单容易上手,避免了编写MapReduce的工作
- Hive执行延迟比较高,无法胜任实时的工作(OLTP),大多用于数据分析工作(OLAP)
- Hive擅长处理大规模的数据
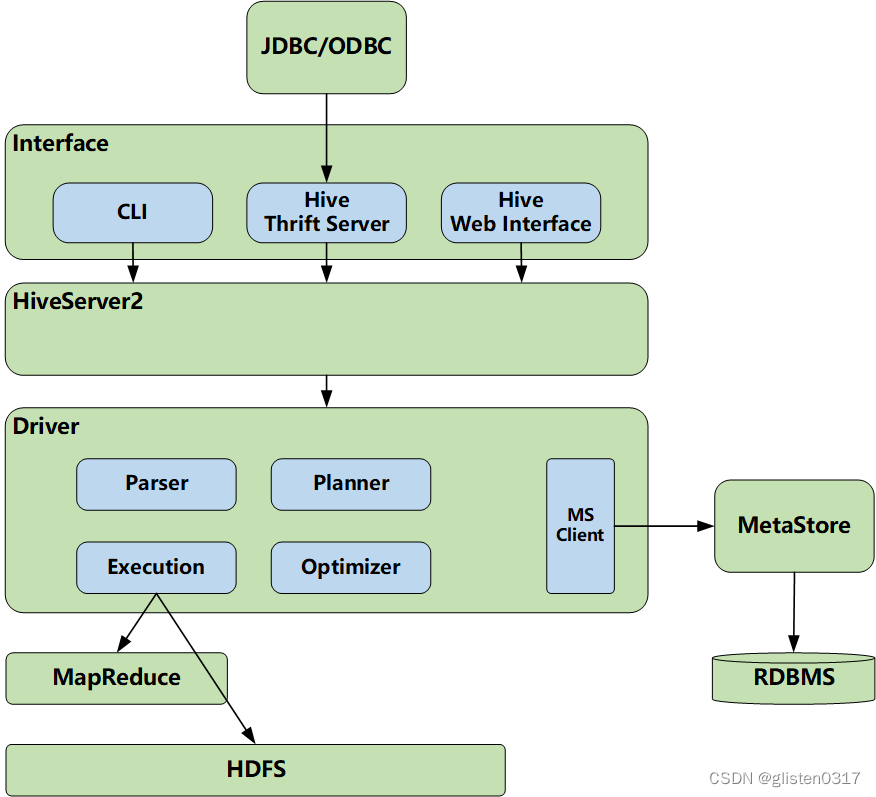
② 系统架构
Interface:Hive提供三个主要的用户接口
- CLI是Shell命令行接口,提供交互式SQL查询
- JDBC/ODBC是Hive的Java数据接口实现,使远程客户端可以通过Hiveserver2查询数据,例如beeline方式
- WebUI用户可以通过浏览器访问Hive页面,查看Hive使用的信息
MetaData:Hive将元数据存储在RMDB中,如mysql\Derby\Postgresql。元数据包括表结构、表名、列属性、分区信息、权限信息及Location等信息。
MetaStore:Hive提供的元数据查询服务,通过MetaStore管理、操作元数据。
Hiveserver2:基于thrift的跨平台、跨编程语言的Hive查询服务。为Hive客户端提供远程访问、查询服务。
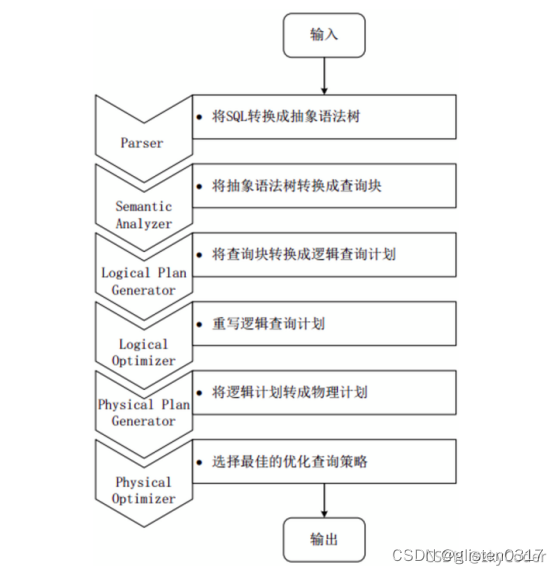
Driver:Hive的核心是驱动引擎,驱动引擎由四部分组成: - 解释器Parser:解释器的作用是将HiveSQL语句转换为抽象语法树
- 编译器Compiler:编译器是将语法树编译为逻辑执行计划
- 优化器Optimizer:优化器是对逻辑执行计划进行优化
- 执行器Execution:执行器是调用底层的运行框架执行逻辑执行计划
③ HiveServer2
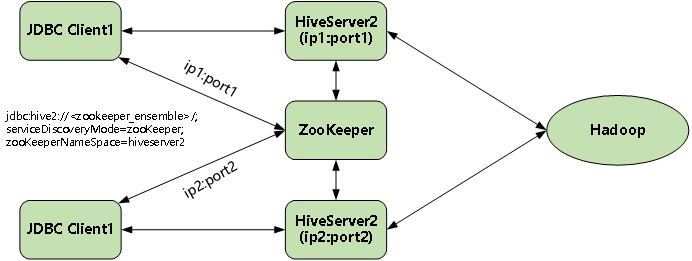
Hive外部连接提供的是一个shell客户端,是直接启动了一个org.apache.hadoop.hive.cli.cliDriver的进程,这个进程主要包含了两块内容,一个是提供交互的cli,另外一个就是Driver驱动引擎,这种情况下如果有多个客户端的情况下,就需要多个Driver,但如果通过HiveServer2连接就可以共享Driver,一方面可以简化客户端的设计降低资源损耗,另外一方面还能降低对MetaStore的压力,减少连接的数量。
在生产环境中使用Hive,强烈建议使用HiveServer2来提供服务,好处很多:
- 在应用端不用部署Hadoop和Hive客户端;
- 相比hive-cli方式,HiveServer2不用直接将HDFS和Metastore暴漏给用户;
- 有安全认证机制,并且支持自定义权限校验;
- 有HA机制,解决应用端的并发和负载均衡问题;
- JDBC方式,可以使用任何语言,方便与应用进行数据交互;
- 从2.0开始,HiveServer2提供了WEB UI。
④ 高可用
MetaStore HA
Hive Metastore HA解决方案旨在处理Metastore服务失败。每当部署的Metastore服务关闭时,Metastore服务在相当长的时间内都会保持不可用状态,直到恢复服务为止。为避免此类停机,在HA模式下部署Metastore服务。
Hive Metastore客户端始终使用第一个URI连接Metastore服务器。如果Metastore服务器变得无法访问,则客户端从列表中随机选取一个URI并尝试与其连接。
HiveServer2 HA
如果只是使用一台服务来启动hiveserver2,那么如果hiveserver2挂掉便不能提供jdbc的支持。hive 支持hiveserver2 HA,用于进行负载均衡和高可用
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能,Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。
⑤ 工作流程
