用 AudioGPT 输入自然语言,可以让 ChatGPT 唱歌了?
 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 智商掉了一地
借助 ChatGPT 强大的理解与生成能力,结合基础语音模型,集成模型 AudioGPT 诞生了!
最近基于 ChatGPT 的二创如雨后春笋一样冒出,上周我们一起看了黑客松优秀作品大赏,这周又有新脑洞横空出世。有篇将 ChatGPT 用于语音理解与生成任务的文章在近日引起热议。
该模型结合了一些音频基础模型来处理具有挑战性的音频任务,并提供了一个模态转换接口,实现了口语对话功能,它擅长在多轮对话中理解和生成语音、音乐、声音以及说话者特写。虽然这是一个集成模型,但它也展现了 AIGC 工具在更多领域中的潜力。
经过语音和文本之间的转换,借助 ChatGPT 强大的语言理解与生成能力,该模型可以实现用自然语言对于语音进行操作,比如风格迁移、语音识别、语音增强等。甚至还能用自然语言直接指挥 AI,让它声情并茂地演唱《小酒窝》,以及合成说话者特写。也许未来将有机会借助这样的插件,使我们不再局限于与 ChatGPT 进行文本式对话,还可以轻松地创造丰富多样的音频内容。
论文题目:
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
论文链接:
https://arxiv.org/abs/2304.12995
代码地址:
https://github.com/AIGC-Audio/AudioGPT
Huggingface demo 地址:
https://huggingface.co/spaces/AIGC-Audio/AudioGPT
AudioGPT 支持的任务
AudioGPT 可以借助一些基础模型来理解和生成语音、音乐、声音以及说话者特写的任务,利用 ChatGPT 让生成和理解的结果更自然,其中包括:
音频到文本
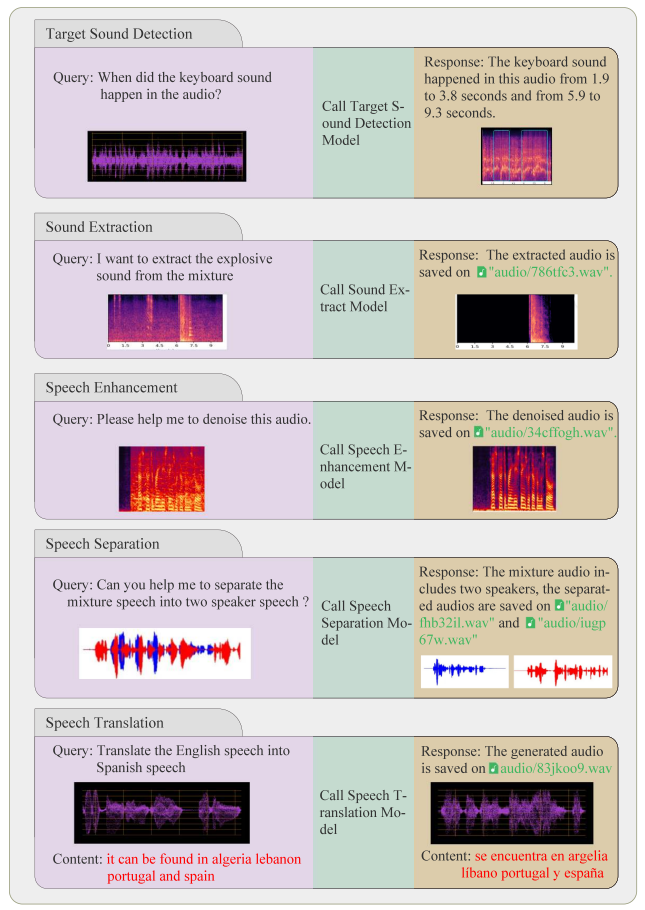
音频文本转换(Speech Recognition):将人类语音转换成文本 - 基础模型 Whisper;
音频翻译(Speech Translation):将人类语音翻译成另一种语言 - 基础模型 MultiDecoder;
音频字幕(Audio Caption):将音频描述转换成文本。
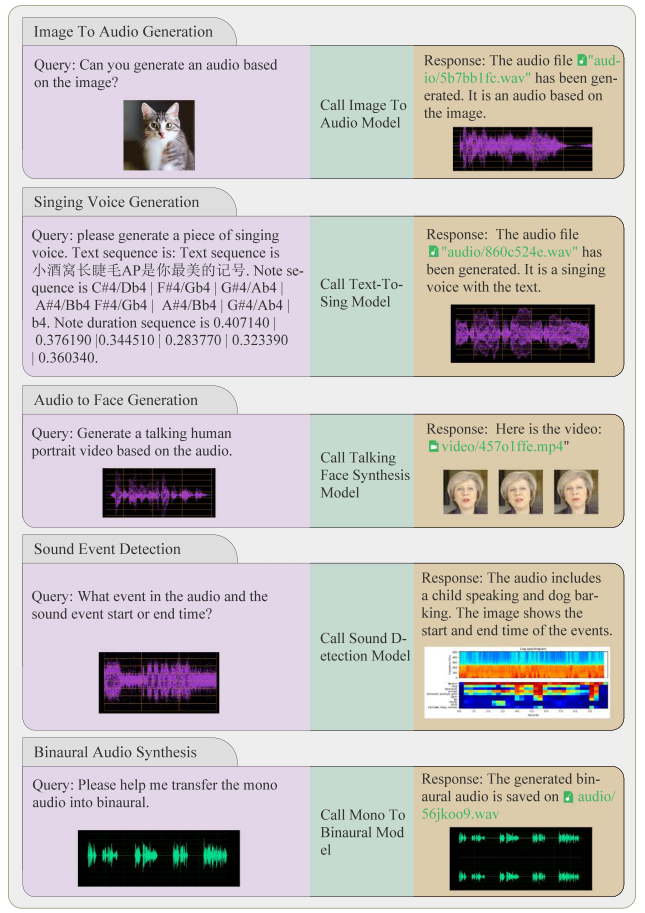
音频到音频
