翻译: 生成式人工智能的工作原理How Generative AI works
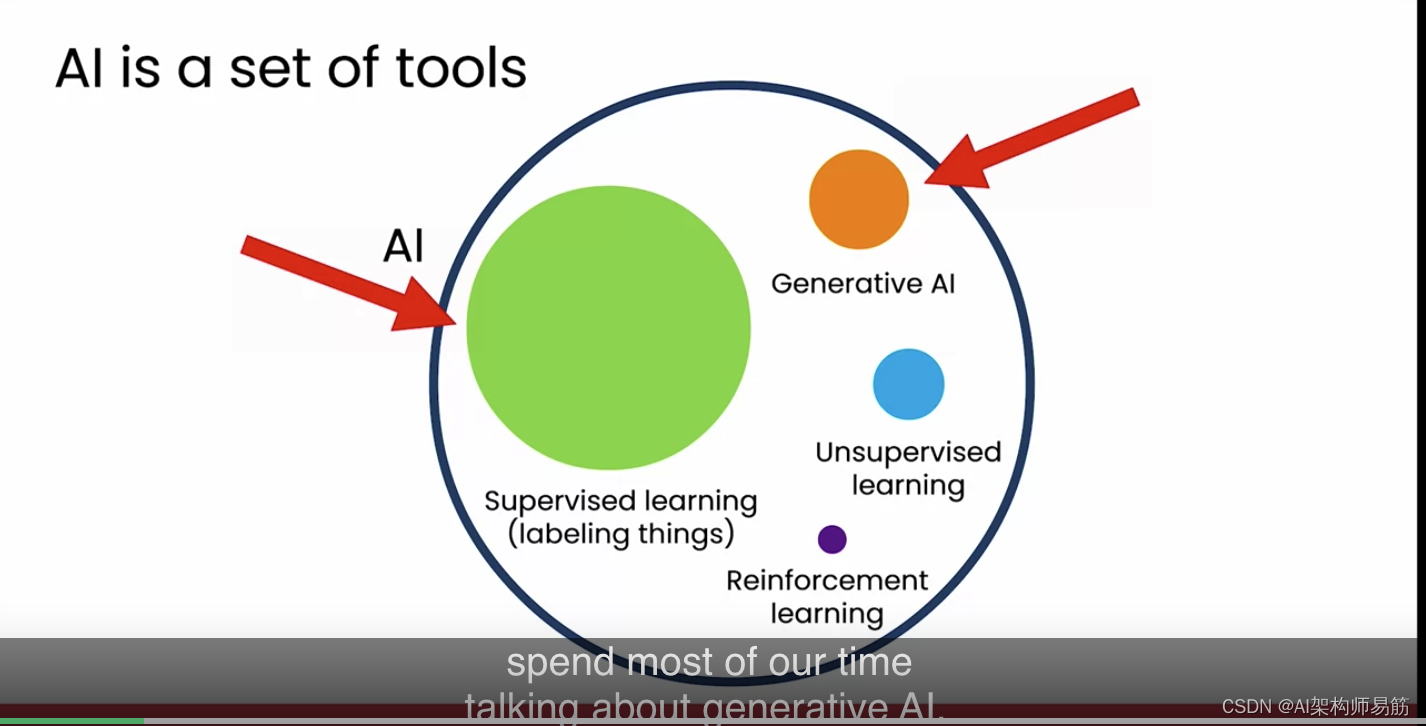
ChatGPT 和 Bard 等系统生成文本的能力几乎像魔法一样。它们确实代表了 AI 技术的一大步进。但是文本生成到底是如何工作的呢?在这个视频中,我们将看看生成式 AI 技术的底层原理,这将帮助你理解你可以如何使用它,以及何时可能不想依赖它。让我们来看看。首先让我们看看生成式 AI 在 AI 领域中的位置。关于 AI 有很多炒作和兴奋,我认为一个有用的方式是将 AI 视为一系列工具的集合。AI 中最重要的工具之一是监督学习,它非常擅长于标记事物。如果你不知道这意味着什么,不用担心,我们将在下一张幻灯片中更多地讨论这个。其次是生成式 AI,这个领域直到最近才开始表现得非常好。如果你研究 AI,你可能会认识到还有其他工具,比如所谓的无监督学习和强化学习。但为了这门课程的目的,我将简要介绍什么是监督学习,然后花大部分时间讨论生成式 AI。
这两个,监督学习和生成式 AI,是当今 AI 中最重要的两个工具。对于大多数商业用例,如果你现在不担心这些工具以外的其他工具,你应该没问题。
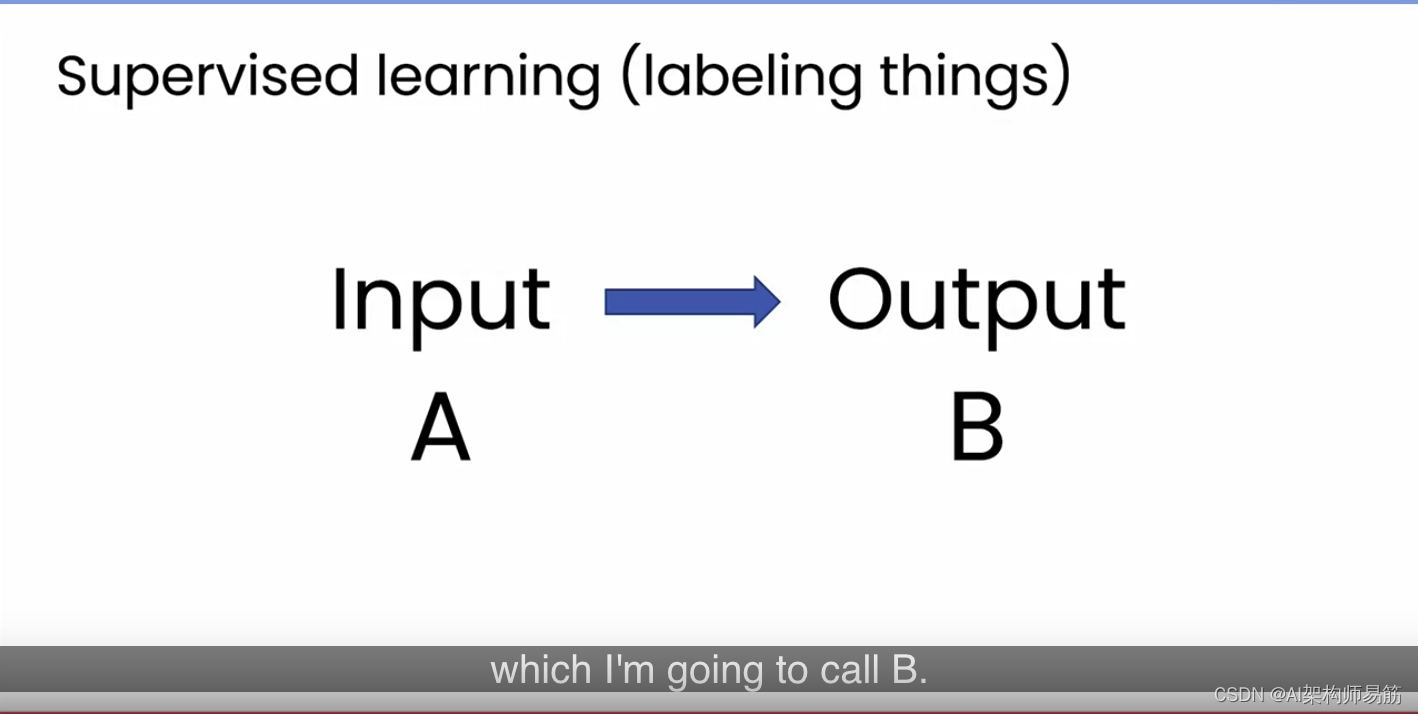
在描述生成式 AI 如何工作之前,让我简要描述一下什么是监督学习,因为生成式 AI 是使用监督学习构建的。监督学习是一种技术,使计算机在给定一个输入(我将称之为 A)时非常擅长生成相应的输出(我将称之为 B)。

