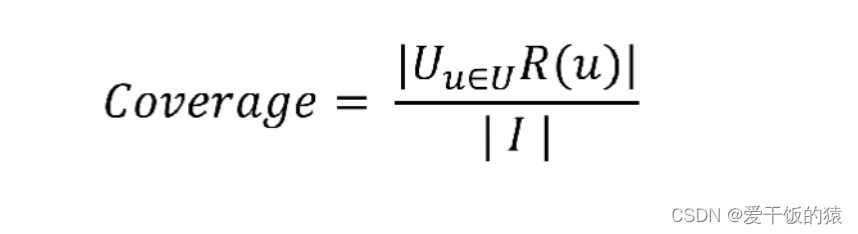【推荐系统】了解推荐系统的生态(重点:推荐算法的主要分类)
【大家好,我是爱干饭的猿,本文重点介绍推荐系统的关键元素和思维模式、推荐算法的主要分类、推荐系统常见的问题、推荐系统效果评测。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【SparkSQL】SparkSQL的运行流程 & Spark On Hive & 分布式SQL执行引擎》
1. 了解推荐系统的生态
本章带你了解推荐系统的生态,让你从思维上重塑对推荐系统的认知。了解推荐系统是由哪些关键元素支撑的,推荐算法的分类以及什么才算一个好的推荐系统。
1.1 推荐系统的关键元素和思维模式
推荐系统是一个系统工程
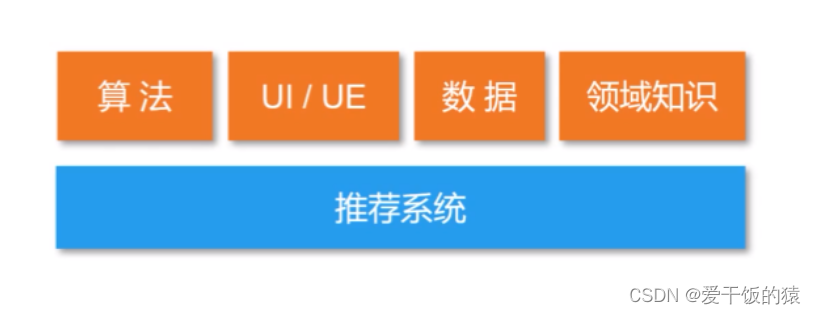
1. 推荐系统的关键元素-数据
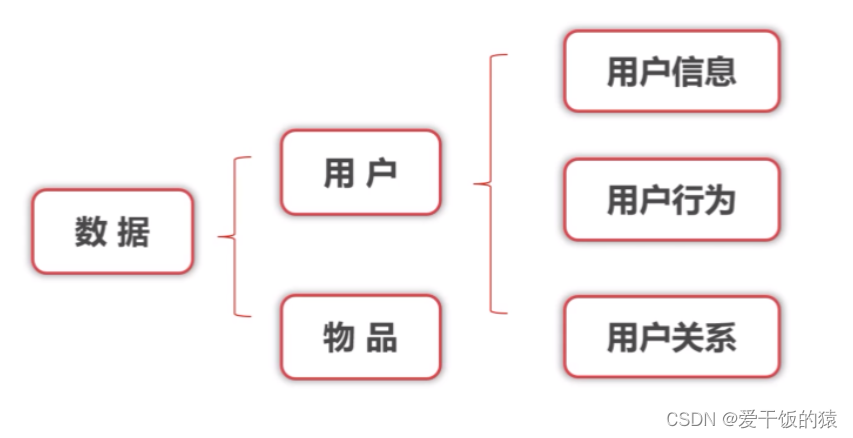
- 数据是整个推荐系统的基石 - 清洗和预处理
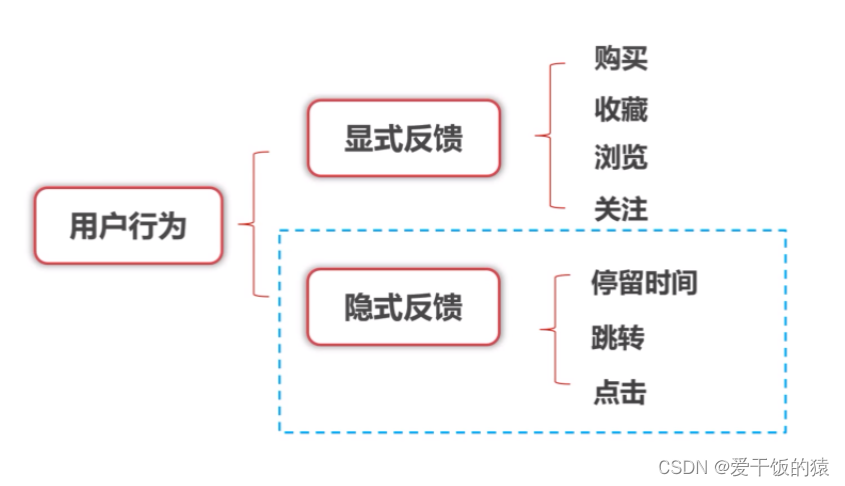
- 用户行为能真实的反映每个用户的偏好和习惯
- 显式反馈数据会比较稀疏,隐式反馈数据蕴含大量的信息
2. 推荐系统的关键元素-算法
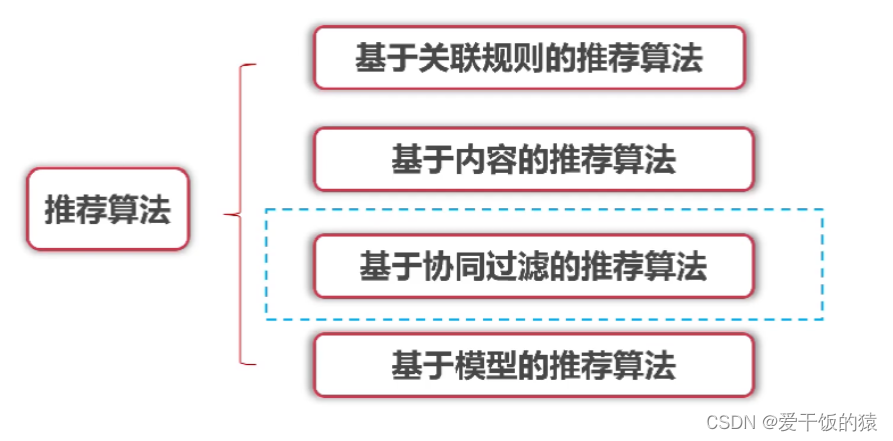
