亚马逊云科技AI创新应用下的托管在AWS上的数据可视化工具—— Amazon QuickSight
目录
Amazon QuickSight简介
Amazon QuickSight的独特之处
Amazon QuickSight注册
Amazon QuickSight使用
Redshift和Amazon QuickSightt平台构建数据可视化应用程序
构建数据仓库
数据可视化
Amazon QuickSight简介

亚马逊QuickSight是一项可用于交付的云级商业智能 (BI) 服务easy-to-understand向与您共事的人提供见解,无论他们身在何处。亚马逊QuickSight连接到您的云端数据,并合并来自许多不同来源的数据。在单个数据仪表板中,QuickSight可以包括 AWS 数据、第三方数据、大数据、电子表格数据、SaaS 数据、B2B 数据等。作为一项完全托管的基于云的服务,亚马逊QuickSight提供企业级安全性、全球可用性和内置冗余。它还提供了从 10 个用户扩展到 10,000 个用户所需的用户管理工具,所有这些工具都无需部署或管理基础架构。
QuickSight让决策者有机会在交互式视觉环境中探索和解释信息。他们可以从您网络上的任何设备和移动设备安全访问仪表板。
Amazon QuickSight的独特之处
以下是使用亚马逊的一些好处QuickSight用于分析、数据可视化和报告:
-
内存引擎,称为SPICE,以惊人的速度响应。
-
没有许可证的前期成本,总拥有成本 (TCO) 也很低。
-
无需安装应用程序即可进行协作分析。
-
将各种数据合并为一项分析。
-
以仪表板的形式发布和共享您的分析。
-
控制功能在仪表板中可用。
-
