k8s中批量处理Pod应用的Job和CronJob控制器、处理守护型pod的DaemonSet控制器介绍
目录
一.Job控制器
1.简介
2.Jobs较完整解释
3.示例演示
4.注意:如上例的话,执行“kubectl delete -f myJob.yaml”就可以将job删掉
二.CronJob(简写为cj)
1.简介
2.CronJob较完整解释
3.案例演示
4.如上例的话,执行“kubectl delete -f myCronJob.yaml”就可以将cj删掉,jobs一并被删除
三.DaemonSet(简写ds)
1.简介
2.DaemonSet较完整解释
3.案例演示
4.注意:如上例的话使用“kubectl delete -f myds.yaml ”就可以撒谎从南湖ds,其中的pod也会跟着被删除
一.Job控制器
1.简介
他主要是用于批量地去执行一次性任务,确保在pod上让指定的任务能够正确完成,我们可以在配置中指定期望其完成的数量,执行成功后会记录下成功的数量,执行完成后pod会标识为completed(该pod的主进程已经完成并退出)。
2.Jobs较完整解释
截取至edit Jobs的spec部分
spec:
backoffLimit: 6 #执行失败后的重试次数,不指定就默认6
completionMode: NonIndexed
completions: 18 #期望job成功运行的数量,不指定就默认为1
manualSelector: true #是否可以使用selector选择器,不指定就默认false那么将无法应用selector部分
parallelism: 6 #job执行的并发数量,不指定的话默认1
selector:
matchLabels:
app: job-pod
suspend: false
template:
metadata:
creationTimestamp: null
labels:
app: job-pod
spec:
containers:
- command:
- /bin/sh
- -c
- for i in [1..10];do /bin/echo $i;sleep 2; done;
image: busybox
imagePullPolicy: Always
name: my-job-container
resources: {}
terminationMessagePath: /dev/termination-log #这些参数之前介绍过
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
#这里的重启策略算是比较特殊的,尤其注意这里template.spec的restartPolicy会覆盖模板外设置的restartPolicy
#若为Never,pod出现故障时job会创建新的pod,故障pod不消失,且不重启,failed次数加1。
#若为OnFailure,pod出现故障时job会重启容器,不创建pod,failed次数不变。
#若为Always,一直重启,job就会重复执行,不使用。
置为Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 303.示例演示
这里创建一个Job,执行指定遍历命令,期望运行成功18个pod,每次并发运行6个pod。最后可以观察到是运行了18个pod,pod的最后状态也变为Completed。
[root@k8s-master pod]# cat myJob.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: my-job
namespace: myns
spec:
completions: 18
parallelism: 6
manualSelector: true
selector:
matchLabels:
app: job-pod
template:
metadata:
labels:
app: job-pod
spec:
restartPolicy: Never
containers:
- name: my-job-container
image: busybox
command: ["/bin/sh","-c","for i in [1..10];do /bin/echo $i;sleep 2; done;"]
[root@k8s-master pod]# kubectl apply -f myJob.yaml
job.batch/my-job created
[root@k8s-master pod]# kubectl get pods -n myns -w
NAME READY STATUS RESTARTS AGE
my-job-b6s8s 0/1 ContainerCreating 0 2s
my-job-jc4zz 0/1 ContainerCreating 0 2s
my-job-kts5m 0/1 ContainerCreating 0 2s
my-job-ppltd 0/1 ContainerCreating 0 2s
my-job-shn8q 0/1 ContainerCreating 0 2s