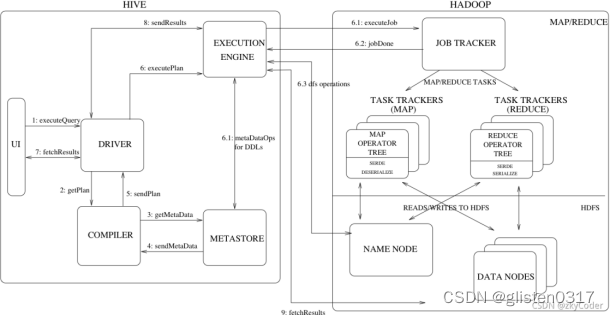
a.用户提交查询任务给Driver;
b.Driver将查询任务给编译器,并请求返回一个plan;
c.编译器向MetaStore获取必要的元数据;
d.MetaStore返回编译器请求的元数据;
e.编译器生成多个stage的DAG作为plan,并将plan交给Driver。每个stage代表着一个map/reduce任务,或一个元数据操作,或一个HDFS操作。这相当于做了一套job的流水线。在Map stage中,plan包含了Map Operator Tree;在Reduce stage中,plan包含了Reduce Operator Tree;
f.Driver上交plan给执行器去执行,获取元数据信息,提交给JobTracker或者ResourceManager去处理该任务,任务会直接读取HDFS中文件进行相应的操作;
g.获取执行的结果;
h.取得并返回执行结果。
⑥ 原理
MapReduce实现基本SQL操作的原理
- SQL转换为MapReduce实现Join
需求:将两个表的数据使用uid连接起来。
SELECT name, orderid FROM User u JOIN Order o ON u.uid=o.uid;
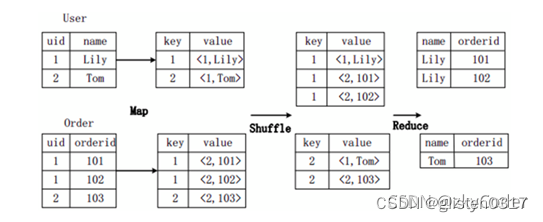
a.两种表进行了join命令,而join on所用的uid正是两个map任务中的key。同时,将表中的其他数据连同各个表的标识id放到value中;
b.通过这种key的选择方式,就可以用shuffle将相同key的不同表的数据聚合在一起;
c.通过shuffle操作后,相同key的数据被聚合到一起,接下来使用reduce把不同表的数据做整合就得到了最后的查询结果。
- SQL转换为MapReduce实现Group By
需求:对一张表的数据进行分组,将同一个rank和level的数据分为一组。
SELECT rank,level,count(*) as value FROM score GROUP BY rank,level;
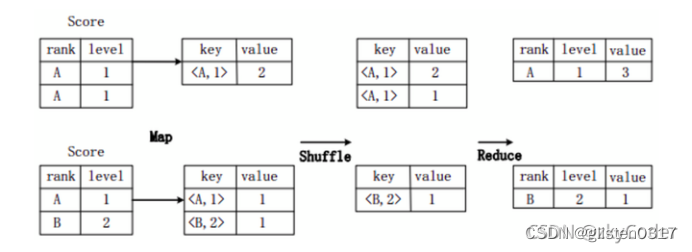
a.sql进行了group by,对rank和level进行分组,也就是说将这两列组合起来当作key,得到像<A, 1>的格式;
b.value记录该数据的出现次数;
c.使用shuffle操作,将相同key的数据分到一起,实现了分组效果;
d.使用reduce操作,将数据进行聚合累加得到最后结果。
SQL转换为MR的具体流程:
a.在编译器中,用Antlr语言识别工具对HQL的输入进行词法和语法解析,将HQL语句转换成抽象语法树(AST Tree)的形式;
b.遍历抽象语法树,转化成QueryBlock查询块。因为AST结构复杂,不方便直接翻译成MR算法程序。其中QueryBlock是一条最基本的SQL语法组成单元,包括输入源、计算过程、和输入三个部分;
c.遍历QueryBlock,生成OperatorTree(操作树),OperatorTree由很多逻辑操作符组成,如TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator和ReduceSinkOperator等。这些逻辑操作符可在Map、Reduce阶段完成某一特定操作;
d.Hive驱动模块中的逻辑优化器对OperatorTree进行优化,变换OperatorTree的形式,合并多余的操作符,减少MR任务数、以及Shuffle阶段的数据量;
e.遍历优化后的OperatorTree,根据OperatorTree中的逻辑操作符生成需要执行的MR任务;
f.启动Hive驱动模块中的物理优化器,对生成的MR任务进行优化,生成最终的MR任务执行计划;
g.最后,有Hive驱动模块中的执行器,对最终的MR任务执行输出。