无需管理精细的数据库权限,仪表板查看者只能看到您共享的内容。

对于高级用户,QuickSight企业版提供更多功能:
-
借助由机器学习 (ML) 提供支持的自动化和可自定义的数据见解,为您节省时间和金钱。这使您的组织无需任何机器学习知识即可完成以下操作:
-
自动做出可靠的预测。
-
自动识别异常值。
-
找出隐藏的趋势。
-
根据关键业务驱动因素采取行动。
-
将数据转换为easy-to-read叙述,例如仪表板的标题图块。
-
-
提供额外的企业安全功能,包括:
-
使用联合用户、群组和单点登录(IAM 身份中心)AWS Identity and Access Management(IAM) 联邦、SAML、OpenID Connect 或AWS Directory Service for Microsoft Active Directory。
-
AWS 数据访问的精细权限。
-
行级安全。
-
高度安全的静态数据加密。
-
访问 Amazon 虚拟私有云中的 AWS 数据和本地数据
-
-
优惠pay-per-session为您置于 “读者” 安全角色的用户定价—读者们是仪表板订阅者,即查看报告但不创建报告的人。
-
赋予你创作能力QuickSight通过部署嵌入式控制台分析和仪表板会话,成为您自己的网站和应用程序的一部分。
-
为分析服务的增值经销商 (VAR) 提供多租户功能,使我们的业务成为您的业务。
-
使您能够以编程方式编写可转移到其他 AWS 账户的控制面板模板脚本。
-
使用分析资产的共享和个人文件夹,简化访问管理和组织。
-
为以下对象启用更大的数据导入配额SPICE数据摄取和更频繁的数据刷新。

Amazon QuickSight注册
-
