利用段落检索和生成模型进行开放域问答12.2
利用段落检索和生成模型进行开放域问答
- 摘要
- 引言
- 2 相关工作
- 3 方法
摘要
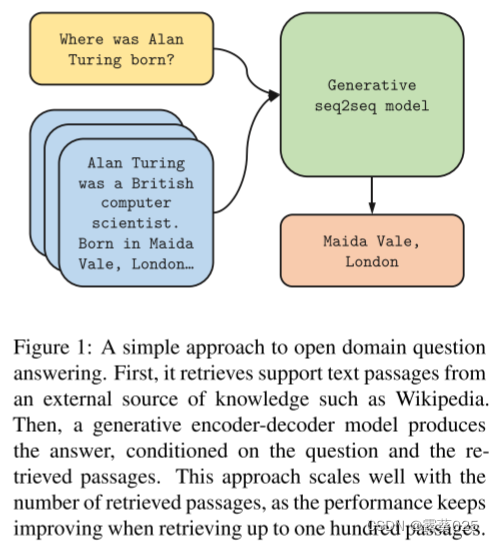
事实证明,开放域问答的生成模型具有竞争力,无需借助外部知识。虽然很有希望,但这种方法需要使用具有数十亿个参数的模型,而这些模型的训练和查询成本很高。在本文中,我们研究了这些模型可以从检索可能包含证据的文本段落中获益多少。我们在 Natural Questions 和 TriviaQA 开放基准测试中获得了最先进的结果。有趣的是,我们观察到当增加检索的段落数量时,该方法的性能显着提高。这证明序列到序列模型提供了一个灵活的框架,可以有效地聚合和组合来自多个段落的证据。
引言
最近,一些工作表明,可以从经过大量数据训练的大规模语言模型中提取事实信息。基于这一观察和自然语言处理模型预训练的进展。2020年引入了开放域问答的生成模型。在不依赖外部知识的情况下,该方法在多个基准测试中获得了有竞争力的结果。然而,它需要包含数十亿个参数的模型,因为所有信息都需要存储在权重中。这使得模型的查询和训练成本高昂。在本文中,我们研究了这种方法可以从访问外部知识源(例如维基百科)中获益多少。
基于检索的方法之前曾在使用提取模型的开放域问答的背景下被考虑过。在这种情况下,系统首先检索支持文档,然后从这些文档中提取答案。我们考虑了不同的检索技术,要么使用基于 TF/IDF 的稀疏表示,要么使用密集嵌入。提取答案的模型通常基于上下文化的单词表示,例如 ELMo 或 BERT,并预测一个范围作为答案。使用提取模型时,聚合和组合来自多个段落的证据并不简单,并且已经提出了多种技术来解决这一限制。
在本文中,我们基于开放域问答的生成建模和检索方面令人兴奋的发展,探索了一种两全其美的简单方法。该方法分两个步骤进行,首先使用稀疏或密集检索支持段落交涉。然后,序列到序列模型生成答案,除了问题之外,还将检索到的段落作为输入。虽然概念上很简单,但该方法在 TriviaQA 和 NaturalQuestions 基准上设置了新的最先进结果。特别是,我们表明,当检索到的段落数量增加时,我们的方法的性能显着提高。我们认为,这证明生成模型比提取模型更擅长结合多个段落的证据。
2 相关工作
开放领域问答 是回答一般领域问题的任务,其中证据不作为系统的输入给出。虽然这是自然语言处理中的一个长期存在的问题,但随着 Chen 等人的工作,这项任务最近重新引起了人们的兴趣,在该版本的问题中,学习系统可以以与答案相对应的跨度的形式进行强有力的监督。陈等人(2017)提出通过首先从维基百科检索支持文档来解决该问题,然后再从检索到的文档中提取答案。人们提出了不同的方法来解决系统没有给出黄金跨度但只给出正确答案的情况。 Clark 和 Gardner(2018)提出在与答案相对应的所有范围内使用全局归一化,后来应用于基于 BERT 的模型。敏等人 (2019) 引入了一种基于硬期望最大化的方法来解决此设置中的噪声监督问题。王等人 (2018) 描述了一种使用置信度和覆盖率得分来汇总不同段落的答案的技术。
段落检索 是开放域问答的重要一步,也是改进 QA 系统的一个活跃的研究领域。最初,基于 TF/IDF 的稀疏表示用于检索支持文档。李等人引入了一种基于 BiLSTM 的监督学习方法来对段落进行重新排序,而 Wang 等人 (2018) 通过强化学习训练了一个排名系统。改进 QA 系统检索步骤的第二种方法是使用额外信息,例如维基百科或维基数据图。最近,多项研究表明,完全基于密集表示和近似最近邻的检索系统与传统方法具有竞争力。此类模型可以使用问答对形式的弱监督进行训练,或者使用完形填空任务和端到端微调进行预训练。
生成式问答 在之前的工作中主要被考虑用于需要生成答案的数据集。这些数据集的生成方式使得答案与支持文档中的范围不对应,因此需要抽象模型。拉斐尔等人 (2019) 表明,生成模型对于阅读理解任务具有竞争力,例如 SQuAD (Rajpurkar et al., 2016),其中答案是跨度。罗伯茨等人(2020)建议使用大型预训练生成模型,而不使用额外的知识来进行开放域问答。最接近我们的工作,Min 等人(2020)和刘易斯等人 (2020) 引入了用于开放域问答的检索增强生成模型。我们的方法与这些作品的不同之处在于生成模型如何处理检索到的段落。这允许扩展到大量文档,并从大量证据中受益。
3 方法
在本节中,我们将描述我们的开放域问答方法。它分两个步骤进行,首先检索支持段落,然后使用序列到序列模型对其进行处理。
检索。
对于支持段落的检索,我们考虑两种方法:BM25(Robertson et al., 1995)和 DPR(Karpukhin et al., 2020)。
在 BM25 中,段落被表示为词袋,排名函数基于术语和逆文档频率。我们使用带有默认参数的 Apache Lucene1 实现,并使用 SpaCy.2 对问题和段落进行标记。
在 DPR 中,段落和问题被表示为密集向量表示,并使用两个 BERT 网络计算。排名函数是查询和段落表示之间的点积。使用 FAISS 库的近似最近邻进行检索。
阅读。
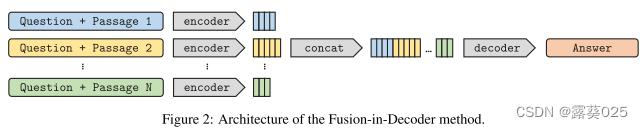
我们的开放域 QA 生成模型基于序列到序列网络,在无监督数据上进行预训练,例如 T5 或 BART。该模型将问题以及支持段落作为输入,并生成答案。更准确地说,每个检索到的段落及其标题都与问题连接在一起,并由编码器独立于其他段落进行处理。我们在每段文章的问题、标题和文本之前添加特殊标记 Question:,title: 和 context: 。最后,解码器对所有检索到的段落的结果表示的串联执行。因此,该模型仅在解码器中执行证据融合,我们将其称为解码器中的融合。
通过在编码器中独立处理通道,但在解码器中联合处理通道,该方法不同于 Min 等人(2020)和刘易斯等人(2020)。在编码器中独立处理段落可以扩展到大量上下文,因为它一次仅对一个上下文执行自关注。这意味着模型的计算时间随着通道数线性增长,而不是二次增长。另一方面,在解码器中联合处理段落可以更好地聚合来自多个段落的证据。