OpenCV快速入门:移动物体检测和目标跟踪
文章目录
- 前言
- 一、移动物体检测和目标跟踪简介
- 1.1 移动物体检测的基本概念
- 1.2 移动物体检测算法的类型
- 1.3 目标跟踪的基本概念
- 1.4 目标跟踪算法的类型
- 二、差值法检测移动物体
- 2.1 差值法原理
- 2.2 差值法公式
- 2.3 代码实现
- 2.3.1 视频或摄像头检测移动物体
- 2.3.2 随机动画生成的移动物体检测
- 三、基于模板的跟踪
- 3.1 模板跟踪原理
- 3.2 模板跟踪公式
- 3.3 代码实现
- 3.3.1 视频或摄像头中的目标跟踪
- 3.3.2 随机动画中的目标跟踪
- 四、基于特征的跟踪
- 4.1 特征跟踪原理
- 4.2 特征跟踪公式
- 4.3 代码实现
- 4.3.1 视频或摄像头中的目标跟踪
- 4.3.2 随机动画中的目标跟踪
- 五、基于密度的跟踪
- 5.1 均值迁移法目标跟踪
- 5.1.1 均值迁移法原理
- 5.1.2 均值迁移法公式
- 5.1.3 代码实现
- 5.2 光流法目标跟踪
- 5.2.1 光流法原理
- 5.2.2 光流法公式
- 5.2.3 代码实现
- 六、基于模型的跟踪
- 6.1 模型跟踪原理
- 6.2 模型跟踪公式
- 6.3 代码实现
- 6.4 跟踪定位不准确的原因
- 七、基于学习的跟踪
- 7.1 学习跟踪原理
- 7.2 KCF跟踪器
- 7.2.1 KCF跟踪器原理和公式
- 7.2.2 代码实现
- 总结
前言
在当今的数字化世界中,计算机视觉技术正在迅速发展并被广泛应用于各种场合。特别是在移动物体检测和目标跟踪领域,这项技术不仅对于安全监控系统至关重要,也在自动驾驶、交互式媒体、机器人技术等多个领域发挥着重要作用。
本文将介绍使用OpenCV进行移动物体检测和目标跟踪的基础知识,包括各种算法的原理、公式和实际代码实现。我们将从移动物体检测的基本概念开始,深入探讨不同类型的目标跟踪方法,如基于模板、特征、密度、模型和学习的跟踪技术。通过这篇文章,我们不仅可以了解到这些技术的理论基础,还能通过提供的代码示例学习如何在实际项目中应用这些技术。

一、移动物体检测和目标跟踪简介
1.1 移动物体检测的基本概念
移动物体检测是指在视频序列中识别和定位动态变化的物体。这个过程通常包括以下几个步骤:
背景建模:识别视频中的静态背景。这是通过分析一系列帧来完成的,旨在找出哪些部分是静态的。
前景检测:算法将识别与背景模型不匹配的部分,这些通常是移动的物体。
数据处理:通过滤波和阈值处理去除噪声,从而准确地提取出移动物体的信息。
1.2 移动物体检测算法的类型
基于背景减除的方法:这是最直观的方法,通过从当前帧中减去背景帧来检测移动物体。这要求背景是静态的或者有一个很好的背景更新机制。
光流法:光流是指图像序列中物体表面的运动模式。通过分析这些模式变化,可以推断出物体的运动。
基于帧差分的方法:这种方法通过比较连续帧之间的差异来检测移动。它对快速移动的物体特别有效,但可能无法检测到缓慢移动的物体。
基于机器学习的方法:这些方法使用训练数据来识别移动物体。例如,使用深度学习算法训练的模型可以在复杂的环境中有效地检测和分类物体。
目标跟踪的主要任务是在连续的视频帧中识别和追踪特定目标。这项技术广泛应用于安防监控、人机交互、自动驾驶等领域。在这一部分,我们将探索目标跟踪的基本概念和不同类型的跟踪算法。
1.3 目标跟踪的基本概念
目标跟踪过程通常包括两个主要步骤:目标检测和目标定位。首先,在视频的第一帧或初始几帧中识别出感兴趣的目标,这一步骤称为目标检测。接下来,系统需要在后续的视频帧中定位这个目标,即使它移动或发生形态上的变化,这一步骤称为目标定位。
在目标跟踪过程中,算法需要处理各种挑战,比如目标的快速移动、遮挡、光照变化、尺度变化等。有效的目标跟踪算法能够在这些挑战下依然稳定地跟踪目标。
1.4 目标跟踪算法的类型
-
基于模板的跟踪:这类算法使用目标的初始外观作为模板,并在后续帧中搜索最匹配的区域。这种方法简单直观,但在目标外观发生显著变化时效果不佳。
-
基于特征的跟踪:此方法依赖于检测和跟踪目标的关键特征(如边缘、角点等)。基于特征的跟踪可以处理一定的外观变化,但对于复杂场景中的遮挡和光照变化敏感。
-
基于密度的跟踪:这种方法通过估计像素级别的运动(如光流法)来跟踪目标。它对快速运动和局部遮挡有很好的适应性,但计算成本较高。
-
基于模型的跟踪:这类算法构建一个目标的三维模型,并在每一帧中尝试匹配该模型。它在处理复杂形状和运动时非常有效,但需要较高的计算资源和精确的初始模型。
-
基于学习的跟踪:近年来,随着机器学习尤其是深度学习的发展,基于学习的跟踪方法取得了显著进展。这类算法通过训练神经网络来自动学习如何有效地跟踪目标,能够处理各种复杂场景和挑战。
每种算法都有其优点和局限性,而在实际应用中,选择哪种跟踪算法通常取决于具体任务的需求和可用的计算资源。通过OpenCV,我们可以实现这些不同类型的跟踪算法,并将它们应用于实际的目标跟踪任务中。
二、差值法检测移动物体
差值法是一种简单而有效的移动物体检测技术,适用于监控和实时跟踪系统。其核心思想是通过比较连续视频帧之间的差异来识别移动物体。
2.1 差值法原理
差值法的基本原理是比较连续两帧或多帧图像间的像素差异。对于静态背景,相邻帧间的差异较小,而对于移动物体,由于其位置的变化,相邻帧间的像素值会有较大差异。
2.2 差值法公式
设 I ( x , y , t ) I(x, y, t) I(x,y,t)为在时间 t t t时刻,图像在位置 ( x , y ) (x, y) (x,y)的像素值。差值法通过计算相邻两帧图像的差异来检测移动物体:
D ( x , y , t ) = ∣ I ( x , y , t ) − I ( x , y , t − 1 ) ∣ D(x, y, t) = |I(x, y, t) - I(x, y, t-1)| D(x,y,t)=∣I(x,y,t)−I(x,y,t−1)∣
其中, D ( x , y , t ) D(x, y, t) D(x,y,t)表示时刻 t t t与时刻 t − 1 t-1 t−1之间在位置 ( x , y ) (x, y) (x,y)的像素差异。
2.3 代码实现
2.3.1 视频或摄像头检测移动物体
下面是实现差值法的一个简单示例:
import cv2
# # 初始化摄像头
# cap = cv2.VideoCapture(0)
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# 读取第一帧
ret, frame1 = cap.read()
gray1 = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
