Mybatis总结
-
基本概念:
- Mybatis是一个半ORM框架,内部封装JDBC,开发时只需要关注SQL本身;
- 使用XML或者注解来配置和映射原生信息,将POJO映射成数据库中的记录;
- 具体执行过程:
- 通过XML文件或者注解的方式将要执行的各种statement配置起来,
- 通过java对象和statement中的SQL的动态参数进行映射生成最终执行的SQL语句,
- 最后由Mybatis框架执行SQL并将结果映射为java对象并返回
-
mybatis**的入门案例
- 注意事项:
- 持久层接口必须和.xml文件名保持一致如:testDao 和 testDao.xml
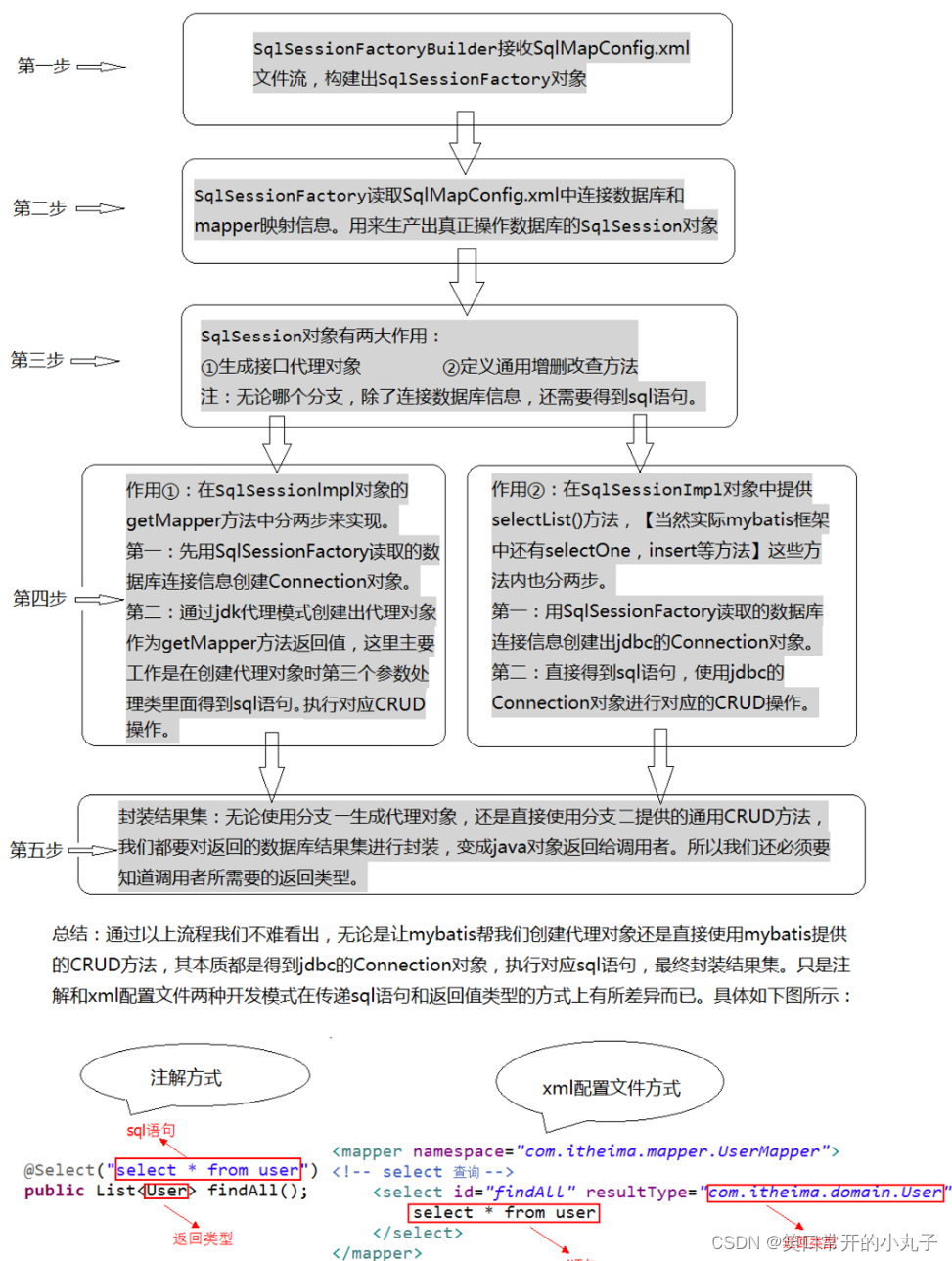
- 执行流程:
- 1、先读取xml配置文件,
- 2、配置文件先读取数据库信息并链接,再读取对应的持久层的xml文件
- 3、持久层xml文件读取1.持久层地址和实体类信息
- 4、执行SQL语句
- 5、通过代理实体类对象开始执行SQL方法,并返回对应的结果集
- */
- mybatis----在 MyBatis 中,反射是用于操作 JavaBean 的实体类对象的,而不是用于操作数据库表中的列名。这是因为 MyBatis 需要将数据库中的数据以及 SQL 查询的结果映射到 JavaBean 的实体对象上,而这个过程就需要使用到反射。
-
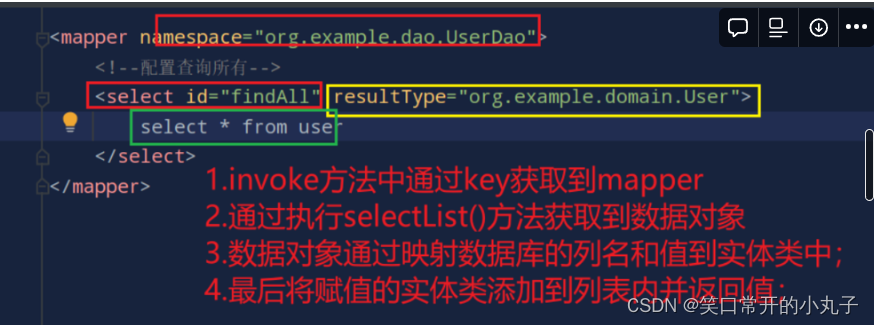
实际的原理过程:
1.invoke方法中通过key获取到mapper
2.通过执行selectList()方法获取到数据对象
3.数据对象通过映射数据库的列名和值到实体类中;
4.最后将赋值的实体类添加到列表内并返回值;
-
public class MybatisTest { /** * 入门案例 核心代码 * @param args */ public static void main(String[] args)throws Exception { //1.读取配置文件 InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml"); //2.创建SqlSessionFactory工厂 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(in); //3.使用工厂生产SqlSession对象 SqlSession session = factory.openSession(); //4.使用SqlSession创建Dao接口的代理对象 UserDao userDao = session.getMapper(UserDao.class); //5.使用代理对象执行方法, List<User> users = userDao.findAll(); for(User user : users){ System.out.println(user); } //6.释放资源 session.close(); in.close(); } } - 注意事项:
-
自定义mybatis
- xml配置文件
- resultType属性:指定结果集的类型
- paramType属性:指定传入参数的类型
- #{}字符: 占位符,自动进行java类型和jdbc类型转换,防止sql注入
- ${}:拼接sql串,可以将paramtype传入的内容拼接在sql中且不进行jdbc类型转换
- session.commit();来实现事务提交