my-job-zb757 0/1 ContainerCreating 0 2s
my-job-kts5m 0/1 ContainerCreating 0 2s
my-job-shn8q 0/1 ContainerCreating 0 2s
my-job-ppltd 0/1 ContainerCreating 0 2s
my-job-jc4zz 1/1 Running 0 5s
my-job-kts5m 1/1 Running 0 6s
my-job-jc4zz 0/1 Completed 0 7s
my-job-zb757 1/1 Running 0 8s
my-job-jc4zz 0/1 Completed 0 8s
my-job-jc4zz 0/1 Completed 0 8s
my-job-kts5m 0/1 Completed 0 8s
my-job-jc4zz 0/1 Completed 0 9s
my-job-2zl7z 0/1 Pending 0 0s
my-job-2zl7z 0/1 Pending 0 0s
my-job-jc4zz 0/1 Completed 0 9s
my-job-2zl7z 0/1 ContainerCreating 0 0s
my-job-shn8q 1/1 Running 0 9s
my-job-kts5m 0/1 Completed 0 9s
my-job-2zl7z 0/1 ContainerCreating 0 0s
my-job-kts5m 0/1 Completed 0 9s
my-job-zb757 0/1 Completed 0 10s
my-job-52mf9 0/1 Pending 0 0s
my-job-52mf9 0/1 Pending 0 0s
my-job-kts5m 0/1 Completed 0 10s
my-job-52mf9 0/1 ContainerCreating 0 0s
my-job-kts5m 0/1 Completed 0 10s
my-job-52mf9 0/1 ContainerCreating 0 0s
my-job-b6s8s 1/1 Running 0 11s
my-job-zb757 0/1 Completed 0 11s
my-job-zb757 0/1 Completed 0 11s
my-job-shn8q 0/1 Completed 0 11s
my-job-zb757 0/1 Completed 0 12s
my-job-ftzpl 0/1 Pending 0 0s
my-job-ftzpl 0/1 Pending 0 0s
my-job-zb757 0/1 Completed 0 12s
my-job-ftzpl 0/1 ContainerCreating 0 0s
my-job-ppltd 1/1 Running 0 12s
my-job-shn8q 0/1 Completed 0 12s
my-job-ftzpl 0/1 ContainerCreating 0 0s
my-job-shn8q 0/1 Completed 0 12s
my-job-b6s8s 0/1 Completed 0 13s
my-job-8hf4n 0/1 Pending 0 0s
my-job-8hf4n 0/1 Pending 0 0s
my-job-shn8q 0/1 Completed 0 13s
my-job-8hf4n 0/1 ContainerCreating 0 0s
my-job-shn8q 0/1 Completed 0 13s
my-job-8hf4n 0/1 ContainerCreating 0 0s
my-job-2zl7z 1/1 Running 0 5s
my-job-b6s8s 0/1 Completed 0 14s
my-job-b6s8s 0/1 Completed 0 14s
my-job-ppltd 0/1 Completed 0 14s
my-job-pxndz 0/1 Pending 0 0s
my-job-b6s8s 0/1 Completed 0 15s
my-job-pxndz 0/1 Pending 0 0s
my-job-b6s8s 0/1 Completed 0 15s
my-job-pxndz 0/1 ContainerCreating 0 0s
my-job-52mf9 1/1 Running 0 5s
my-job-ppltd 0/1 Completed 0 15s
my-job-pxndz 0/1 ContainerCreating 0 0s
my-job-ppltd 0/1 Completed 0 15s
my-job-6tdqn 0/1 Pending 0 0s
my-job-2zl7z 0/1 Completed 0 7s
my-job-6tdqn 0/1 Pending 0 0s
my-job-ppltd 0/1 Completed 0 16s
my-job-6tdqn 0/1 ContainerCreating 0 0s
my-job-ppltd 0/1 Completed 0 16s
my-job-6tdqn 0/1 ContainerCreating 0 0s
