Spark RDD惰性计算的自主优化

原创/朱季谦
RDD(弹性分布式数据集)中的数据就如final定义一般,只可读而无法修改,若要对RDD进行转换或操作,那就需要创建一个新的RDD来保存结果。故而就需要用到转换和行动的算子。
Spark运行是惰性的,在RDD转换阶段,只会记录该转换逻辑而不会执行,只有在遇到行动算子时,才会触发真正的运算,若整个生命周期都没有行动算子,那么RDD的转换代码便不会运行。
这样的惰性计算,其实是有好处的,它在遇到行动算子需要对整个DAG(有向无环图)做优化,以下是一些优化说明——
本文的样本部分内容如下,可以基于这些数据做验证——
Amy Harris,39,男,18561,性价比,家居用品,天猫,微信支付,10,折扣优惠,品牌忠诚
Lori Willis,33,女,14071,功能性,家居用品,苏宁易购,货到付款,1,折扣优惠,日常使用
Jim Williams,61,男,14145,时尚潮流,汽车配件,淘宝,微信支付,3,免费赠品,礼物赠送
Anthony Perez,19,女,11587,时尚潮流,珠宝首饰,拼多多,支付宝,5,免费赠品,商品推荐
Allison Carroll,28,男,18292,环保可持续,美妆护肤,唯品会,信用卡,8,免费赠品,日常使用
Robert Rice,47,男,5347,时尚潮流,图书音像,拼多多,微信支付,8,有优惠券,兴趣爱好
Jason Bradley,25,男,9480,性价比,汽车配件,拼多多,信用卡,5,折扣优惠,促销打折
Joel Small,18,女,15586,社交影响,食品饮料,亚马逊,支付宝,5,无优惠券,日常使用
Stephanie Austin,33,男,7653,舒适度,汽车配件,亚马逊,银联支付,3,无优惠券,跟风购买
Kathy Myers,33,男,18159,舒适度,美妆护肤,亚马逊,货到付款,4,无优惠券,商品推荐
Gabrielle Mccarty,57,男,19561,环保可持续,母婴用品,网易考拉,支付宝,5,免费赠品,日常使用
Joan Smith,43,女,11896,品牌追求,图书音像,亚马逊,支付宝,4,免费赠品,商品推荐
Monica Garcia,19,男,16665,时尚潮流,电子产品,京东,货到付款,7,免费赠品,商品推荐
Christopher Faulkner,55,男,3621,社交影响,美妆护肤,苏宁易购,支付宝,7,无优惠券,日常使用
一、减少不必要的计算
RDD的惰性计算可以通过优化执行计划去避免不必要的计算,同时可以将过滤操作下推到数据源或者其他转换操作之前,减少需要处理的数据量,进而达到计算的优化。
例如,执行以下这段spark代码时,
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("count")
val ss = SparkSession.builder().config(conf).getOrCreate()
val filePath: String = "transaction_data.csv"
val lineRDD = ss.sparkContext.textFile(filePath)
val value = lineRDD.map { x => {
println(s"打印 $x")
x.split(",")
} }
value.take(10).foreach(println)
ss.stop()
}
若Spark不是惰性计算的情况下,代码顺序运行到这行 val lineRDD = ss.sparkContext.textFile(filePath)代码时,就会将transaction_data.csv文件里的几万条数据全部加载出来,然后再做计算。
而在惰性计算的情况下,直至运行这行代码 value.take(10).foreach(println)而遇到foreach这个行动算子时,才会去执行前面的转换,这时它会基于RDD的转化自行做一个优化——在这个例子里,它会基于lineRDD.take(5)这行代码只会从transaction_data.csv取出前5行,避免了将文件里的几万条数据全部取出。
打印结果如下,发现lineRDD.map确实只处理了前5条数据——
打印 Amy Harris,39,男,18561,性价比,家居用品,天猫,微信支付,10,折扣优惠,品牌忠诚
打印 Lori Willis,33,女,14071,功能性,家居用品,苏宁易购,货到付款,1,折扣优惠,日常使用
打印 Jim Williams,61,男,14145,时尚潮流,汽车配件,淘宝,微信支付,3,免费赠品,礼物赠送
打印 Anthony Perez,19,女,11587,时尚潮流,珠宝首饰,拼多多,支付宝,5,免费赠品,商品推荐