- mybatis好处:
- mybatis自动将java对象映射至sql对象;
- 通过statement中的resultType定义输出结果类型;
- Mybatis 的输出结果封装
-
resultType 属性可以指定结果集的类型,它支持基本类型和实体类类型
-
实体类必须是全限定类名
-
实体类中的属性名称必须和查询语句中的列名保持一致,否则无法实现封装
-
resultMap标签
- 建立查询的列明和实体类属性名称不一致建立对应关系
- 映射对象中包括 pojo 和 list 实现一对一查询和一对多查询
<-- type 属性:指定实体类的全限定类名 id 属性:给定一个唯一标识,是给查询 select 标签引用用的。 --> <resultMap type="com.itheima.domain.User" id="userMap"> <id column="id" property="userId"/> <result column="username" property="userName"/> <result column="sex" property="userSex"/> <result column="address" property="userAddress"/> <result column="birthday" property="userBirthday"/> </resultMap> id 标签:用于指定主键字段 result 标签:用于指定非主键字段 column 属性:用于指定数据库列名 property 属性:用于指定实体类属性名 -
mapper映射器
<mapper resource=" " /> //使用相对于类路径的资源,实现读取xml文件的方式 如:<mapper resource="com/itheima/dao/IUserDao.xml" /> 使用 mapper 接口类路径 实现注解方式 如:<mapper class="com.itheima.dao.UserDao"/> 注意:此种方法要求 mapper 接口名称和 mapper 映射文件名称相同,且放在同一个目录中 -
Mybatis 连接池与事务深入
-
数据源分为三类
我们的数据源配置就是在 SqlMapConfig.xml 文件中,具体配置如下: <!-- 配置数据源(连接池)信息 --> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource> MyBatis 在初始化时,根据<dataSource>的 type 属性来创建相应类型的的数据源 DataSource,即: type=”POOLED”:MyBatis 会创建 PooledDataSource 实例 type=”UNPOOLED” : MyBatis 会创建 UnpooledDataSource 实例 type=”JNDI”:MyBatis 会从 JNDI 服务上查找 DataSource 实例,然后返回使 -
Mybatis 的事务控制
-
setAutoCommit()进行事务控制
