浅谈一下布隆过滤器的设计之美
1 缓存穿透
2 原理解析
3 Guava实现
4 Redisson实现
5 实战要点
6 总结
布隆过滤器是一个非常有用的数据结构。它可以在大规模数据中高效地判断某个元素是否存在。布隆过滤器的应用非常广泛,不仅在搜索引擎、防垃圾邮件等领域中经常用到,而且在许多知名项目中都有布隆过滤器的身影,比如RocketMQ、Hbase、Cassandra、LevelDB、RocksDB等。在后端程序开发中,学习和理解布隆过滤器的原理和实现非常重要。除了可以提高程序的效率和准确性,更可以开拓我们的思维,激发我们对程序设计的热情。
所以,让我们一起深入探讨布隆过滤器的设计之美吧
1 缓存穿透
我们先来看一个商品服务查询详情的接口:

假设此商品既不存储在缓存中,也不存在数据库中,则没有办法回写缓存 ,当有类似这样大量的请求访问服务时,数据库的压力就会极大。
这是一个典型的缓存穿透的场景。
为了解决这个问题呢,通常我们可以向分布式缓存中写入一个过期时间较短的空值占位,但这样会占用较多的存储空间,性价比不足。
问题的本质是:"如何以极小的代价检索一个元素是否在一个集合中 ?"
我们的主角布隆过滤器 出场了,它就能游刃有余的平衡好时间和空间两种维度 。
2 原理解析
布隆过滤器 (英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量 和一系列随机映射函数 。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率 和查询时间 都远远超过一般的算法 ,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理:当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0 ,则被检元素一定不在 ;如果都是 1 ,则被检元素很可能在 。
简单来说就是准备一个长度为 m 的位数组并初始化所有元素为 0,用 k 个散列函数对元素进行 k 次散列运算跟 len (m) 取余得到 k 个位置并将 m 中对应位置设置为 1。

如上图,位数组的长度是8,散列函数个数是 3,先后保持两个元素x,y。这两个元素都经过三次哈希函数生成三个哈希值,并映射到位数组的不同的位置,并置为1。元素 x 映射到位数组的第0位,第4位,第7位,元素y映射到数组的位数组的第1位,第4位,第6位。
保存元素 x 后,位数组的第4位被设置为1之后,在处理元素 y 时第4位会被覆盖,同样也会设置为 1。
当布隆过滤器保存的元素越多 ,被置为 1 的 bit 位也会越来越多 ,元素 x 即便没有存储过,假设哈希函数映射到位数组的三个位都被其他值设置为 1 了,对于布隆过滤器的机制来讲,元素 x 这个值也是存在的,也就是说布隆过滤器存在一定的误判率 。
▍ 误判率
布隆过滤器包含如下四个属性:
-
k : 哈希函数个数
-
m : 位数组长度
-
n : 插入的元素个数
-
p : 误判率
若位数组长度太小则会导致所有 bit 位很快都会被置为 1 ,那么检索任意值都会返回”可能存在“ , 起不到过滤的效果。位数组长度越大,则误判率越小。
同时,哈希函数的个数也需要考量,哈希函数的个数越大,检索的速度会越慢,误判率也越小,反之,则误判率越高。
从张图我们可以观察到相同位数组长度的情况下,随着哈希函数的个人的增长,误判率显著的下降。
误判率 p 的公式是
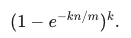
-
k 次哈希函数某一 bit 位未被置为 1 的概率为