为了使用QuickSight,需要拥有一个有效的AWS账户。 如果没有AWS账户,访问http://console.aws.amazon.com/并首先创建一个账户。 登录到AWS控制台后,搜索QuickSight并单击链接,如下所示:
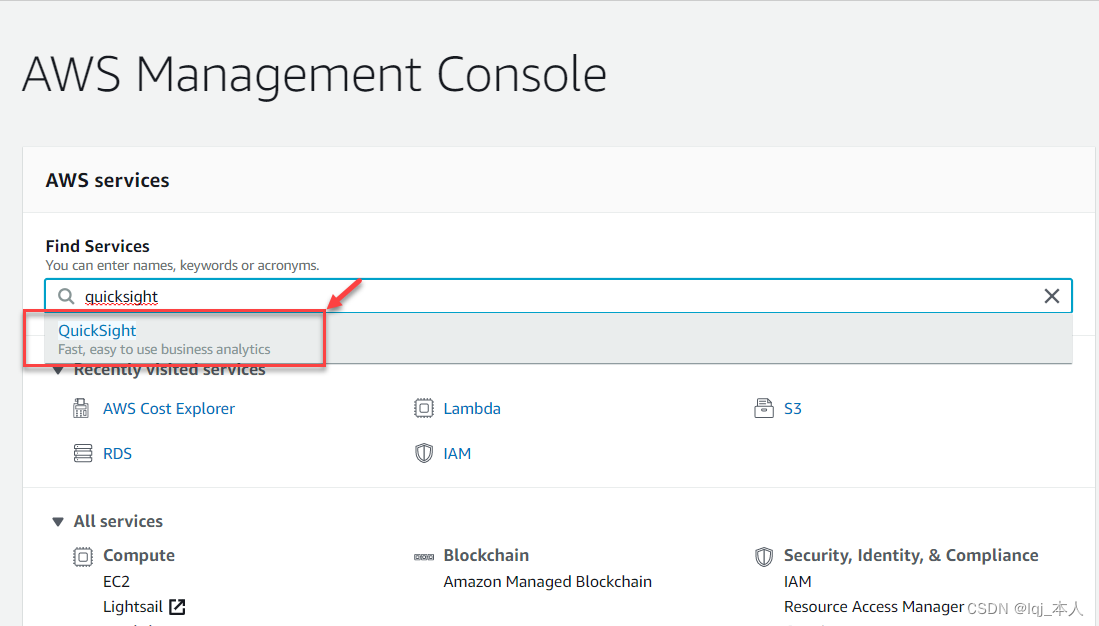
-
将被导航到Amazon QuickSightt的门户,将特别要求在其中注册该服务。 单击“ 注册QuickSight”,然后继续进行。 在下一页上,可以选择版本。 我这里选择标准版 ,然后单击继续 。
-
在下一页上,将需要提供QuickSight服务的帐户名和一个可以接收通知的电子邮件地址 。 完成后,单击完成。
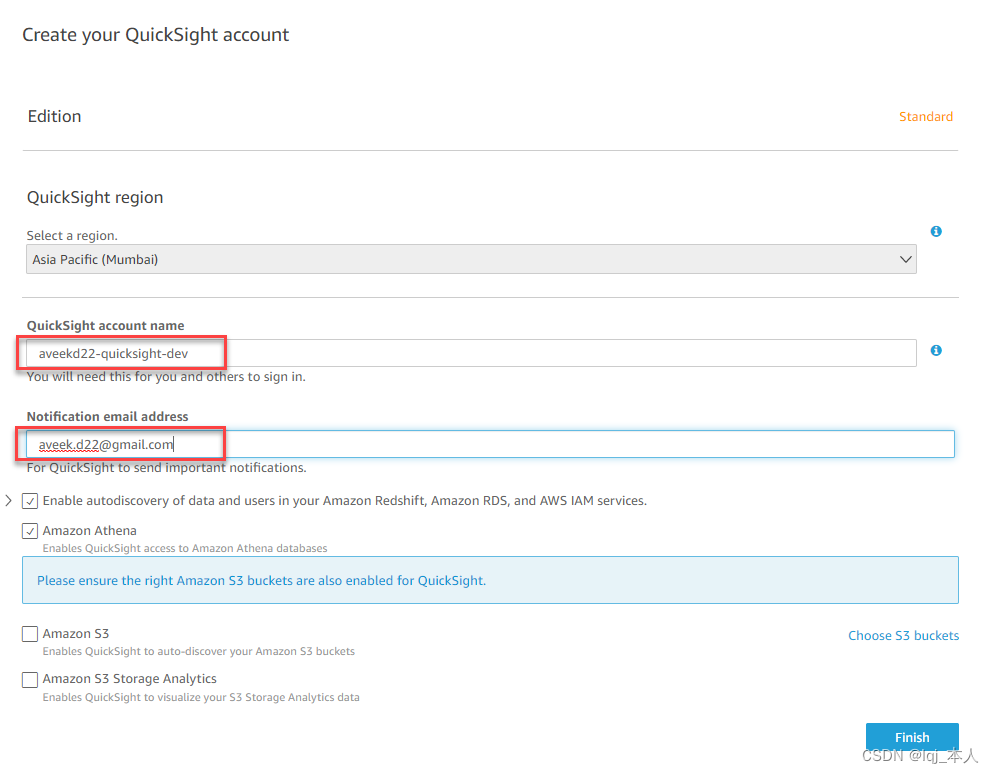
-
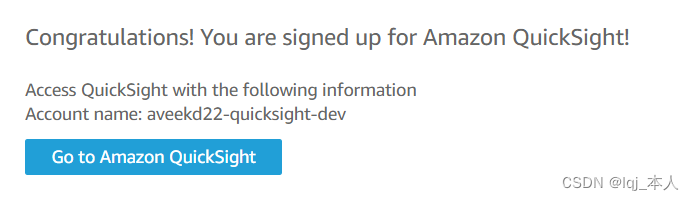
该过程可能需要花费几分钟,一旦完成,将收到一条消息,提示成功注册Amazon QuickSightt。
Amazon QuickSight使用
-
单击转到Amazon QuickSightt以启动服务。 将被导航到其他服务,在其中可以看到QuickSight正在加载一些已经准备好的示例分析。

-
只是为了对样本分析有所了解,让我们继续打开列表中可用的Sales Pipeline分析 。 所见,将启动一个新的分析,将能够按照以下方式查看报告。

Redshift和Amazon QuickSightt平台构建数据可视化应用程序
-
创建Redshift集群
-
将S3的数据文件批量装载到Redshift数据库
-
使用Quicksight对数据表进行可视化
本程序的架构图如下图所示:

构建数据仓库