为什么 CUD 过程中必须使用 sqlSession.commit()提交事务? 主要原因就是在连接池中取出的连接,都会将调用 connection.setAutoCommit(false)方法; 就必须使用 sqlSession.commit()方法,相当于使用了 JDBC 中的 connection.commit()方法实现事务提交; private InputStream in; private SqlSession sqlSession; private IUserDao userDao; @Before//用于在测试方法执行之前执行 public void init()throws Exception{ //1.读取配置文件,生成字节输入流 in = Resources.getResourceAsStream("SqlMapConfig.xml"); //2.获取SqlSessionFactory SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in); //3.获取SqlSession对象 sqlSession = factory.openSession(true); //4.获取dao的代理对象 userDao = sqlSession.getMapper(IUserDao.class); } @After//用于在测试方法执行之后执行 public void destroy()throws Exception{ //提交事务 // sqlSession.commit(); //6.释放资源 sqlSession.close(); in.close(); }
-
-
动态sql语句
- 动态 SQL 之标签
-
-
多表查询
- 一对一
- 方法一
- 定义账户实体类
- 定义AccountUser继承账户实体类并设置要查询的字段
- 定义账户持久层,返回类型为AccountUser
- 方法二
- Account 类中加入 User 类的对象作为 Account 类的一个属性
- 返回值类型是Account
- association建立xml关系association下指定从表User的实体属性值
- 方法一
- 一对多
- 方法一
- User 类中加入 Account 类的对象作为 User 类的一个属性
- 返回值类型是User
- collection:是用于建立一对多中集合属性的对应关系
- ofType 用于指定集合元素的数据类型
- property 关联查询的结果集存储在 User 对象的上哪个属性
- select 属性:用于指定查询 account 列表的 sql 语句,所以填写的是该 sql 映射的 id
- column 属性:用于指定 select 属性的 sql 语句的参数来源
- 方法一
- 一对一
-
Mybatis 延迟加载策略
-
就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载
-
association and collection具备延迟加载的功能
我们需要在 Mybatis 的配置文件 SqlMapConfig.xml 文件中添加延迟加载的配置。 <!-- 开启延迟加载的支持 --> <settings> <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> </settings>
-
-
mybatis缓存:缓存策略减少数据库查询次数,从而提高性能
-
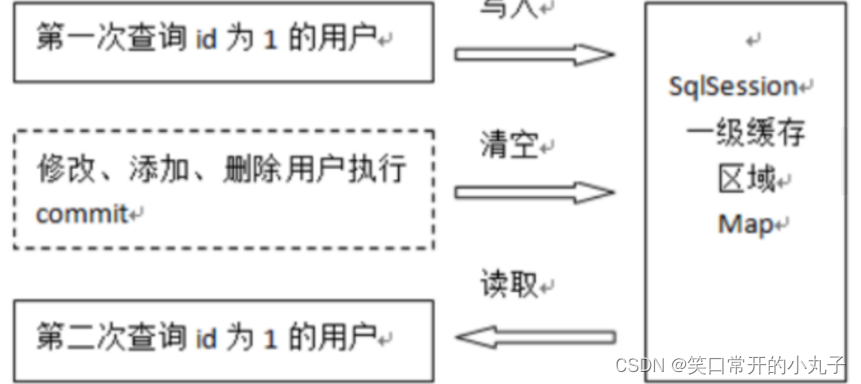
一级缓存:SqlSession缓存,只要SqlSession没有close 或者flush 就一直存在
- 一级缓存在dao.xml中的配置信息

-
具体测试的结果:两次查询出来的结果对象相等则代表使用了缓存策略
-
缓存清空:sqlsession.clearCache,清空缓存后两次结果对象不相等
