第 7 部分 — 增强 LLM 安全性的策略:数学和伦理框架
一、说明
增强大型语言模型 (LLM) 安全性的追求是技术创新、道德考虑和实际应用的复杂相互作用。这项努力需要一种深入而富有洞察力的方法,将先进的数学模型与道德原则和谐地融合在一起,以确保LLM的发展不仅在技术上稳健,而且在道德上合理且对社会负责。
在这篇博客中,我提供了数学工具、框架和想法来增强LLM的安全性。

二、 稳健的训练数据:多样性和代表性的数学方法
减少LLM偏差的基石在于训练数据的组成。这可以通过复杂的优化框架来实现:
2.1 训练数据优化框架
可以通过结合基于熵的多样性度量和更细致的差异指数以及对覆盖和冗余的复杂评估来增强优化框架:
![]()
在哪里,
- H ( D ) 是多样性的香农熵,提供数据集信息丰富度的度量。
- Δ( D ) 是基于基尼系数的差异指数,提供了更精确的数据表示不平等度量。
- C ( D ) 是基于 Jaccard 指数的覆盖度量,评估数据元素的唯一性。
- R ( D ) 是基于数据元素频率分析的冗余度量。
- α、λ、β和γ是平衡每一项贡献的系数。
2.2 增强度量的数学公式
基于熵的多样性(香农熵):
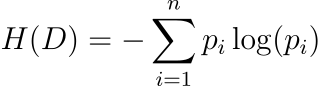
其中,pi表示数据集中第 i个类别或特征出现的概率。
香农熵是数据集中不确定性或随机性的度量。在LLM的训练数据中,熵值越高表示数据集越多样化。这种多样性对于训练稳健的模型至关重要,因为它确保接触广泛的语言输入和场景,从而降低模型输出中存在偏差的风险。
基于基尼系数的差距指数:
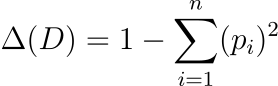
该指数衡量不同类别或特征的表示的不平等程度。
基于基尼系数的差异指数是数据集中不同类别或特征表示的不平等的度量。在LLM的训练数据中,较低的 Δ( D ) 值表示不同类别或特征的表示更加平衡和公平,这对于最大限度地减少模型输出中的偏差至关重要。该索引有助于确保训练数据中没有单一类别或特征过度占主导地位或代表性不足。
基于 Jaccard 指数的覆盖范围:
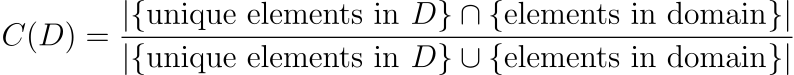
该索引评估D中的唯一元素与域中所有可能元素之间的重叠。
杰卡德指数是两个集合之间相似性的度量。在LLM训练数据的背景下,它量化了数据集D覆盖整个感兴趣领域的程度。C ( D )值越高,表明数据集包含更广泛的领域元素,这对于确保模型训练数据的全面覆盖和代表性至关重要。该指标有助于评估数据集是否充分代表了其要建模的领域的多样性。
基于频率分析的冗余:
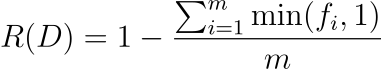
- fi表示数据集中第 i个元素的频率。
- min( fi ,1) 确保每个元素对总和的贡献最多为 1,无论其频率如何。这对于防止高频元素过度影响冗余分数非常重要。
- 除以m可以标准化度量,使其独立于数据集的大小。
此冗余指标量化了数据集中唯一数据的比例。R ( D )值越低表示冗余度越高,这意味着数据集包含大量重复或重复元素。该指标对于评估训练LLM的数据集的质量非常有用,因为过多的冗余可能会扭曲模型的学习过程并影响其性能。
2.3 示例:多语言翻译LLM强化培训
在多语言翻译LLM中,这种先进的方法可确保训练数据涵盖广泛的语言、方言和语言风格。基于熵的多样性度量确保了语言的丰富性,基于基尼系数的指数最大限度地减少了对任何特定语言的偏见,基于杰卡德指数的覆盖范围确保了广泛的语言谱,基于频率分析的冗余度量避免了常见短语的过度表达或结构。
三、道德准则和监督:道德合规的算法框架
道德评估框架可以扩展到多标准决策分析(MCDA)模型,纳入一系列道德维度及其复杂的相互依赖性:
