DBS note7 (end):DB Design
目录
一、前言
二、引言
三、Entity-Relationship Models(实体-关系模型)
1、关系约束
三、函数依赖和正则化
1、BCNF分解
2、无损分解
3、依赖关系保留分解
一、前言
略读过一遍CS186,对于CS186来说,绝对不止这 7 篇笔记(包括这一篇)中呈现的内容,我把我的note 7作为该课程的收尾笔记是因为我目前深究课程里面的部分内容性价比不高,我要把精力花在刀刃上,另一原因是我还没有找到比较好的学习数据库的节奏和方法,这7篇note不是结束,只是开始,虽说没有给我带来很多硬核知识上的领悟,但这给我方向上的指引,日后遇到类似知识,可以在博客进行修订补充,不管怎么说,跌跌撞撞前进总比没有前进来得好。结束这一篇note后,下一篇就是新开课程学习著名神课15-445。下面言归正传。
二、引言
到目前为止,我们已经学会了如何使用已经构建好的数据库:SQL查询。但是,如果我们获得了有关我们想要存储的数据的高级描述,我们该怎么设计一个能满足我们需求的数据库呢?
三、Entity-Relationship Models(实体-关系模型)
在设计数据库时,我们经常使用实体-关系模型(也称为 “E-R” 模型)。这些模型有两个主要组成部分。
第一个主要组成部分是实体:由一组属性值描述的现实世界对象。
在我们的 E-R 模型中,实体通常表示为一个矩形。
此外,与实体关联的属性/字段被描绘为椭圆形。
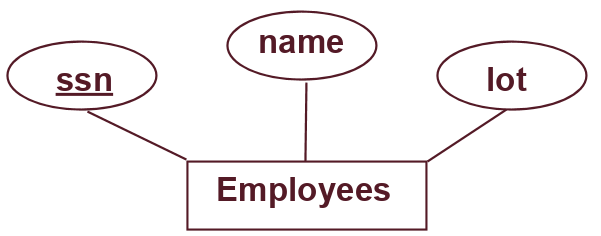
例如,以下图示显示了员工作为实体在我们的 E-R 模型中,具有以下字段:SSN 号码、姓名和其他信息。请注意,“ssn”属性被加下划线,因为它是该实体的识别属性!在模式中,这将是主键。
第二个主要组成部分是关系:两个或多个实体之间的关联。
在我们的 E-R 模型中,关系通常表示为一个菱形。同样,与关系相关的属性被描绘为椭圆形。例如,以下图示显示了员工和部门之间的 “works in” 关系。"works in" 关系具有属性 "since"。

请注意,相同的实体集可以参与不同的关系集,或者在同一个关系集中扮演不同的 “角色”。
1、关系约束
到目前为止,我们一直用一条细黑线将我们的实体连接到关系。这条线表示多对多的关系。这意味着每个实体可以在关系中参与0次或多次,反之亦然。
例如,对于上面的图表,这意味着许多员工可以在许多部门工作(0次或多次),而部门可以有许多员工(0次或多次)。
相比之下,我们希望我们的模型反映每个部门至多有一个经理。我们通过使用 “键约束” 来实现这一点,该约束表示最多有一个,或者是一对多的关系。键约束由细箭头表示。需要注意箭头的方向,它指向在关系中有 0 或 1 的实体,指向有许多实体的方向。例如,对于以下图表,这意味着每个部门最多有一个经理(0 或 1),而员工可以是许多部门的经理(0 次或多次)。
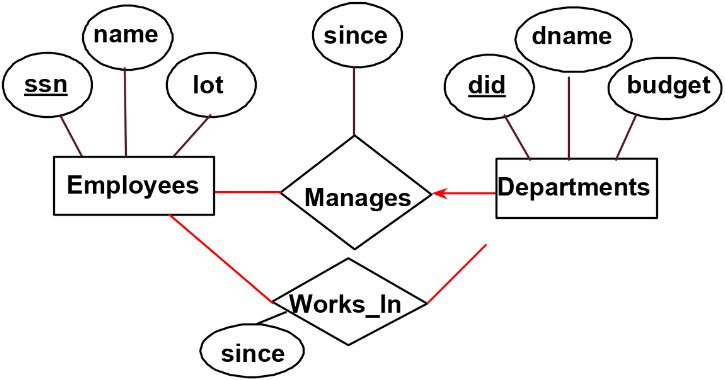
如果我们希望我们的模型显示每个员工至少在一个部门工作,我们可以使用参与约束,该约束表示至少有一个关系。参与约束由一条粗线表示。例如,在下图中,我们添加了两条粗线。其中一条表示每个员工至少在一个部门工作。另一条表示每个部门至少有一个员工。