音频风格转换(Style Transfer):根据参考样式生成带有对应风格的人类语音 - 基础模型 GenerSpeech;
音频增强(Speech Enhancement):通过降噪等方式提高语音的质量 - 基础模型 ConvTasNet;
语音分离(Speech Separation):分离混合多种语音的不同音频信号 - 基础模型 TF-GridNet;
单声道转立体声(Mono-to-Binaural):将单声道音频转换成立体声 - 基础模型 NeuralWarp;
填补音频空白(Audio Impainting):根据用户提供的 Mask 修复音频中的缺失部分 - 基础模型 Make-An-Audio。

音频到事件
音频事件提取(Sound Extraction):根据描述提取音频片段;
声音检测(Sound Detection):预测音频中事件的时间轴 - 基础模型 LASSNet。
音频到视频
语音生成头像视频(Talking Head Synthesis):通过输入的音频生成一个说话的人类头像视频 - 基础模型 GeneFace。
文本到音频
文本语音生成(Text-to-Speech):根据用户输入的文本生成人类语音 - 基础模型 FastSpeech 2。
图像到音频
图像音频生成(Image-to-Audio):根据图像生成对应的音频 - 基础模型 Make-An-Audio。
乐谱到音频
乐谱生成歌声(Singing Synthesis):根据输入的文本、音符和节奏生成歌声 - 基础模型 DiffSinger 和 VISinger。
模型速览
支持音频处理的 LLMs 的训练仍然具有挑战性,原因如下:
数据有限:获得人工标注的语音数据是一个昂贵和耗时的任务,而提供真实世界的口语对话的资源仅有少数可用。此外,与庞大的网络文本数据相比,数据量有限,而多语言的对话数据则更为稀缺。
浪费计算资源:从头开始训练多模态 LLM 需要大量的计算资源和时间。鉴于已经存在可以理解和生成语音、音乐、声音和说话者特写的音频基础模型,从头开始训练将是一种浪费。
本文提出的 AudioGPT 是一个多模态的人工智能系统。它针对于上述问题,对目前的 ChatGPT 应用进行了补充,具体有两点:
配备基础模型:处理复杂的音频信息,将 ChatGPT 视为通用接口,解决大量的理解和生成任务。
连接输入/输出接口(ASR,TTS):支持口语对话。

如图 1 所示,AudioGPT 的整个处理过程可以分为四个阶段:
模态转换:使用输入/输出接口进行语音和文字之间的模态转换,以缩小口语 LLM 与 ChatGPT 之间的差距。
任务分析:利用对话引擎和提示管理器帮助 ChatGPT 理解用户的意图来处理音频信息。
模型分配:通过结构化参数来控制韵律、音色和语言,ChatGPT 为理解和生成音频基础模型进行分配。
生成回复:在执行音频基础模型后,生成并返回给用户最终的回复。
实验
为了评估多模态 LLM 在人类意图理解和与基础模型合作方面的能力,作者从一致性、能力和健壮性三个方面对 AudioGPT 进行了实验与评估。
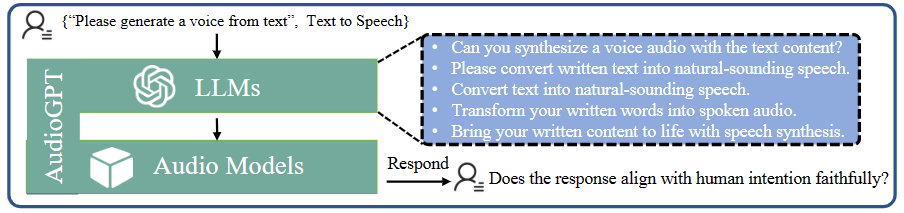
一致性设计
如图 2 所示,作者在这里介绍了如何在没有提供特定任务的训练示例的情况下评估 AudioGPT 的理解和解决问题能力。评估过程分为三个步骤:即提供提示、生成描述和人类评估。
评估的详情如表 1 所示:

能力
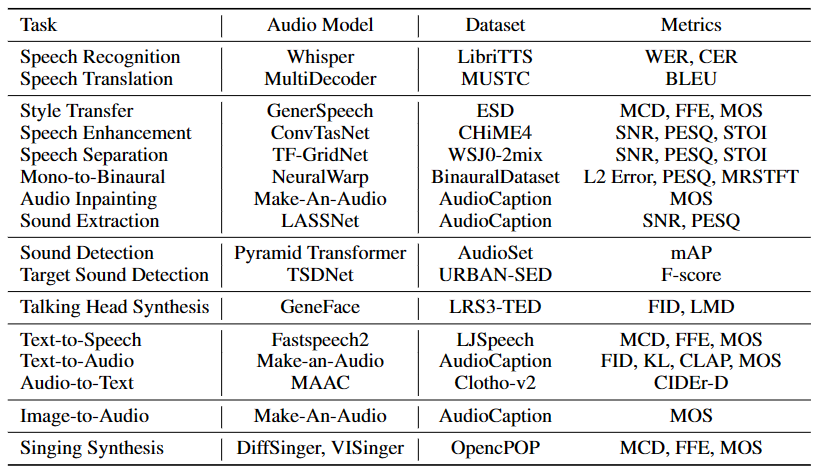
作为处理复杂音频信息的任务执行者,音频基础模型对于处理复杂的下游任务具有重要影响,表 2 中报告了其用于理解和生成语音、音乐、声音和讲话者头像的评估指标和下游数据集。
鲁棒性
作者通过评估多模态 LLM 的鲁棒性来评估它们处理特殊情况的能力,包括长链式查询、不受支持的任务、多模态模型的错误处理以及超越上下文的能力。
为了评估鲁棒性,采用了一个三步的主观用户评分过程。
人类评注员根据上述四个分类提供提示。
将提示馈入 LLM 以制定完整的交互会话。
来自多模态 LLM 的不同受试者组进行对交互会话的评分,以验证其处理特殊情况的能力。
小结
综合来看,尽管 AudioGPT 在解决复杂的音频相关 AI 任务方面表现出色,但也存在一些限制:
Prompt 工程:它需要进行自然语言指令的构建,这需要专业知识和较长的时间,如果不熟悉相关领域,可能会影响指令的效果。
长度限制:聊天机器人当前仍需要考虑到最大标记长度的限制,这可能会影响对话的连贯性和用户的指示说明。
能力限制:AudioGPT 的性能与音频基础模型的准确性和有效性密切相关。
这些限制提醒着我们,在看待这些基于 ChatGPT 的新系统时要保持清醒的认识。同时,也让我们意识到 Prompt 工程对于构建更高效和可靠的 AI 系统至关重要,使其更为普遍且易于使用。我们期待未来能够涌现更多具有开创性的 AI 技术,利用其强大的理解与生成能力,丰富我们的生活、改善日常业务的处理效率。我们拭目以待,并期待着 AIGC 相关的技术日渐成熟,可以更好地服务于人类社会~