看几个例子。给定一封电子邮件,监督学习可以决定这封电子邮件是否是垃圾邮件。输入 A 是一封电子邮件,输出 B 是 0 或 1,其中 0 表示非垃圾邮件,1 表示垃圾邮件。这就是今天的垃圾邮件过滤器工作原理。作为第二个例子,可能是我曾经参与过的最赚钱的应用,不是最鼓舞人心,但对一些公司来说是赚钱的,是在线广告,其中给定一个广告和一些关于用户的信息,一个 AI 系统可以生成一个与您是否可能点击该广告相对应的输出 B。通过显示略微更相关的广告,这为在线广告平台带来了可观的收入。在自动驾驶汽车和驾驶辅助系统中,监督学习被用来将你的汽车前方的图像和雷达信息作为输入,并标记出其他汽车的位置。给它一个医疗 X 光片,它可以尝试用医疗诊断来标记它。我还在制造缺陷检查方面做了很多工作,你可以让一个系统拍摄一部手机的照片,当它从生产线上滚下来时,检查手机是否有任何划痕或其他缺陷,或者在语音识别中,输入 A 将是一段音频,我们将用文本转录来标记它,或者作为最后一个例子,如果你经营一家餐馆或其他偶尔有人写评论的生意,监督学习可以阅读这些评论,并将每一个标记为具有正面或负面情绪。这对于监控业务声誉很有用。
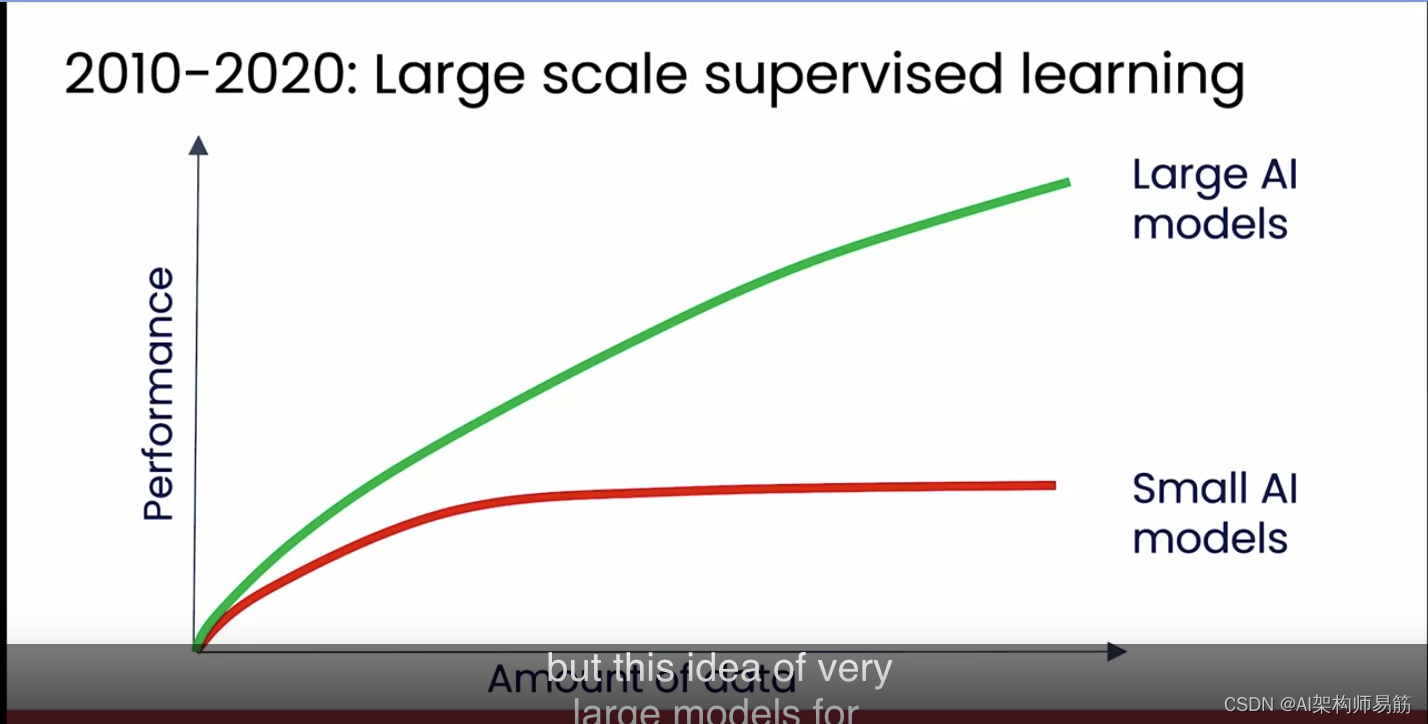
