AI算力研究报告:智算供给格局分化国产化进程有望加速
今天分享的AI系列深度研究报告:《AI算力研究报告:智算供给格局分化国产化进程有望加速》。
(报告出品方:华龙证券)
报告共计:24页

1 大模型浪潮推动作用下,其力需求缺口将持续扩大
1.1 大模型发展对算力需求的推动作用
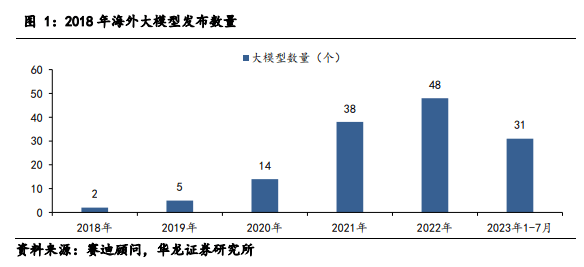
大模型的训练效果、成本和时间与算力资源有密切的关系。大模型发展浪潮有望进一步增加 AI 行业对智算算力的需求规模。大模型数量加速增长,算力成为模型竞赛底座。自2018 年以来,海外云厂商巨头接连发布 NLP 大模型。据赛迪顾问 2023 年 7月发布的数据显示,海外大模型发布数量逐年上升,年发布数量在五年中由 2 个增长至48个。且仅 2023 年1-7 月就发布了31 个大模型。自 2021 年起,海外大模型数量呈现加速增长的趋势,结合 2023 年1-7 月的情况,该趋势有望延续。
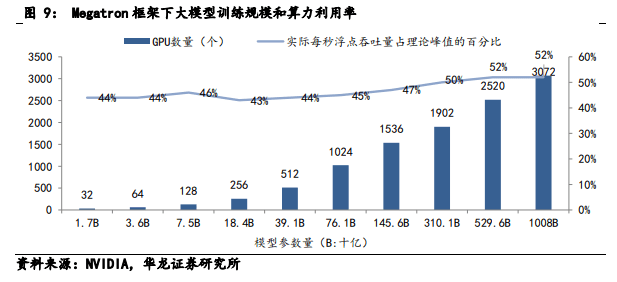
GPU 数量与不同量级大模型所需的算力之间的线 性关系。根据 2021 年 8 月 Deepak Narayanan 等人发布 的论文,随着模型参数增加,大模型训练需要的总浮点 数与 GPU 数量呈现正相关的线性关系。175B 参数量级 的大模型所需的 A100 级别芯片数量为 1024 片(Token 数为 300B,训练 34 天情况下)。当参数增长到 1T 时, 大模型训练所需的 A100 芯片数量为 3072 片(Token 数 为 450B,训练 84 天情况下)。
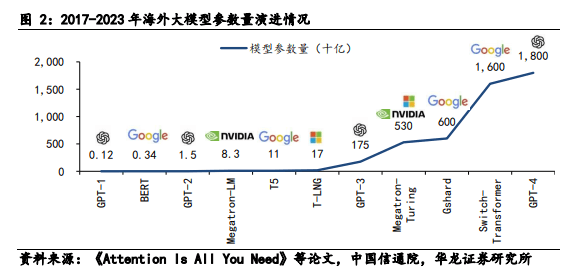
加大成本投入,海外大模型训练周期有望进一步缩短。从 2020 年 6 月 OpenAI 发布首个千亿参数量级大模 型 GPT-3 到 2021 年 1 月谷歌推出首个万亿参数量级的 Switch Transformer 模型,大模型实现参数量级从千亿 到万亿的跨越只用了不到一年。随着海外大厂商加大对 大模型训练的成本投入,预计大模型发布周期将进一步 缩短。在商业逻辑上,大模型发布数量指数型增长,意 味着市场竞争越来越激烈。厂商更愿意通过使用高性能 的芯片缩短大模型训练时间,使大模型更早投入应用为 公司带来业务增长。因此,芯片性能的提高并不会削弱 厂商对芯片数量的需求意愿。
数量增长情况与海外类似,短期内呈现密集发布的特点。自2019年至2023 年7月底,国内累计发布 130个大模型,2023 年 1-7 月国内共有 64 个大模型发布大模型发布数量呈现加速增长趋势。数量增长趋势与海外情况一致,我国大模型研发起步较晚,随着在大模型领域布局的厂商数量快速增加,大模型发布周期逐步编短,预期未来两到三年内国产大模型数量将呈现爆发式增长局面。

巨头引领,千亿级参数规模大模型陆续落地。2023 年 3 月,百度发布文心一言 1.0;同年 4 月,阿里发布 通义千问大模型、商汤科技发布日日新大模型体系;同 年 5 月,科大讯飞发布星火大模型;同年 7 月,华为发 布面向行业的盘古大模型 3.0,千亿级参数规模大模型密集发布。2023 年 10 月,随着百度发布万亿级参数大 模型文心一言 4.0,国产大模型或将具备对标 GPT-4 性 能的能力。