-
查看数据
-
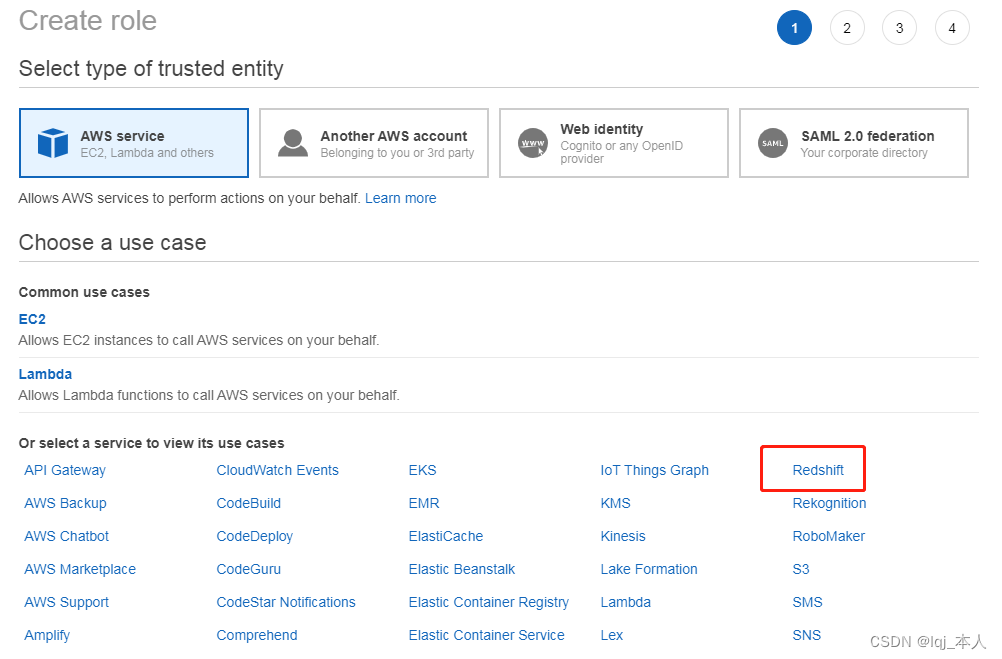
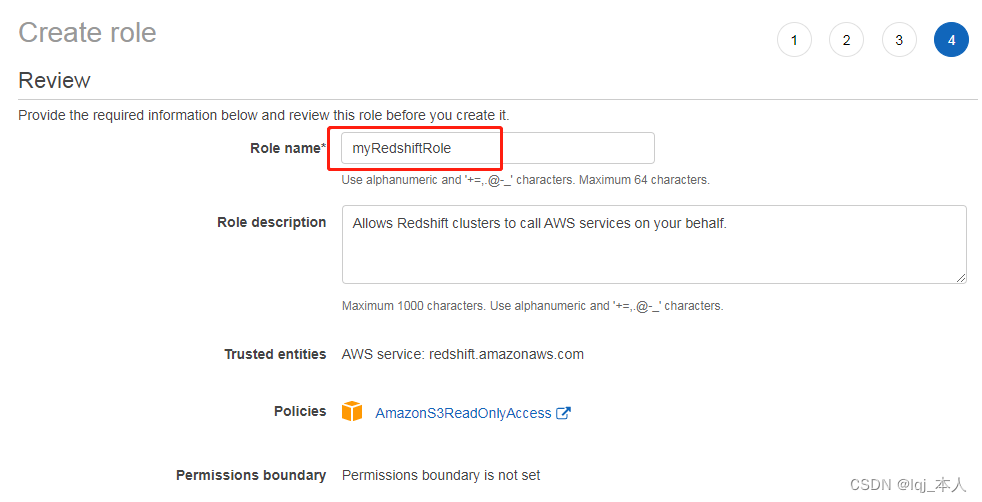
创建 IAM Role
选择 IAM 服务,点击角色->创建角色,选择 Redshift
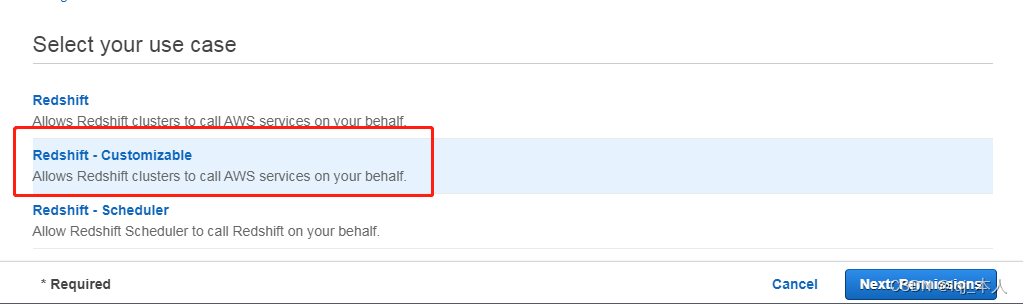
选择 Redshift-Customizable,点击下一步权限
添加权限名字 myRedshiftRole,点击确认
-
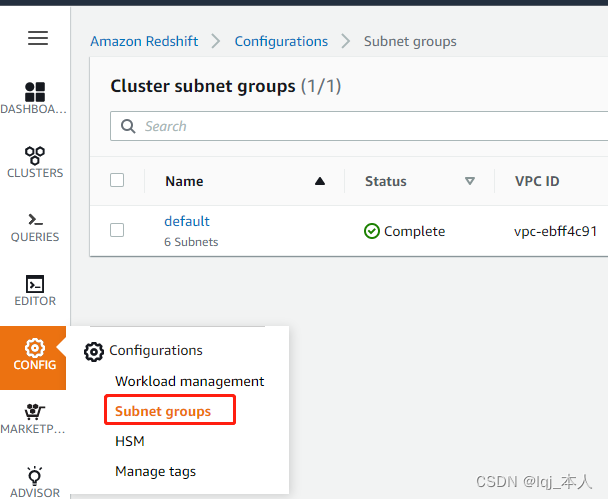
创建子网组
创建 Redshift 集群前,先创建子网组。选择 Redshift 服务,在左边菜单条中选择“CONFIG”->”管理子网组“
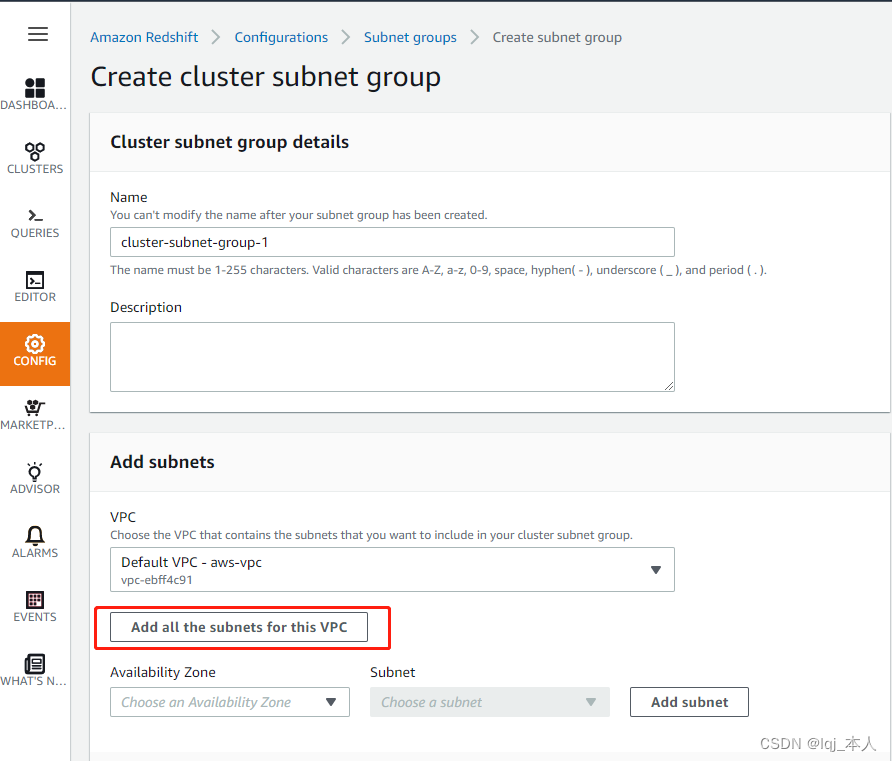
然后选择“创建集群子网组”,子网组名称可接受缺省名字“cluster-subnet-group-1“,在描述框中输入任意说明文字。选择“默认VPC”,选择“为此 VPC 添加所有子网“,然后点击“创建集群子网组”完成创建子网组。
-
创建 Redshift 集群
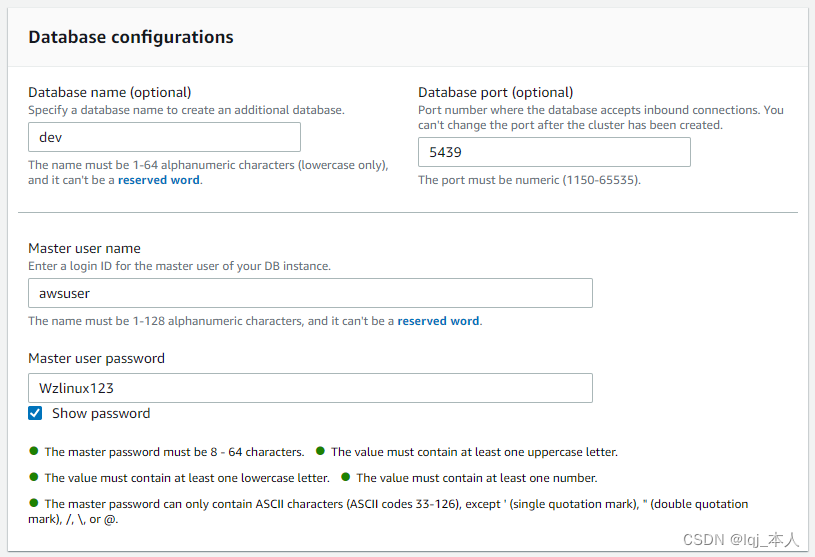
在左侧菜单中选择“集群”,点击“创建集群“,设置集群的名字(不要用中文,不要用特殊字符,英文开头,可以有数字,可以有减号),节点类型选择 dc2.large

数据库配置接受缺省值,输入主用户密码(请记住您输入的密码)
集群权限中,选择前面创建的 myRedshiftRole 角色,点击“Associate IAM role”