my-job-ftzpl 1/1 Running 0 5s
my-job-2zl7z 0/1 Completed 0 8s
my-job-2zl7z 0/1 Completed 0 8s
my-job-52mf9 0/1 Completed 0 7s
my-job-2zl7z 0/1 Completed 0 9s
my-job-cxfmh 0/1 Pending 0 0s
my-job-cxfmh 0/1 Pending 0 0s
my-job-2zl7z 0/1 Completed 0 9s
my-job-cxfmh 0/1 ContainerCreating 0 0s
my-job-8hf4n 1/1 Running 0 5s
my-job-52mf9 0/1 Completed 0 8s
my-job-cxfmh 0/1 ContainerCreating 0 0s
my-job-52mf9 0/1 Completed 0 8s
my-job-ftzpl 0/1 Completed 0 7s
my-job-4zg6h 0/1 Pending 0 0s
my-job-4zg6h 0/1 Pending 0 0s
my-job-52mf9 0/1 Completed 0 9s
my-job-4zg6h 0/1 ContainerCreating 0 0s
my-job-52mf9 0/1 Completed 0 9s
my-job-4zg6h 0/1 ContainerCreating 0 0s
my-job-pxndz 1/1 Running 0 5s
my-job-ftzpl 0/1 Completed 0 8s
my-job-ftzpl 0/1 Completed 0 8s
my-job-8hf4n 0/1 Completed 0 7s
my-job-ftzpl 0/1 Completed 0 9s
my-job-5spg7 0/1 Pending 0 0s
my-job-5spg7 0/1 Pending 0 0s
my-job-ftzpl 0/1 Completed 0 9s
my-job-5spg7 0/1 ContainerCreating 0 0s
my-job-6tdqn 1/1 Running 0 5s
my-job-8hf4n 0/1 Completed 0 8s
my-job-5spg7 0/1 ContainerCreating 0 0s
my-job-8hf4n 0/1 Completed 0 8s
my-job-pxndz 0/1 Completed 0 7s
my-job-dr2mp 0/1 Pending 0 0s
my-job-dr2mp 0/1 Pending 0 0s
my-job-8hf4n 0/1 Completed 0 9s
my-job-dr2mp 0/1 ContainerCreating 0 0s
my-job-8hf4n 0/1 Completed 0 9s
my-job-dr2mp 0/1 ContainerCreating 0 0s
my-job-cxfmh 1/1 Running 0 5s
my-job-pxndz 0/1 Completed 0 8s
my-job-pxndz 0/1 Completed 0 8s
my-job-6tdqn 0/1 Completed 0 7s
my-job-pxndz 0/1 Completed 0 9s
my-job-7wjqq 0/1 Pending 0 0s
my-job-7wjqq 0/1 Pending 0 0s
my-job-pxndz 0/1 Completed 0 9s
my-job-7wjqq 0/1 ContainerCreating 0 0s
my-job-4zg6h 1/1 Running 0 5s
my-job-6tdqn 0/1 Completed 0 8s
my-job-7wjqq 0/1 ContainerCreating 0 0s
my-job-6tdqn 0/1 Completed 0 8s
my-job-cxfmh 0/1 Completed 0 7s
my-job-cz8f4 0/1 Pending 0 0s
my-job-cz8f4 0/1 Pending 0 0s
my-job-6tdqn 0/1 Completed 0 9s
my-job-cz8f4 0/1 ContainerCreating 0 0s
my-job-6tdqn 0/1 Completed 0 9s
my-job-cz8f4 0/1 ContainerCreating 0 0s
my-job-5spg7 1/1 Running 0 5s
my-job-cxfmh 0/1 Completed 0 8s
my-job-cxfmh 0/1 Completed 0 8s
my-job-4zg6h 0/1 Completed 0 7s
my-job-cxfmh 0/1 Completed 0 9s
my-job-cxfmh 0/1 Completed 0 9s
my-job-4zg6h 0/1 Completed 0 8s
my-job-4zg6h 0/1 Completed 0 8s
