scrapy介绍,并创建第一个项目
一、scrapy简介
- scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
- Scrapy 使用了Twisted异步网络框架,可以加快我们的下载速度。
-
- Scrapy文档地址:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
- 工作流程
-
传统的爬虫流程
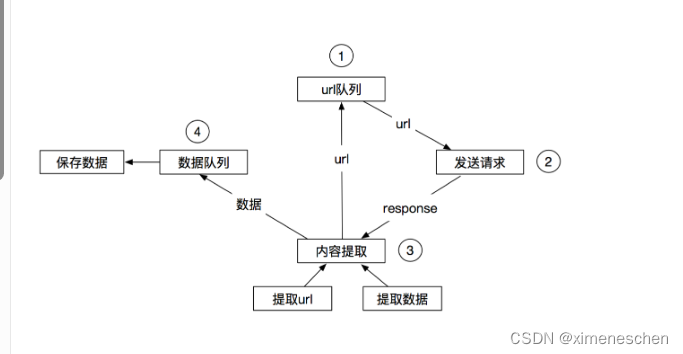
-
scrapy的流程
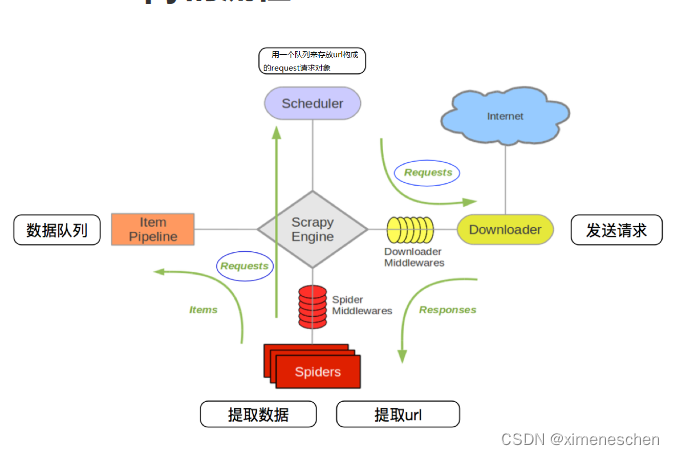
- 描述
- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
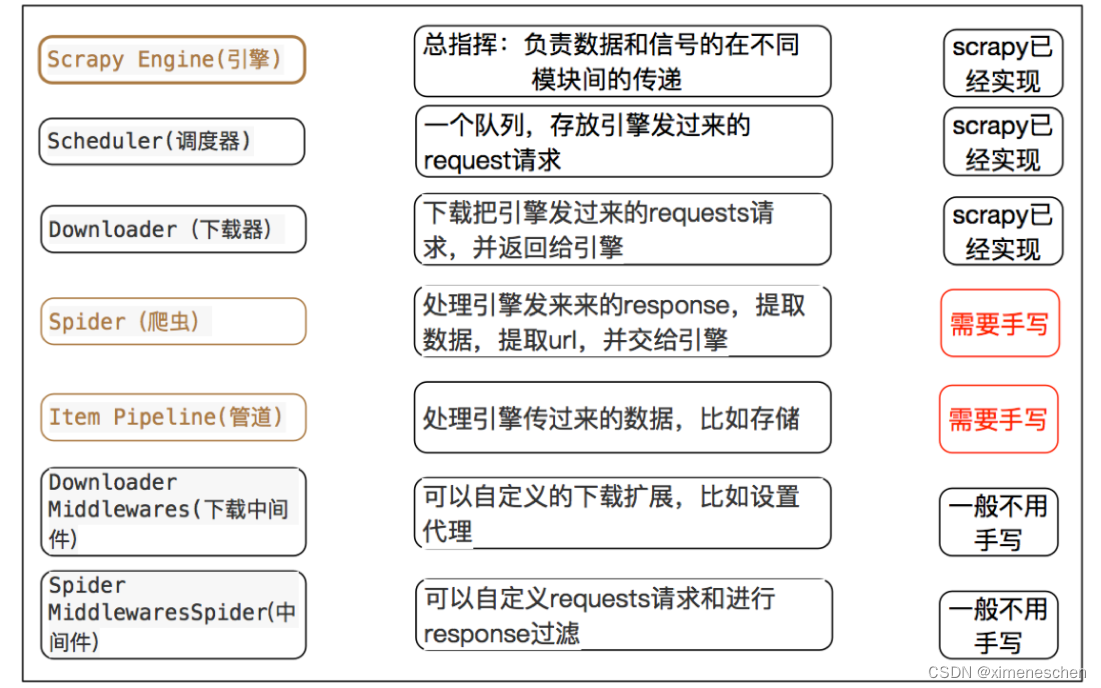
二、关于中间件
- 爬虫中间件(Spider Middleware)
作用: 爬虫中间件主要负责处理从引擎发送到爬虫的请求和从爬虫返回到引擎的响应。这些中间件在请求发送给爬虫之前或响应返回给引擎之前可以对它们进行处理。
- 功能:
- 修改请求或响应。
- 在请求被发送到爬虫之前进行预处理。
- 在响应返回给引擎之前进行后处理。
- 过滤或修改爬虫产生的请求和响应。
- 常见的爬虫中间件:
- HttpErrorMiddleware: 处理 HTTP 错误。
- OffsiteMiddleware: 过滤掉不在指定域名内的请求。
- RefererMiddleware: 添加请求的 Referer 头。
- UserAgentMiddleware: 添加请求的
- User-Agent 头。
- DepthMiddleware: 限制爬取深度。
- 下载中间件(Downloader Middleware)
-
作用: 下载中间件
主要负责处理引擎发送到下载器的请求和从下载器返回到引擎的响应。这些中间件在请求发送给下载器之前或响应返回给引擎之前可以对它们进行处理。 -
功能:
- 修改请求或响应。
- 在请求被发送到下载器之前进行预处理。
- 在响应返回给引擎之前进行后处理。
- 对请求进行代理、设置代理认证等。
- 常见的下载中间件:
HttpProxyMiddleware: 处理 HTTP 代理。- UserAgentMiddleware: 添加请求的 User-Agent头。
- RetryMiddleware: 处理请求重试。
- HttpCompressionMiddleware: 处理 HTTP 压缩。
- CookiesMiddleware: 管理请求的 Cookies。
三、scrapy的三个内置对象
- scrapy.Item:
-
作用: scrapy.Item 是一个简单的容器对象,
用于封装存储爬取到的数据。每个 scrapy.Item 对象都代表了网站上的一个特定数据项。 -
使用: 在 Scrapy 爬虫中,你可以定义一个继承自 scrapy.Item 的类,
定义这个类的属性来表示要提取的字段。这样,当你从页面中提取数据时,可以将提取到的数据存储在 scrapy.Item 对象中。 -
示例:
import scrapy
class MyItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
- scrapy.Request:
-
作用: scrapy.Request 对象