- 基于流行度的推荐算法 - 根据PVUV进行推荐,无个性推荐
- 基于协同过滤的推荐算法
- 基于内容的推荐算法 - 标签、特征向量
- 基于模型的推荐算法 - 解决协同过滤算法的数据稀疏性的问题
- 混合算法
3. 推荐系统的关键元素-领域知识
- 不同领域,不同行业有自己的知识体系和评价准则
- 泛化的推荐无法满足具体领域中特定的用户需求
- 结合领域知识定制推荐系统
4. 推荐系统的关键元素-UI
- 推荐结果的最终呈现给用户的展示位置,提供了哪些信息
- 不同物品的推荐,根据用户的关注点,展现的方案也要不同

5. 推荐系统的思维模式
- 要有不确定的思维 - 推荐算法都是概率算法
- 目标思维 - 追求的是指标的增长
1.2 推荐算法的主要分类
1. 基于关联规则的推荐算法
-
基于Apriori 的算法
- Apariori是无监督学习算法
- Apariori是挖掘一堆数据集中数据之间的某种关联
- 数据集很大时,Apariori运行效率很低 - FP-Growth解决此问题
-
基于FP-Growth的算法
- FP-Growth 不产生候选集 - 和Apriori的两个不同点
- FP-Growth只需要扫描⒉次数据集 - 和Apriori的两个不同点
- 数据集映射到一颗FP树上,再从这棵树挖掘频繁项集 - 思路
关联分析算法应用场景关联分析算法应用场景
- 购物篮分析:
通过放入购物篮的不同商品之间的联系,分析顾客的购物习惯- 例子:购买鞋子的顾客,10%的会同时购买袜子
帮助商家能制定营销策略,货架摆放
- 例子:购买鞋子的顾客,10%的会同时购买袜子
2. 基于内容的推荐算法
- 推荐内容相似的物品 - 文章、商品类目及文本信息
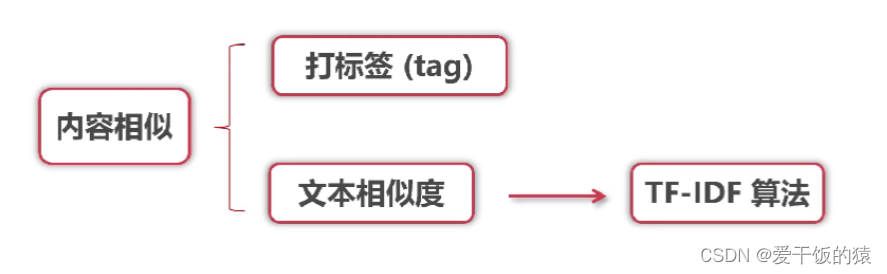
- TF-IDF算法步骤: - 基于自然语言
- 提取关键词及其TFIDF值
- 将共同关键词的TFIDF值的积并求和
- 获取相似度的值

3. 基于协同过滤的推荐算法
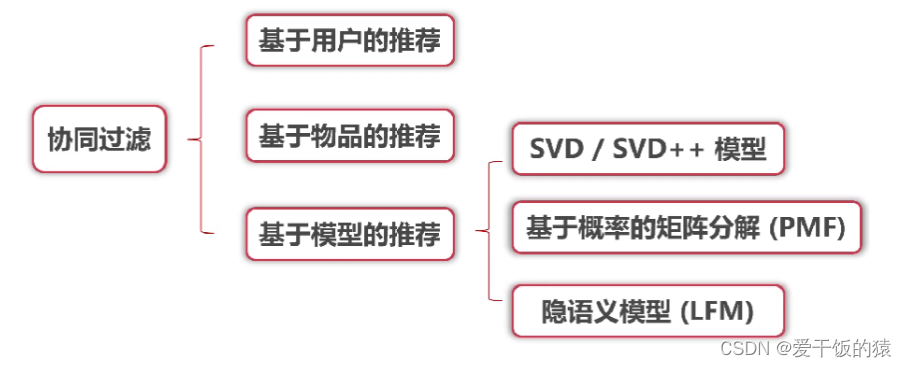
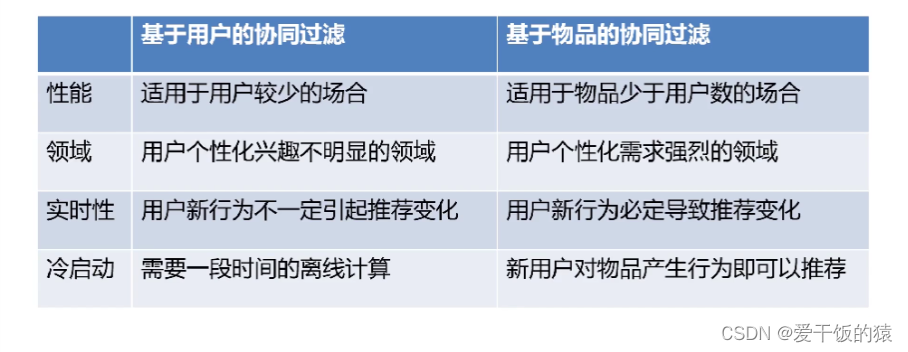
- 基于用户的协同过滤:兴趣相近的用户会对同样的物品感兴趣
- 基于物品的协同过滤:推荐给用户他们喜欢的物品相似的物品
- 基于物品的协同过滤,要基于用户的方式 - 不能简单推荐相似物品
-
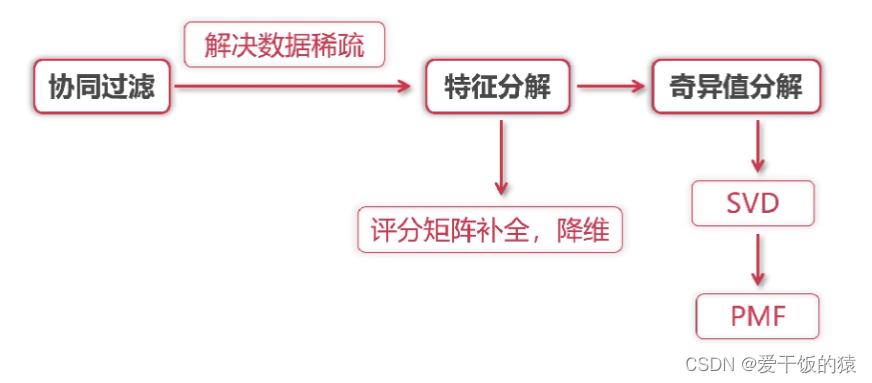
缺点:
- 数据稀疏性和冷启动问题
-
优点:
- 挖掘用户的潜在兴趣
- 仅需要评分矩阵来训练矩阵分解模型
-
SVD++是最流行的协同过滤模型 - 解决数据稀疏的问题
-
基于概率的矩阵分解PMF - 解决SVD模型过于复杂的问题
-
Spark内置的推荐算法是基于隐语义模型的协同过滤 - ALS
4. 基于模型的推荐算法