Hive驱动模块中的执行器执行最终的MR任务时,Hive本身不会生成MR算法程序。它通过一个表示“Job执行计划”的XML文件,来驱动内置的、原生的Mapper和Reducer模块。Hive通过和JobTracker通信来初始化MR任务,而不需直接部署在JobTracker所在管理节点上执行。通常在大型集群中,会有专门的网关机来部署Hive工具,这些网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务。Hive要处理的数据文件常存储在HDFS上,HDFS由名称节点(NameNode)来管理。
⑦ Tez计算引擎
Hive引擎包括:默认MR、Tez、Spark,不更换引擎hive默认的是MR。
MR性能差,资源消耗大,如:Hive作业之间的数据不是直接流动的,而是借助HDFS作为共享数据存储系统,即一个作业将处理好的数据写入HDFS,下一个作业再从HDFS重新读取数据进行处理。很明显更高效的方式是,第一个作业直接将数据传递给下游作业。
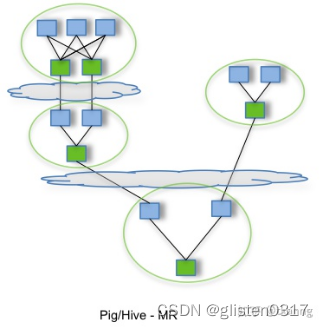
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
7.数据采集
(1)Kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
① 特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
② 应用场景
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等
消息系统:解耦和生产者和消费者、缓存消息等
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
流式处理:比如spark streaming和storm
事件源
③ 消息队列通信的模式
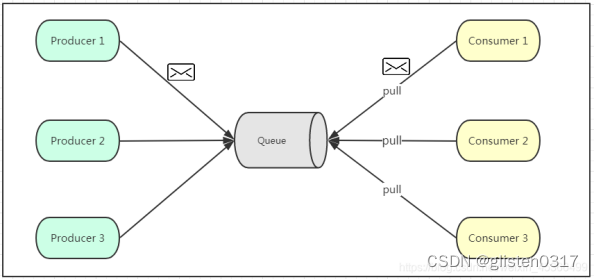
点对点模式
点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
发布订阅模式
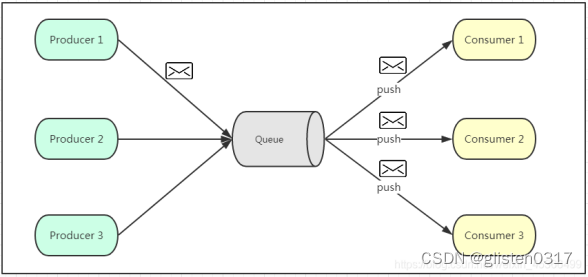
发布订阅模式是一个基于消息送的消息传送模型,改模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!假设三个消费者处理速度分别是8M/s、5M/s、2M/s,如果队列推送的速度为5M/s,则consumer3无法承受!如果队列推送的速度为2M/s,则consumer1、consumer2会出现资源的极大浪费!
④ 架构
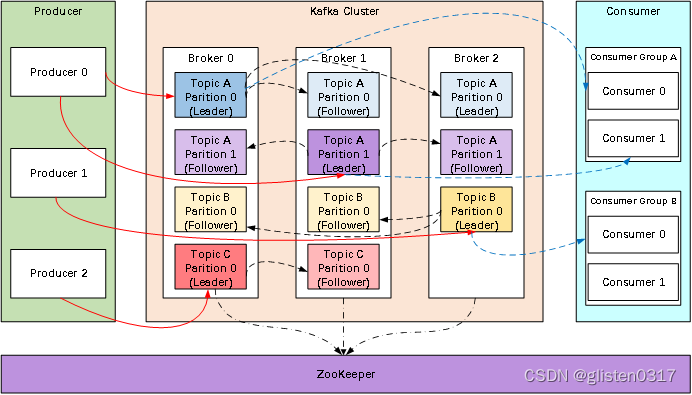
Producer:Producer即生产者,消息的产生者,是消息的入口。
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
⑤ 发送数据流程
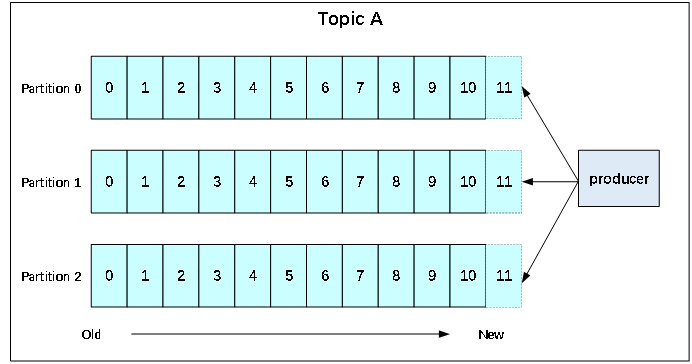
producer就是生产者,是数据的入口。注意看图中的红色箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower。

1、先从集群获取分区的leader
2、producer将消息发送给leader
3、leader将消息写入到本地文件
4、followers从leader pull消息
5、followers将消息写入本地后向leader发送ACK
6、leader收到所有副本的ACK后向producer发送ACK
消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!
