InnoDB存储引擎体系结构中的各个组件是如何协同工作的?
查询 MySQL 支持的存储引擎:
select * from information_schema.engines;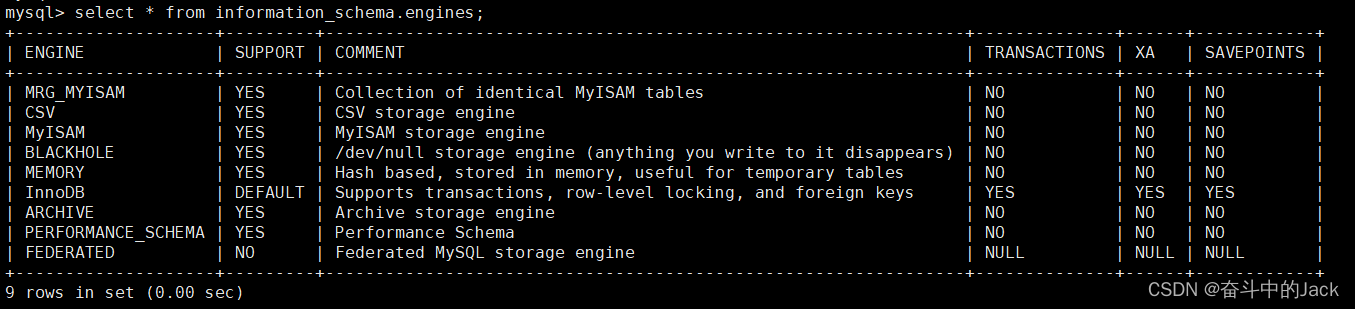
InnoDB存储引擎体系结构如下图(图片来源:XtraDB / InnoDB internals in drawing):
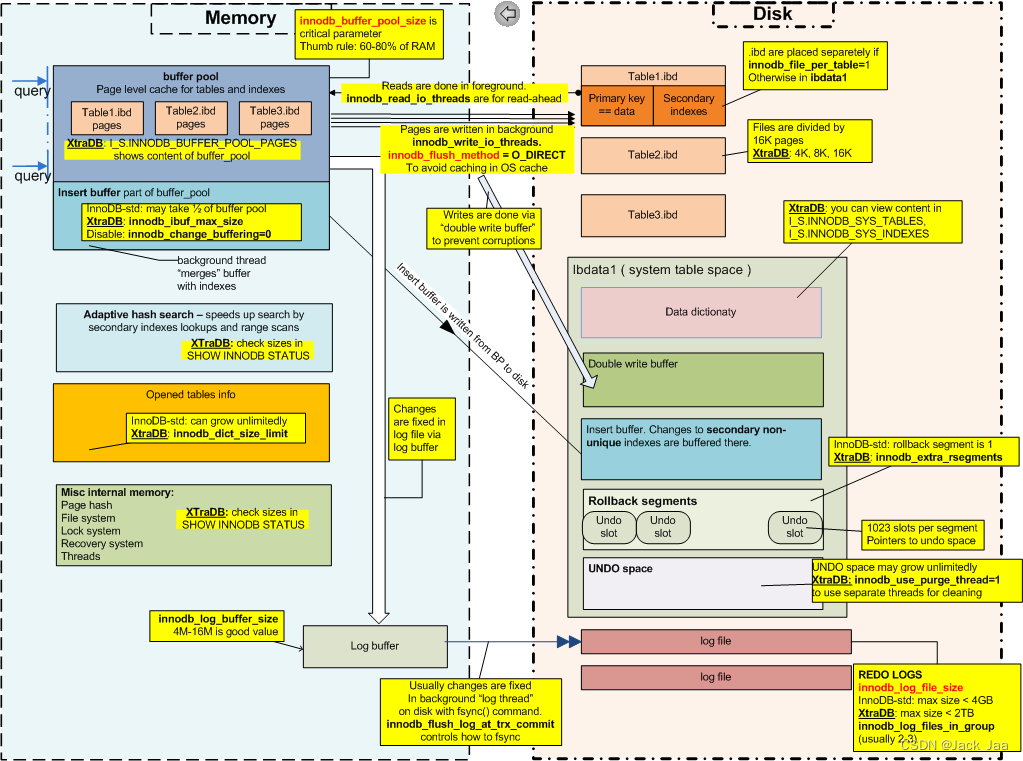
列举一个UPDATE场景加以说明。
假设有一个UPDATE语句正在执行:UPDATE test SET idx = 2 WHERE id=10,执行流程如下(这里主要以InnoDB存储引擎体系结构中的组件为主):
(1)在Server层进行词法解析,解析成MySQL认识的语法,查询什么表、什么字段,并生成查询路径树,选择最优查询路径。
(2)到了InnoDB存储引擎这里,先判断id=10这行数据对应的页是否在缓冲池中,如果不在,则将id=10记录对应的页从datafile中读入InnoDB缓冲池中(如果该页已经在缓冲池中,就省去了读入这一步),并对相关记录加独占锁。
(3)将idx修改之前的值和对应的主键、事务ID原来的信息写入Undo Tablespace的回滚段中。
(4)更改缓存页中的数据,并将更新记录和新生成的LSN值(日志序列号)写入Log Buffer中,更新完之后在缓冲池中这个页就是脏页了。
(5)在提交事务时,根据innodb_flush_log_at_trx_commit的设置,用不同的方式将Log Buffer中的更新记录刷新到redo log中,然后写binlog(二进制日志文件),写完binlog就开始commit(这里的commit是指binlog的commit,就是同步到磁盘),binlog同步之后就把binlog文件名和position(binlog文件内的位置)也写到redo log中。然后在redo log中写入一个commit标记,那么此时就完成了这个事务的提交。接下来释放独占锁。
(6)后台I/O线程根据需要择机将缓存中合适的脏页刷新到磁盘数据文件中。当然,在刷新脏页时要先拷贝一份到双写缓冲区中(如果开启了双写缓冲区功能的话),当双写缓冲区中的数据落盘之后,再从缓冲池中把脏页刷新到各个数据文件中。
摘自《千金良方:MySQL性能优化金字塔法则 3.5》