geemap学习笔记019:监督分类与精度验证(上)
前言
上一节中介绍了非监督分类,今天就详细介绍一下监督分类与精度验证。从这一节开始,我也是配置了本地的geemap,就可以不用colab了,配置也是花了挺长时间,但好在也是能够成功应用了,准备用两节的时间介绍监督分类与精度验证。GEE中的监督分类方法主要是包括以下几种,包括决策树、随机森林(RF)、贝叶斯、支持向量机(SVM)等。监督分类主要是包括以下几个步骤:(1)收集数据,包括待分类的影像数据以及标签数据;(2)划分训练集和测试集;(3)利用训练数据训练一个分类器;(3)对原有的数据进行分类;(4)精度验证。
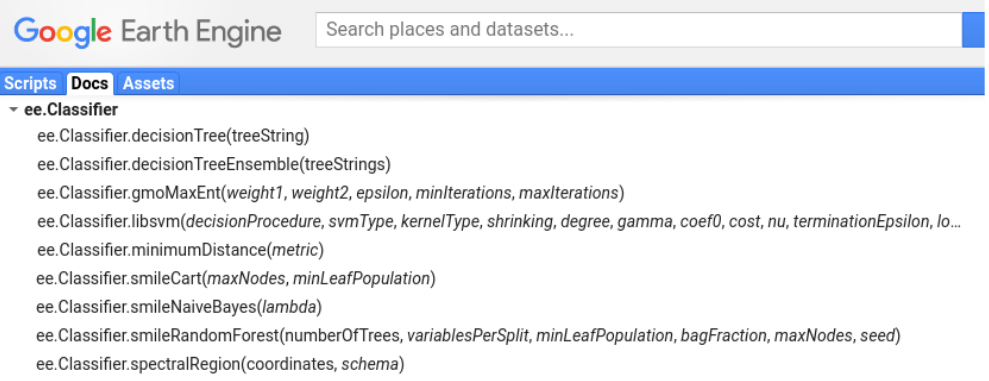
1 导入库并显示地图
import ee
import geemap
ee.Initialize() #这一行代码实在本地代码中要添加的
Map = geemap.Map()
Map
2 添加数据
point = ee.Geometry.Point([-87.7719, 41.8799]) #初始化点坐标
image = (
ee.ImageCollection('LANDSAT/LC08/C01/T1_SR') #Landsat 8数据
.filterBounds(point) #过滤经过该点的影像
.filterDate('2016-01-01', '2016-12-31') #与非监督不同的是,这里取了206年的数据,是为了与NLCD2016相对应
.sort('CLOUD_COVER') #按照云量进行排序
# .limit(10) #可以限制取前多少个
.first() #选择第一景影像
.select('B[1-7]') #选择1-7个波段
)
vis_params = {'min': 0, 'max': 3000, 'bands': ['B5', 'B4', 'B3']}
Map.centerObject(point, 8)
Map.addLayer(image, vis_params, "Landsat-8")
nlcd_raw = ee.Image('USGS/NLCD/NLCD2016').select('landcover').clip(image.geometry()) #加载NLCD数据,并根据影像范围进行裁剪
Map.addLayer(nlcd_raw, {}, 'NLCD')
Map
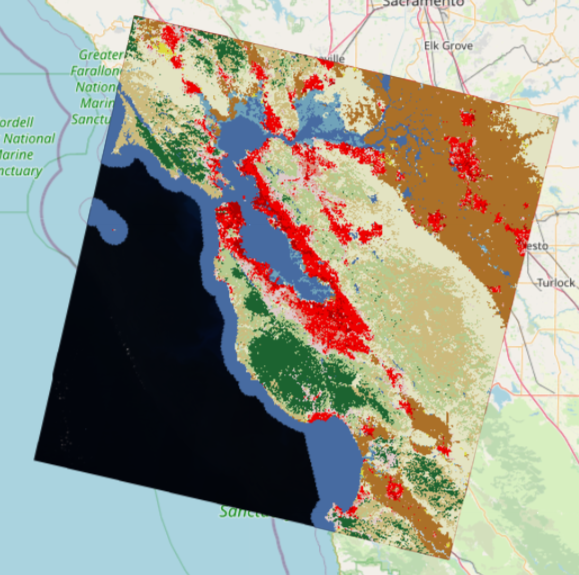
加载数据结果
3 查看图像的属性
ee.Date(image.get('system:time_start')).format('YYYY-MM-dd').getInfo() #时间属性
image.get('CLOUD_COVER').getInfo() #云量属性
4 制作数据集
以NLCD数据创建标签

4.1 准备连续的类别标签
在分类中,标签需要设定从0开始,使用 remap() 函数将类标签转换为连续的整数。
raw_class_values = nlcd_raw.get('landcover_class_values').getInfo() #获取原始数据的标签值
print(raw_class_values)
n_classes = len(raw_class_values)
new_class_values = list(range(0, n_classes)) #定义从0开始的标签
new_class_values
class_palette = nlcd_raw.get('landcover_class_palette').getInfo() #获取原始数据的颜色表
print(class_palette)
nlcd = nlcd_raw.remap(raw_class_values, new_class_values).select(
['remapped'], ['landcover']
) #将原始数据标签值改为新值
nlcd = nlcd.set('landcover_class_values', new_class_values)
nlcd = nlcd.set('landcover_class_palette', class_palette)
4.2 生成样本点数据集
#有多种方法可以创建用于生成训练数据集的区域
# region = Map.user_roi #可以在地图绘制ROI
# region = ee.Geometry.Rectangle([-122.6003, 37.4831, -121.8036, 37.8288]) #可以自定义矩形范围
# region = ee.Geometry.Point([-122.4439, 37.7538]).buffer(10000) #也可以创建缓冲区
# 生成样本点数据集
points = nlcd.sample(
**{
'region': image.geometry(),
'scale': 30,
'numPixels': 5000,
'seed': 0,
'geometries': True, # Set this to False to ignore geometries
}
)
Map.addLayer(points, {}, 'training', False)
Map
print(points.size().getInfo()) #打印样本点的属性
print(points.first().getInfo())
4.3 制作训练和测试数据集
# 利用这些波段用于训练和预测
bands = ['B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7']
# 这个属性储存标签.
label = 'landcover'
# 将点叠加在图像上以获得训练
sample = image.select(bands).sampleRegions(
**{'collection': points, 'properties': [label], 'scale': 30}
)
# 添加一列伪随机数
sample = sample.randomColumn()
split = 0.7 #划分比例
training = sample.filter(ee.Filter.lt('random', split)) #小于0.7划分为训练数据
validation = sample.filter(ee.Filter.gte('random', split)) #大于等于0.7划分为训练数据
print(training.first().getInfo()) #打印第一个点的信息
5 训练分类器
# 使用默认参数训练 CART 分类器
classifier = ee.Classifier.smileCart().train(training, label, bands)
后记
大家如果有问题需要交流或者有项目需要合作,可以加Q Q :504156006详聊,加好友请留言“CSDN”,谢谢。