事实证明,大约 2010-2020 年的十年是大规模监督学习的十年。我想简要谈谈这一点,因为事实证明,这为现代生成式 AI 奠定了基础。但我们从 2010 年左右开始发现的是,对于很多应用来说,我们有很多数据,但即使我们提供了更多数据,如果我们训练的 AI 模型很小,它的性能并没有变得更好。这意味着,例如,如果你正在构建一个语音识别系统,即使你的 AI 听了成千上万小时或数十万小时的数据,这是很多数据,与只听了较少量音频数据的系统相比,它并没有变得更准确。但越来越多的研究人员在这一时期开始意识到,如果你训练一个非常大的 AI 模型,意味着在非常快速、非常强大的计算机上,有很多内存的 AI 模型,那么随着你提供越来越多的数据,它的性能会越来越好。
事实上,多年前当我开始并领导了 Google Brain 团队时,我为 Google Brain 团队设定的主要使命是,我说,让我们只是构建非常非常大的 AI 模型并向它们提供大量数据。幸运的是,这个配方奏效了,并最终推动了 Google 的许多 AI 进步。大规模监督学习今天仍然很重要,但这种用于标记事物的非常大的模型的想法是我们今天如何获得生成式 AI 的。

让我们看看生成式 AI 是如何使用一种叫做大型语言模型的技术来生成文本的。这是大型语言模型(我将缩写为 LLM)生成文本的一种方式。给定一个输入,比如“我喜欢吃”,这被称为提示,一个 LLM 然后可以用“百吉饼配奶油芝士”之类的东西来完成这个句子,或者如果你再运行一次,它可能会说“我妈妈的肉饼”,或者如果你第三次运行,也许它会说“和朋友一起出去”。一个大型语言模型是如何生成这个输出的呢?事实证明,LLM 是通过使用监督学习构建的。这是一种将输入 A 和输出标签 B 的技术。