Hive数据库与表操作
文章目录
- 一、准备工作
- 二、Hive数据库操作
- (一)Hive数据存储
- (二)创建数据库
- (三)查看数据库
- (四)修改数据库信息
- (五)使用数据库
- (六)删除数据库
- Hive是一个建立在Hadoop上的数据仓库系统,它提供了类似于SQL的查询语言(称为HiveQL),允许用户通过类似于传统数据库的方式查询和分析存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。
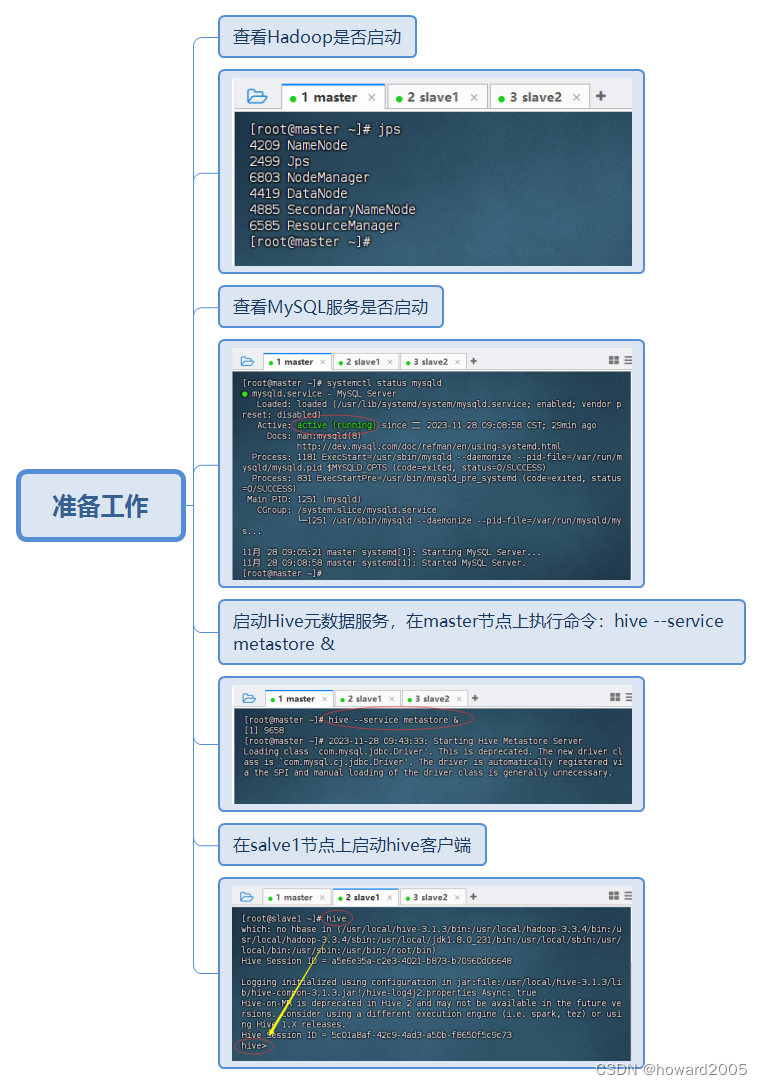
一、准备工作
二、Hive数据库操作
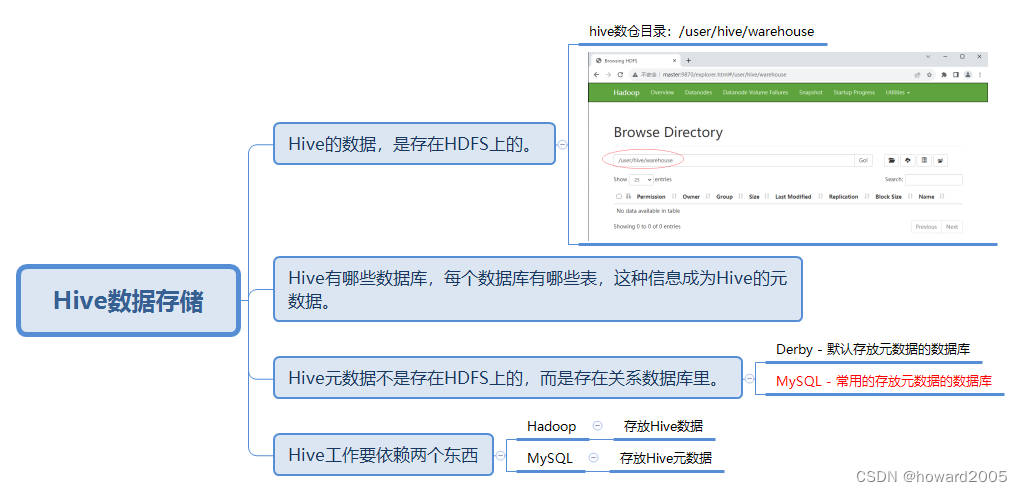
(一)Hive数据存储
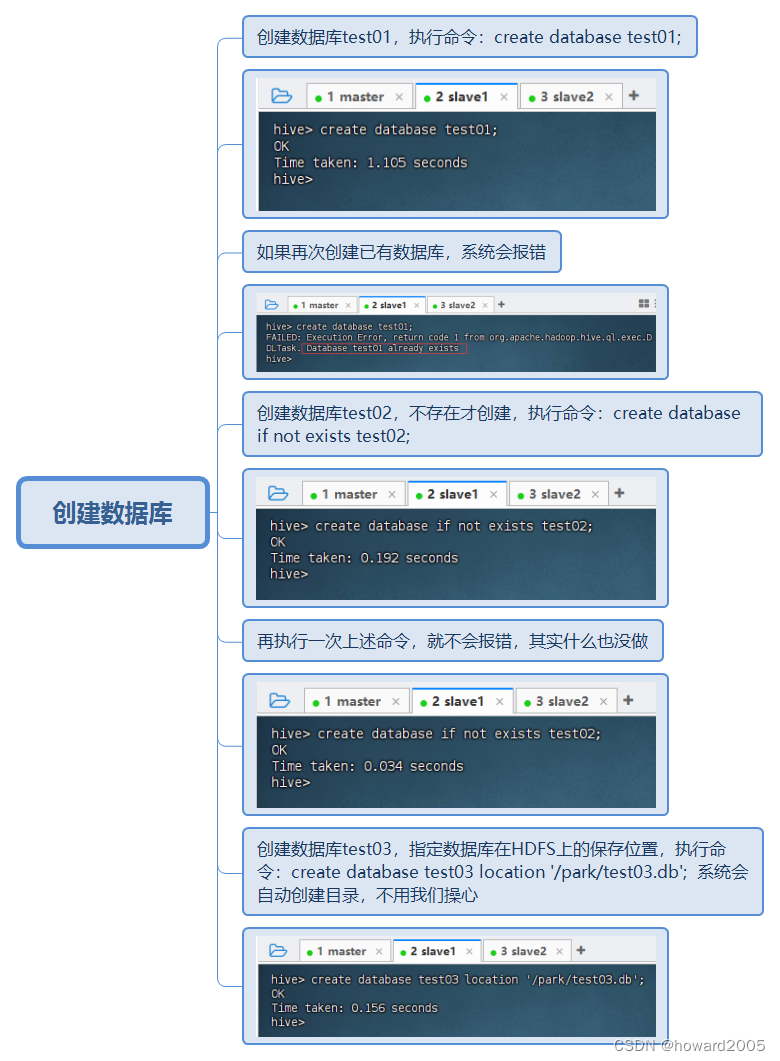