my-job-5spg7 0/1 Completed 0 7s
my-job-4zg6h 0/1 Completed 0 9s
my-job-4zg6h 0/1 Completed 0 9s
my-job-dr2mp 1/1 Running 0 6s
my-job-7wjqq 1/1 Running 0 5s
my-job-5spg7 0/1 Completed 0 8s
my-job-5spg7 0/1 Completed 0 8s
my-job-5spg7 0/1 Completed 0 9s
my-job-5spg7 0/1 Completed 0 9s
my-job-dr2mp 0/1 Completed 0 8s
my-job-7wjqq 0/1 Completed 0 7s
my-job-cz8f4 1/1 Running 0 6s
my-job-dr2mp 0/1 Completed 0 9s
my-job-dr2mp 0/1 Completed 0 9s
my-job-dr2mp 0/1 Completed 0 10s
my-job-7wjqq 0/1 Completed 0 8s
my-job-7wjqq 0/1 Completed 0 8s
my-job-dr2mp 0/1 Completed 0 10s
my-job-7wjqq 0/1 Completed 0 9s
my-job-7wjqq 0/1 Completed 0 9s
my-job-cz8f4 0/1 Completed 0 8s
my-job-cz8f4 0/1 Completed 0 9s
my-job-cz8f4 0/1 Completed 0 9s
my-job-cz8f4 0/1 Completed 0 10s
my-job-cz8f4 0/1 Completed 0 10s
[root@k8s-master pod]# kubectl get Jobs -n myns
NAME COMPLETIONS DURATION AGE
my-job 18/18 35s 4m15s4.注意:如上例的话,执行“kubectl delete -f myJob.yaml”就可以将job删掉
二.CronJob(简写为cj)
1.简介
他是在借助Job的情况下,按照指定的时间节点去循环重复执行任务。在 CronJob 对象中定义时间表(schedule),该时间表指定了作业运行的时间间隔或特定的运行时间。CronJob 控制器会定期检查时间表,如果当前时间匹配时间表中定义的时间,则创建一个新的 Job 对象,其中包含要执行的任务(如容器镜像、命令、参数等)。
当 Job 对象创建后,k8s会自动将其调度到可用节点上进行运行,并自动管理作业的生命周期,包括启动、监控、重试和清理等操作。执行成功后pod会被表示为completed(该pod的主进程已经完成并退出)。
2.CronJob较完整解释
截取自edit cj的spec部分
spec:
schedule: '*/1 * * * *' #这里是为任务定义时间,分时日月周的顺序书写,控制任务再什么时候执行,如果这里需要指定多个时间时可以用逗号隔开
startingDeadlineSeconds: 300 #同jobs解释
successfulJobsHistoryLimit: 3 #同jobs解释
suspend: false
concurrencyPolicy: Allow
#并发执行策略,用于定义前一次作业运行尚未完成时是否以及如何运行后一次的作业
#默认Allow,允许jobs并发运行
#Forbid,禁止并发运行,上一次的运行失败会跳过下一次运行
#Replace,用新定时任务区替换旧任务的执行
failedJobsHistoryLimit: 1 #同jobs
jobTemplate: #定义job的控制模板,在pod模板外面嵌套一个对job的模板定义,为cronjob控制器生成jobs
metadata:
creationTimestamp: null
spec:
completions: 3 #这里就是jobs的定义了
parallelism: 1
template:
metadata:
creationTimestamp: null
spec:
containers:
- command:
- /bin/sh
- -c
- for i in [1..10]; do /bin/echo $i;sleep 2; done;
image: busybox
imagePullPolicy: Always
name: my-cronjob-container
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
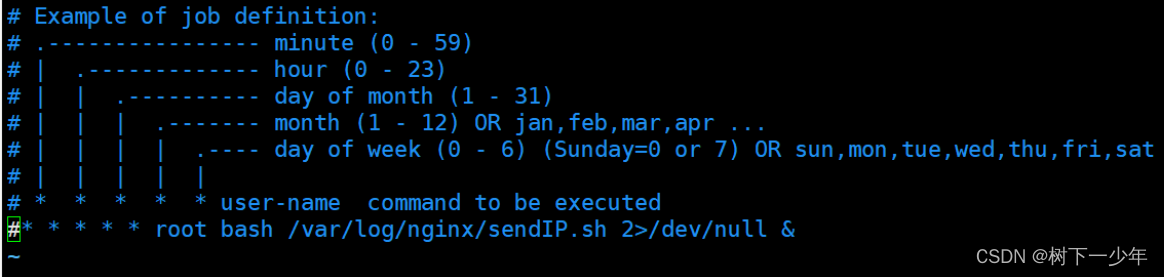
terminationGracePeriodSeconds: 30格式类似于Linux上的这个定时任务(分时日月周),周表示一周中的第几天,可填值如图示
3.案例演示
这里我们创建一个Cronjob,每隔一分钟(只是为了测试效果)执行指定的遍历任务,记录jobs的成功次数。最后结果可以观察jobs的创建时间(25s-85s-2m25s),确实是按照每分钟执行一次