它使用监督学习来反复预测下一个词是什么。例如,如果一个 AI 系统在互联网上读到了一句话,比如“我最喜欢的食物是百吉饼配奶油芝士”,那么这一个句子就会变成很多数据点,让它尝试学习预测下一个词。具体来说,根据这个句子,我们现在有一个数据点,它说,给定短语“我最喜欢的食物是”,你认为下一个词是什么?在这种情况下,正确的答案是百吉饼。此外,给定“我最喜欢的食物是百吉饼”,你认为下一个词是什么?是“配”,等等。

这句话被转化为多个输入 A 和输出 B,以便从中学习,其中 LLM 正在学习给定几个词来预测接下来的词是什么。当你在大量数据上训练一个非常大的 AI 系统时,对于 LLM 来说,大量数据意味着数千亿甚至超过一万亿的词,那么你就会得到一个像 ChatGPT 这样的大型语言模型,它在给定一个提示时非常擅长生成一些额外的词作为响应。现在,我暂时省略一些技术细节。具体来说,下周我们将讨论一个使 LLM 不仅仅预测下一个词,而且实际上学会遵循指令并在其输出中保持安全的过程。但 LLM 的核心是这项从大量数据中学习预测下一个词的技术。这就是大型语言模型的工作方式;它们被训练来反复预测下一个词。事实证明,许多人,也许包括你,已经发现这些模型对日常工作中的写作、寻找基本信息或作为思考伙伴帮助思考问题很有用。
参考
https://www.coursera.org/learn/generative-ai-for-everyone/lecture/FhzP3/how-generative-ai-works