# 定义矩形结构元素
rectangle_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
while True:
# 读取下一帧
ret, frame2 = cap.read()
if not ret:
break # 如果视频结束,跳出循环
gray2 = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
# 计算两帧的差异
diff = cv2.absdiff(gray1, gray2)
# 二值化以突出差异
_, thresh = cv2.threshold(diff, 30, 255, cv2.THRESH_BINARY)
thresh = cv2.dilate(thresh, rectangle_kernel, iterations=2) # 膨胀操作,使轮廓更清晰
# 找出轮廓
_, contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 识别面积最大的轮廓
if contours:
largest_contour = max(contours, key=cv2.contourArea)
x, y, w, h = cv2.boundingRect(largest_contour)
cv2.rectangle(frame2, (x, y), (x + w, y + h), (0, 255, 0), 2) # 用绿色矩形框出
# 显示结果
thresh_img = cv2.merge([thresh, thresh, thresh])
cv2.imshow('Difference', cv2.hconcat([frame2, thresh_img]))
# 准备下一次迭代
gray1 = gray2
# 按'q'退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
这段代码首先初始化摄像头,然后循环读取每一帧图像。通过计算连续两帧的灰度图像差异,并通过阈值处理来突出这些差异,从而检测出移动物体。
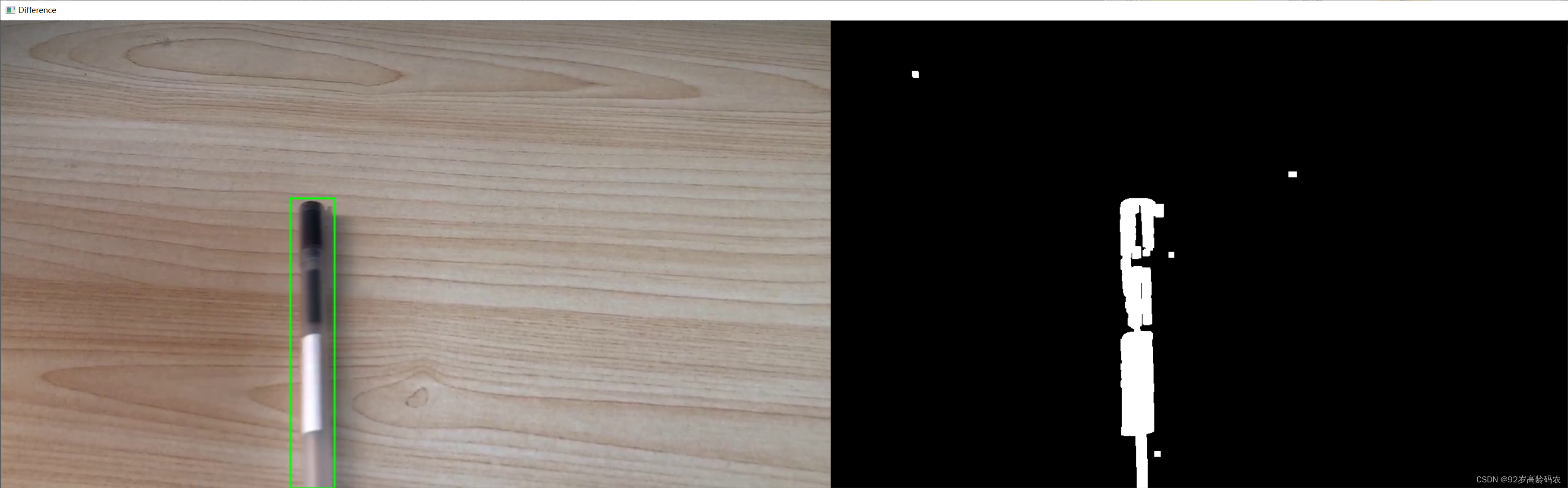
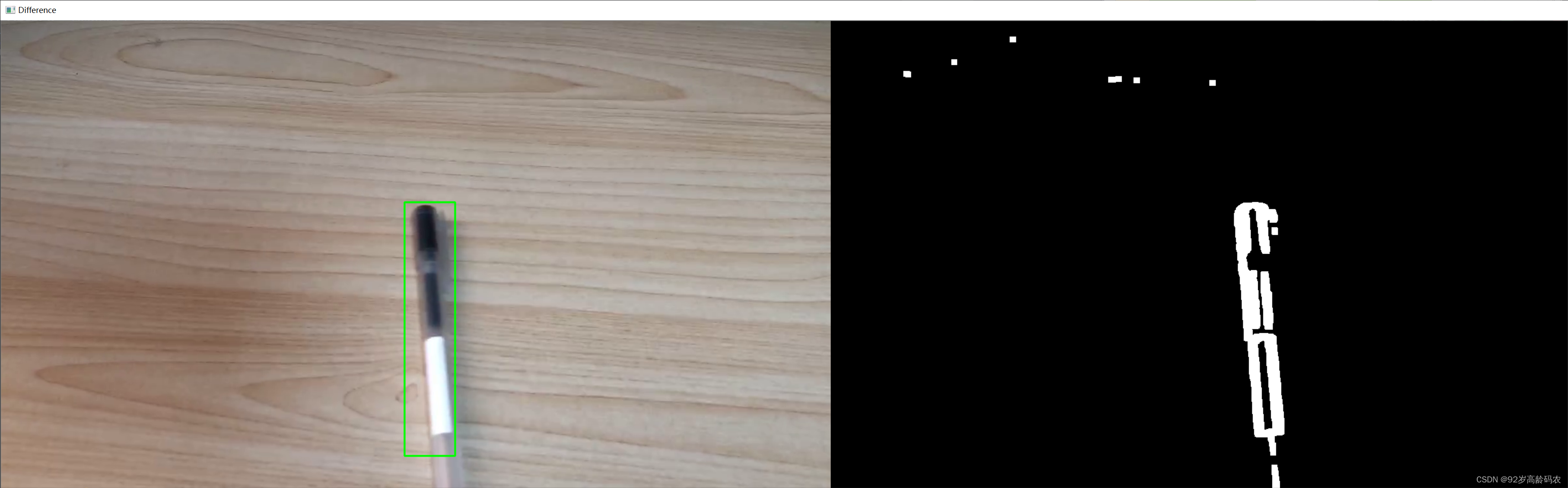
2.3.2 随机动画生成的移动物体检测
动画生成代码Animation.py
import cv2
import numpy as np
import random
class Animation:
def __init__(self, width=800, height=800, num_shapes=10):
self.width, self.height = width, height
self.canvas = np.zeros((height, width, 3), dtype=np.uint8)
self.shapes = [self.Shape(width, height) for _ in range(num_shapes)]
self.running = False
class Shape:
def __init__(self, width, height):
self.type = random.choice(["rectangle", "circle", "ellipse"])
self.color = tuple(np.random.randint(0, 255, (3,)).tolist())
self.center = np.random.randint(0, min(width, height), (2,))
self.size = np.random.randint(10, 50)
self.velocity = np.random.randint(-5, 5, (2,))
self.width = width
self.height = height
def move(self):
self.center += self.velocity
for i in range(2):
if self.center[i] < 0 or self.center[i] > (self.width if i == 0 else self.height):
self.velocity[i] *= -1
self.center[i] += self.velocity[i]
def draw(self, canvas):
if self.type == "rectangle":
top_left = (self.center - self.size).astype(int)
bottom_right = (self.center + self.size).astype(int)
cv2.rectangle(canvas, tuple(top_left), tuple(bottom_right), self.color, -1)
elif self.type == "circle":
cv2.circle(canvas, tuple(self.center), self.size, self.color, -1)
else: # ellipse
axes = (self.size, self.size // 2)
cv2.ellipse(canvas, tuple(self.center), axes, 0, 0, 360, self.color, -1)
def start(self):
self.running = True
while self.running:
self.canvas[:] = 0
for shape in self.shapes:
shape.move()
shape.draw(self.canvas)
cv2.imshow("Animation", self.canvas)
if cv2.waitKey(1) & 0xFF == ord('q'):
self.stop()
def stop(self):
self.running = False
cv2.destroyAllWindows()
def get_frame(self):
self.canvas[:] = 0
for shape in self.shapes:
shape.move()
shape.draw(self.canvas)
return self.canvas.copy()
# 使用方法:
# animation = Animation()
# animation.start() # 开始动画
# animation.get_frame() # 获取一帧画面
移动物体检测代码
import cv2
import Animation
animation = Animation.Animation(500, 400, 10)