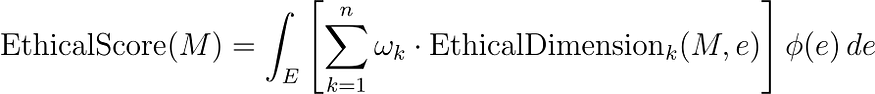
在这里,
- EthicalScore( M ) 是模型M的综合道德评分。
- EthicalDimension k ( M , e ) 代表在各种场景e中评估的一系列道德维度(如公平、透明、问责、隐私等)。
- ωk是每个道德维度的权重系数,反映它们的相对重要性。
- ψ ( e ) 是一个加权函数,根据频率、影响或利益相关者关注等因素为不同场景分配重要性。
- E上的积分可确保对不同场景进行全面评估。
该方程代表了评估LLM道德表现的综合方法。它考虑道德行为的多个方面,每个方面都有其重要性,并根据不同场景的相关性或影响来调整评估。这种方法可确保对模型在各种潜在情况下遵守道德标准的情况进行细致入微和彻底的评估
示例:自动驾驶法学硕士的道德评估
考虑用于自动驾驶决策系统的LLM。这个先进的框架评估模型在紧急决策、行人安全和遵守交通法规等场景中的道德表现。该模型不仅针对即时决策结果进行评估,还针对长期社会影响和法律合规性进行评估。
3.1 进一步的数学扩展:伦理决策理论和MCDA
为了量化每个道德维度,我们可以从道德决策理论和 MCDA 中得出:
公平指标(功利主义方法):
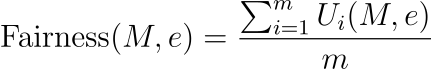
其中,Ui ( M , e ) 表示场景e中第 i个利益相关者的效用或收益,m是利益相关者的数量。
该方程代表了一种实现公平的功利主义方法,其中模型在特定场景中的公平性是根据它为所有相关利益相关者提供的平均收益或效用来评估的。这种方法可确保评估模型的决策或输出对不同利益相关者群体的总体影响,从而促进公平和平衡的结果。
透明度指标(信息论):
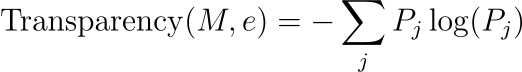
其中Pj是模型提供的第 j个解释或决策路径的概率。
该方程表示基于模型提供的解释或决策路径的多样性和分布的透明度度量。它类似于信息论中的熵概念,其中较高的值表示更多样化,因此可能更透明的解释集。该指标对于评估模型解释其决策或输出的能力特别有用,这是道德人工智能和机器学习系统的一个重要方面。
责任指标(风险评估):
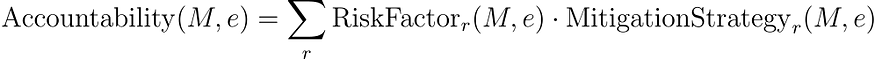
其中 RiskFactor r ( M , e ) 评估与第 r个决策路径相关的风险,MitigationStrategy r ( M , e ) 评估潜在纠正措施的有效性。
该方程通过评估模型识别和减轻各种风险的能力来评估模型的责任性。每个风险因素都被量化,并评估其相应缓解策略的有效性。然后通过对所有已识别风险的评估进行求和来确定总体责任。这种方法可确保对模型负责任地处理潜在问题的能力及其纠正问题的准备情况进行全面评估,这对于道德人工智能系统至关重要。
四、高级安全协议:非线性随机控制和稳定性分析
增强型随机控制模型可以通过结合非线性动力学和稳定性分析来进一步细化:
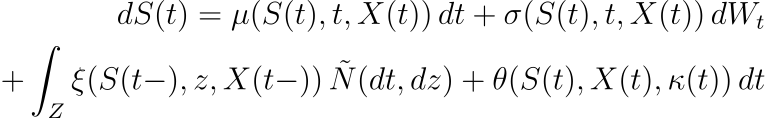
在这个高级模型中:
- μ ( S ( t ), t , X ( t )) 和σ ( S ( t ), t , X ( t )) 是安全级别S ( t )、时间t和附加状态变量X ( t)。
- θ ( S ( t ), X ( t ), κ ( t )) 是根据当前状态和控制动作κ ( t ) 进行调整的反馈控制项。
- 可以应用李亚普诺夫稳定性分析来确保安全水平保持在期望的范围内,从而增强模型的稳健性。
方程的叙述:
- 时间t时安全水平S ( t ) 的微分变化由dS ( t )给出,它是四个分量的总和。
- 第一个分量μ ( S ( t ), t , X ( t )) dt表示漂移项,它是安全级别S ( t )、时间t和外部状态变量X ( t )的函数。