分区的主要目的是:
方便扩展:因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
提高并发:以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
在kafka中,如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?kafka中有几个原则:
partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
如果既没指定partition,又没有设置key,则会轮询选出一个partition。
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?其实上面的写入流程图中有描述出来,那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高;1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功;all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
⑥ 保存数据
Producer将数据写入kafka后,集群就需要对数据进行保存了。kafka将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
Partition结构
前面说过了每个topic都可以分为一个或多个partition,如果你觉得topic比较抽象,那partition就是比较具体的东西了。Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件,log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。

如上图,这个partition有三组segment文件,每个log文件的大小是一样的,但是存储的message数量是不一定相等的(每条的message大小不一致)。文件的命名是以该segment最小offset来命名的,如000.index存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
Message结构
上面说到log文件就实际是存储message的地方,我们在producer往kafka写入的也是一条一条的message,那存储在log中的message是什么样子的呢?消息主要包含消息体、消息大小、offset、压缩类型……等等!重点需要知道的是下面三个:
- offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置!
- 消息大小:消息大小占用4byte,用于描述消息的大小。
- 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
存储策略
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢? - 基于时间,默认配置是168小时(7天)。
- 基于大小,默认配置是1073741824。
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能!
⑦ 消费数据流程
消息存储在log文件后,消费者就可以进行消费了。Kafka采用的是发布订阅模式,消费者主动的去kafka集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader去拉取。
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id。同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据。
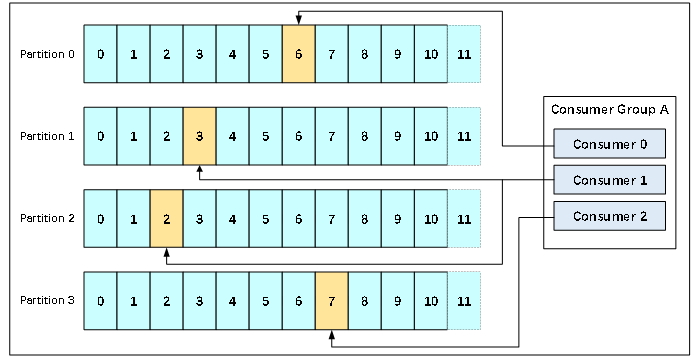
图示是消费者组内的消费者小于partition数量的情况,所以会出现某个消费者消费多个partition数据的情况,消费的速度也就不及只处理一个partition的消费者的处理速度!如果是消费者组的消费者多于partition的数量,多出来的消费者不消费任何partition的数据。所以在实际的应用中,建议消费者组的consumer的数量与partition的数量一致。
partition划分为多组segment,每个segment又包含.log、.index、.timeindex文件,存放的每条message包含offset、消息大小、消息体……我们多次提到segment和offset,查找消息的时候是怎么利用segment+offset配合查找的呢?假如现在需要查找一个offset为368801的message是什么样的过程呢?我们先看看下面的图:
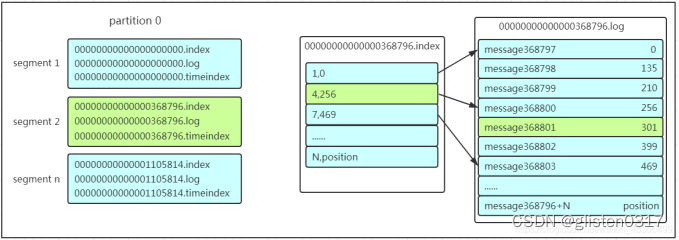
先找到offset的368801message所在的segment文件(利用二分法查找),这里找到的就是在第二个segment文件。
打开找到的segment中的.index文件(也就是368796.index文件,该文件起始偏移量为368796+1,我们要查找的offset为368801的message在该index内的偏移量为368796+5=368801,所以这里要查找的相对offset为5)。由于该文件采用的是稀疏索引的方式存储着相对offset及对应message物理偏移量的关系,所以直接找相对offset为5的索引找不到,这里同样利用二分法查找相对offset小于或者等于指定的相对offset的索引条目中最大的那个相对offset,所以找到的是相对offset为4的这个索引。
根据找到的相对offset为4的索引确定message存储的物理偏移位置为256。打开数据文件,从位置为256的那个地方开始顺序扫描直到找到offset为368801的那条Message。
这套机制是建立在offset为有序的基础上,利用segment+有序offset+稀疏索引+二分查找+顺序查找等多种手段来高效的查找数据!至此,消费者就能拿到需要处理的数据进行处理了。那每个消费者又是怎么记录自己消费的位置呢?在早期的版本中,消费者将消费到的offset维护zookeeper中,consumer每间隔一段时间上报一次,这里容易导致重复消费,且性能不好!在新的版本中消费者消费到的offset已经直接维护在kafk集群的__consumer_offsets这个topic中。