frame1 = animation.get_frame()
gray1 = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)
# 定义矩形结构元素
rectangle_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
while True:
# 读取下一帧
frame2 = animation.get_frame()
gray2 = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)
# 计算两帧的差异
diff = cv2.absdiff(gray1, gray2)
# 二值化以突出差异
_, thresh = cv2.threshold(diff, 30, 255, cv2.THRESH_BINARY)
# 闭运算操作
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, rectangle_kernel,iterations=2)
# 找出轮廓
_, contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 识别面积最大的轮廓
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(frame2, (x, y), (x + w, y + h), (0, 255, 0), 2) # 用绿色矩形框出
# 显示结果
thresh_img = cv2.merge([thresh, thresh, thresh])
cv2.imshow('Difference', cv2.hconcat([frame2, thresh_img]))
# 准备下一次迭代
gray1 = gray2
# 按'q'退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
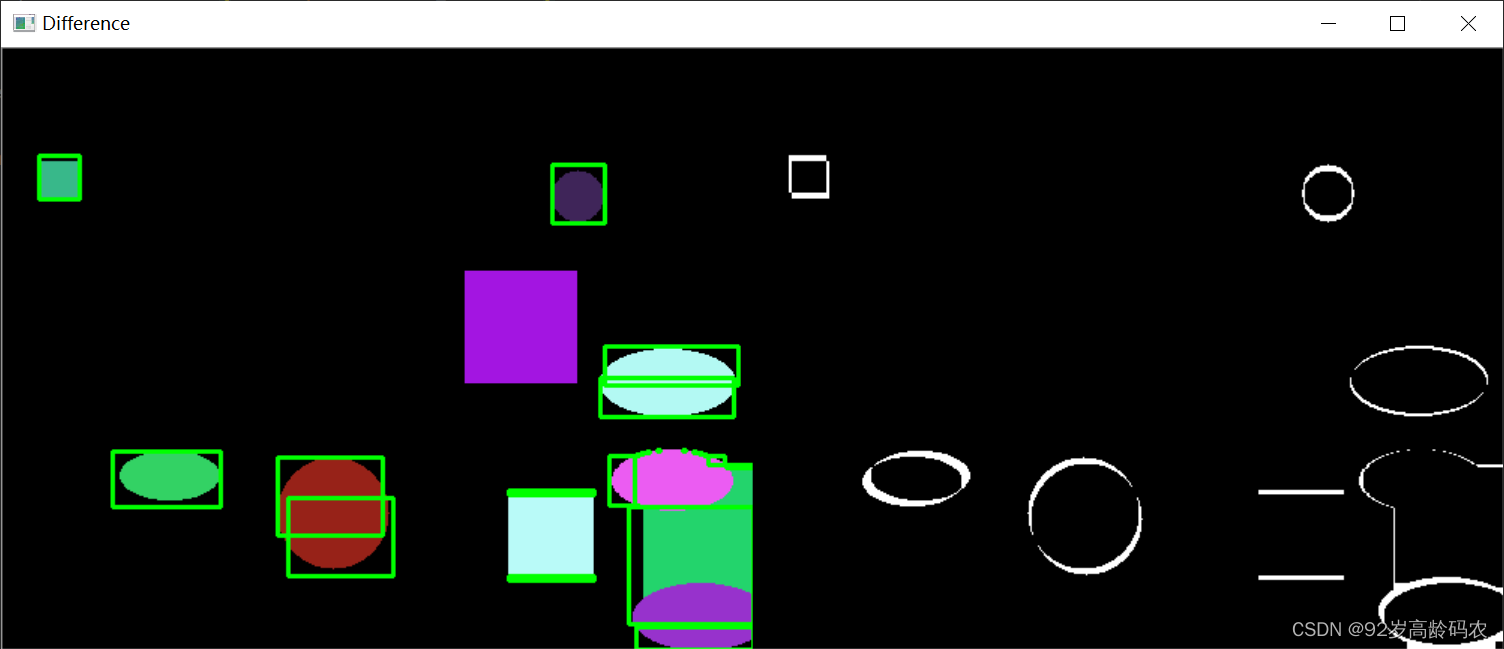
三、基于模板的跟踪
基于模板的跟踪是一种简单而直观的目标跟踪方法。在这种方法中,我们使用目标的初始外观作为一个模板,然后在视频的后续帧中搜索与该模板最匹配的区域。这种方法的关键在于如何定义和使用模板,以及如何在新帧中搜索该模板。
3.1 模板跟踪原理
基于模板的跟踪通常涉及以下步骤:
- 模板选择:在视频的第一帧或某一特定帧中选择一个区域作为跟踪的目标模板。
- 相似度度量:定义一个度量来计算模板与新帧中候选区域之间的相似度。常见的度量包括平方差、相关系数等。
- 搜索匹配:在后续帧中搜索与模板最相似的区域。这可以通过滑动窗口和相似度度量来实现。
3.2 模板跟踪公式
一个常见的相似度度量是归一化的交叉相关系数,其公式为:
R ( x , y ) = ∑ x ′ , y ′ [ T ( x ′ , y ′ ) ⋅ I ( x + x ′ , y + y ′ ) ] ∑ x ′ , y ′ [ T ( x ′ , y ′ ) 2 ] ⋅ ∑ x ′ , y ′ [ I ( x + x ′ , y + y ′ ) 2 ] R(x, y) = \frac{\sum_{x', y'}[T(x', y') \cdot I(x + x', y + y')]}{\sqrt{\sum_{x', y'}[T(x', y')^2] \cdot \sum_{x', y'}[I(x + x', y + y')^2]}} R(x,y)=∑x′,y′[T(x′,y′)2]⋅∑x′,y′[I(x+x′,y+y′)2]∑x′,y′[T(x′,y′)⋅I(x+x′,y+y′)]
其中, R ( x , y ) R(x, y) R(x,y)是在位置 (x, y) 的相关系数, T T T是模板图像,而 I I I是当前帧中的搜索区域。
3.3 代码实现
3.3.1 视频或摄像头中的目标跟踪
import cv2
# # 初始化摄像头
# cap = cv2.VideoCapture(0)
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# 读取第一帧并选择模板
ret, frame = cap.read()
template = cv2.selectROI("Select Template", frame, fromCenter=False)
template_img = frame[int(template[1]):int(template[1] + template[3]), int(template[0]):int(template[0] + template[2])]
h, w = template_img.shape[:2]
# 开始跟踪
while True:
_, frame = cap.read()
if not ret:
break
# 匹配模板
res = cv2.matchTemplate(frame, template_img, cv2.TM_CCOEFF_NORMED)
_, _, _, max_loc = cv2.minMaxLoc(res)
# 绘制跟踪结果
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(frame, top_left, bottom_right, (0, 255, 0), 2)
cv2.imshow("Tracking", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
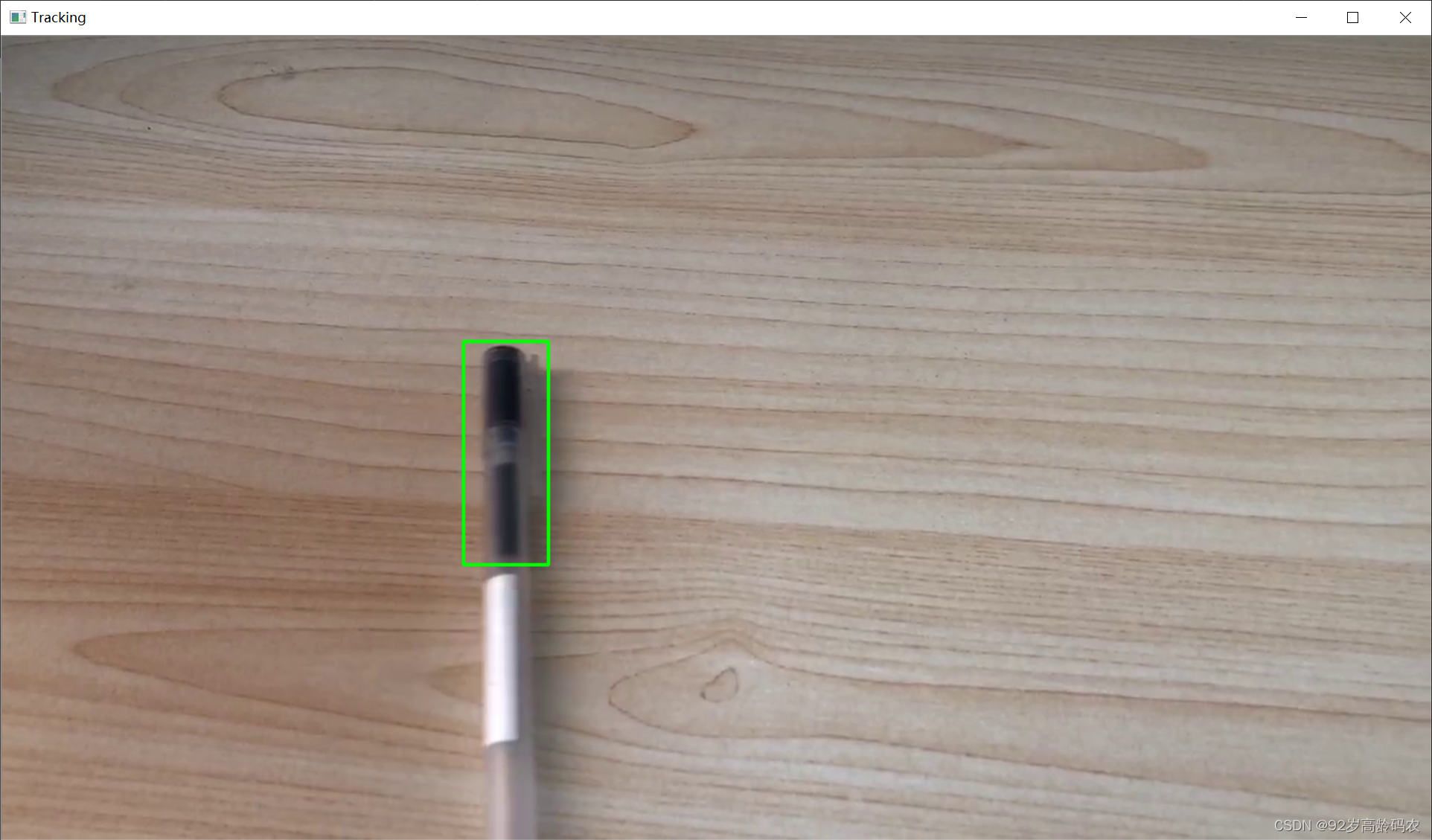
在这个示例中,我们首先从视频的第一帧中选择一个模板区域。然后,使用 cv2.matchTemplate 函数在每一帧中查找与该模板最匹配的区域。这种方法在目标外观发生显著变化时可能效果不佳,但在目标外观保持相对稳定的情况下可以有效工作。
在实际任务中,存在丢失或者错误定位等问题。
正确定位:

错误定位:

3.3.2 随机动画中的目标跟踪
import cv2
import Animation
animation = Animation.Animation(500, 400, 10)
frame = animation.get_frame()
template = cv2.selectROI("Select Template", frame, fromCenter=False)
template_img = frame[int(template[1]):int(template[1] + template[3]), int(template[0]):int(template[0] + template[2])]