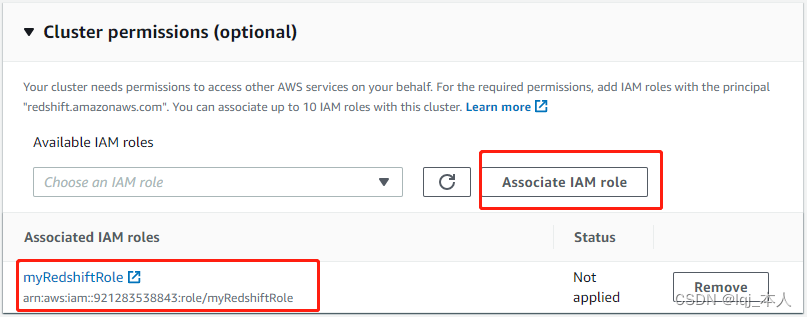
其它配置中,选择默认 VPC,缺省安全组和之前创建的集群子网组,点击确认“创建集群”,大约5分钟后,集群变为“Available”状态。
-
访问 Redshift 数据库
有两种方式访问 Redshift 数据库,一种是通过 Redshift Console 上的查询编辑器,一种是通过 SQL 客户端(例如 SQL Workbench/J 客户端)。本实验中为了简便操作,使用 Redshift Console 上的查询编辑器来访问数据库。选择左边菜单中“编辑器”,在“连接到数据库”窗口中输入一下参数,然后“连接到数据库”

-
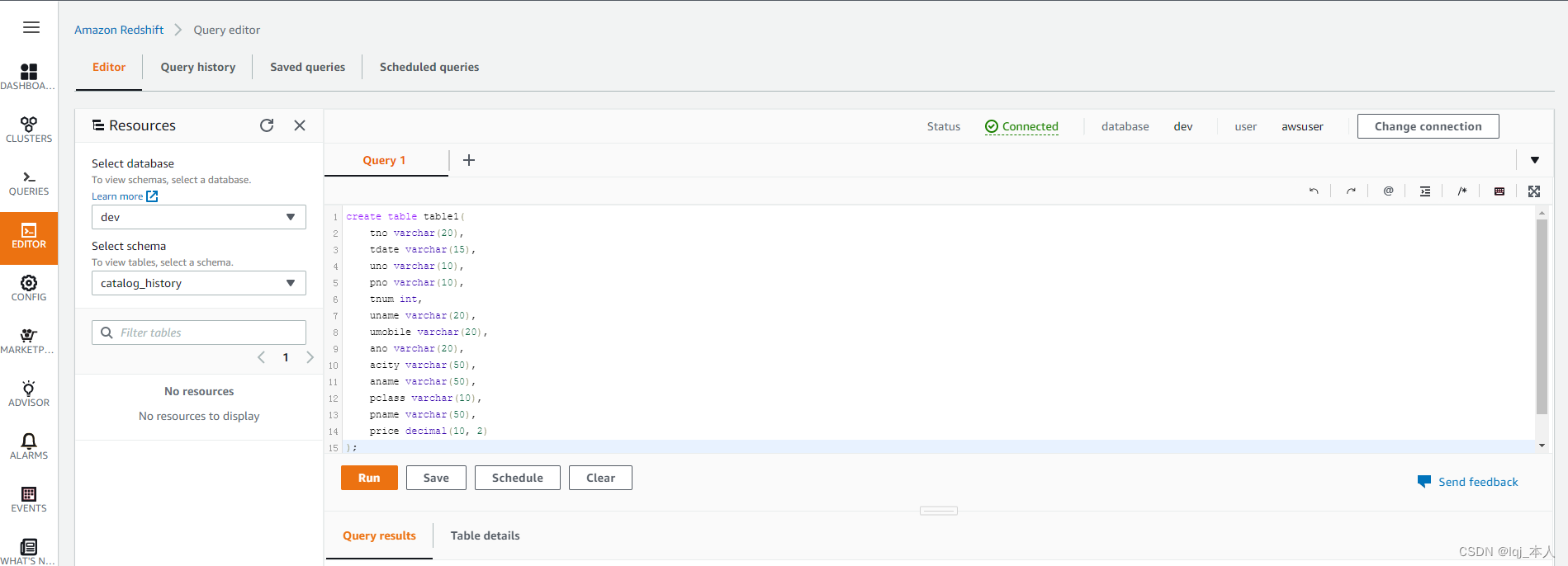
创建表
在查询编辑器中创建表,在左边Select Schema中选择“Public”,然后在SQL查询窗口中输入创建表的SQL语句:
create table table1( tno varchar(20), tdate varchar(15), uno varchar(10), pno varchar(10), tnum int, uname varchar(20), umobile varchar(20), ano varchar(20), acity varchar(50), aname varchar(50), pclass varchar(10), pname varchar(50), price decimal(10, 2) );
-
导入S3数据
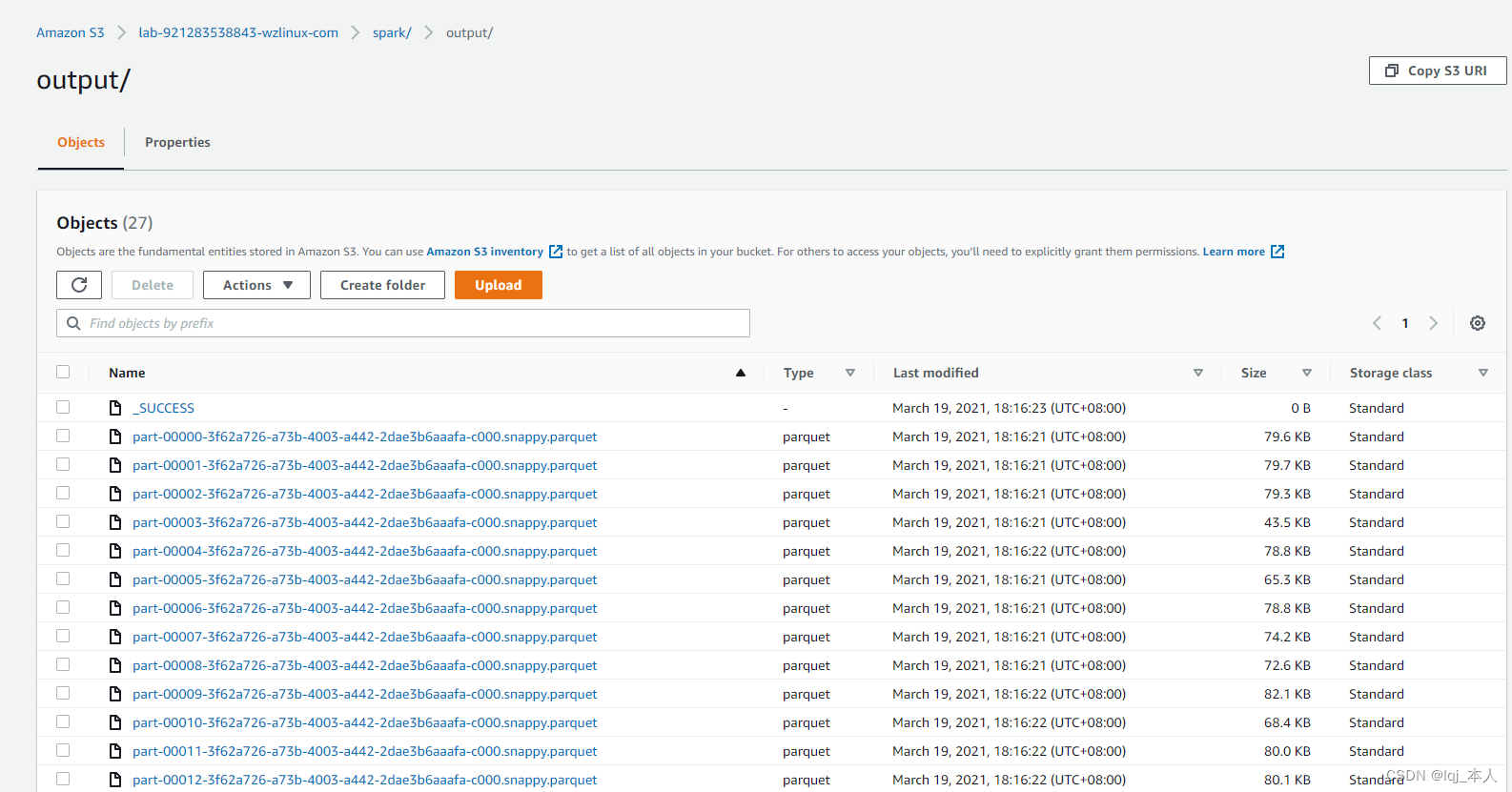
新开一个 SQL 查询窗口(此处为 Query 2),输入下面装载 S3 数据的 SQL 命令,注意要将帐号替换为实际的帐号 ID,并确认争取的 S3 桶地址。