⑧ Controller作用
在Kafka集群中,某个Broker将被选举出来担任一种特殊的角色,其用于管理和协调Kafka集群,即管理集群中的所有分区的状态并执行相应的管理操作。
每个Kafka集群任意时刻都只能有一个Controller。
当集群启动时,所有Broker都参与Controller的竞选,最终有一个胜出,一旦Controller在某个时刻崩溃,集群中的其他的Broker会收到通知,然后开启新一轮的Controller选举,新选举出来的Controller将承担起之前Controller的所有工作。
集群状态的维护是Controller保持运行状态一致性的基本要素,如果要持续稳定的对外提供服务,除了集群状态还有其他的工作需要Controller负责,如下:
- 更新集群元数据信息
一个client可以向集群中任意一台Broker发送METADATA请求来查询topic的分区信息(例如topic有多少个分区、每个分区的leader在哪台Broker上以及分区的副本列表),随着集群的运行,元数据信息可能会发生变化,因此Controller必须提供一种机制,用于随时随地将变更后的分区信息广播出去,同步给集群中所有的Broker,
具体做法是,当有分区信息发生变更时,Controller将变更后的信息封装进UpdateMetaRequests请求中,然后发送给集群中的每个Broker,后续client在请求数据时就可以获取最新、最及时的分区信息。 - 创建topic
Controller启动时会创建一个Zookeeper的监听器,该监听器的唯一任务就是监控Zookeeper节点/brokers/topics下节点的变更情况。
通过client或admin进行topic创建的方式主要有下面3种:
通过kafka-topics脚本的–create创建
构造CreateTopicsRequest请求创建
配置broker端参数auto.create.topics.enable为true,然后发送MetadataRequest请求
无论是上面哪种方式,最终都是在Zookeeper的/brokers/topics下创建一个对应的znode,然后将该topic分区以及对应的副本列表写入到这个znode中,Controller监听器一旦监控到该目录下有新增znode,立即触发topic的创建逻辑,即为新建Topic的每个分区确定leader和ISR,然后更新集群的元数据信息,之后Controller将创建一个新的监听器用于监听Zookeeper的/brokers/topics/<新增 topic>节点内容的变更,之后该topic分区发生变化时,Controller可立即收到通知。 - 删除topic
标准的Kafka删除Topic方式有两种
通过kafka-topics脚本的–delete来删除topic
构造DeleteTopicsRequest
这两种方式都是向Zookeeper的/admin/delete_topics下新建一个znode,Controller启动时会创建一个监听器专门监听该路径下的子节点变更情况,
当发现有新增节点,则Controller开启删除Topic的逻辑,该逻辑主要分为两个阶段:
停止所有副本运行
删除所有副本的日志数据
一旦完成这些操作,Controller将移除/admin/delete_topics/<待删除topic>节点,表示Topic删除操作正式完成。 - 分区重分配
分区重分配操作一般由Kafka集群的管理员发起,用于对Topic的所有分区重新分配副本所在Broker的位置,达到更均匀的分配效果,该操作中,管理员需要手动制定分配方案并按照执行的格式写入Zookeeper的/admin/reassign_partitions节点下。
分区副本重分配的过程实际上是先扩展再收缩的过程,Controller首先将分区副本集合进行扩展,等待它们全部与leader保持同步之后,从新分配方案中的副本选举leader,最后执行收缩阶段,将分区副本集合缩减成分配方案中的副本集合。 - preferred leader选举
为了避免分区副本分配不均匀,Kafka引入了preferred副本的概念,例如一个分区的副本列表是[1,2,3],那么broker1就被称为该分区的preferred leader,因为它位于副本列表的第一位。
在集群运行过程中,分区的leader会因为各种各样的原因发生变更,从而使得leader不再是preferred leader,此时用户可以自行通过命令将分区的leader重新调整为preferred leader,方法有如下两种:
设置broker端参数auto.leader.rebalance.enable为true,Controller将定时自动调整preferred leader
通过kafka-preferred-replica-election脚本手动触发
上面两种方式都向Zookeeper的/admin/preferred_replica_election节点写入数据,同时,Controller将注册该目录的监听器,一旦触发,Controller将对应分区的leader调整回副本列表中的第一个副本,并将此变更广播出去。 - topic分区拓展
在Kafka集群运行过程中,用户可能会发现某Topic的现有分区不足以支撑client的业务量,因此需要新增分区,目前增加分区主要使用kafka-topics脚本的–alter选项来完成,和创建topic一样,它会向Zookeeper的/brokers/topics/节点下写入新的分区目录,因为topic在创建的时候,Controller已经注册过一个监听器用于监听分区目录数据的变化,因此一旦新增了topic分区,该监听器就会被触发,执行对应的分区创建任务(例如选举leader和ISR),之后更新集群的元数据。 - broker加入集群
每个Broker成功启动之后都会在Zookeeper的/broker/ids下创建一个znode,并写入broker的信息,为了动态维护Broker列表,Kafka注册一个Zookeeper监听器用于时刻监控该目录下的数据变化,每当有新Broker加入集群时,该监听器会感知到变化,执行对应的Broker启动任务,之后更新集群元数据信息并广而告之。 - broker崩溃
