Apache Zeppelin系列教程第一篇——安装和使用
一、Apache Zeppelin 介绍
Apache Zeppelin是一种开源的Web笔记本类型交互式数据分析工具,它提供了基于浏览器的界面,允许数据工程师和科学家通过各种语言和工具,如Scala, Python, SQL, R,等等,交互式地进行数据分析、可视化以及分享。它通过解释器插件架构与不同的数据处理系统(如Apache Spark,Flink,Hive等等)进行集成,使用户能够轻松地使用和切换不同的数据处理引擎。
其主要功能包括:
1. 笔记本界面:提供了一个交互式的Web界面,用户可以轻松地编写和运行代码,查看结果,进行数据可视化,以及方便地管理和分享笔记本。
2. 多语言支持:Zeppelin支持多种语言,比如Scala, Python, R, SQL等等,让用户可以选择最适合任务的编程语言。
3. 解释器插件系统:Zeppelin通过解释器插件来支持不同的数据处理引擎,如Apache Spark,Flink,Hive等。用户可以根据需求安装不同的解释器。
4. 数据可视化:内置了一系列数据可视化工具,无需导出数据到其他平台即可进行各种图表的生成,例如柱状图、饼图、折线图和表格等。
5. 实时协作和共享:支持多人实时协作并共享笔记本,便于团队成员之间的沟通和共享分析结果。 6. 安全性:提供了基于用户和角色的访问控制系统,可以限制对笔记本和解释器的访问,确保数据安全。
总的来说,Apache Zeppelin是一款功能强大的交互式数据分析工具,它适用于数据探索、模型开发、可视化和分享等场景,为数据工程师和科学家提供了一个灵活、高效的分析平台。
ps:也可以看官网上的介绍:Zeppelin
二、快速安装(基于docker)
docker run -d --name zeppelin0.9 -p 8888:8080 apache/zeppelin:0.10.1三、使用
安装完成之后进入页面:localhost:8888
配置Interpreters
1.jdbc配置连接mysql


2.新建notebook 选择jdbc Interpreter,运行sql 即可查询出来数据库中的数据

Zeppelin一些概念解释:
Interpreter:执行器,执行代码执行器,比如:jdbc、spark、python、shell、markdown等等
Notebook:可以理解为页面
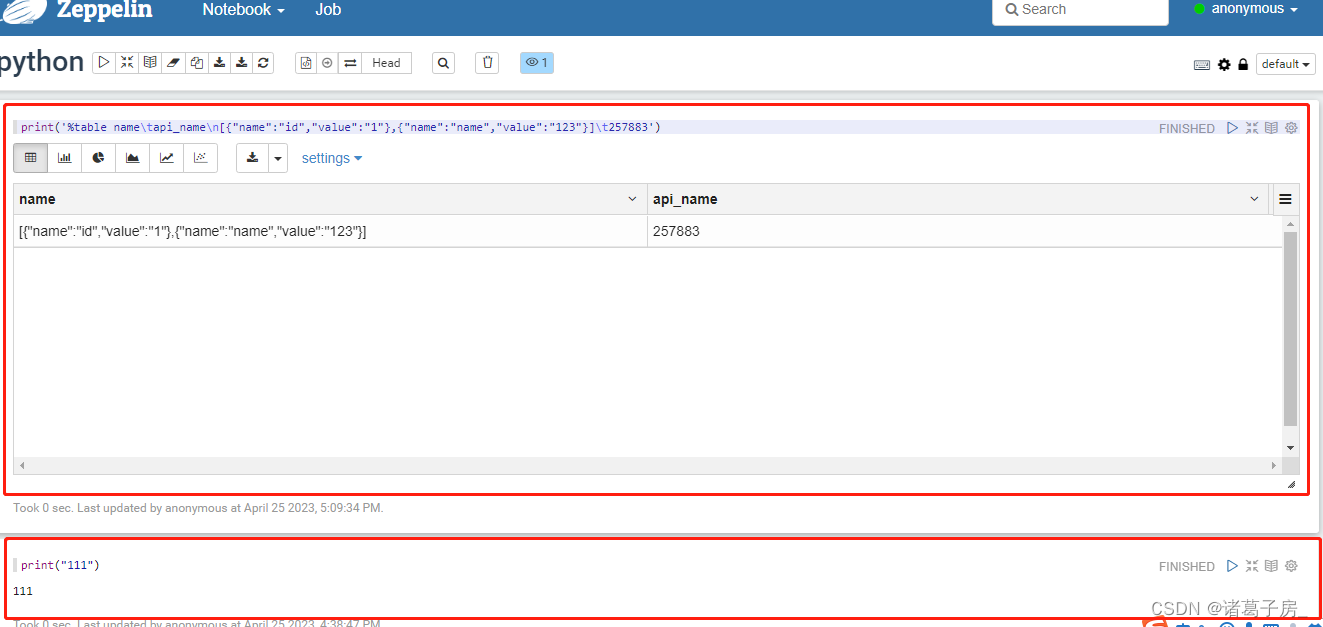
Paragraph:运行的内容
一个Notebook 下可以有多个Paragraph(如下截图所示,一个Notebook两个Paragraph)