2-4、DEBUG和源程序区别
语雀原文链接
文章目录
- 1、DEBUG 和 汇编编译器MASM
- 区别1:默认进制不同
- 区别2:[地址]
- 示例1:debug
- 示例2:[0]
- 示例3:[寄存器]
- 示例4:ds:[0]
- 小结
- 区别3:源程序数据不能以字母开头
1、DEBUG 和 汇编编译器MASM
- 之前的学习中,我们可以通过debug a命令写入汇编指令;也可以通过编写一个xx.asm源文件,通过编译链接,最终运行该程序。这两种方式在写法上有细微差别,同样的写法在这两个方式下可能会产生不同的结果。
- 下面我们就对这些差异点做详细的描述
区别1:默认进制不同
- 在debug中,默认所有数字都是 16 进制,加了 h 反而会报错;
- AX=1234

- DEBUG中主动添加进制标识会报错

- 在汇编源程序 .asm 中,不加 h 则默认为 10 进制,加 h 才表示 16 进制,加 b 为后缀为二进制;下述写法会报错
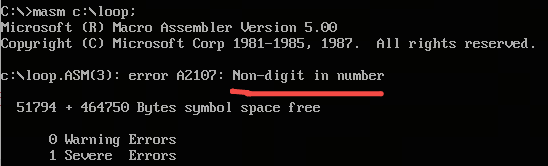
assume cs:code
code segment
mov ax,0fff
code ends
end
- asm源程序的正确写法
assume cs:code
code segment
mov ax,0fffH
mov bx,1234
code ends
end
- 使用 debug 跟踪可执行程序 .exe 的时候,debug会将不加 h 的 10 进制(或者加了b为后缀的二进制)变为对应的 16 进制。
区别2:[地址]
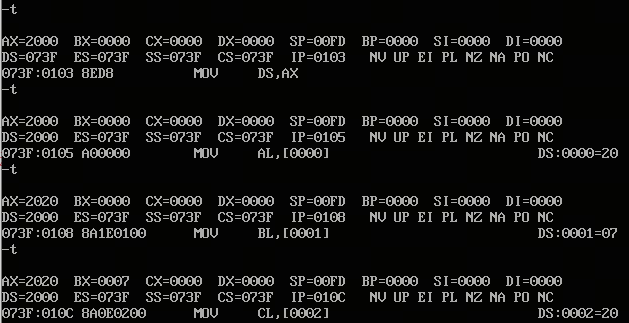
- DEBUG中会将[0]、[1]也就是2000:0 2000:1单元中数据送入al bl cl dl,符合我们的预期
示例1:debug
- 写入指令a

- 查看u

- 执行t
示例2:[0]
- 使用
assume cs:code
code segment
mov ax,2000H
mov ds,ax
mov al,[0]
mov bl,[1]
mov cl,[2]
mov dl,[3]
code ends
end
- 上述代码编译链接后运行,mov al,[0]最终被解释成了mov al,00,被当成了一个数据而不是内存单元的偏移地址


示例3:[寄存器]
- 为了解决上述问题,可以使用[寄存器]方式来访问内存单元,此时默认的段地址保存在ds中
assume cs:code
code segment
mov ax,2000H
mov ds,ax
mov bx,1
mov al,[bx]
code ends
end
- 执行结果

示例4:ds:[0]
- [0]里面是一个常量,就要显式的给出段地址所在的寄存器
assume cs:code
code segment
mov ax,2000H
mov ds,ax
mov al,ds:[0]
mov bl,ds:[1]
mov cl,ds:[2]
mov dl,ds:[3]
code ends
end
- 编译链接结果

小结
- 在汇编源程序中,如果用指令访问一个内存单元,则在指令中中必须用"[…]"来表示内存单元。
- 如果在"[]“里用一个常量idata直接给出内存单元的偏移地址,就要在”[]"的前面显式地给出段地址所在的段寄存器。比如mov al,ds:[0]
- 如果没有在"II"的前面显式地给出段地址所在的段寄存器,比如mov al,[0],那么,编译器masm将把指令中的"[idata]“解释为"idata”。
- 如果在"[]"里用寄存器,比如bx,间接给出内存单元的偏移地址,则段地址默认在ds中。当然,也可以显式地给出段地址所在的段寄存器
区别3:源程序数据不能以字母开头
- 下述程序可以正常编译运行
assume cs:code
code segment
mov ax,0fffh
code ends
end
- 下述程序报错,汇编源程序中数据不能以字母开头,必要的话前面加0
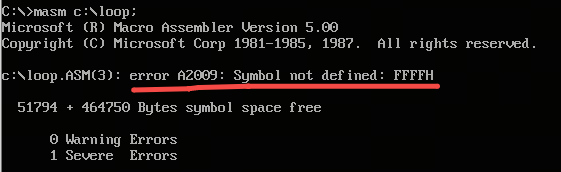
assume cs:code
code segment
mov ax,ffffh
code ends
end
- 数据前面加个0就不会报错
assume cs:code
code segment
mov ax,0ffffh
code ends
end