Broker加入集群时,注册的是临时节点znode,因此一旦Broker崩溃,与Zookeeper的会话失效,临时节点就会被立即删除,因此上面的监听器也可以监视因为崩溃而退出集群的Broker列表,如果发现Broker子目录消失,Controller可立即知道该Broker退出集群,从而开启Broker退出逻辑,最后更新集群元数据并同步到其他Broker上。 - 受控关闭
受控关闭指通过kafka-server-stop脚本、kill -15的方式关闭Broker,Broker崩溃一般是机器突然断电或kill -9导致的,受控关闭可以最大程度的降低Broker的不一致性,由即将关闭的Broker向Controller发送 ControlledShutdownRequest,发送完毕后,待关闭Broker将处于阻塞状态,直到收到 ControlledShutdownResponse 表示关闭成功,或用完所有重试机会后强制退出,Controller在完成必要的leader重选举和ISR收缩调整之后,会向待关闭Broker发送ControlledShutdownResponse表示该Broker现在可以正常退出。
受控关闭是由待关闭Broker发起RPC请求给Controller来实现的,并没有依赖Zookeeper,之前的功能都依赖了Zookeeper来做。 - controller leader选举
如果Kafka当前集群中的Controller发生故障或显式关闭,Kafka必须保证可以及时选出新的leader,即故障转移(fail-over),一般会导致Controller leader选举的场景有如下几种:
关闭Controller所在Broker
当前Controller所在的Broker宕机或崩溃
手动删除Zookeeper的/controller节点
手动向Zookeeper的/controller节点写入新的broker id
上面4种操作都是修改了/controller节点内容,因此Controller只需要做一件事情:创建一个监听该目录的监听器。
/controller本质上是一个临时节点,节点保存了当前Controller所在的broker id,集群首次启动时所有broker都会争抢该节点,但Zookeeper保证最终只有一个Broker胜出并成为Controller,一旦成为Controller,它就会增加Controller的版本号,即更新/controller/_epoch的节点值,然后履行上面的所有职责,对于没有成为Controller的broker而言,它们将继续监听/controller节点的存活情况,并随时准备竞选为新的controller。
(2)Flume
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume最主要是用在分布式系统中,例如读取服务器本地的磁盘数据,并将数据写入到HDFS中。
① 基础架构
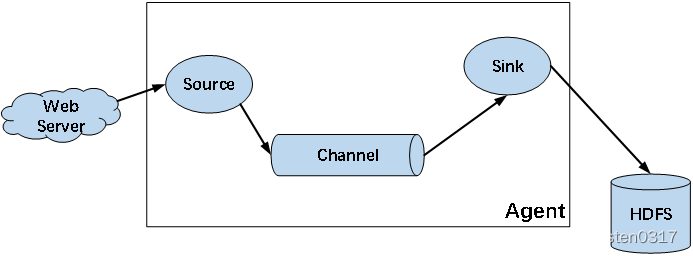
flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
Agent
flume中通过agent进行日志采集、聚合、传输。agent是一个JVM进程,它以事件的形式将数据从源头送至目的。Agent主要有3个部分组成,Source、Channel、Sink。
Source
Source作为Agent的输入口,负责接收各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、taildir、sequence generator、syslog、http、legacy。
Sink
Sink作为Agent的输出口,负责不断轮询Channel中的事件并批量移除事件,根据配置文件的配置将事件写入到HDFS等存储系统,或者发到另一个Agent中。Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel 和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Event
event是flume的数据传输基本单元,event由两部分组成:Header和Body。
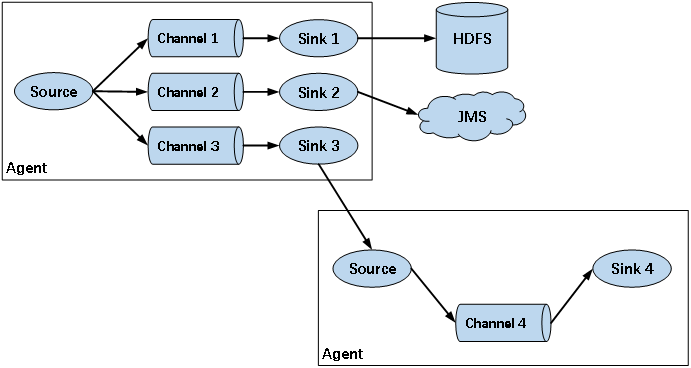
② 广义用法
flume可以支持多级flume的agent,即flume可以前后相继,例如sink可以将数据写到下一个agent的source中,这样的话就可以连成串了,可以整体处理了。flume还支持扇入(fan-in)、扇出(fan-out)。所谓扇入就是source可以接受多个输入,所谓扇出就是sink可以将数据输出多个目的地destination中。
8.列式数据库HBase
HBase是一种面向列存储的非关系型数据库,是在Hadoop之上的NoSQL的Key/value数据库,不支持join的、也不支持ACID、对事务支持有限,无schema(创建表的时候,无需去指定列、列类型)、原生就支持分布式存储的,所以可以用来存储海量数据,同时也兼顾了快速查询、写入的功能。是大数据领域中Key-Value数据结构存储最常用的数据库方案。
HBase作为NoSQL数据库的代表,属于三驾马车之一BigTable的对应实现,HBase的出现很好地弥补了大数据快速查询能力的空缺。
Hbase利用Hadoop的HDFS作为其文件存储系统,利用Hadoop的MapReduce来处理Hbase中的海量数据,利用zookeeper作为其协调工具。
HBase依赖于:ZooKeeper、HDFS,在启动HBase之前必须要启动ZK、HDFS。
(1)架构
HBase的核心架构由五部分组成,分别是HBase Client、HMaster、Region Server、ZooKeeper以及HDFS。
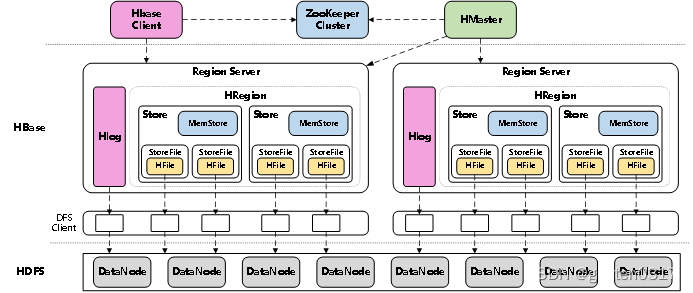
HBase Client
为用户提供了访问HBase的接口,可以通过元数据表来定位到目标数据的RegionServer,另外HBase Client还维护了对应的cache来加速Hbase的访问,比如缓存元数据的信息。
HMaster
HBase集群的主节点,负责整个集群的管理工作,主要工作职责如下:
- 分配Region:负责启动的时候分配Region到具体的RegionServer;