[root@k8s-master pod]# cat myCronJob.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: my-cronjob
namespace: myns
spec:
schedule: "*/1 * * * *"
startingDeadlineSeconds: 300
jobTemplate:
metadata:
spec:
completions: 3
parallelism: 1
template:
spec:
restartPolicy: Never
containers:
- name: my-cronjob-container
image: busybox
command: ["/bin/sh","-c","for i in [1..10]; do /bin/echo $i;sleep 2; done;"]
[root@k8s-master pod]# kubectl get cj -n myns
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
my-cronjob */1 * * * * False 0 53s 3m9s
[root@k8s-master pod]# kubectl get jobs -n myns
NAME COMPLETIONS DURATION AGE
my-cronjob-28354471 3/3 24s 2m25s
my-cronjob-28354472 3/3 24s 85s
my-cronjob-28354473 3/3 23s 25s4.如上例的话,执行“kubectl delete -f myCronJob.yaml”就可以将cj删掉,jobs一并被删除
三.DaemonSet(简写ds)
1.简介
他是保证每个集群的node上运行一个副本,那么就可以得知他适用于节点级pod功能,像日志收集、节点监控这种每个节点只需要一个pod的情况,当集群中有新node加入时,也会自动为其创建pod副本。
2.DaemonSet较完整解释
截取自edit ds的spec部分
spec:
revisionHistoryLimit: 3 #保留历史版本数
selector:
matchLabels:
app: nginx-ds-pod
template:
metadata:
labels:
app: nginx-ds-pod
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: my-nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
updateStrategy: #更新策略
rollingUpdate: #指定滚动更新,和Deployment的差不多
maxSurge: 0
maxUnavailable: 1 #最大不可用pod最大值
type: RollingUpdate #类型为滚动更新3.案例演示
这里我们集群中有两个node,应用一个创建ds的文件,最后可以观察到共创建了两个pod,且确实是两个node上各一个pod。
[root@k8s-master pod]# cat myds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: my-ds
namespace: myns
spec:
revisionHistoryLimit: 3
selector:
matchLabels:
app: nginx-ds-pod
template:
metadata:
labels:
app: nginx-ds-pod
spec:
containers:
- name: my-nginx
image: nginx
[root@k8s-master pod]# kubectl get ds -n myns
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
my-ds 2 2 2 2 2 <none> 13s
[root@k8s-master pod]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 11m v1.28.2
k8s-node1 Ready <none> 10m v1.28.2
k8s-node2 Ready <none> 10m v1.28.2
[root@k8s-master pod]# kubectl get pods -n myns -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-ds-k2vwc 1/1 Running 0 25s 10.244.36.66 k8s-node1 <none> <none>
my-ds-xqsn9 1/1 Running 0 25s 10.244.169.129 k8s-node2 <none> <none>4.注意:如上例的话使用“kubectl delete -f myds.yaml ”就可以撒谎从南湖ds,其中的pod也会跟着被删除