模式识别与机器学习(七):集成学习
集成学习
- 1.概念
- 1.1 类型
- 1.2 集成策略
- 1.3 优势
- 2. 代码实例
- 2.1boosting
- 2.2 bagging
- 2.3 集成
1.概念
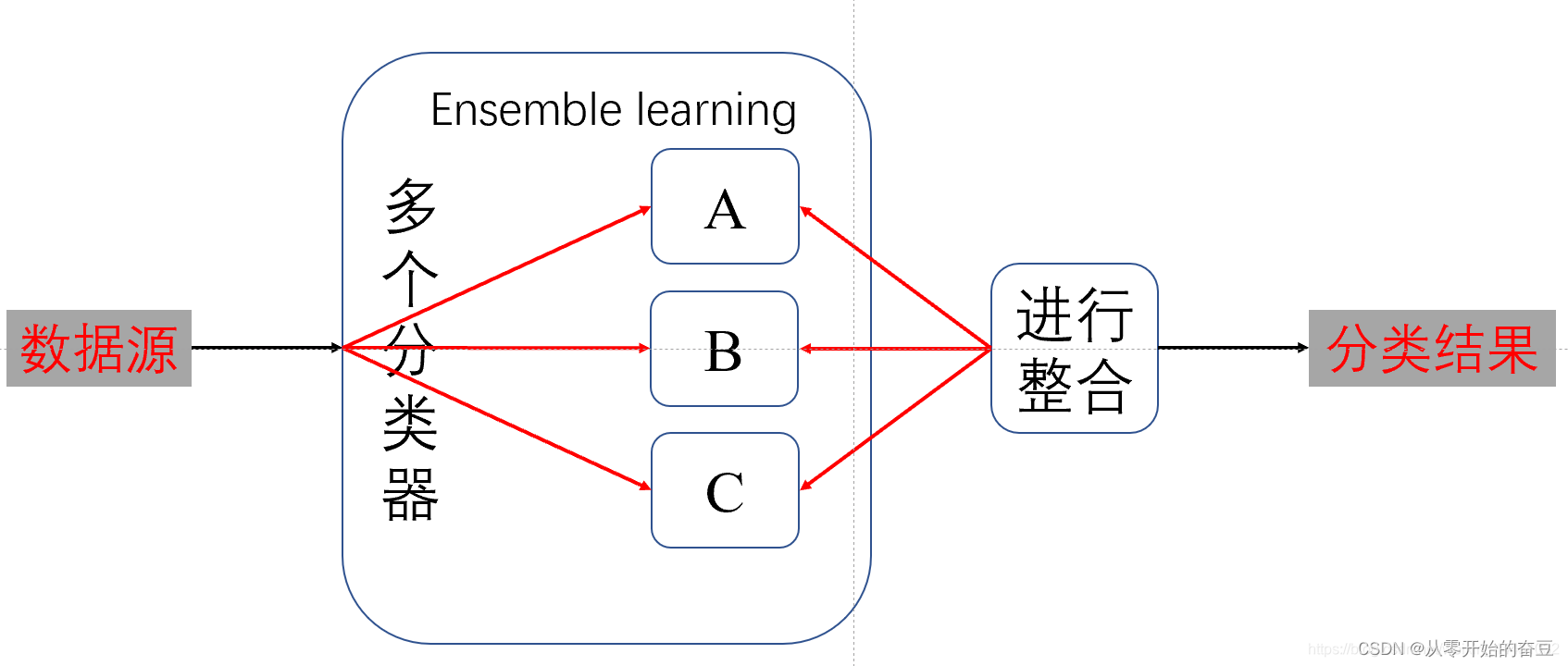
集成学习是一种机器学习方法,旨在通过组合多个个体学习器的预测结果来提高整体的预测性能。它通过将多个弱学习器(个体学习器)组合成一个强学习器,以获得更准确、更稳定的预测结果。
在集成学习中,个体学习器可以是同质的(使用相同的学习算法,但在不同的训练集上训练)或异质的(使用不同的学习算法)。集成学习的核心思想是通过个体学习器之间的合作和协同来提高整体的预测性能。
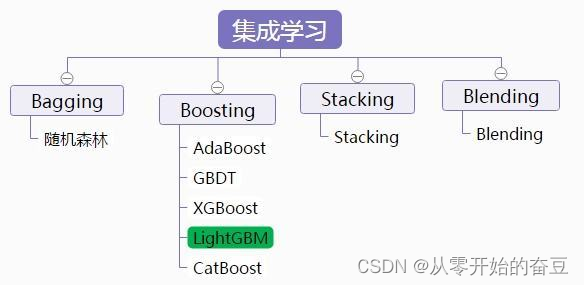
1.1 类型
集成学习可以分为两种主要类型:bagging和boosting。
-
Bagging(自助聚集法):Bagging是一种基于自助采样的集成学习方法。它通过从原始训练集中有放回地随机采样生成多个新的训练集,然后使用这些训练集分别训练多个个体学习器。最后,通过对个体学习器的预测结果进行投票或平均来得到最终的集成预测结果。常见的Bagging方法包括随机森林(Random Forest)。
-
Boosting(提升法):Boosting是一种迭代的集成学习方法。它通过依次训练多个个体学习器,每个个体学习器都试图纠正前一个学习器的错误。在每一轮迭代中,Boosting根据样本的权重调整训练集,使得前一个学习器预测错误的样本在后续的训练中得到更多的关注。最终,通过对个体学习器的加权组合来得到最终的集成预测结果。常见的Boosting方法包括AdaBoost、Gradient Boosting和XGBoost。
1.2 集成策略
集成策略是集成方法中用于合并个体学习器预测结果的策略。它决定了如何将个体学习器的预测结果组合起来得到最终的集成预测结果。下面是一些常见的集成策略:
-
投票(Voting):对于分类问题,投票是一种常见的集成策略。每个个体学习器对样本进行预测后,最终的预测结果是通过多数投票来决定的。例如,如果有5个个体学习器,其中3个预测为类别A,2个预测为类别B,则最终的预测结果为类别A。
-
平均(Averaging):对于回归问题,平均是一种常见的集成策略。每个个体学习器对样本进行预测后,最终的预测结果是通过对个体学习器的预测结果进行平均得到的。例如,如果有5个个体学习器,它们的预测结果分别为[1.2, 1.5, 1.3, 1.4, 1.6],则最终的预测结果为平均值1.4。
-
加权平均(Weighted Averaging):加权平均是一种对平均策略的扩展,它给不同的个体学习器赋予不同的权重。权重可以根据个体学习器的性能或其他因素进行分配。例如,性能较好的个体学习器可以被赋予更高的权重,从而在集成预测中起到更大的作用。
-
堆叠(Stacking):堆叠是一种更高级的集成策略,它通过训练一个元学习器来组合多个个体学习器的预测结果。在堆叠中,首先将训练集分成多个子集,每个子集用于训练不同的个体学习器。然后,使用这些个体学习器对测试集进行预测,并将它们的预测结果作为新的特征输入到元学习器中进行训练和预测。
这些集成策略可以根据具体的问题和需求进行选择和组合。不同的集成策略适用于不同的情况,可以根据个体学习器的性能、数据集的特点和任务的要求来选择最合适的集成策略。
1.3 优势
集成学习的优势在于它能够通过组合多个个体学习器的优势来弥补单个学习器的缺点,从而提高整体的泛化能力和鲁棒性。它在许多机器学习任务中都取得了很好的效果,并成为了一种常用的技术。
2. 代码实例
2.1boosting
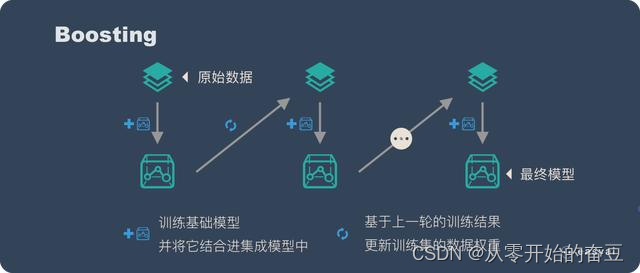