- 负载均衡:一方面负责将用户的数据均衡地分布在各个Region Server上,防止Region Server数据倾斜过载。另一方面负责将用户的请求均衡地分布在各个Region Server上,防止Region Server请求过热;
- 维护数据:发现失效的Region,并将失效的Region分配到正常的RegionServer上,并且在Region Sever失效的时候,协调对应的HLog进行任务的拆分。
RegionServer
直接对接用户的读写请求,是真正的干活的节点,主要工作职责如下。 - 管理HMaster为其分配的Region;
- 负责与底层的HDFS交互,存储数据到HDFS;
- 负责Region变大以后的拆分以及StoreFile的合并工作。
与HMaster的协同:当某个RegionServer宕机之后,ZK会通知Master进行失效备援。下线的RegionServer所负责的Region暂时停止对外提供服务,Master会将该RegionServer所负责的Region转移到其他RegionServer上,并且会对所下线的RegionServer上存在MemStore中还未持久化到磁盘中的数据由WAL重播进行恢复。
Region Serve数据存储的基本结构
Region:每一个Region都有起始RowKey和结束RowKey,代表了存储的Row的范围,保存着表中某段连续的数据。一开始每个表都只有一个Region,随着数据量不断增加,当Region大小达到一个阀值时,Region就会被Regio Server水平切分成两个新的Region。当Region很多时,HMaster会将Region保存到其他Region Server上。
Store:一个Region由多个Store组成,每个Store都对应一个Column Family,Store包含MemStore和StoreFile。
MemStore:作为HBase的内存数据存储,数据的写操作会先写到MemStore中,当MemStore中的数据增长到一个阈值(默认64M)后,Region Server会启动flasheatch进程将MemStore中的数据写人StoreFile持久化存储,每次写入后都形成一个单独的StoreFile。当客户端检索数据时,先在MemStore中查找,如果MemStore中不存在,则会在StoreFile中继续查找。
StoreFile:MemStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。HBase以Store的大小来判断是否需要切分Region。
当一个Region中所有StoreFile的大小和数量都增长到超过一个阈值时,HMaster会把当前Region分割为两个,并分配到其他Region Server上,实现负载均衡。
HFile:HFile和StoreFile是同一个文件,只不过站在HDFS的角度称这个文件为HFile,站在HBase的角度就称这个文件为StoreFile。
HLog:负责记录着数据的操作日志,当HBase出现故障时可以进行日志重放、故障恢复。例如,磁盘掉电导致MemStore中的数据没有持久化存储到StoreFile,这时就可以通过HLog日志重放来恢复数据。
ZooKeeper
HBase通过ZooKeeper来完成选举HMaster、监控Region Server、维护元数据集群配置等工作,主要工作职责如下: - 选举HMaster:通ooKeeper来保证集中有1HMaster在运行,如果HMaster异常,则会通过选举机制产生新的HMaster来提供服务;
- 监控Region Server:通过ZooKeeper来监控Region Server 的状态,当Region Server有异常的时候,通过回调的形式通知HMaster有关Region Server上下线的信息;
- 维护元数据和集群配置:通过ooKeeper储B信息并对外提供访问接口。
HDFS
HDFS为HBase提供底层数据存储服务,同时为HBase提供高可用的支持,HBase将HLog存储在HDFS上,当服务器发生异常宕机时,可以重放HLog来恢复数据。
(2)写流程
Region Server寻址
A、HBase Client访问ZooKeeper;
B、获取写入Region所在的位置,即获取hbase:meta表位于哪个Region Server;
C、访问对应的Region Server;
D、获取hbase:meta表,并查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的Region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问;
写Hlog
E、HBase Client向Region Server发送写Hlog请求;
F、Region Server会通过顺序写入磁盘的方式,将Hlog存储在HDFS上;
写MemStore并返回结果
G、HBase Client向Region Server发送写MemStore请求;
只有当写Hlog和写MemStore的请求都成功完成之后,并将反馈给HBase Client,这时对于整个HBase Client写入流程已经完成。
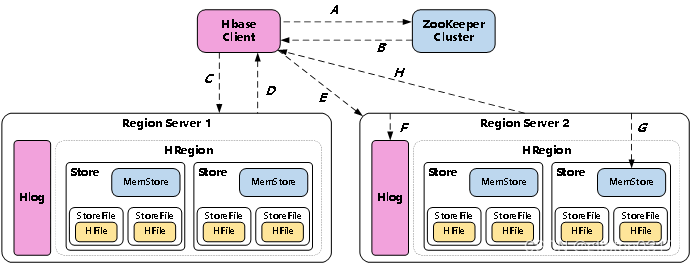
MemStore刷盘
HBase会根据MemStore配置的刷盘策略定时将数据刷新到StoreFile 中,完成数据持久化存储。
为什么要把WAL加载到MemStore中,再刷写成HFile呢?
WAL(Write-Ahead-Log)预写日志是HBase的RegionServer在处理数据插入和删除过程中用来记录操作内容的一种日志。每次Put、Delete等一条记录时,首先将其数据写入到RegionServer对应的HLog文件中去。
而WAL是保存在HDFS上的持久化文件,数据到达Region时先写入WAL,然后被加载到MemStore中。这样就算Region宕机了,操作没来得及执行持久化,也可以再重启的时候从WAL加载操作并执行。
从写入流程中可以看出,数据进入HFile之前就已经被持久化到WAL了,而WAL就是在HDFS上的,MemStore是在内存中的,增加MemStore并不能提高写入性能,为什么还要从WAL加载到MemStore中,再刷写成HFile呢?