打印 Allison Carroll,28,男,18292,环保可持续,美妆护肤,唯品会,信用卡,8,免费赠品,日常使用
[Ljava.lang.String;@3c87e6b7
[Ljava.lang.String;@77bbadc
[Ljava.lang.String;@3c3a0032
[Ljava.lang.String;@7ceb4478
[Ljava.lang.String;@7fdab70c
二、操作合并和优化
Spark在执行行动算子时,会自动将存在连续转换的RDD操作合并到更为高效的执行计划,这样可以减少中间不是必要的RDD数据的生成和传输,可以整体提高计算的效率。这很像是,摆在你面前是一条弯弯曲曲的道路,但是因为你手里有地图,知道这条路是怎么走的,因此,可以基于这样的地图,去尝试发掘下是否有更好的直径。
还是以一个代码案例说明,假如需要统计薪资在10000以上的人数。
运行的代码,是从transaction_data.csv读取了几万条数据,然后将每行数据按","分割成数组,再基于每个数组去过滤出满足薪资大于10000的数据,最后再做count统计出满足条件的人数。
以下是最冗余的代码,每个步骤都转换生成一个新的RDD,彼此之间是连续的,这些RDD是会占内存空间,同时增加了很多不必要的计算。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("count")
val ss = SparkSession.builder().config(conf).getOrCreate()
val filePath: String = "transaction_data.csv"
val lineRDD = ss.sparkContext.textFile(filePath)
val array = lineRDD.map(_.split(","))
//过滤出薪资10000的数据
val valueRdd = array.filter(x => x.apply(3).toInt > 10000)
//统计薪资10000以上的人数
val count = valueRdd.count()
ss.stop()
}
Spark就可能会将这些存在连续的RDD进行优化,将其合并成一个单独的转换操作,直接就对原始RDD进行映射和过滤——
val value = ss.sparkContext.textFile(filePath).map(_.split(",")).filter(x =>{x.apply(3).toInt > 10000})
value.count()
这样优化同时避免了多次循环遍历,每个映射的数组只需要遍历一次即可。
可以通过coalesce(1)只设置一个分区,使代码串行运行,然后增加打印验证一下效果——
val value = ss.sparkContext.textFile(filePath).coalesce(1).map(x =>{
println(s"分割打印 $x")
x.split(",")
}).filter(x =>
{
println(s"过滤打印 ${x.apply(0)}")
x.apply(3).toInt > 10000
}
)
value.count()
打印部分结果,发现没每遍历一次,就把映射数组和过滤都完成了,没有像先前多个RDD那样需要每次都得遍历,这样就能达到一定优化效果——
分割打印 Amy Harris,39,男,18561,性价比,家居用品,天猫,微信支付,10,折扣优惠,品牌忠诚
过滤打印 Amy Harris
分割打印 Lori Willis,33,女,14071,功能性,家居用品,苏宁易购,货到付款,1,折扣优惠,日常使用
过滤打印 Lori Willis
分割打印 Jim Williams,61,男,14145,时尚潮流,汽车配件,淘宝,微信支付,3,免费赠品,礼物赠送
过滤打印 Jim Williams
分割打印 Anthony Perez,19,女,11587,时尚潮流,珠宝首饰,拼多多,支付宝,5,免费赠品,商品推荐
过滤打印 Anthony Perez
分割打印 Allison Carroll,28,男,18292,环保可持续,美妆护肤,唯品会,信用卡,8,免费赠品,日常使用
过滤打印 Allison Carroll
分割打印 Robert Rice,47,男,5347,时尚潮流,图书音像,拼多多,微信支付,8,有优惠券,兴趣爱好
过滤打印 Robert Rice
这样也提醒了我们,在遇到连续转换的RDD时,其实可以自行做代码优化,避免产生中间可优化的RDD和遍历操作。
三、窄依赖优化
RDD在执行惰性计算时,会尽可能进行窄依赖优化。
有窄依赖,便会有宽依赖,两者有什么区别呢?