copy table1 from 's3://lab-921283538843-wzlinux-com/spark/output/' credentials 'aws_iam_role=arn:aws:iam::921283538843:role/myRedshiftRole' format as parquet;

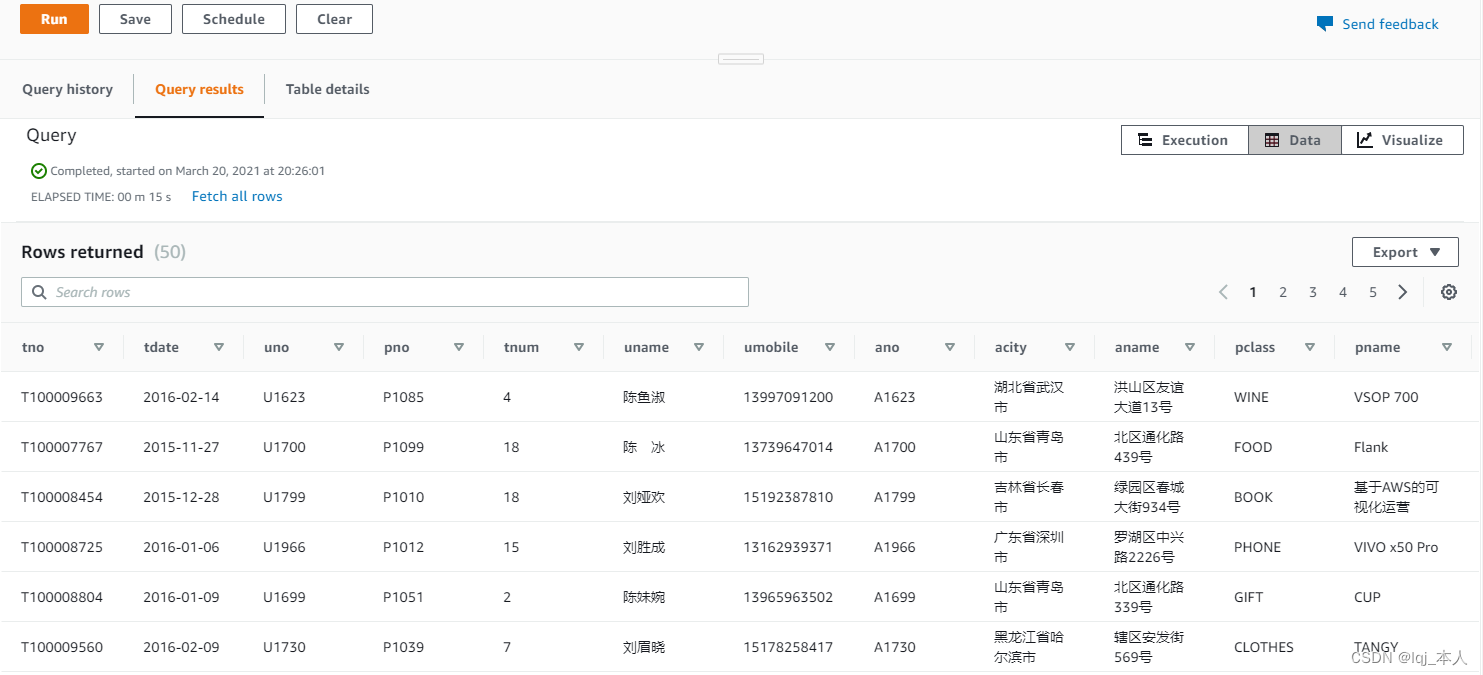
点击运行,结果应显示为“Completed”。在 Query3中 输入”select from table1;”应查询中表中的数据。在Query4 中输入“select count() from table1; “,应查询到表中的数据。这说明 S3 中的数据已完成 copy 到 Redshift 数据仓库中。
-
允许 Internet 访问
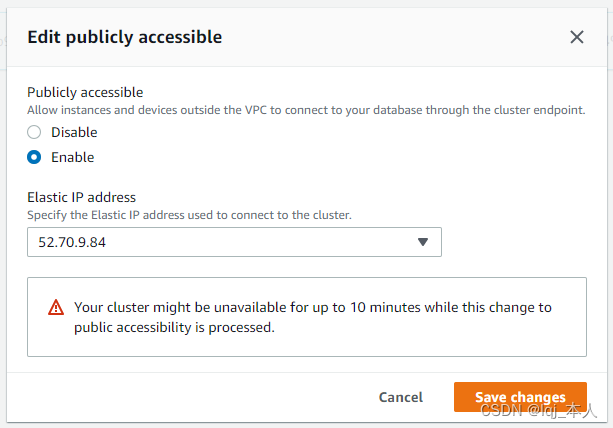
下一步,我们将使用 AWS Quicksight 将 Redshift 中的数据进行可视化展现。在此之前,需要给予 Quicksight 从 Internet 访问 Redshift 的权限。为此,我们先在 EC2 菜单中创建一个公网的弹性 IP 地址(过程略)。然后修改 Redshift 属性,赋予公开访问权限。

将可公开访问改成“是”,选择对应的弹性公网 IP 地址即可。
数据可视化
-
启用 Quicksight
-
创建数据集
进入Quicksight控制台界面,点击左侧数据集,选择创建“新数据集”

选择 Redshift(自动发现)数据集,Redshift 也有手动连接的方式.