数据需要顺序写入,但HDFS是不支持对数据进行修改的;
WAL的持久化为了保证数据的安全性,是无序的;
Memstore在内存中维持数据按照row key顺序排列,从而顺序写入磁盘;
所以MemStore的意义在于维持数据按照RowKey的字典序排列,而不是做一个缓存提高写入效率。
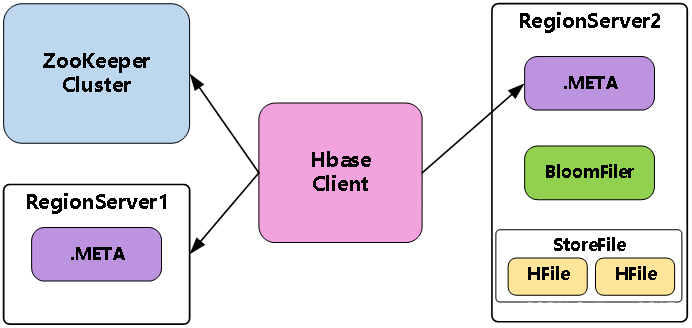
(3)读流程
Region Server寻址
HBase Client请求ZooKeeper获取元数据表所在的Region Server的地址。
Region寻址
HBase Client请求RegionServer获取需要访问的元数据,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
数据读取
HBase Client请求数据所在的Region Server,获取所需要的数据。Region首先在MemStore中查找,若命中则返回;如果在MemStore中找不到,则通过BloomFilter判断数据是否存在;如果存在,则在StoreFile中扫描并将结果返回客户端。
(4)数据删除
HBase的数据删除操作并不会立即将数据从磁盘上删除,因为HBase的数据通常被保存在HDFS中,而HDFS只允许新增或者追加数据文件,所以删除操作主要对要被删除的数据进行标记。
当执行删除操作时,HBase新插入一条相同的Key-Value数据,但是keyType=Delete,这便意味着数据被删除了,直到发生Major_compaction操作,数据才会真正地被从磁盘上删除。
HBase这种基于标记删除的方式是按顺序写磁盘的的,因此很容易实现海量数据的快速删除,有效避免了在海量数据中查找数据、执行删除及重建索引等复杂的流程。
(5)行式存储与列式存储
行式存储的原理与特点
对于OLAP场景,大多都是对一整行记录进行增删改查操作的,那么行式存储采用以行的行式在磁盘上存储数据就是一个不错的选择。
当查询基于需求字段查询和返回结果时,由于这些字段都埋藏在各行数据中,就必须读取每一条完整的行记录,大量磁盘转动寻址的操作使得读取效率大大降低。
举个例子,下图为员工信息emp表。
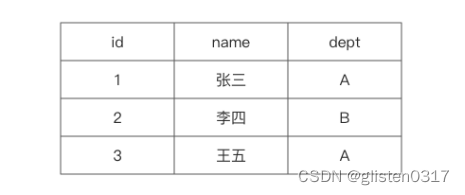
数据在磁盘上是以行的形式存储在磁盘上,同一行的数据紧挨着存放在一起。
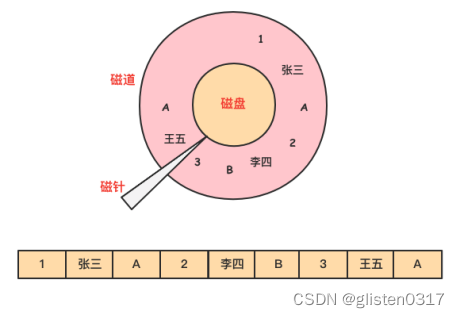
对于emp表,要查询部门dept为A的所有员工的名字。
select name from emp where dept=A
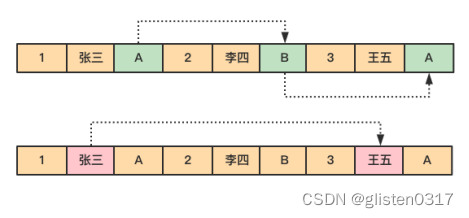
由于dept的值是离散地存储在磁盘中,在查询过程中,需要磁盘转动多次,才能完成数据的定位和返回结果。
列式存储的原理与特点
对于OLAP场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来行式存储中把一整行记录存放在一起的优势就不复存在了。而且,分析型SQL常常不会用到所有的列,而仅仅对其中某些需要的的列做运算,那一行中无关的列也不得不参与扫描。
然而在列式存储中,由于同一列的数据被紧挨着存放在了一起。
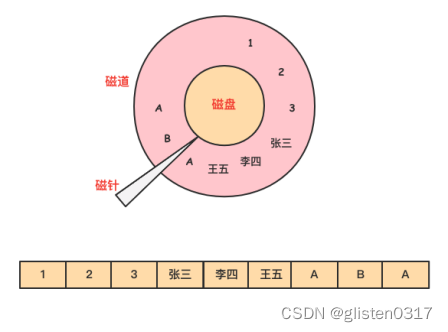
那么基于需求字段查询和返回结果时,就不许对每一行数据进行扫描,按照列找到需要的数据,磁盘的转动次数少,性能也会提高。
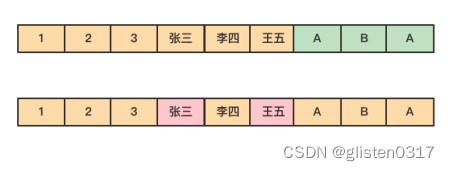
还是上面例子中的查询,由于在列式存储中dept的值是按照顺序存储在磁盘上的,因此磁盘只需要顺序查询和返回结果即可。
列式存储不仅具有按需查询来提高效率的优势,由于同一列的数据属于同一种类型,如数值类型,字符串类型等,相似度很高,还可以选择使用合适的编码压缩可减少数据的存储空间,进而减少IO提高读取性能。
总的来说,行式存储和列式存储没有说谁比谁更优越,只能说谁更适合哪种应用场景。