Pandas进阶:拼接 concat 使用方法
1.处理索引和轴
假设我们有2个关于考试成绩的数据集。
df1 = pd.DataFrame({
'name':['A','B','C','D'],
'math':[60,89,82,70],
'physics':[66, 95,83,66],
'chemistry':[61,91,77,70]
})
df2 = pd.DataFrame({
'name':['E','F','G','H'],
'math':[66,95,83,66],
'physics':[60, 89,82,70],
'chemistry':[90,81,78,90]
})
最简单的用法就是传递一个含有DataFrames的列表,例如[df1, df2]。默认情况下,它是沿axis=0垂直连接的,并且默认情况下会保留df1和df2原来的索引。
pd.concat([df1,df2])
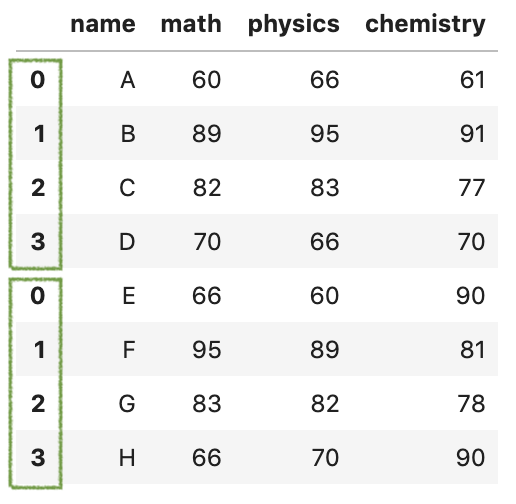
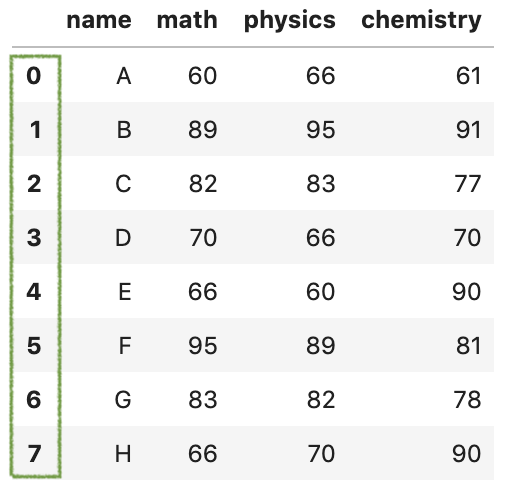
如果想要合并后忽略原来的索引,可以通过设置参数ignore_index=True,这样索引就可以从0到n-1自动排序了。
pd.concat([df1,df2],ignore_index = True)
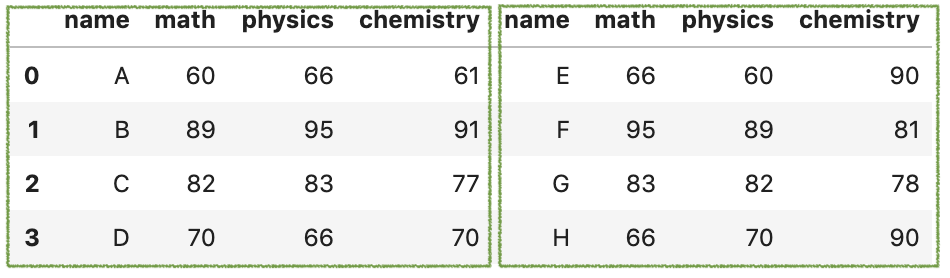
如果想要沿水平轴连接两个DataFrame,可以设置参数axis=1。
pd.concat([df1,df2],axis = 1)
以上是一些基本操作,我们继续往下看。
2.避免重复索引
我们知道了concat()函数会默认保留原dataframe的索引。那有些情况,我想保留原来的索引,并且我还想验证合并后的结果是否有重复的索引,该怎么办呢?