- 第二个分量σ ( S ( t ), t , X ( t )) dWt表示扩散项,对安全性中的随机波动进行建模,其中dWt是维纳过程的微分。
- 第三个分量 ∫ Z xi ( S ( t −), z , X ( t −)) N ~( dt , dz ) 表示跳跃项,解释由于罕见或极端事件导致的安全水平突然变化,其中N ~ 是补偿泊松随机测度。
- 第四个分量θ ( S ( t ), X ( t ), κ ( t )) dt是反馈控制项,根据当前状态S ( t )、外部变量X ( t ) 和控制进行动态调整动作κ ( t )。
该方程对LLM中安全机制的动态进行建模,考虑到可预测和不可预测的变化,以及自适应响应各种条件和场景的能力。这种复杂的方法可以实时调整安全协议,这对于动态和不可预测的环境至关重要。
示例:自主导航中的自适应安全LLM
考虑用于自主导航系统的LLM。非线性随机控制模型使系统能够自适应地响应各种导航场景,从标准城市驾驶到复杂的紧急情况。反馈控制项θ根据当前交通状况、天气和车辆性能实时调整导航算法,而李亚普诺夫稳定性分析确保这些调整保持导航系统的整体安全性和稳定性。
4.1 进一步的数学扩展:基于强化学习的适应
为了优化基于学习的环境中的安全机制,我们可以引入强化学习框架:
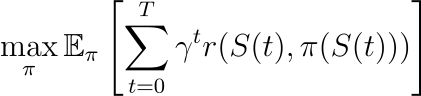
在这里:
- 目标是在政策π下,在时间范围T内最大化预期累积奖励。
- r ( S ( t ), π ( S ( t ))) 是奖励函数,量化在状态S ( t ) 下采取行动π ( S ( t )) 的收益。
- γ是一个折扣因子,平衡当前和未来的奖励。
- E π 表示策略π下的期望。
该方程通过多种方式与 LLM(大型语言模型)安全性间接相关:
- 安全响应培训:在LLM的背景下,强化学习可用于训练模型以生成安全、适当且合乎道德的响应。奖励函数r ( S ( t ), π ( S ( t ))) 可以设计为向符合安全和道德准则的输出分配较高的奖励,并为有害的、有偏见的输出分配较低(或负)的奖励。或不合适。
- 安全自适应学习:强化学习框架允许LLM从交互和反馈中不断学习。通过根据收到的奖励调整策略π,LLM可以自适应地提高其安全性方面的表现。这在“安全响应”的定义可能随着时间的推移而变化的动态环境中特别有用。
- 基于场景的训练: RL 框架中的状态S ( t ) 可以代表 LLM 运行的不同场景或上下文。通过考虑广泛的场景,强化学习方法可以确保LLM在不同情况(包括边缘情况)下保持安全。
- 平衡即时和长期安全: RL 方程中的折扣因子γ有助于平衡即时奖励与长期结果。这对于LLM的安全至关重要,因为它确保模型不仅能在短期内生成安全响应,还能学习维持长期安全的策略。
- 可定制的安全指标:强化学习中奖励函数的灵活性允许结合可定制的、细致入微的安全指标。安全的不同方面,例如避免错误信息、尊重隐私或防止攻击性内容,可以编码到奖励函数中。
五、人工智能辅助红队(AART):高级博弈论和系统分析框架
AART 框架可以通过集成博弈论模型和复杂系统分析来增强,以模拟更复杂的对抗性交互:

在这个高级方程中:
- GameTheoreticResponse( M , Ai )使用博弈论原理评估模型M对对抗性输入Ai的策略响应。
- αi代表每个博弈论对抗场景的重要性。
- SystemsRobustnessMetric( M , s ) 评估模型在复杂系统场景s中的稳健性。
- β ( s ) 是复杂系统场景 S 空间上的权重函数。
叙述:
- 模型M的AARTScore AARTScore( M )计算为显着性系数αi 和对抗性输入Ai的博弈论响应 GameTheoreticResponse( M , Ai ) 的乘积之和,加上空间上的积分复杂的系统场景S .