据赛迪顾问于 2023 年 7 月统计的数据显示,我国通用 大模型和行业大模型占比分别为 40%和 60%。行业大 模型分布较多的领域为商业(14 个)、金融(13 个)、 医疗(10 个)、工业(7 个)、教育(6 个)和科研(6 个)。研究显示,通用大模型在行业领域及行业细分场 景的表现一般。但行业模型可以在通用模型的基础上通 过行业数据库进一步训练出来。

大模型应用向细分场景下沉。华为发布的盘古大模 型实际分为 L0(基础大模型)L1(行业大模型)L2(场 景模型)三个层级。采取 5+N+X 模式,即 5 个基础大 模型、N 个行业大模型和 X 个细分场景应用模型。目前 行业模型主要应用于矿山、政务、气象、汽车、医学、 数字人和研发共七大领域,覆盖 14 个细分场景。这种通过基础大模型+行业大模型实现大模型商业化落地的 模式已经逐渐得到验证,未来行业大模型有望带动大模 型本地化部署热潮,在解决行业长尾问题上将发挥更大 优势并成为打通大模型“最后一公里”的桥梁。

1.2 国产大模型 AI 算力需求测算
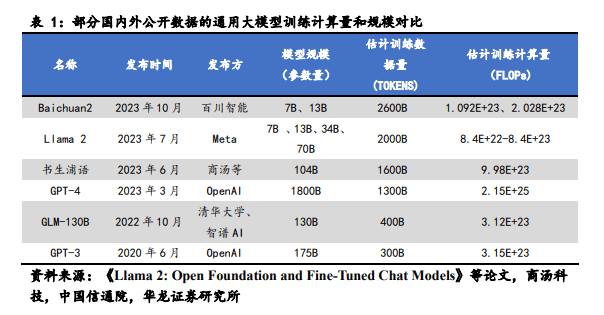
大模型算力需求测算方法:根据 2023 年8 月腾讯公布的大模型算力评估通用方法,在大模型训练过程中,训练侧算力需求可量化表达为:训练所需浮点运算量 (FLOPs) =6X参数量XTraining Tokens;若训练中使用激活重计算技术,则对应算力需求可量化表达为:训练所需浮点运算量 (FLOPs)=8X参数量X;Training Tokens同时,在大模型推理过程中的算力需求可量化表达为:推理侧所需浮点运算量 (FLOPs)=2X参数量X;Prompt Tokens由于激活重计算技术是可选的,因此假设在训练中没有选择使用激活重计算技术,按照以上计算方法可得:训练 GPT-3 量级的大模型算力需求估算为3.15E+23 FLOPs:训练 GPT-4 量级的大模型算力估算为 2.15E+25FLOPs,由于 GPT-4 采用了混合专家(MoE)模型,实际训练调用参数量按约 2770 亿计算。
1.2.1通用大模型AI 算力需求测算
训练侧:2023 年10 月,百度发布文心一言 4.0 大模型。据百度公开的信息,该大模型在综合水平上可以对标GPT-4。
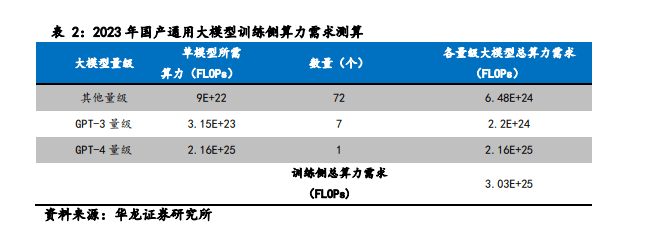
乐观预期下,2023 年内,国内头部互联网厂商中百度能够训练出 GPT-4 量级的大模型。且假设阿里、腾讯、字节跳动、商汤、科大讯飞、浪潮、华为这 7 家厂商能够训练出 GPT-3 量级的大模型。
参考 2023 年上半年国产大模型发布数量情况,预估到 2023 年年底,国内大模型发布数量可达约 200 个年内新增约 134 个,其中通用大模型新增约 80 个。除头部大厂商外,其他厂商和科研机构发布的通用大模型数量估计为 72 个,参数在百亿至千亿之间,保守估计平均参数量级为 500 亿。
由此计算,2023 年年内国产通用大模型训练侧算力需求为 3.03E+25 FLOPs。
1.2.2 行业大模型 AI 算力需求测算