h, w = template_img.shape[:2]
# 开始跟踪
while True:
frame = animation.get_frame()
# 匹配模板
res = cv2.matchTemplate(frame, template_img, cv2.TM_CCOEFF_NORMED)
_, _, _, max_loc = cv2.minMaxLoc(res)
# 绘制跟踪结果
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(frame, top_left, bottom_right, (0, 255, 0), 2)
cv2.imshow("Tracking", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
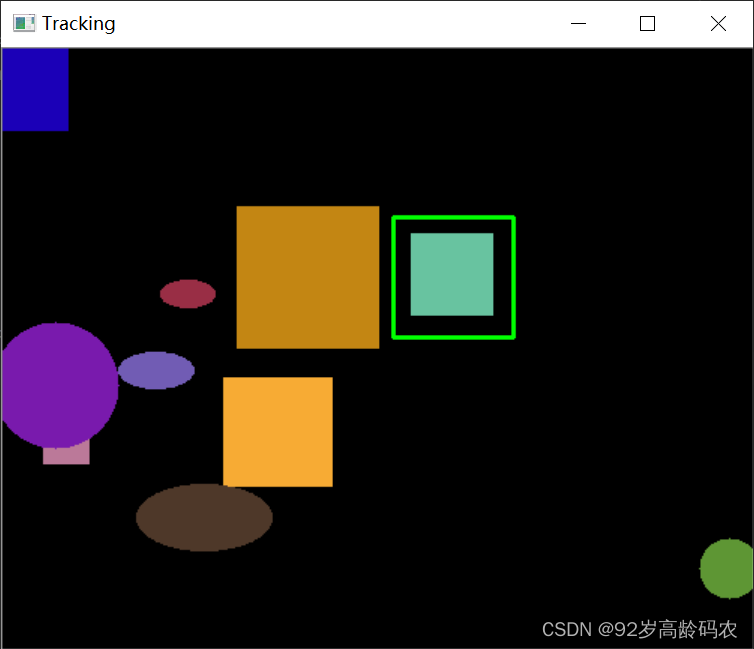
四、基于特征的跟踪
在计算机视觉中,基于特征的跟踪侧重于识别和跟踪视频序列中物体的关键特征点。
4.1 特征跟踪原理
基于特征的跟踪通常包括两个主要步骤:特征点检测和特征点匹配。
-
特征点检测:首先,算法在第一帧中识别出关键的特征点。这些点是图像中独特的区域,例如角点、边缘等。
-
特征点匹配:随后,在后续帧中追踪这些特征点。这是通过比较相邻帧中特征点的外观和位置来完成的。
4.2 特征跟踪公式
一个常用的特征点检测算法是Shi-Tomasi角点检测器,其计算公式如下:
R = m i n ( λ 1 , λ 2 ) R = min(\lambda_1, \lambda_2) R=min(λ1,λ2)
其中, λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 是图像某点邻域内梯度的协方差矩阵的特征值。较大的 R R R 值意味着该点是一个强角点。
4.3 代码实现
4.3.1 视频或摄像头中的目标跟踪
以下是基于特征的跟踪的示例代码:
import numpy as np
import cv2
# # 初始化摄像头
# cap = cv2.VideoCapture(0)
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# Shi-Tomasi角点检测参数
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7)
# 光流法参数
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 随机颜色
color = np.random.randint(0, 255, (100, 3))
# 读取第一帧
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建一个掩模用于绘制轨迹
mask = np.zeros_like(old_frame)
while True:
ret, frame = cap.read()
if not ret:
break
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流以获取新的特征点位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 如果p1为None,重新检测特征点
if p1 is None:
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
continue
# 选取好的特征点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv2.circle(frame, (a, b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow('Frame', img)
# 更新上一帧的图像和特征点位置
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源和关闭窗口
cv2.destroyAllWindows()

4.3.2 随机动画中的目标跟踪
import numpy as np
import cv2
import Animation
animation = Animation.Animation(500, 400, 2)
# Shi-Tomasi角点检测参数
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7)
# 光流法参数
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 随机颜色
color = np.random.randint(0, 255, (100, 3))
# 读取第一帧
old_frame = animation.get_frame()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建一个掩模用于绘制轨迹
mask = np.zeros_like(old_frame)
while True:
frame = animation.get_frame()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流以获取新的特征点位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 如果p1为None,重新检测特征点
if p1 is None:
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
continue
# 选取好的特征点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv2.circle(frame, (a, b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow('Frame', img)
# 更新上一帧的图像和特征点位置
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源和关闭窗口
cv2.destroyAllWindows()
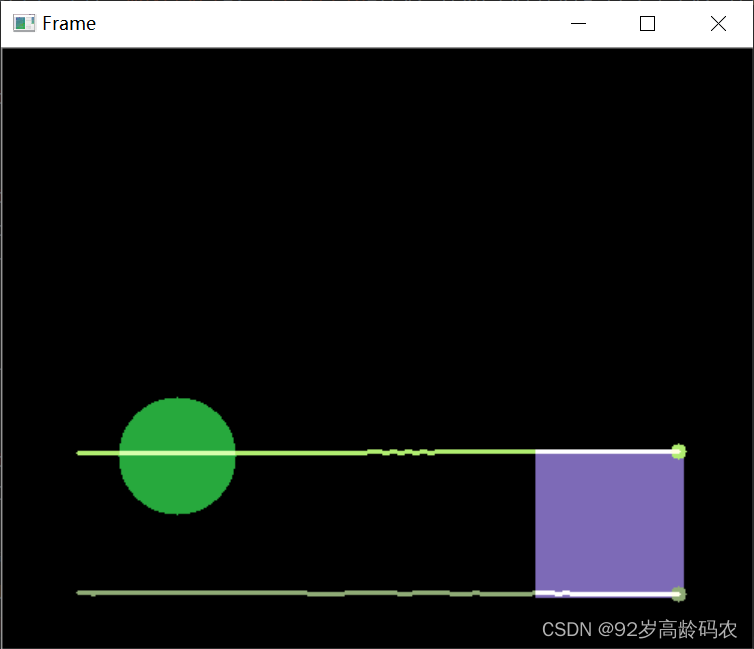
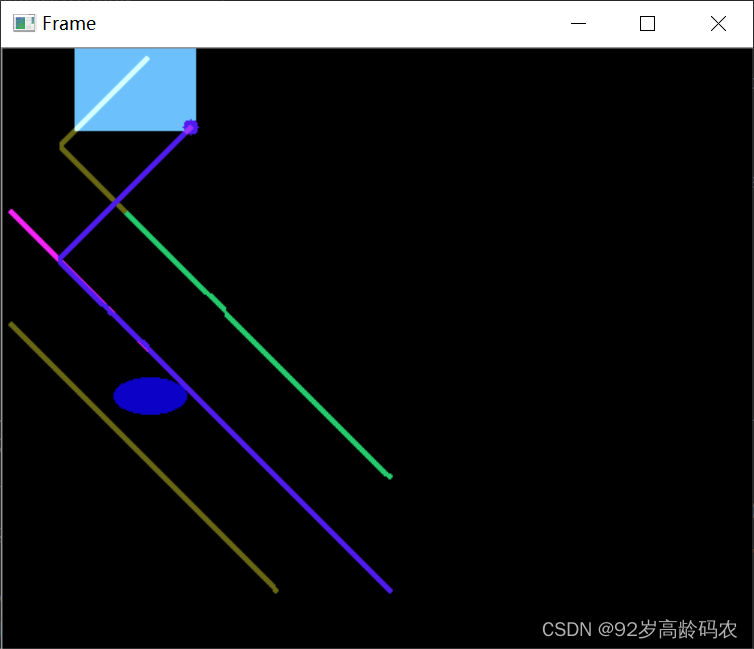
五、基于密度的跟踪
5.1 均值迁移法目标跟踪
5.1.1 均值迁移法原理