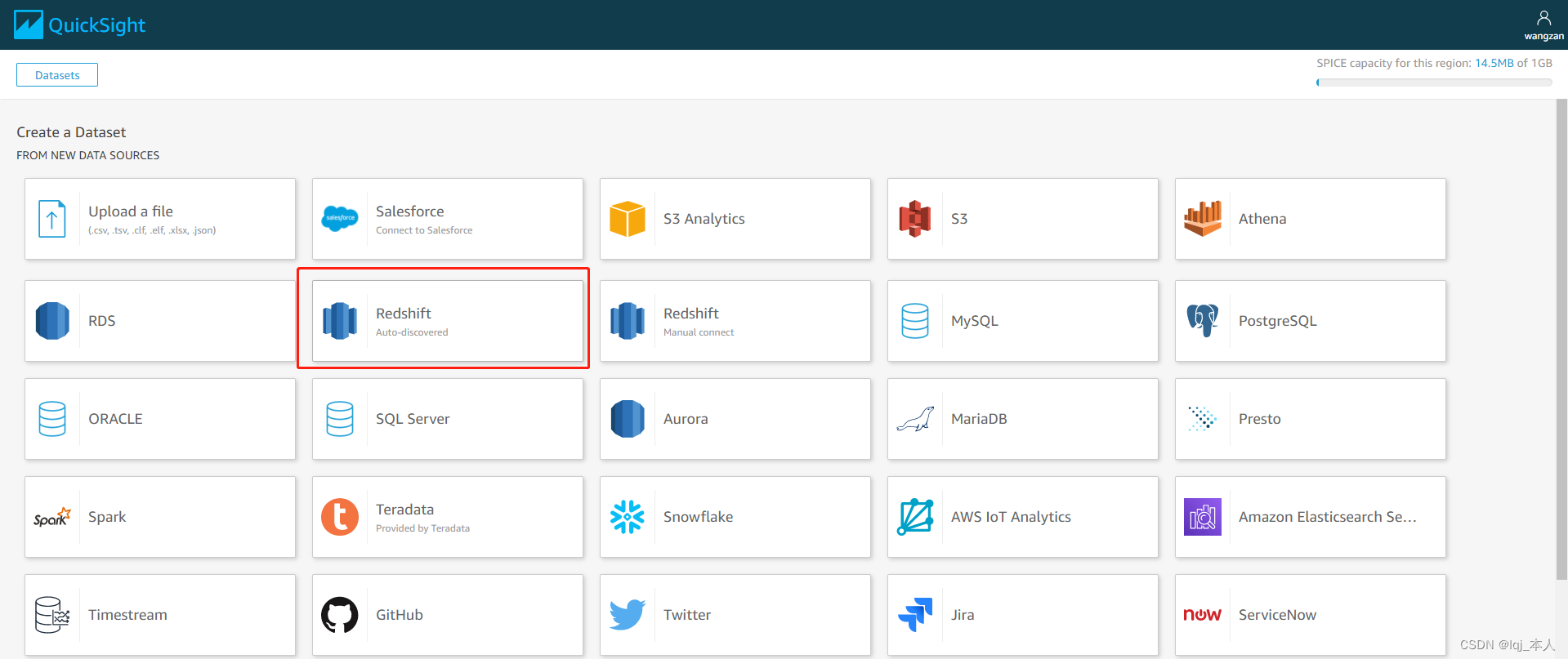
输入连接参数,选择“创建 data source”,选择对应的 Redshift 数据库,注意配置对应的地址,端口,数据库名称,用户名和密码
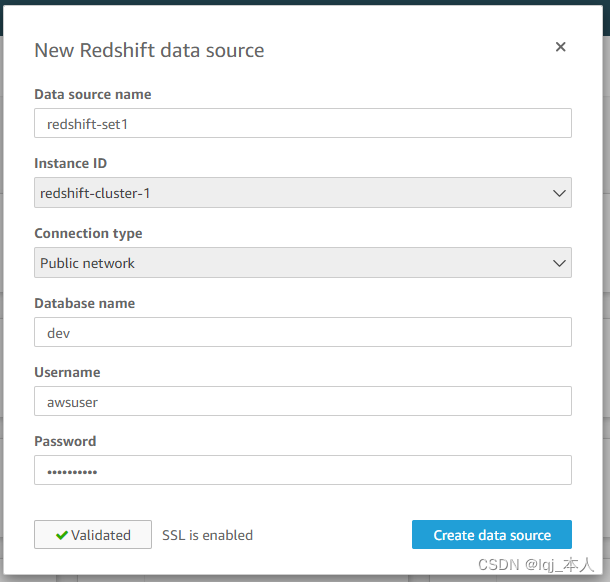
选择 Table1,点击“Select”,最后点击“Virtualize”完成创建数据集(此处我们选择把数据从 