-
插入 n 个元素后某一 bit 位依旧为 0 的概率为

-
那么插入 n 个元素后某一 bit 位置为1的概率为

-
整体误判率为
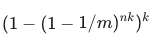
当 m 足够大时,误判率会越小,该公式约等于

我们会预估布隆过滤器的误判率 p 以及待插入的元素个数 n 分别推导出最合适的位数组长度 m 和 哈希函数个数 k。

布隆过滤器支持删除吗
布隆过滤器其实并不支持删除元素,因为多个元素可能哈希到一个布隆过滤器的同一个位置,如果直接删除该位置的元素,则会影响其他元素的判断。
▍ 时间和空间效率
布隆过滤器的空间复杂度为 O(m) ,插入和查询时间复杂度都是 O(k) 。存储空间和插入、查询时间都不会随元素增加而增大。空间、时间效率都很高。
▍哈希函数类型
Murmur3,FNV 系列和 Jenkins 等非密码学哈希函数适合,因为 Murmur3 算法简单,能够平衡好速度和随机分布,很多开源产品经常选用它作为哈希函数。
3 Guava实现
Google Guava是 Google 开发和维护的开源 Java开发库,它包含许多基本的工具类,例如字符串处理、集合、并发工具、I/O和数学函数等等。
1、添加Maven依赖

2、创建布隆过滤器
3、添加数据

4、判断数据是否存在
接下来,我们查看 Guava 源码中布隆过滤器是如何实现的 ?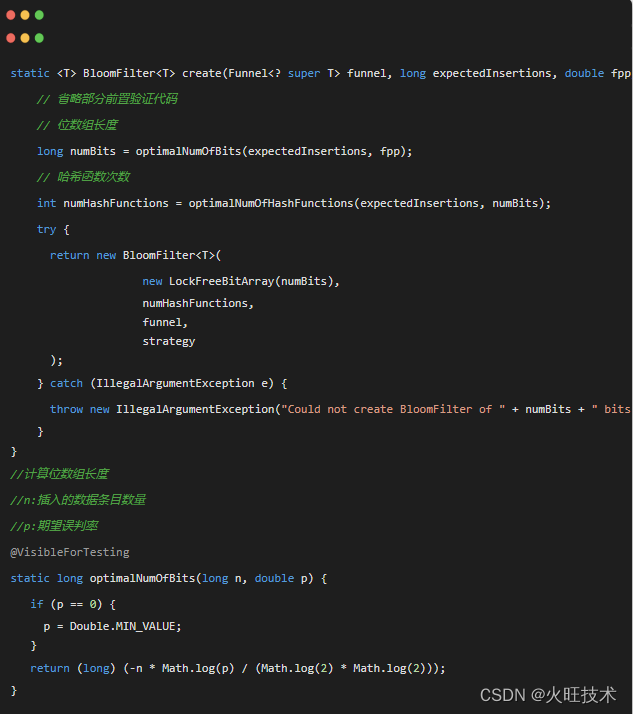
Guava 的计算位数组长度和哈希次数和原理解析这一节展示的公式保持一致。
重点来了,Bloom filter 是如何判断元素存在的 ?
方法名就非常有 google 特色 , ”mightContain “ 的中文表意是:”可能存在“ 。方法的返回值为 true ,元素可能存在,但若返回值为 false ,元素必定不存在。
4 Redisson实现
Redisson 是一个用 Java 编写的 Redis 客户端,它实现了分布式对象和服务,包括集合、映射、锁、队列等。Redisson的API简单易用,使得在分布式环境下使用Redis 更加容易和高效。
1、添加Maven依赖
2、配置 Redisson 客户端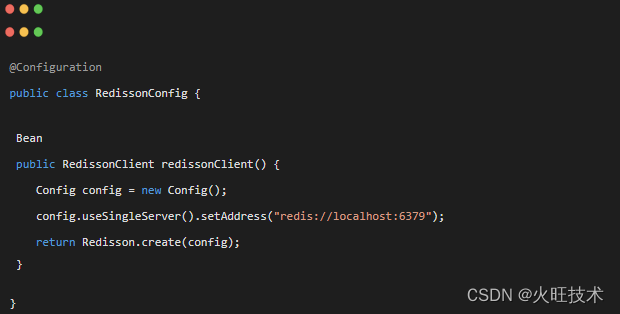
3、初始化 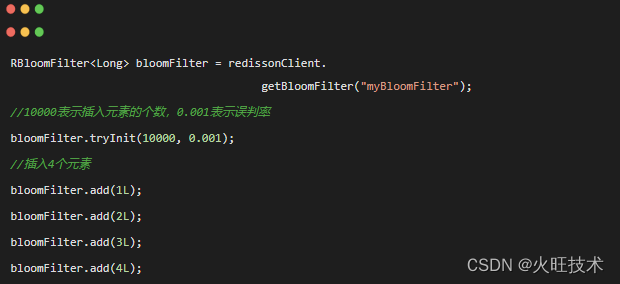
4、判断数据是否存在
好,我们来从源码分析 Redisson 布隆过滤器是如何实现的 ?
Bf配置信息
Redisson 布隆过滤器初始化的时候,会创建一个 Hash 数据结构的 key ,存储布隆过滤器的4个核心属性。
那么 Redisson 布隆过滤器如何保存元素呢 ?
从源码中,我们发现 Redisson 布隆过滤器操作的对象是 位图(bitMap) 。
在 Redis 中,位图本质上是 string 数据类型,Redis 中一个字符串类型的值最多能存储 512 MB 的内容,每个字符串由多个字节组成,每个字节又由 8 个 Bit 位组成。位图结构正是使用“位”来实现存储的,它通过将比特位设置为 0 或 1来达到数据存取的目的,它存储上限为 2^32 ,我们可以使用getbit/setbit命令来处理这个位数组。
为了方便大家理解,我做了一个简单的测试。
通过 Redisson API 创建 key 为 mybitset 的 位图 ,设置索引 3 ,5,6,8 位为 1 ,右侧的二进制值 也完全匹配。
5 实战要点
通过 Guava 和 Redisson 创建和使用布隆过滤器比较简单,我们下面讨论实战层面的注意事项。
1、缓存穿透场景
首先我们需要初始化 布隆过滤器,然后当用户请求时,判断过滤器中是否包含该元素,若不包含该元素,则直接返回不存在。
若包含则从缓存中查询数据,若缓存中也没有,则查询数据库并回写到缓存里,最后给前端返回。