可以通过设置参数verify_integrity=True,将此设置True为时,如果存在重复的索引,将会报错。比如下面这样。
try:
pd.concat([df1,df2], verify_integrity=True)
except ValueError as e:
print('ValueError', e)
ValueError: Indexes have overlapping values: Int64Index([0, 1, 2, 3], dtype='int64')
3.使用keys和names选项添加层次结构索引
添加层次结构索引非常的有用,可以进行更多层的数据分析。
举个例子,某些情况下我们并不想合并两个dataframe的索引,而是想为两个数据集贴上标签。比如我们分别为df1和df2添加标签Year 1和Year 2。
这种情况,我们只需指定keys参数即可。
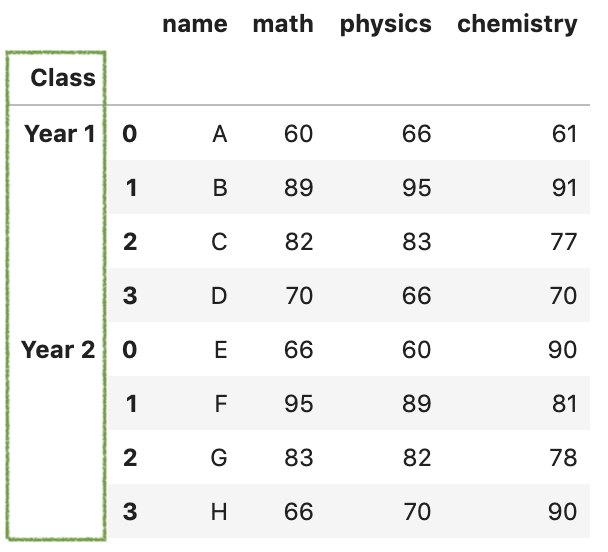
res = pd.concat([df1,df2],keys = ['Year 1','Year 2'])
res
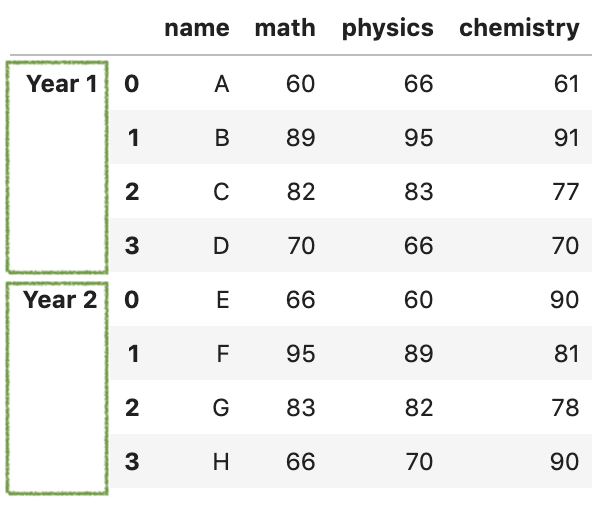
如果我们想要获取Year 1的数据集,可以直接使用loc像下面这样操作:
res.loc['Year 1']
另外,参数names可用于为所得的层次索引添加名称。例如,将名称Class添加到刚创建的的标签上。
pd.concat(
[df1,df2],
keys = ['Year 1','Year 2'],
names = ['Class',None],
)
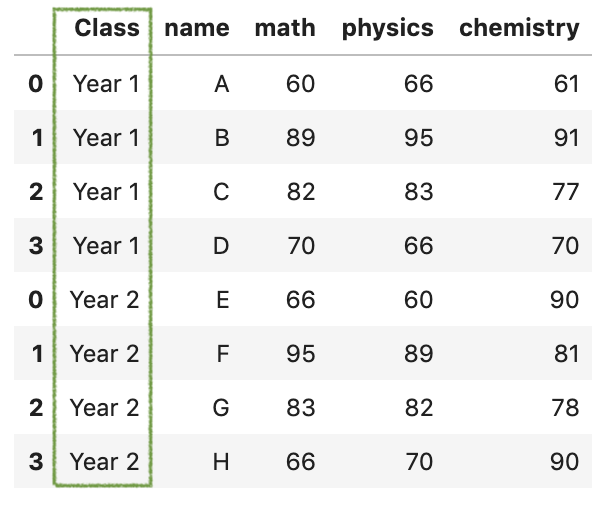
如果要重置索引并将其转换为数据列,可以使用 reset_index(),这一步操作也是非常的实用。
pd.concat(
[df1, df2],
keys=['Year 1', 'Year 2'],
names=['Class', None],
).reset_index(level=0)
# reset_index(level='Class')
4.列匹配和排序
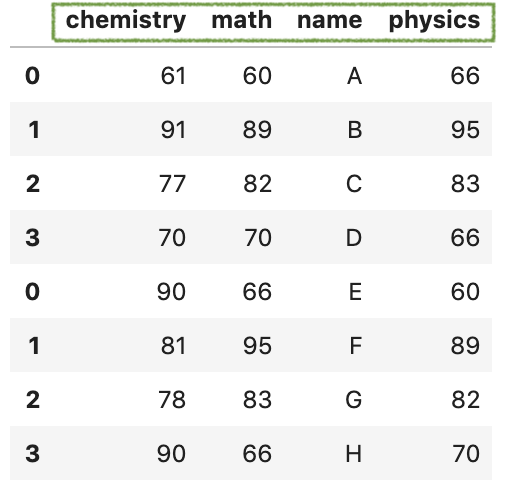