我国垂类大模型主要分布在遥感、生物制药、气象、轨道交通、代码生成/编辑、金融等领域。未来垂类大模型数量有望随着其在各行业细分场景的渗透上升而加速增长。华为已经在算力和软硬件方面,为多个国产重类大模型的训练提供支持。在医疗方面,华为和医渡科技于 2023 年 9 月在华为全联接大会上联合发布医疗垂类领域大模型训推一体机。该一体机由异腾 AI 提供算力支持,内置医渡科技研发的医疗垂类大模型,目标是帮助医院、机构等医疗场所实现大模型私有化。在遥感方面,2022年8月,中科院推出了“空天·灵眸”遥感预训练大模型。该大模型基于华为异腾 AI 澎湃算力和MindSpore 训练而成,有望在中科星图的线下业务中通过 AI 赋能公司的数字化产品。
总结近年来国内大模型商业化落地的过程和效果可以得出,商业化的一般路径为:厂商基于通用大模型训练行业垂类大模型,再通过定制化服务为企业提供所处行业的细分场景 AI 解决方案。从垂类大模型数量上看,截至 2023 年上半年,垂类大模型占国产大模型的 40%,预计 2023 年新增量为54个。

AI 芯片需求——大模型算力需求具象表现。据英 伟达 2023 年 5 月的研究数据所示,训练 GPT-3 的 GPU 数量随着模型规模的增长而增加,同时 GPU 的利用效 率从 44%提升到了 52%,说明 GPU 的利用率存在较大 的限制。因此在大模型算力需求细化到 GPU 数量需求 上时,需考虑 GPU 在模型训练时的实际每秒浮点吞吐 量。按 44.8%的 GPU 利用率来计算(GPT-3 训练用 A100 的实际利用率),A100 在 FP16 精度下的算力约为 140TFLOPS。
芯片性能方面,按摩尔定律所述,芯片算力每 18个月性能会提升一倍。根据 OpenAI 的测算,在深度学习快速发展的 2012年之后,训练大模型的算力需求约每 3.4 个月翻一倍。近年来,从2020年6月GPT-3 发布到2023年3月GPT-4发布,大模型计算量增长约 7倍。未来大模型计算量增速可能受限于成本和硬件效率,因此估计未来两年,即到 2025 年.训练大模型所需的算力需求增速范围约为 5倍到 133 倍。对比摩尔定律中芯片算力的增速,训练大模型带来的算力需求增长速度预估远大于算力性能的增长速度。
1.3 AI算力供给方面:高端芯片进口受限,国产替代为大势所趋
1.3.1国际形势:美国进一步收紧芯片对华出口标准
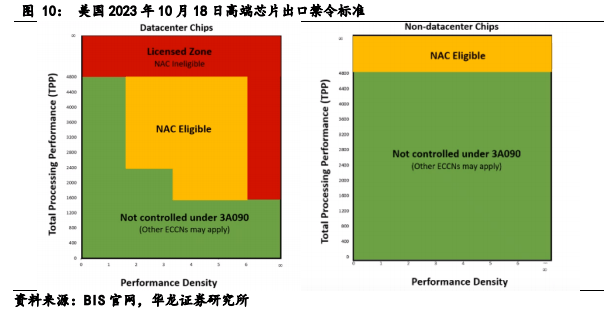
2023 年10 月18 日,美国发布新禁令提出对高端芯片出口限制标准,从原来对单芯片算力(TTP)的关注向“性能密度阙值”(PD)转移,首次提出对小型高性能芯片的出口限制。意在防范 Chiplet 技术对芯片性能利用率的提升效果。
1.3.2 AI 芯片国产化替代
国产 AI 芯片短期看好华为,长期关注各厂商研发进度。按本次美国禁售芯片的性能标准,市面上主流国产芯片中只有少数能够对标美国禁售的 A100/A800 等芯片。国产芯片替代化道路还处于起步阶段,距离在大模型训练中大规模使用仍有一段距离。一方面,在芯片IP 设计之后,厂商需要根据芯片在大规模生态中应用的实际效果对算子做出调整,不断做出优化以使芯片达到实际应用级别。另一方面,在芯片量产的过程中还需考虑芯片代工厂商的制造工艺、交货周期和定价等等。目前华为发布的异腾910与英伟达A100/A800性能较为接近,且经过大模型自用和调整,已经具备了大规模商业化应用的条件。截至 2023 年 5 月,基于异腾算力的华为异腾 AI基础软硬件平台已孵化和适配了30 多个主流大模型。随着更多国内厂商宣布进入芯片自研领域和发布自研芯片,如百度、腾讯等,未来将持续看好国产芯片领域。