Boosting是一种集成学习方法,通过迭代训练一系列基本学习器,每个基本学习器都会根据前一个学习器的表现进行调整,以提高整体性能。下面是Boosting的详细介绍:
-
基本概念:Boosting的核心思想是将多个弱学习器组合成一个强学习器。弱学习器是指在某个学习任务上表现略好于随机猜测的学习器,而强学习器则是在该任务上表现较好的学习器。
-
迭代过程:Boosting通过迭代的方式生成一系列基本学习器。每个基本学习器都会根据前一个学习器的表现进行调整,使得前一个学习器在错误样本上的权重增加,从而更加关注错误样本,提高整体性能。
-
加权投票:在预测阶段,Boosting会对每个基本学习器进行加权投票,将各个学习器的预测结果进行加权组合,得到最终的预测结果。通常,表现较好的学习器会被赋予更高的权重。
-
AdaBoost算法:AdaBoost是Boosting的一种经典算法。它通过调整样本的权重来训练基本学习器,每个基本学习器的权重由前一个学习器的错误率决定。AdaBoost在每一轮迭代中,都会调整样本的权重,使得前一个学习器错误分类的样本权重增加,从而使得后续学习器更加关注这些错误样本。
-
Gradient Boosting算法:Gradient Boosting是另一种常用的Boosting算法。它通过梯度下降的方式训练基本学习器,每个基本学习器都会拟合前一个学习器的残差。Gradient Boosting在每一轮迭代中,都会计算残差,并将残差作为新的目标进行训练。
Boosting是一种强大的集成学习方法,能够有效提高模型的性能。它在实际应用中广泛使用,如梯度提升树(Gradient Boosting Trees)和XGBoost等。
以下是一个使用Python中的scikit-learn库实现AdaBoost算法的简单代码示例:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成一个示例数据集
X, y = make_classification(n_samples=100, n_features=10, random_state=42)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建AdaBoost分类器
clf = AdaBoostClassifier(n_estimators=50, random_state=42)
# 在训练集上拟合分类器
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
在这个示例中,我们首先使用make_classification函数生成一个包含100个样本和10个特征的示例数据集。然后,我们将数据集拆分为训练集和测试集。接下来,我们创建一个AdaBoost分类器,并使用训练集对其进行拟合。最后,我们使用测试集进行预测,并计算预测准确率。
2.2 bagging
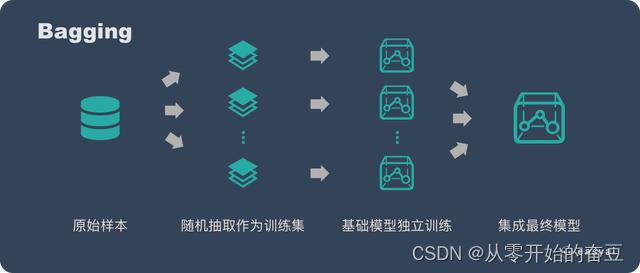
Bagging(Bootstrap Aggregating)是一种集成学习方法,通过随机有放回抽样生成多个训练集,每个训练集用于训练一个基本学习器,最后通过投票或平均来进行预测。下面是Bagging的详细介绍:
-
基本概念:Bagging的核心思想是通过构建多个基本学习器的集合来提高整体性能。每个基本学习器都是在不同的训练集上独立训练得到的,最后通过集成基本学习器的预测结果来进行最终的预测。
-
Bootstrap抽样:Bagging使用Bootstrap抽样技术生成多个训练集。Bootstrap抽样是一种有放回的抽样方法,从原始训练集中随机抽取样本,生成与原始训练集大小相同的新训练集。由于有放回抽样,新训练集中可能包含重复的样本,也可能有部分样本未被抽到。
-