(二)创建数据库
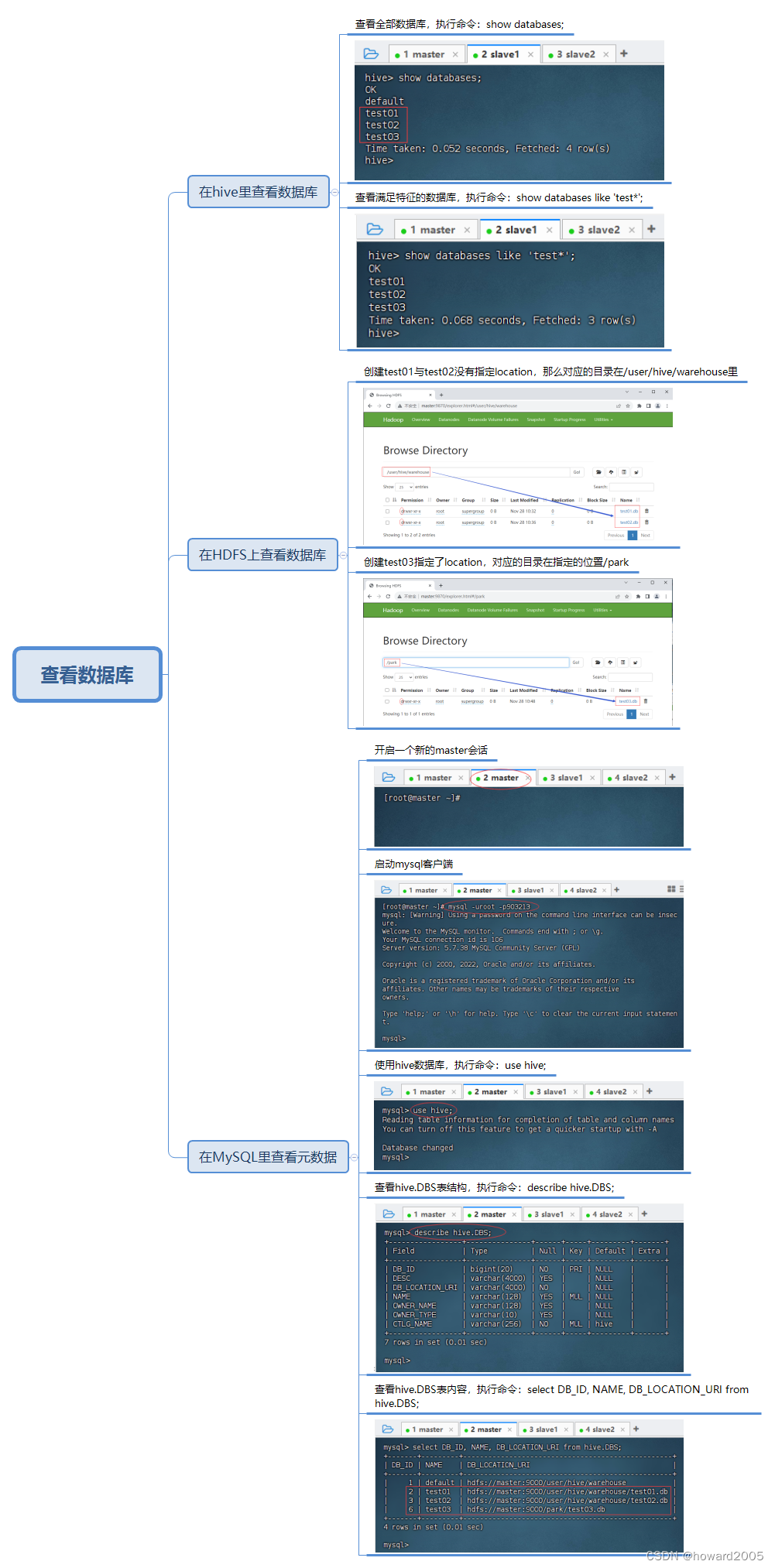
(三)查看数据库
- 注意,我们创建的hive数据库,对应的是HDFS上的目录,比如数据库
test01,对应的就是test01.db目录
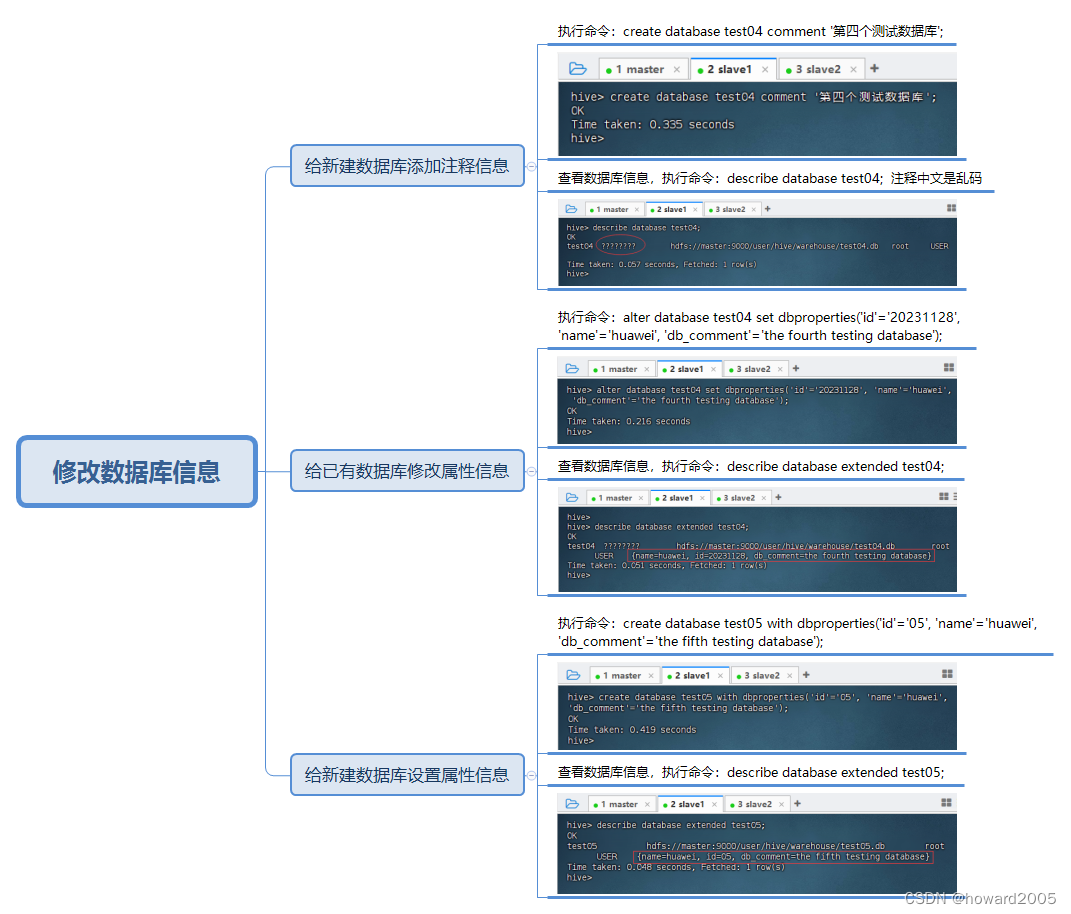
(四)修改数据库信息
(五)使用数据库

(六)删除数据库