1.3.3 Al 芯片产能:台积电产能复苏伴随订单激增供不应求情况仍将持续
短期内台积电的芯片制造工艺难有替代。目前台积电依靠 2.5D、3D 等适用于高端芯片的先进封装技术,在芯片制造行业仍然处于垄断地位。其他代工厂商,如三星、格芯等,所占市场份额较少。为提高良率、降低成本、提高芯片制造的精度,目前各芯片 IP 厂商在芯片量产环节广泛依赖台积电。
台积电产能复苏,同时英伟达等大客户订单激增。2023 年10 月,台积电的产能利用率释放回暖信号,目前 7/6nm 产线利用率从 40%恢复到 60%,到年底预估可以达到 70%。另外,5/4nm 产线利用率为 75-80%。预计台积电明年的 CoWoS (即 2.5D、3D 封装技术) 月产能将同比增长 120%。
与此同时,国外大厂商也在大量追加订单。在英伟达 10 月份确定扩大下单后,苹果、超威、博通、迈威尔等重量级客户近期也开始向台积电追单。加上国内四大厂商到 2024 年共计 50 亿美元的芯片订单,台积电大客户订单量全面激增。虽然在台积电在明年计划将 7nm以下芯片代工定价提高 3-6%,但英伟达、微软等大客户对定价接受度比较高,侧面表现出大厂商对台积电代工的依赖程度比较大。因此短期内订单量仍有保持增速的趋势,且考虑到台积电出货周期拉长以及产能恢复周期的情况,短期内可能出现大量订单积压的现象。
2 AI 算力租赁行业的内在价值
2.1 AI 算力租赁对下游公司:带来成本和时间优势
对下游公司来说,在大模型训练方面,自建算力成本过高,且自建算力对设备的运维能力要求很高。这就意味着自建算力的公司除了支付购买硬件设备的高额成本之外还需要支付运维成本,组建运维团队以及付出额外的时间成本。目前市场上购买硬件设备及安装调试的时间过长 (1-2 年),过长的设备等待时间会导致大模型训练速度和数量落后于行业整体水平。另一方面,能够通过自建算力形成规模效应的大厂商较少,小型厂 商既有算力需求又难以通过自建算力的方式形成规模 效应。这类小型厂商的算力需求使拥有算力资源的公司 从业务中分化出算力租赁这一新的业务模式。
2.2 对具备算力资源的公司:算力租赁可为公司带来第二业务增长线
2.2.1 AI算力租赁成本回收周期测算
算力租赁业务模式近年来在国外头部云厂商中已经得到验证。国内具备 AI 算力资源的公司可以分为三类。一类是传统云计算服务提供商,如三大运营商、阿里、腾讯等。一类是具备 IDC 建设运营能力的企业,如云赛智能、中科曙光 (海光信息) 、中贝通信等。以及跨界厂商,如恒润股份、莲花健康等。
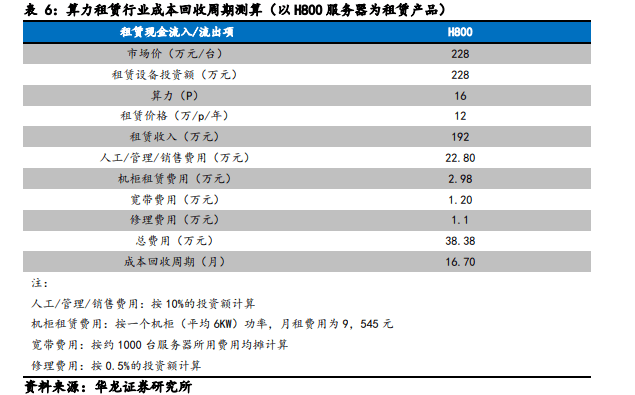
国内算力租赁目前的定价方式分为两种,一种按单台设备定价、一种按每P算力定价。国内市场上用于算力租赁的服务器主要有A100/A800/H800 等型号。本报告中以英伟达 H800 服务器 (8 卡) 为例测算短期算力租赁成本回收周期。
按恒润股份披露的采购公告,英伟达 H800 服务器的采购价格为 228 万元每台。每台服务器搭载8块 GPU算力约为 16P。按鸿博股份 2023 年披露数据显示,该公司H系列服务器刊例价格为 29.9 万1月/台,与其他同行业同类型服务的租金基本持平,或价差浮动不超过 5%。参考阿里云年租定价折扣 (年租约 5 折),同时考虑到租金浮动因素,因此市场面上的租赁均价按 12 万元/P/年计算。