2、元素删除场景
现实场景,元素不仅仅是只有增加,还存在删除元素的场景,比如说商品的删除。
原理解析这一节,我们已经知晓:布隆过滤器其实并不支持删除元素,因为多个元素可能哈希到一个布隆过滤器的同一个位置,如果直接删除该位置的元素,则会影响其他元素的判断 。
我们有两种方案:
▍计数布隆过滤器
计数过滤器(Counting Bloom Filter)是布隆过滤器的扩展,标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。

虽然计数布隆过滤器可以解决布隆过滤器无法删除元素的问题,但是又引入了另一个问题:“更多的资源占用,而且在很多时候会造成极大的空间浪费 ”。
▍ 定时重新构建布隆过滤器
从工程角度来看,定时重新构建布隆过滤器 这个方案可行也可靠,同时也相对简单。
-
定时任务触发全量商品查询 ;
-
将商品编号添加到新的布隆过滤器 ;
-
任务完成,修改商品布隆过滤器的映射(从旧 A 修改成 新 B );
-
商品服务根据布隆过滤器的映射,选择新的布隆过滤器 B进行相关的查询操作 ;
-
选择合适的时间点,删除旧的布隆过滤器 A。
6 总结
布隆过滤器 是一种常用于检索元素是否在集合中的数据结构。它由一个很长的二进制向量和一系列随机映射函数组成。虽然布隆过滤器存在一定的误判率(函数返回 true 表示元素可能存在,返回 false 表示元素必定不存在),但是它的空间效率和查询时间都远远超过一般的算法。而且,我们可以通过计数布隆过滤器和定时重新构建布隆过滤器两种方案来实现删除元素的效果。
布隆过滤器有四个核心属性:
k: 哈希函数个数
m: 位数组长度
n: 插入的元素个数
p: 误判率
在 Java 世界里,使用 Guava 和 Redisson 创建和使用布隆过滤器非常简单。因为布隆过滤器的设计精巧且简洁,工程上实现非常容易,效能高,所以在很多开源项目中被广泛使用。虽然它存在一定的误判率,但这是软件设计中 trade off 的一部分。因此,布隆过滤器是一种非常有用的数据结构,可以在很多应用场景中发挥作用。