均值迁移法(Mean Shift)的基本思想是利用样本点的密度分布来进行聚类。算法过程中,每个样本点向其邻域内的密度中心移动,这个过程不断迭代,直到达到局部密度最大的点。这样,具有相似特征的样本点会逐渐聚集在一起形成簇。均值迁移算法的关键在于如何确定每个点的邻域及其密度中心。
5.1.2 均值迁移法公式
均值迁移法的核心公式涉及到对每个点的邻域内样本点的均值进行计算,以此作为迁移的方向。具体公式为:
设 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn 为样本点,对于每一个样本点 x i x_i xi,均值迁移算法通过以下步骤更新其位置:
-
选择窗口大小:首先选择一个“窗口”或“核”(通常是高斯核或者均匀核)和相应的带宽(bandwidth)参数 h h h。
-
计算窗口内的均值:对于每个数据点 x i x_i xi,计算在其周围带宽 h h h 内的所有样本点的均值。这个均值是通过权重来计算的,权重通常由核函数确定。均值计算公式为:
m ( x i ) = ∑ x j ∈ N ( x i ) K ( x i − x j ) x j ∑ x j ∈ N ( x i ) K ( x i − x j ) m(x_i) = \frac{\sum_{x_j \in N(x_i)} K(x_i - x_j) x_j}{\sum_{x_j \in N(x_i)} K(x_i - x_j)} m(xi)=∑xj∈N(xi)K(xi−xj)∑xj∈N(xi)K(xi−xj)xj
其中, N ( x i ) N(x_i) N(xi) 表示 x i x_i xi 周围的邻域, K K K 是核函数。 -
更新数据点位置:将每个数据点 x i x_i xi 移动到计算出的均值 m ( x i ) m(x_i) m(xi) 位置。
-
迭代:重复步骤2和3,直到所有点的移动距离小于某个阈值或达到预设的迭代次数。
均值迁移算法的关键在于核函数的选择和带宽参数 h h h 的设置。核函数的选择决定了样本点的权重分布,而带宽 h h h 决定了局部邻域的大小。通过这种方式,均值迁移能够找到数据的密度峰值,从而实现数据的聚类。
5.1.3 代码实现
以下是实现均值迁移目标跟踪的示例:
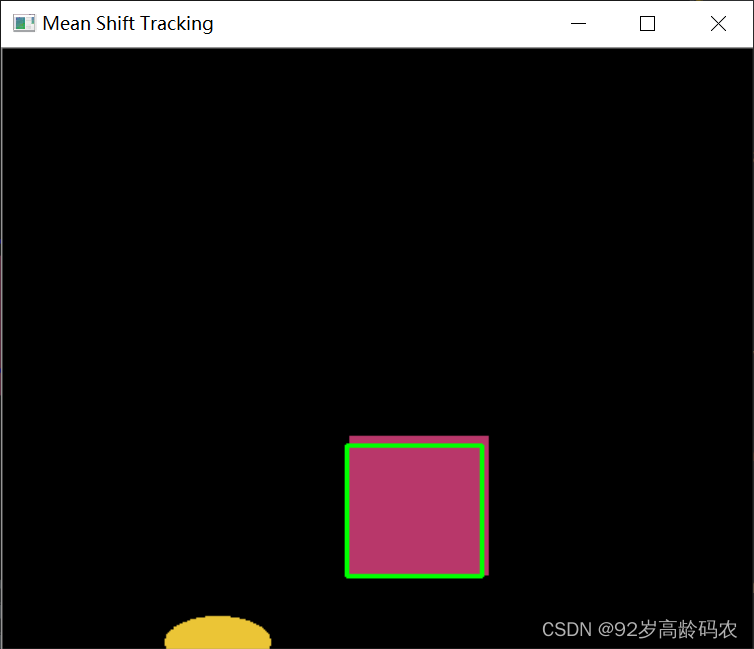
视频或摄像头中的目标跟踪:
import numpy as np
import cv2
# # 初始化摄像头
# cap = cv2.VideoCapture(0)
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# 读取第一帧并选择跟踪目标
ret, frame = cap.read()
roi = cv2.selectROI(frame, False)
x, y, w, h = roi
track_window = (x, y, w, h)
# ROI的直方图
roi_img = frame[y:y+h, x:x+w]
hsv_roi = cv2.cvtColor(roi_img, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0,180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# 均值迁移参数
term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
while True:
ret, frame = cap.read()
if not ret:
break
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
# 应用均值迁移来获取新窗口位置
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# 绘制窗口
x, y, w, h = track_window
final_img = cv2.rectangle(frame, (x, y), (x+w, y+h), 255, 2)
cv2.imshow('Mean Shift Tracking', final_img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
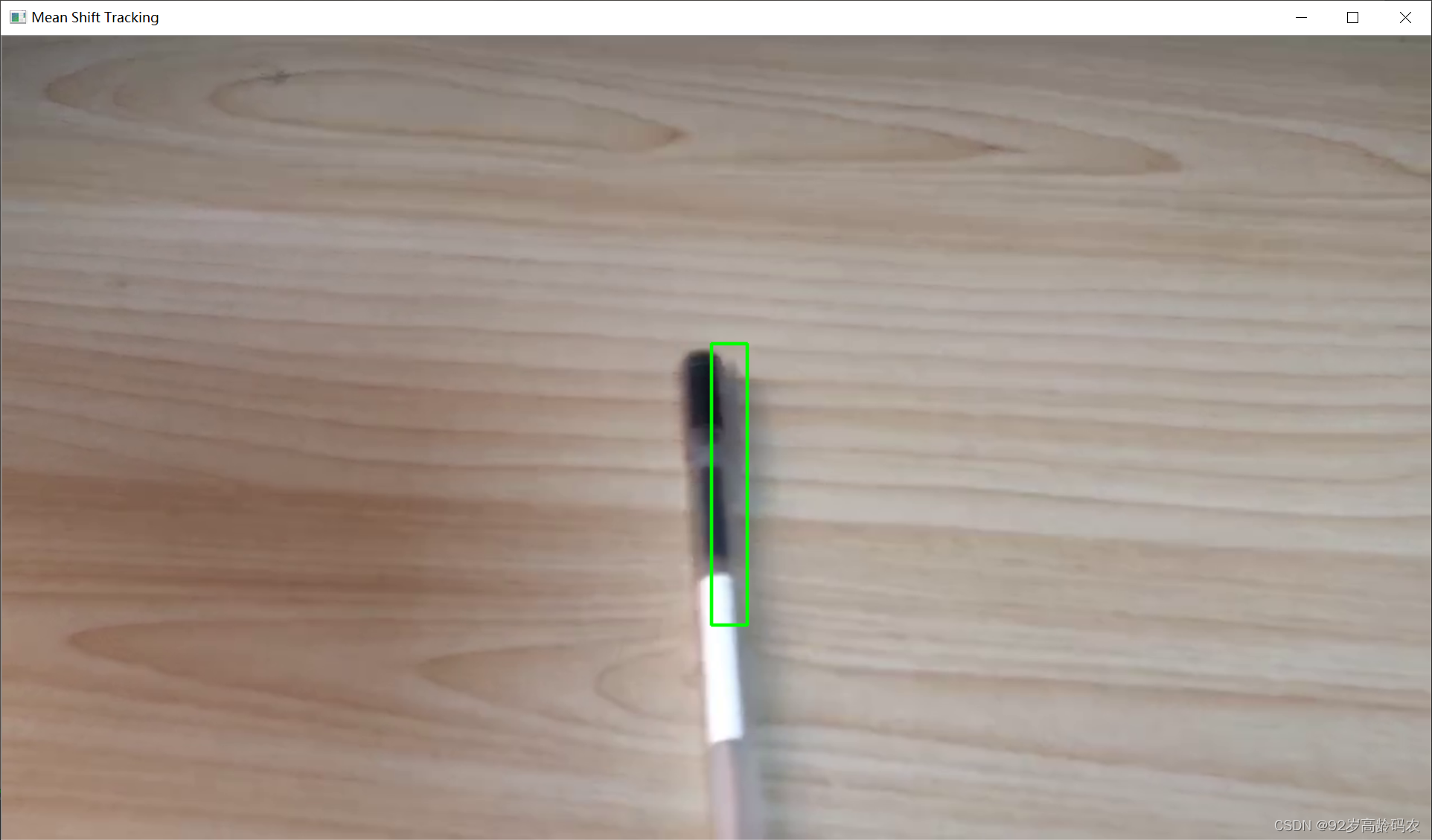
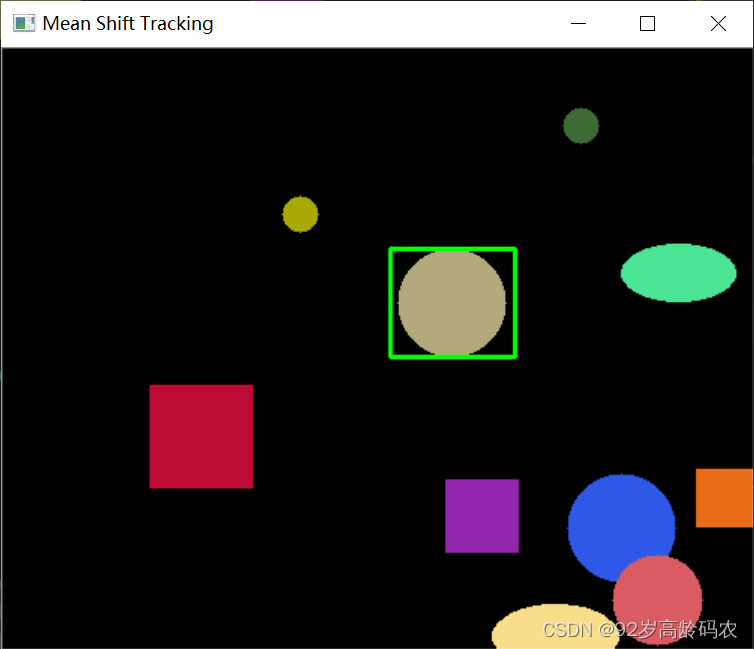
随机动画中的目标跟踪:
import numpy as np
import cv2
import Animation
animation = Animation.Animation(500, 400, 2)
# 读取第一帧并选择跟踪目标
frame = animation.get_frame()
roi = cv2.selectROI(frame, False)
x, y, w, h = roi
track_window = (x, y, w, h)
# ROI的直方图
roi_img = frame[y:y+h, x:x+w]
hsv_roi = cv2.cvtColor(roi_img, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0,180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# 均值迁移参数
term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
while True:
frame = animation.get_frame()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
# 应用均值迁移来获取新窗口位置
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# 绘制窗口
x, y, w, h = track_window
final_img = cv2.rectangle(frame, (x, y), (x+w, y+h), (0,255,0), 2)
cv2.imshow('Mean Shift Tracking', final_img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
5.2 光流法目标跟踪
光流法是一种在连续动态图像中分析和跟踪目标运动的技术。它广泛应用于计算机视觉和视频处理领域,尤其在目标跟踪方面。
5.2.1 光流法原理
光流法基于这样一个假设:随着时间的变化,一个物体在图像序列中的运动会导致图像亮度的变化。因此,通过分析这些亮度变化,可以推断物体在两个连续帧之间的运动。