则当前以 H800 服务器作为租赁产品的厂商成本回收周期约为 17 个月。实际上,中贝通信算力租赁价格已有上涨趋势。2023 年 11 月,汇纳科技也释放出大幅提价信号,拟将 A100 服务器的算力服务价格提高 100%预期国内厂商未来的算力租赁定价受强需求影响将有普遍上涨的趋势,整体算力租赁成本回收周期将进一步缩短。
3 AI 算力未来发展方向一一增质提效
3.1 以云网融合为前提,算力调度成为提高资源配置效率的核心
算力资源紧缺使算力供给加速进入到共享时代。对有算力需求的公司,租用云端算力可以大幅度降低硬件成本,提高对成本的控制能力。另一方面,算力上云也为算力调度奠定了基础。有效的算力调度能够使算力资源能够得到精准管理,分时复用,从而解决算力闲置问题。近两年,我国已着力在算力资源调度方面布局。2022年2月,我国“东数西算”工程正式启动,旨在通过构建数据中心、云计算、大数据一体化的新型算力网络体系,解决东西部算力供需不匹配的问题。2023 年 6 月全国一体化算力算网调度平台发布,该平台是我国首个实现多元异构算力调度的全国性平台,有望成为“东数西算”项目的有力助益。国内多家上市公司,如中兴通信、浪潮信息、中科曙光、商汤科技、思特奇等以不同的形式参与了该平台的建设。
3.2 芯片数据传输效率:关注 Chiplet 技术和芯片互联技术
3.2.1 Chiplet 技术
芯片性能提升存在物理极限,摩尔定律或将失效。摩尔定律的核心内容为: 集成电路上可以容纳的晶体管数目在大约每经过 18 个月到 24 个月便会增加一倍。换言之,处理器的性能大约每两年翻一倍,同时价格下降为之前的一半。但单集成电路的面积存在物理极限,不能无限容纳品体管。近年来,摩尔定律中所预言的增速已经明显减慢。随着单芯片面积的缩小,芯片制造的难度和成本也大大提高。根据 AMD 在 IEDM 会议上的资料,若将生产 250 平方毫米的 45nm 芯片的生产成本定为基准 1,14/16nm 芯片的成本将达到 2,而生产7nm 芯片的成本更将翻倍达到 4。
在此情况下,Chiplet 技术有望降低芯片成本增速也能够在突破单芯物理极限方面持续发挥作用。Chiplet 技术是指通过把不同芯片的能力模块化,利用新的设计、互连接口、封装等技术,在一个封装的产品中使用来自不同技术、不同制程甚至不同工厂的芯片。其优势在于通过缩小单个计算芯粒的面积,提高良率、降低成本、提高算力性能,也可满足定制化需求。

3.2.2芯片互联技术
芯片互联技术是 Chiplet 技术得以存续和发展的底层技术之一。2022年3月3日,英特尔、AMD、Arm、高通、台积电、三星、日月光、Google 云、Meta、微软等十大行业巨头联合成立了 Chiplet 标准联盟,正式推出了通用 Chiplet 高速互联标准“Universal ChipletInterconnect Express”(通用芯粒互连,简称“UCle”)UCle 是 PCle 的扩展,不但支持 PCle、CXL,还支持用户定制的 Raw Mode。国内厂商中,芯片 IP 厂商芯原股份、封测厂商长电科技也加入了 UCle 产业联盟。总体来说,建立广泛兼容的芯片互联标准,有利于形成良好的上下游生态,提高 Chiplet 的应用范围和技术提升的底层基础。
报告共计:24页