基本学习器:每个训练集用于训练一个基本学习器。基本学习器可以是同一种学习算法的不同实例,也可以是不同的学习算法。通过在不同的训练集上独立训练基本学习器,可以获得多个学习器的集合。
-
集成预测:在预测阶段,Bagging通过对基本学习器的预测结果进行投票(分类问题)或平均(回归问题)来得到最终的预测结果。对于分类问题,可以采用多数投票的方式,选择预测结果最多的类别作为最终预测结果。
-
随机森林(Random Forest):随机森林是一种基于Bagging和决策树的集成学习方法。它通过随机选择特征子集和样本子集来构建多个决策树,并通过投票来进行预测。随机森林在每个决策树的训练过程中,都会使用随机选择的特征子集,以增加模型的多样性。
Bagging是一种简单而有效的集成学习方法,能够减少模型的方差,提高模型的稳定性和泛化能力。它在实际应用中广泛使用,如随机森林和Bagging分类器等。
以下是一个使用Python中的scikit-learn库实现Bagging算法的简单代码示例:
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
# 生成一个示例数据集
X, y = make_classification(n_samples=100, n_features=10, random_state=42)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建基本学习器(决策树)
base_estimator = DecisionTreeClassifier()
# 创建Bagging分类器
clf = BaggingClassifier(base_estimator=base_estimator, n_estimators=50, random_state=42)
# 在训练集上拟合分类器
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
在这个示例中,我们首先使用make_classification函数生成一个包含100个样本和10个特征的示例数据集。然后,我们将数据集拆分为训练集和测试集。接下来,我们创建一个基本学习器(这里使用决策树),并使用基本学习器创建一个Bagging分类器。最后,我们使用训练集对Bagging分类器进行拟合,并使用测试集进行预测,计算预测准确率。
2.3 集成
这是一个使用投票策略的集成分类器的示例代码。以下是一个使用Python编写的示例:
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义三个不同的分类器
clf1 = DecisionTreeClassifier(random_state=42)
clf2 = KNeighborsClassifier()
clf3 = SVC(probability=True)
# 定义投票分类器
voting_clf = VotingClassifier(estimators=[('dt', clf1), ('knn', clf2), ('svc', clf3)], voting='hard')
# 训练投票分类器
voting_clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = voting_clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们使用了三个不同的分类器(决策树、K近邻和支持向量机)来构建一个投票分类器。通过VotingClassifier类,我们将这三个分类器组合在一起,并使用voting='hard'来指定使用硬投票策略。然后,我们使用训练集对投票分类器进行训练,并在测试集上进行预测。最后,我们使用accuracy_score函数计算预测结果的准确率。