<!-- 根据id查询用户 --><!--开启一级缓存--> <select id="findById" parameterType="INT" resultType="user" useCache="true"> select * from user where id = #{uid} </select>@Test public void testFirstCache(){ User user1 = userDao.findById(41); System.out.println("第一次查询用户"+ user1); User user2 = userDao.findById(41); System.out.println("第二次查询用户"+user2); System.out.println("两次查询结果对比,如果为true则代表没有创建新的对象使用缓存数据"); System.out.println(user1 == user2); }
-
二级缓存:二级缓存是 mapper 映射级别的缓存,多个 SqlSession 去操作同一个 Mapper 映射的 sql 语句,多个SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。
-
开启二级缓存
<settings> <!-- 开启二级缓存的支持 --> <setting name="cacheEnabled" value="true"/> </settings> 因为 cacheEnabled 的取值默认就为 true,所以这一步可以省略不配置。为 true 代表开启二级缓存;为 false 代表不开启二级缓存 -
配置相关的 Mapper 映射文件
<cache>标签表示当前这个 mapper 映射将使用二级缓存,区分的标准就看 mapper 的 namespace 值。 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.itheima.dao.IUserDao"> <!-- 开启二级缓存的支持 --> <cache></cache> </mapper <!-- 根据 id 查询 --> <select id="findById" resultType="user" parameterType="int" useCache="true"> select * from user where id = #{uid} </select> 将 UserDao.xml 映射文件中的<select>标签中设置 useCache=”true”代表当前这个 statement 要使用 二级缓存,如果不使用二级缓存可以设置为 false。 注意:针对每次查询都需要最新的数据 sql,要设置成 useCache=false,禁用二级缓存 -
关闭一级缓存并不会影响二级缓存的使用
-
使用二级缓存时,必须实现java.io.Serializable接口,使用序列化方法保存对象
-
-
-
Mybatis 注解开发
-
mybatis 的常用注解说明
@Insert:实现新增 @Update:实现更新 @Delete:实现删除 @Select:实现查询 @Result:实现结果集封装 @Results:可以与@Result 一起使用,封装多个结果集 @ResultMap:实现引用@Results 定义的封装 @One:实现一对一结果集封装 @Many:实现一对多结果集封装 @SelectProvider: 实现动态 SQL 映射 @CacheNamespace:实现注解二级缓存的使用 -
使用注解实现复杂关系映射开发
-
-