此外,可以看到我们添加了一条从部门指向管理者的粗箭头。这既是一个键约束,也是一个参与约束:每个部门恰好有一个经理。
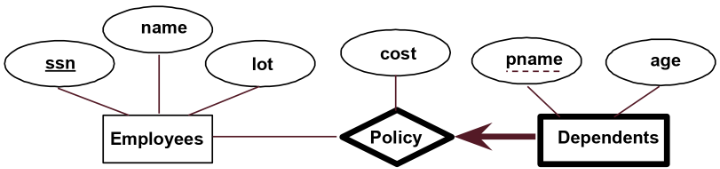
弱实体只能通过考虑另一个(所有者)实体的主键来唯一标识。所有者实体和弱实体必须参与一对多的关系(一个所有者,多个弱实体)。弱实体必须在这个识别关系集中具有总参与度。我们通过加粗矩形和关系来表示弱实体,如下所示。此外,弱实体只有一个 “部分键”(虚线下划线)。在下面的示例中,我们说每个依赖项都通过其 pname 和员工的 ssn 唯一标识,并且每个员工都有 0 个或更多个附属项。
现在我们已经绘制出了我们的 E-R 模型,那么我们如何将其实际组织成关系呢?我们可以将每个实体和关系转化为自己的表,并根据表之间的关系设置主键和外键。一般来说,有很多种方法可以设置关系来表示相同的 E-R 模型。
三、函数依赖和正则化
现在我们已经建立了我们的数据库,我们想要进行优化!我们想要避免的一件事是我们模式中的冗余。这是一种浪费存储空间的情况,同时也会导致插入/删除/更新异常。我们解决这个问题的方法将是函数依赖(Functional Dependencies)。一个函数依赖 X->Y 表示 X 列在表 R 中决定了 Y 列。这意味着对于表 R 中的任意两个元组,如果它们的 X 值相同,那么它们的 Y 值必须相同(但反之则不然)。让我们看几个例子,以更好地理解函数依赖和“决定”是什么意思。在下面的例子中,两行具有相同的 X 值(1),但不同的 Y 值(5和6),因此我们不能说 X 决定了 Y:

对于以下示例,我们可以看到具有相同 X 值的所有行都具有相同的 Y 值。更具体地说,所有 X=1 的行都有 Y=2,所有 X=2 的行都有 Y=4,所有 X=3 的行都有 Y=4。在这种情况下,X 可能确定 Y(即 X->Y):
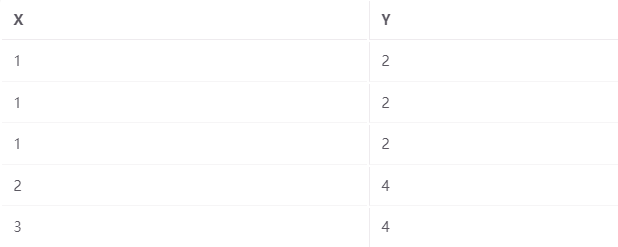
请注意,在上面的示例中,尽管两行的 Y=4,但它们的 X 值不必相同才能说 X 确定 Y。我们只关心特定 X 值的 Y 值是否相同,反之亦然!主键是函数依赖的特殊情况。超键是一组确定表中所有列的列。如果 X 是表 R 的超键,则 X->R。
候选键是一组列,确定表中的所有列,以至于如果我们移除候选键中的任何列,得到的集合将不是关系的超键。您可以将其视为表的超键的最小列集。如果 X 是 R 的候选键,则 X->R,对于每个严格的子集 YX,Y
R。
例如,如果列 K、L 是表中的列,并且 K 是表的主键(即列 K 单独确定表中的所有列),那么 KL 是超键,K 是超键,也是候选键。
我们将使用函数依赖来分解关系以避免冗余。但首先,我们定义 F 的闭包,表示为 F+,是由 F 隐含的所有 FD 的集合。更广泛地说,闭包是可以从已知 FD 推断出的表关系的完整集合。
下面看个例子:

1、BCNF分解
这里只提供一个学习的方向性指引,具体BCNF分解的内容自己去找一下资料,网上很多。
2、无损分解
这里只提供一个学习的方向性指引,具体无损分解的内容自己去找一下资料,网上很多。
3、依赖关系保留分解
这里只提供一个学习的方向性指引。
以上,DBS note7 (end):DB Design