光流本质上是图像中每个像素点的运动速度和方向的向量场。它不是实际物体的运动速度,而是物体运动在图像平面上的投影。通过分析这些向量,可以估计物体的运动轨迹、速度和方向。
5.2.2 光流法公式
光流法的核心公式基于亮度恒定假设,即一个点在连续两帧图像中的亮度保持不变。假设图像的亮度 I ( x , y , t ) I(x, y, t) I(x,y,t) 在位置 ( x , y ) (x, y) (x,y) 和时间 t t t 是已知的,则光流方程可以表示为:
∂ I ∂ x v x + ∂ I ∂ y v y + ∂ I ∂ t = 0 \frac{\partial I}{\partial x}v_x + \frac{\partial I}{\partial y}v_y + \frac{\partial I}{\partial t} = 0 ∂x∂Ivx+∂y∂Ivy+∂t∂I=0
其中, ∂ I ∂ x \frac{\partial I}{\partial x} ∂x∂I 和 ∂ I ∂ y \frac{\partial I}{\partial y} ∂y∂I 是图像在空间维度的亮度梯度, ∂ I ∂ t \frac{\partial I}{\partial t} ∂t∂I 是时间维度的亮度变化, v x v_x vx 和 v y v_y vy 分别是像素点在 x x x 和 y y y 方向的运动速度。
光流法的挑战在于,这个方程只有一个方程但有两个未知数( v x v_x vx 和 v y v_y vy),因此它是一个不适定问题。为了解决这个问题,通常需要引入额外的约束条件,如平滑性约束,或采用多种技术和算法来近似求解。
在实际应用中,光流法需要考虑到噪声、光照变化、遮挡等因素的影响,因此通常结合其他算法和技术来提高准确性和鲁棒性。光流法在目标跟踪、场景分析、3D结构重建等多个领域都有广泛的应用。
5.2.3 代码实现
这里的代码实现与3.3.1 视频或摄像头中的目标跟踪是相似的。
视频或摄像头中的目标跟踪:
import cv2
# # 初始化摄像头
# cap = cv2.VideoCapture(0)
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# Shi-Tomasi角点检测参数
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7)
# 读取第一帧
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 光流法参数
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 使用Shi-Tomasi方法检测角点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
while True:
ret, frame = cap.read()
if not ret:
break
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选取好的特征点
good_new = p1[st==1]
good_old = p0[st==1]
# 绘制特征点
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
frame = cv2.line(frame, (a, b), (c, d), (0, 255, 0), 2)
frame = cv2.circle(frame, (a, b), 5, (0, 255, 0), -1)
cv2.imshow('Optical Flow Tracking', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cap.release()
cv2.destroyAllWindows()

这里的代码实现与3.3.2 随机动画中的目标跟踪是相似的。
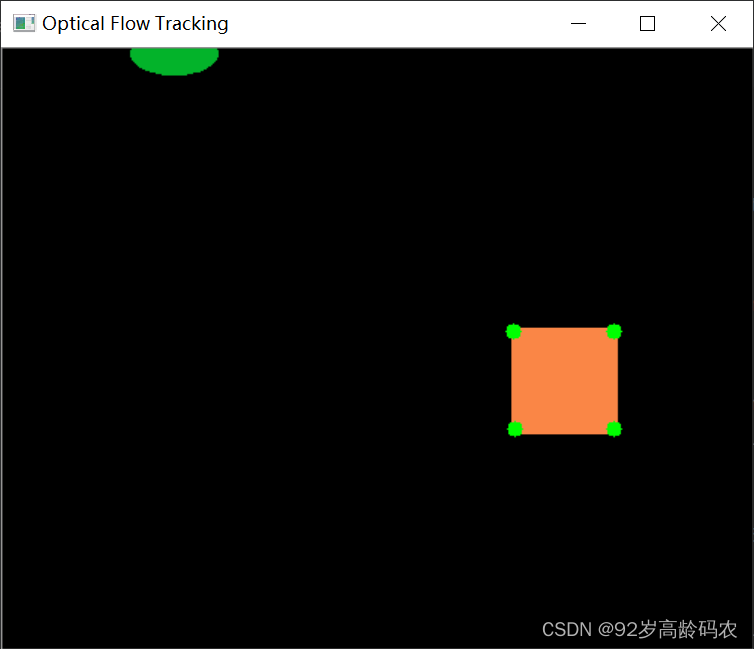
随机动画中的目标跟踪:
import cv2
import Animation
animation = Animation.Animation(500, 400, 2)
# Shi-Tomasi角点检测参数
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7)
# 读取第一帧
old_frame = animation.get_frame()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# 光流法参数
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 使用Shi-Tomasi方法检测角点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
while True:
frame = animation.get_frame()
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 如果p1为None,重新检测特征点
if p1 is None:
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
continue
# 选取好的特征点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制特征点
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
frame = cv2.line(frame, (a, b), (c, d), (0, 255, 0), 2)
frame = cv2.circle(frame, (a, b), 5, (0, 255, 0), -1)
cv2.imshow('Optical Flow Tracking', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cv2.destroyAllWindows()
六、基于模型的跟踪
6.1 模型跟踪原理
基于模型的跟踪是一种利用数学模型来表示并跟踪目标的方法。这种跟踪技术通常依赖于预先定义的目标模型,这些模型可以是几何形状、物体的三维模型、或者具有特定特征的模型。跟踪过程涉及不断地调整模型参数以确保模型与观测数据最佳匹配。
6.2 模型跟踪公式
在基于模型的跟踪中,模型跟踪的公式核心是优化问题,即寻找最佳的模型参数 θ \theta θ 以便模型预测与实际观测尽可能接近。通常这是通过最小化一个损失函数来实现的。损失函数衡量的是预测值和实际观测值之间的差异。