- 模型 - 基于深度学习
5. 基于混合的推荐算法
- 加权的混合:多种推荐算法按照权重组合起来
- 分层的混合:多种推荐算法,前一个推荐结果作为下一个的输入
- 分区的混合:多种推荐机制,将不同的推荐结果分不同的区推荐
1.3 推荐系统常见的问题
- 冷启动
- 数据稀疏
- 不断变化的用户喜好
- 不可预知的事项
1. 冷启动
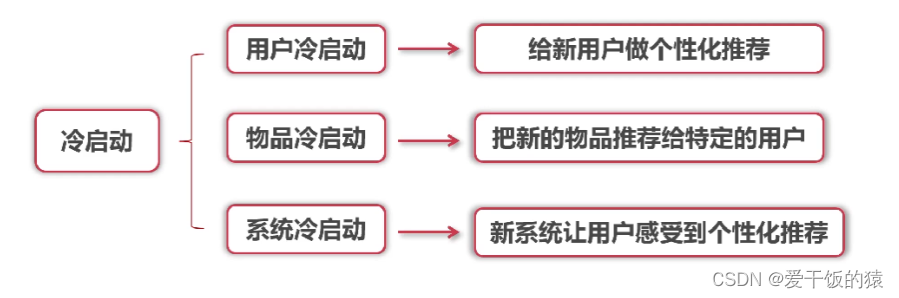
冷启动问题解决方法:
-
根据用户注册信息对用户进行分类
-
推荐热门的排行榜
-
基于深度学习的语义理解模型
-
引导用户把自己的属性表达出来
-
利用用户在社交媒体的信息
方案:
- 文本分析
- 主题模型
- 给物品打标签
- 推荐排行榜单
2. 数据稀疏
- 用户喜欢的物品,与其相似的用户也喜欢这个物品 - 协同过滤
- 用户-物品矩阵是稀疏矩阵 - 计算不准确
解决方案:
- 降低矩阵维数能降低数据稀疏性 - 奇异值分解
- 弊端:降低矩阵维数会丢失有效数据,使得预测的评分不准确
- 假设用户对其感兴趣物品相似的物品也感兴趣 - 数据填充
- 弊端:固定填充没有考虑到项目的属性,对推荐带来偏差
- 基于深度学习的语义理解模型 - 基于物品本身的信息
3. 不断变化的用户喜好
解决方案:
- 对用户行为的存储有实时性
- 推荐算法要考虑到用户近期行为和长期行为
- 要不断挖掘用户新的兴趣爱好
4. 什么是好的推荐系统?