concat()函数还可以将合并后的列按不同顺序排序。虽然,它会自动将两个df的列对齐合并。但默认情况下,生成的DataFrame与第一个DataFrame具有相同的列排序。例如,在以下示例中,其顺序与df1相同。

如果想要按字母顺序对结果DataFrame进行排序,则可以设置参数sort=True。
pd.concat([df1, df2], sort=True)
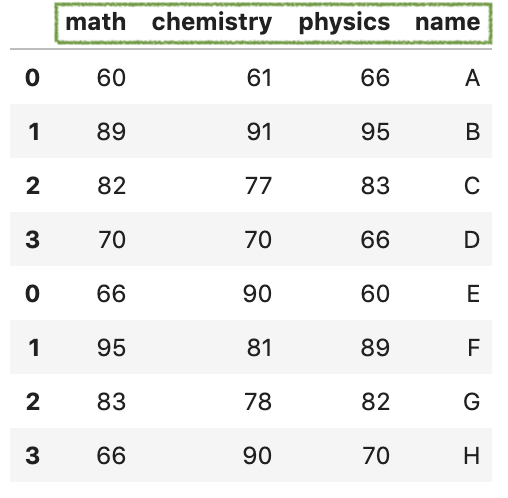
或者也可以自定义排序,像下面这样:
custom_sort = ['math', 'chemistry', 'physics', 'name']
res = pd.concat([df1, df2])
res[custom_sort]
5.连接CSV文件数据集
假设我们需要从一堆CSV文件中加载并连接数据集。常规做法,我们可能会使用for循环解决,比如下面这样。
import pathlib2 as pl2
ps = pl2.Path('data/sp3')
res = None
for p in ps.glob('*.csv'):
if res is None:
res = pd.read_csv(p)
else:
res = pd.concat([res, pd.read_csv(p)])
但上面pd.concat()在每次for循环迭代中都会被调用一次,效率不高,推荐使用列表推导式的写法。
import pathlib2 as pl2
ps = pl2.Path('data/sp3')
dfs = (
pd.read_csv(p, encoding='utf8') for p in ps.glob('*.csv')
)
res = pd.concat(dfs)
res
这样就可以用一行代码读取所有CSV文件并生成DataFrames的列表dfs。然后,我们只需要调用pd.concat(dfs)一次即可获得相同的结果,简洁高效。
使用%%timeit测试下上面两种写法的时间,第二种列表推导式大概省了一半时间。
# for-loop solution
298 ms ± 11.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# list comprehension solution
153 ms ± 6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)