设 y \mathbf{y} y 是观测到的数据点(例如,图像中目标的位置), f ( θ ) f(\theta) f(θ) 是模型预测,其中 θ \theta θ 是模型的参数。目标函数 L ( θ ) L(\theta) L(θ)(通常称为损失函数)可以表示为:
L ( θ ) = ∑ i ( y i − f ( θ ) i ) 2 L(\theta) = \sum_{i}(y_i - f(\theta)_i)^2 L(θ)=i∑(yi−f(θ)i)2
这里, L ( θ ) L(\theta) L(θ) 是实际观测值 y i y_i yi 和模型预测 f ( θ ) i f(\theta)_i f(θ)i 之间差异的平方和。目标是找到参数 θ \theta θ,使得 L ( θ ) L(\theta) L(θ) 最小。
优化方法
-
梯度下降法:这是一种常用的优化技术,用于更新参数 θ \theta θ 以最小化损失函数。参数更新公式为:
θ : = θ − α ∇ θ L ( θ ) \theta := \theta - \alpha \nabla_\theta L(\theta) θ:=θ−α∇θL(θ)
其中, α \alpha α 是学习率, ∇ θ L ( θ ) \nabla_\theta L(\theta) ∇θL(θ) 是损失函数关于 θ \theta θ 的梯度。
-
迭代方法:在实际应用中,梯度下降法会迭代多次,每次迭代都会根据梯度的方向更新 θ \theta θ,直到找到损失函数的最小值或达到某个停止条件。
通过这种方式,基于模型的跟踪方法能够在每一帧中调整模型参数 θ \theta θ,以确保模型对目标的描述尽可能接近实际观测数据,实现对目标的有效跟踪。
6.3 代码实现
注:以下方法只适合简单图形
视频或摄像头中的目标跟踪:
import cv2
import numpy as np
# # 初始化摄像头
# cap = cv2.VideoCapture(0)
# 读取视频
cap = cv2.VideoCapture('video2.mp4')
# 读取第一帧并定义初始矩形位置
ret, frame = cap.read()
init_pos = cv2.selectROI("Frame", frame, False)
cv2.destroyWindow("Frame") # 关闭选择窗口
x, y, w, h = init_pos
track_window = (x, y, w, h)
# 设置ROI并计算直方图
roi = frame[y:y+h, x:x+w]
hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60., 32.)), np.array((180., 255., 255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# 设置跟踪模型
term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
while True:
ret, frame = cap.read()
if not ret:
break
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# 绘制跟踪结果
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
img2 = cv2.polylines(frame, [pts], True, 255, 2)
cv2.imshow('Tracking', img2)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
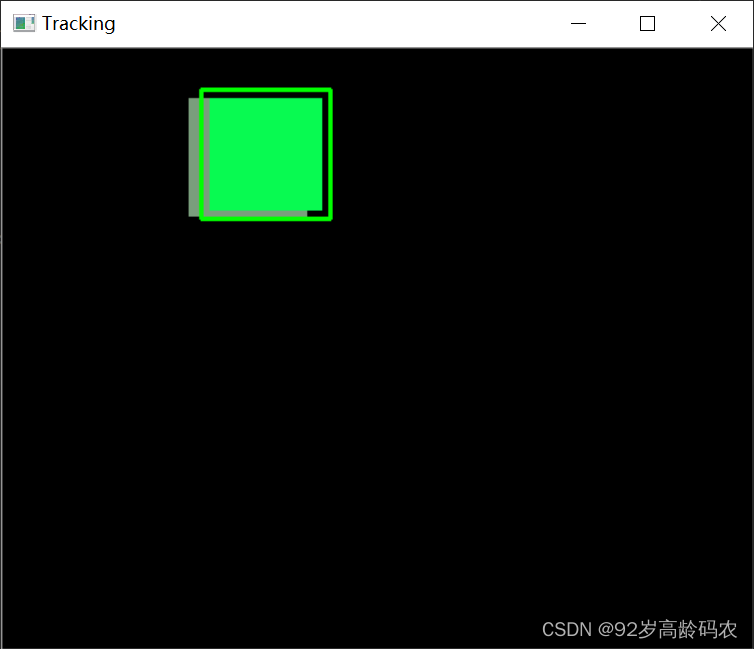
在这个例子中,我们使用CamShift算法进行基于模型的跟踪。CamShift是一种自适应的跟踪方法,可以处理目标大小的变化。跟踪开始时,用户需要选择一个ROI(感兴趣区域),之后算法会根据ROI中的颜色信息在后续帧中寻找最佳匹配。

随机动画中的目标跟踪:
import cv2
import numpy as np
import Animation
animation = Animation.Animation(500, 400, 2)
# 读取第一帧并定义初始矩形位置
frame = animation.get_frame()
init_pos = cv2.selectROI("Frame", frame, False)
cv2.destroyWindow("Frame") # 关闭选择窗口
x, y, w, h = init_pos
track_window = (x, y, w, h)
# 设置ROI并计算直方图
roi = frame[y:y + h, x:x + w]
hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60., 32.)), np.array((180., 255., 255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# 设置跟踪模型
term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
while True:
frame = animation.get_frame()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# 绘制跟踪结果
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
img2 = cv2.polylines(frame, [pts], True, (0, 255, 0), 2)
cv2.imshow('Tracking', img2)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cv2.destroyAllWindows()
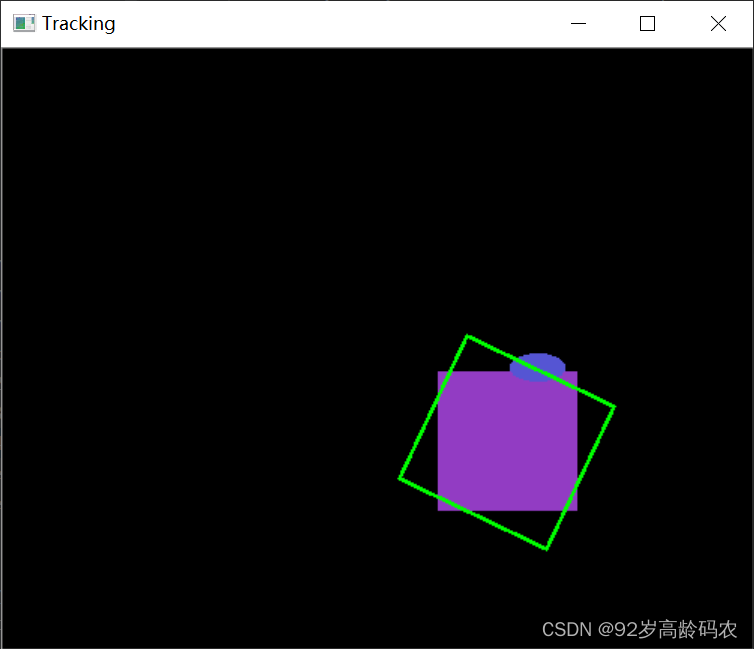
6.4 跟踪定位不准确的原因
初始ROI选择:使用
cv2.selectROI函数手动选择视频的第一帧中的一个区域。这个区域的颜色信息用于初始化跟踪。颜色直方图:代码中计算了选定ROI的HSV颜色空间的颜色直方图。这个直方图用于后续帧中相同或相似颜色分布的区域的搜索。
颜色分布依赖:CamShift算法追踪对象的能力强烈依赖于初始ROI的颜色分布。如果视频中的其他帧中没有类似的颜色分布,或者被追踪的目标颜色发生了显著变化,那么跟踪效果会大大降低。