Redshift 导入到 Quicksigh 里面来,这样分析起来速度会快很多)
-
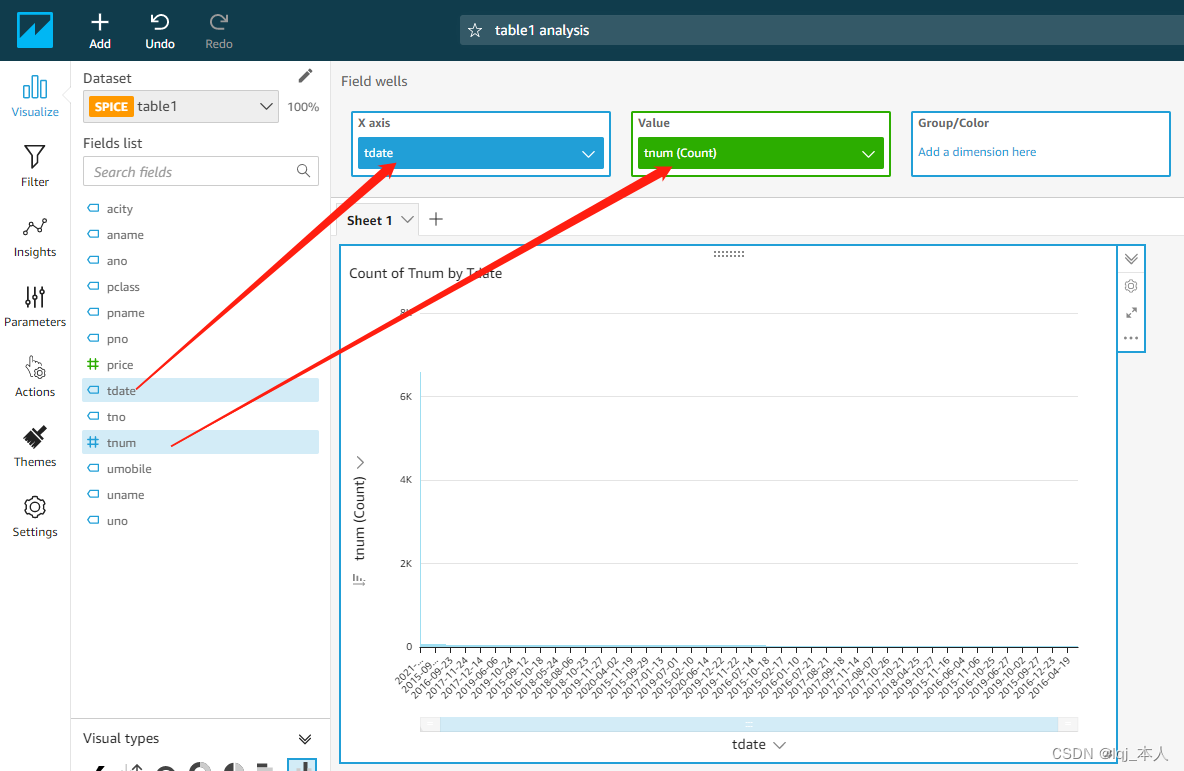
数据可视化
打开可视化对象窗口,选择展现方式为“竖条状图“
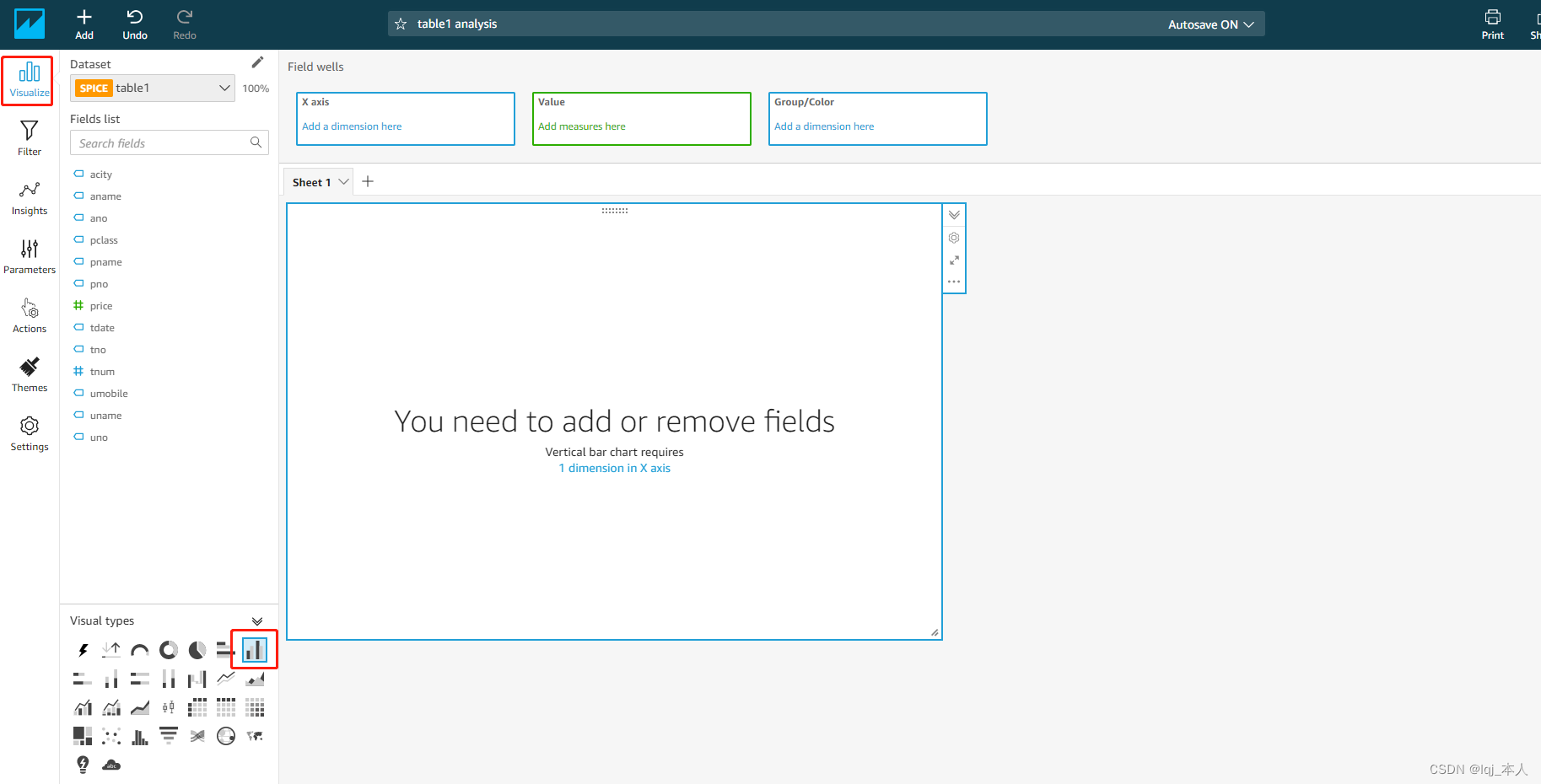
将 tdate 拖放到 X axis 栏,将 tnum 拖动到 value 栏(系统会自动选择计数)