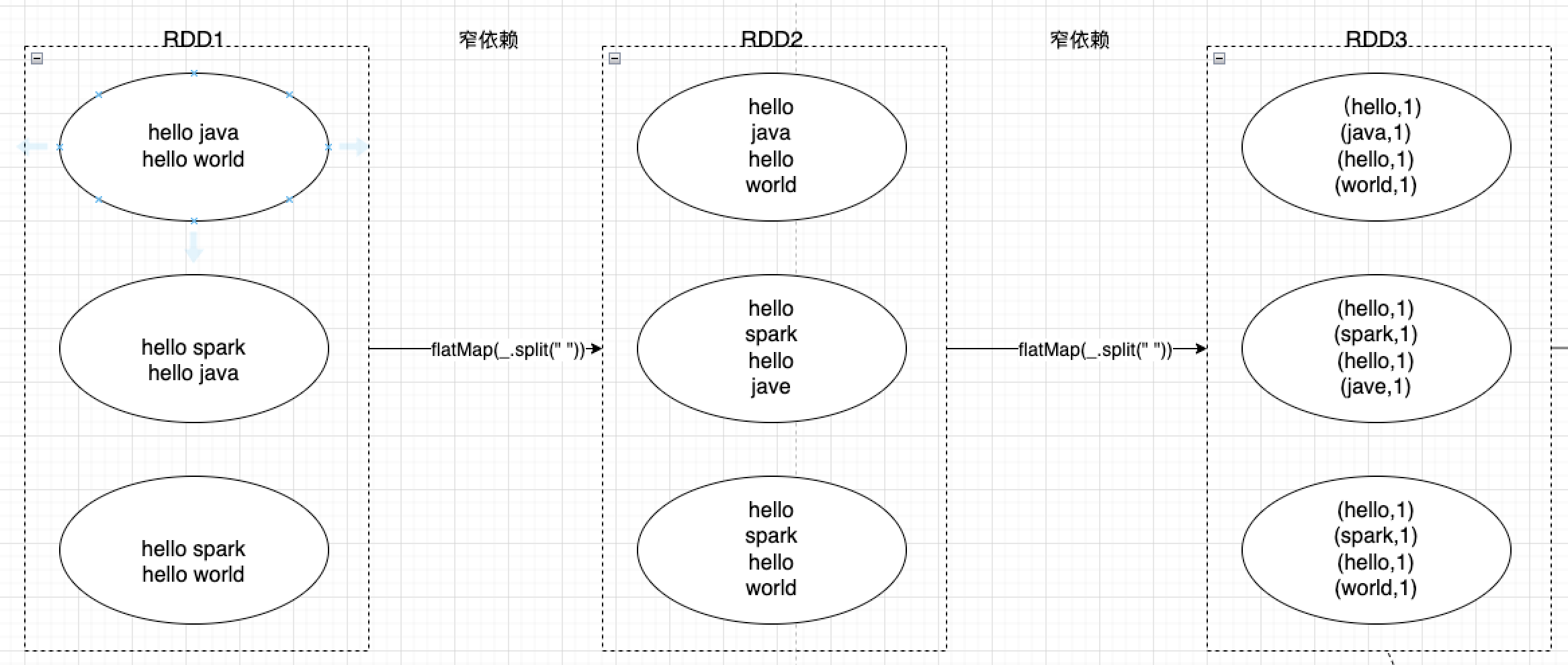
窄依赖指的是父RDD的每个分区只需要通过简单的转换操作就可以计算出对应的子RDD分区,不涉及跨多个分区的数据交换,即父子之间每个分区都是一对一的。
前文提到的map、filter等转换都属于窄依赖的操作。
例如,array.filter(x => x.apply(3).toInt > 10000),父RDD有三个分区,那么三个分区就会分别执行array.filter(x => x.apply(3).toInt > 10000)将过滤的数据传给子RDD对应的分区——
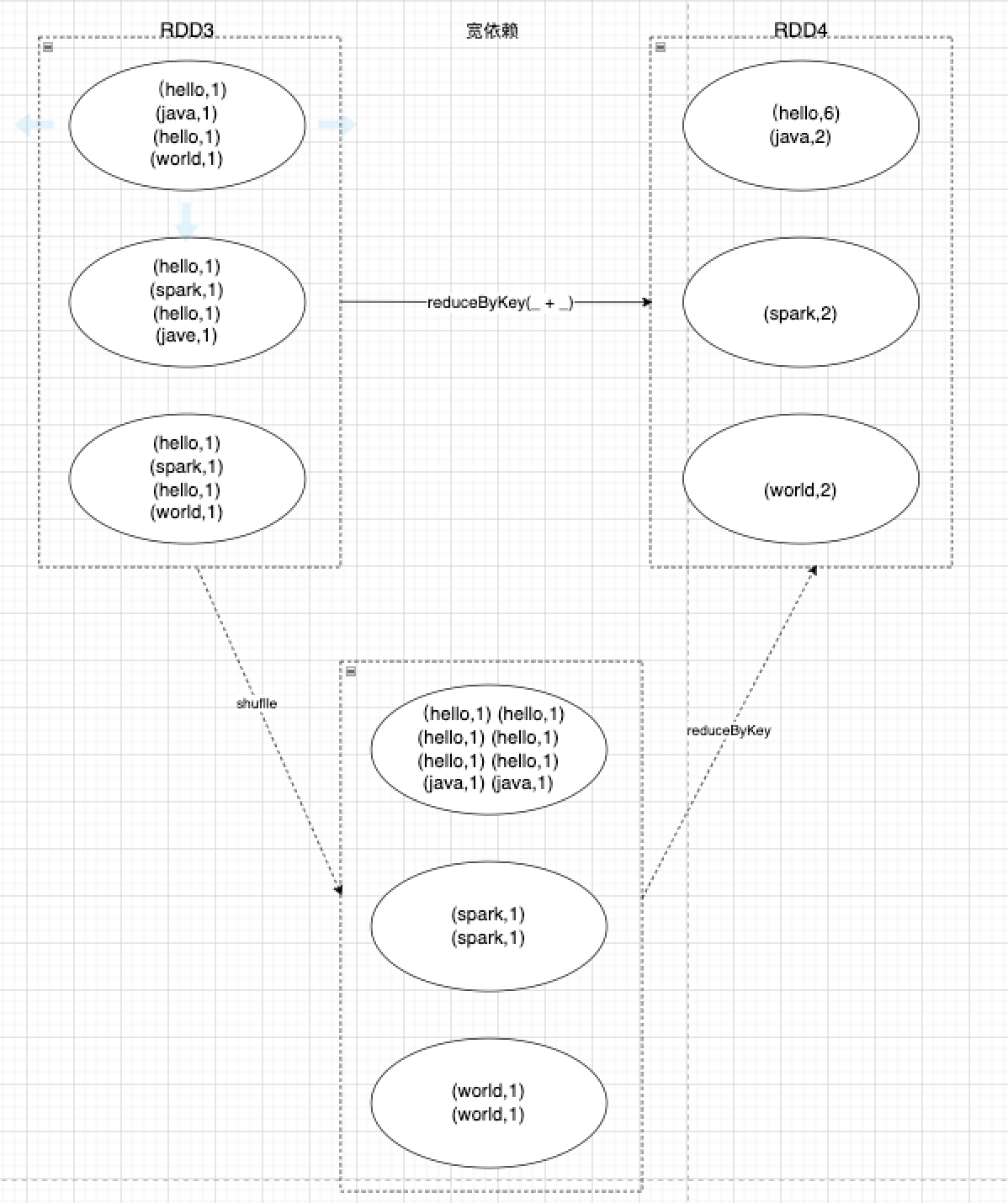
宽依赖指父RDD的每个分区会通过跨区计算将原本同一个分区数据分发到不同子分区上,这中间涉及到shuffle重新洗牌操作,会存在较大的计算,父子之间分区是一对多的。可以看到,父RDD同一个分区的数据,在宽依赖情况下,会将相同的key传输到同一个分区里,这就意味着,同一个父RDD,如果存在多个不同的key,可能会分发到多个不同的子分区上,进而出现shuffle重新洗牌操作。
因此,RDD会尽可能的进行窄依赖优化,在无需跨区计算的情况下,就避免进行shuffle重新洗牌操作,将父分区一对一地传输给子分区。同时,窄依赖还有一个好处是,在子分区出现丢失数据异常时,只需要重新计算对应的父分区数据即可,无需将父分区全部数据进行计算。