- 推荐给用户的是用户感兴趣的内容
- 满足所有内容都被推荐给感兴趣的用户
- 能预测用户的行为
- 帮助用户发现那些他们可能会买,但不容易发现的东西
1.4 推荐系统效果评测
- 模型离线实验
- A/B Test在线实验
- 用户调研和用户反馈
1. 模型离线实验
- 将数据集分为训练集和测试集
- 在训练集上训练推荐模型,在测试集上进行预测
- 通过预定的指标来评测测试集上的预测结果
2. A/B Test在线实验
- A/B Test在线实验是以正交分桶为基础(随机将用户划分几组)
- 根据分桶执行不同的算法得出差异化的指标
- 取其中较优的算法
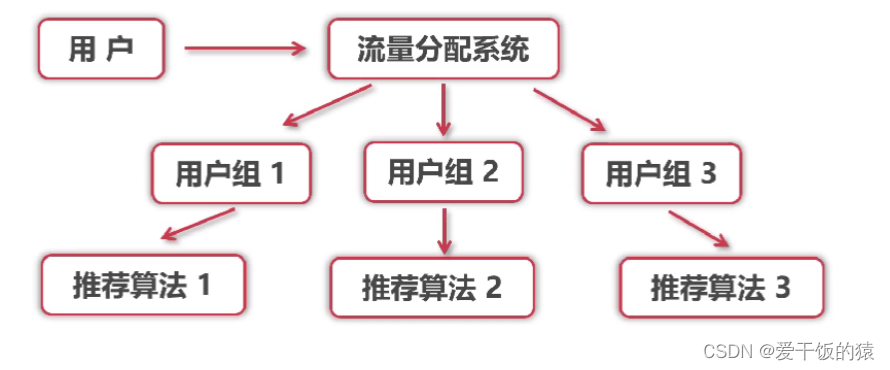
- A/B Test可以在各个桶间进行多层多类的AB Test测试
- A/B Test 也可以作为针对特定用户进行个性化的推荐
3. 用户调研和用户反馈
- 预测准确率高不代表用户满意度高
- 用户调研需要有一些真实的用户,需要他们完成一些的任务
- 缺点是用户调研成本高,一般情况下很难进行大规模的用户调查
4. 评测指标
4.1 预测准确度
预测准确度:度量预测用户行为的能力
4.1.1 评分预测
- 评分预测:用户对物品的评分行为
- 预测准确度:均方根误差(RMSE)和平均绝对误差(MAE)

4.1.2 TopN推荐
- TopN推荐:个性化推荐列表
- 预测准确度:准确率/召回率
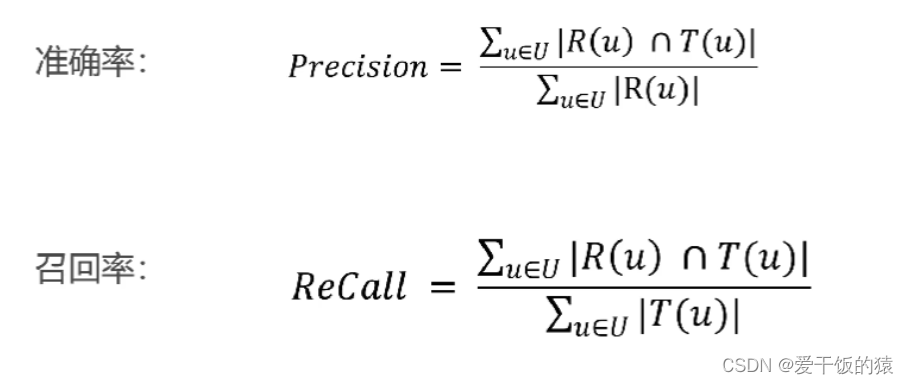
- 训练集(PHP, Java,C,C++)
- 测试集T(u)(Ruby,R,Python)
- 推荐列表R(u) (R,Python,Java,Vue)
- R(u)和T(u)的交集=2,准确率=2/4,召回率=2/3
4.2 覆盖率
- 覆盖率:描述推荐系统对物品长尾的发掘能力