用于指示 Scrapy 下载某个URL,并在下载完成后返回一个 scrapy.Response 对象。 -
使用: 在爬虫中,
你可以创建 scrapy.Request 对象,指定要访问的URL、回调函数、请求方法、请求头等信息,然后通过调用这个对象,将请求添加到爬虫的调度队列中。 -
示例:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = ['http://example.com/page1', 'http://example.com/page2']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 处理响应的逻辑
pass
- scrapy.Response:
-
作用: scrapy.Response 对象表示从服务器接收到的响应,它包含了网页的内容以及一些有关响应的元数据。
-
使用: 在爬虫的回调函数中,你
将接收到的响应作为参数,通过对 scrapy.Response 对象的操作,提取数据或者进一步跟踪其他URL。 -
示例:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = ['http://example.com/page1']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 使用 response.xpath 或 response.css 提取数据
title = response.xpath('//h1/text()').get()
这三个内置对象是构建 Scrapy 爬虫时非常重要的组件。scrapy.Item 用于封装爬取到的数据,scrapy.Request 用于定义要爬取的URL和请求参数,scrapy.Response 用于处理从服务器返回的响应。通过巧妙地使用这些对象,你可以有效地构建和组织你的爬虫逻辑。
四、scrapy的入门使用
- 安装
pip/pip3 install scrapy
- scrapy项目开发流程
- 创建项目:
scrapy startproject mySpider
- 创建一个爬虫:
1.进入刚才的项目路径
2.执行生成命令:scrapy genspider <爬虫名字> <允许爬取的域名>
例如:scrapy genspider baidui baidu.com
3.执行后就会在myspider/spider下,生成一个baidu.py,这就是我们的爬虫文件
- 提取数据:
根据网站结构在spider中(即baidu.py文件)实现数据采集相关内容- 保存数据:
使用pipeline进行数据后续处理和保存
- 定义一个管道类
- 重写管道类的process_item方法
- process_item方法处理完item之后必须返回给引擎
- 在setting文件中启用管道


管道文件
import json
class ItcastPipeline():
# 爬虫文件中提取数据的方法每yield一次item,就会运行一次
# 该方法为固定名称函数
def process_item(self, item, spider):
print(item)
return item
配置文件
#值越小越先运行
ITEM_PIPELINES = {
'myspider.pipelines.ItcastPipeline': 400
}
- 运行爬虫项目
scrapy crawl baidu