跟踪窗口更新:每一帧中,CamShift算法都会更新跟踪窗口的位置,尝试匹配与初始直方图相似的区域。如果目标移动到了一个颜色分布与初始ROI不同的区域,跟踪可能会失败。
环境因素:光照变化、遮挡、相似颜色的背景等因素都可能影响跟踪的准确性。
七、基于学习的跟踪
7.1 学习跟踪原理
基于学习的跟踪方法涉及使用机器学习算法来训练模型,以便识别和跟踪视频中的目标。这些方法通常包括特征提取、模型训练和在线跟踪。
-
特征提取:从视频帧中提取有效的特征,这些特征能够代表目标的重要属性。
-
模型训练:使用提取的特征训练一个分类器或回归模型,以区分目标和背景。
-
在线跟踪:在视频流中应用训练好的模型,实时更新模型参数以适应目标的变化。
OpenCV 提供了一些内置的基于学习的跟踪器,如 KCF(Kernelized Correlation Filters)和 CSRT(Channel and Spatial Reliability Tracker)
7.2 KCF跟踪器
7.2.1 KCF跟踪器原理和公式
KCF跟踪器基于相关滤波器的概念,并通过使用循环矩阵和快速傅里叶变换(FFT)来高效地实现目标跟踪。
1. 循环矩阵与相关
KCF跟踪器的核心在于构建循环矩阵,这是通过将训练样本(即目标周围的图像块)转换为循环结构来实现的。这样的循环矩阵使得可以通过快速傅里叶变换(FFT)高效地计算样本之间的相关性,大幅提升了计算速度。
2. 目标函数
KCF跟踪器的目的是学习一个滤波器,它能够最大化新图像帧上的响应函数。响应函数定义如下:
f
(
w
)
=
∑
i
=
1
n
(
y
i
−
w
T
ϕ
(
x
i
)
)
2
+
λ
∥
w
∥
2
f(\mathbf{w}) = \sum_{i=1}^{n} \left( y_i - \mathbf{w}^T \phi(\mathbf{x}_i) \right)^2 + \lambda \|\mathbf{w}\|^2
f(w)=i=1∑n(yi−wTϕ(xi))2+λ∥w∥2
在这里,
w
\mathbf{w}
w表示滤波器的权重,
ϕ
(
x
i
)
\phi(\mathbf{x}_i)
ϕ(xi)是经过核函数映射的特征,
y
i
y_i
yi是目标的响应值,而
λ
\lambda
λ是一个正则化参数,用来防止过拟合。
3. 核相关
KCF利用核技巧将数据映射到更高维的特征空间,从而能够捕获更复杂的特征关系。核相关函数可以定义为:
K
(
x
,
z
)
=
ϕ
(
x
)
T
ϕ
(
z
)
K(\mathbf{x}, \mathbf{z}) = \phi(\mathbf{x})^T \phi(\mathbf{z})
K(x,z)=ϕ(x)Tϕ(z)
这里,
x
\mathbf{x}
x和
z
\mathbf{z}
z是特征向量,而
ϕ
\phi
ϕ是核函数映射。
4. 滤波器的训练
滤波器训练涉及求解上述目标函数的最优解。利用傅里叶变换和核技巧,这个过程可以被高效地完成。
5. 目标定位
在新的视频帧中,已学习的滤波器被用来计算相关响应,从而定位目标。目标位置通常对应于响应图中的最大值。
6. 更新机制
为了适应目标的外观变化,KCF跟踪器包含了一种机制,用于根据新的跟踪结果逐步更新滤波器。
KCF跟踪器因其在速度和性能之间的良好平衡而受到欢迎。通过运用FFT和核技巧,它能够在实时视频流中有效地跟踪目标,特别适用于需要快速跟踪处理的应用场景。
7.2.2 代码实现
视频或摄像头中的目标跟踪:
import cv2
# 创建KCF跟踪器的实例
tracker = cv2.TrackerKCF_create()
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# 读取视频的第一帧
ret, frame = cap.read()
# 选择要跟踪的目标
bbox = cv2.selectROI(frame, False)
# 初始化跟踪器
ok = tracker.init(frame, bbox)
while True:
# 读取新的帧
ret, frame = cap.read()
if not ret:
break
# 更新跟踪器
ok, bbox = tracker.update(frame)
# 绘制跟踪框
if ok:
(x, y, w, h) = [int(v) for v in bbox]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2, 1)
# 显示结果
cv2.imshow("Tracking", frame)
# 退出条件
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
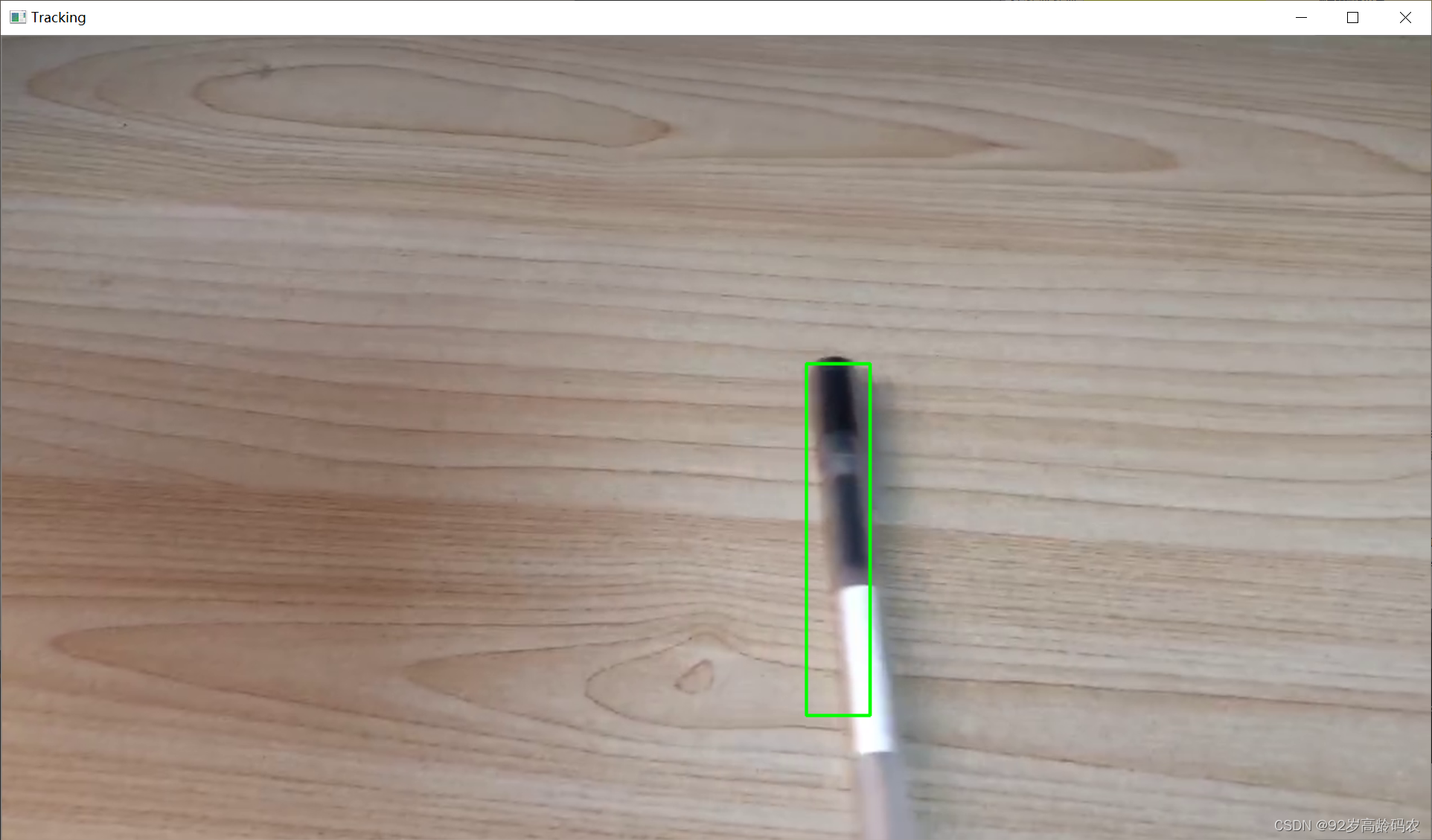
随机动画中的目标跟踪:
import cv2
import Animation
animation = Animation.Animation(500, 400, 10)
# 创建KCF跟踪器的实例
tracker = cv2.TrackerKCF_create()
# 读取视频的第一帧
frame = animation.get_frame()
# 选择要跟踪的目标
bbox = cv2.selectROI(frame, False)
# 初始化跟踪器
ok = tracker.init(frame, bbox)
while True:
# 读取新的帧
frame = animation.get_frame()
# 更新跟踪器
ok, bbox = tracker.update(frame)
# 绘制跟踪框
if ok:
(x, y, w, h) = [int(v) for v in bbox]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2, 1)
# 显示结果
cv2.imshow("Tracking", frame)
# 退出条件
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cv2.destroyAllWindows()
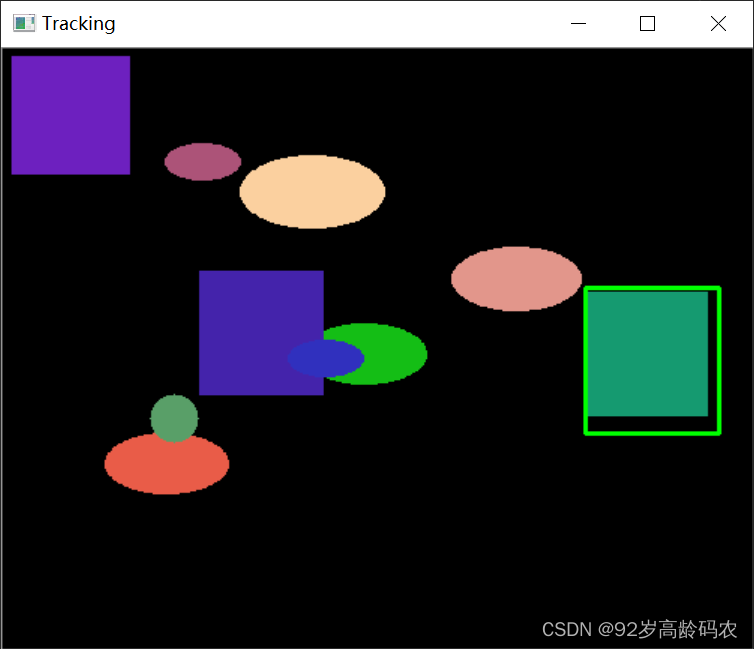
总结
通过本文的学习,我们对OpenCV在移动物体检测和目标跟踪领域的应用有了全面的了解。从基础的差值法到复杂的学习型跟踪器,每种方法都有其独特的优势和应用场景。差值法虽然简单,但在某些情况下非常有效。基于模板、特征和密度的方法提供了更多灵活性和准确性,适用于更复杂的场景。而基于模型和学习的方法则代表了目标跟踪技术的最新进展,能够处理极其复杂的跟踪环境。
不同的跟踪技术各有千秋,适合解决不同类型的问题。作为一个动态发展的领域,计算机视觉和目标跟踪技术仍有很大的发展空间,未来定将带来更多创新和突破。