- 该积分计算每个场景s的加权函数β ( s ) 和系统鲁棒性度量 SystemsRobustnessMetric( M , s ) 的乘积。
这是评估LLM抵御对抗性攻击的稳健性的综合方法。它考虑了模型对特定对抗性输入的战略响应及其在复杂的全系统场景中的整体鲁棒性。这种双重方法确保了对LLM应对复杂和多方面的对抗性挑战的能力进行全面评估。
示例:国家安全LLM的战略和系统分析
考虑用于国家安全分析的LLM。增强的 AART 框架采用博弈论模型来模拟与潜在对手的战略互动,评估模型提供战略见解的能力。此外,它还使用复杂系统分析来评估模型在涉及地缘政治事件、信息战和网络威胁的复杂网络的场景中的稳健性。
5.1 进一步的数学扩展:多智能体建模和进化动力学
为了更真实地模拟对抗场景,可以使用多智能体建模方法:
![]()
在这里:
- Ai是由多智能体模型 M 生成的对抗性输入。
- θ 代表控制代理行为的参数。
- D和I代表代理的数据分布和交互规则。
用于测试LLM的对抗性输入不仅是随机生成的,而且是由模拟现实且具有战略相关性的对抗性场景的复杂模型产生的。
参数 θ 控制模型内代理的行为,而 D 和 I 分别表示底层数据分布和控制代理交互的规则或约束。这种方法允许创建具有挑战性和多样化的对抗性输入,可以有效地测试和增强LLM的稳健性。
结合进化动力学可以随着时间的推移适应和优化对抗策略:
![]()
其中,EvolutionaryAdversarialEffectiveness( M , Ai ) 衡量在挑战模型M时随时间演变的对抗策略的有效性。
AART 和 LLM 对抗性测试背景下的“进化对抗有效性”函数是一种概念函数,而不是标准的、普遍定义的函数。其具体表述可能会根据对抗性测试的目标和所测试的LLM的特征而有所不同。不过,我可以提供这样一个函数可能需要什么的一般概念:
该功能的目标:
- “EvolutionaryAdversarialEffectiveness”函数的主要目标是评估给定的对抗性输入(通过进化策略生成)在暴露 LLM 中的漏洞或弱点方面的有效性。
该功能的可能组成部分:
- 漏洞利用分数:衡量对抗性输入利用 LLM 中已知或潜在漏洞的程度。这可能涉及测试LLM对旨在引发偏见、不正确或不道德反应的输入的响应。
- 稳健性挑战得分:评估对抗性输入对LLM稳健性的挑战程度,可能是通过呈现LLM必须处理的复杂、模糊或新颖的场景。
- 多样性和新颖性分数:与典型训练数据或之前的对抗性示例相比,评估对抗性输入的独特性,确保LLM在广泛的场景中进行测试。
数学表示:
该函数的简化表示可能如下所示:
![]()
其中,V ( M , Ai ) 是给定对抗性输入Ai的模型M 的漏洞利用分数,R ( M , Ai ) 是鲁棒性挑战分数,D ( Ai ) 是多样性和新颖性分数。权重 1,2、w 1、w 2和w 3平衡了每个组件的重要性。
进化方面:
- 进化方面意味着该函数在迭代过程中使用,其中对抗性输入逐渐完善以变得更加有效。这可能涉及遗传算法等技术,其中输入根据其有效性分数在几代人中不断演变。
在实践中,目标函数的具体表述将根据LLM的特殊性和对抗性测试的目标进行定制,并且可能涉及机器学习指标、统计分析和特定领域评估的组合。
六、透明度和问责制:先进的统计和理论框架
透明度指数可以通过捕获可解释性各个方面的指标来增强,并且可以引入问责框架来量化模型的责任和可追溯性。该指数可以通过纳入统计可解释性和决策一致性的衡量标准来增强:
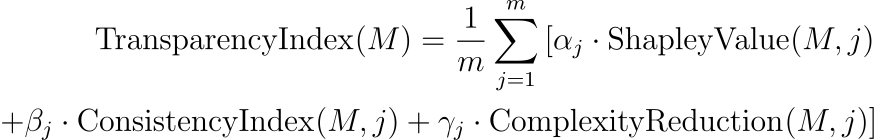
在这里:
- ShapleyValue( M , j )使用合作博弈论中的 Shapley 值来量化场景j中每个输入特征对模型输出的贡献。
- ConsistencyIndex( M , j ) 衡量相似场景中模型输出的一致性,从而增强可预测性。
- ComplexityReduction( M , j ) 继续评估模型简化复杂信息的能力。
全面的问责框架:
问责框架可以包括因果影响分析和道德决策审计:
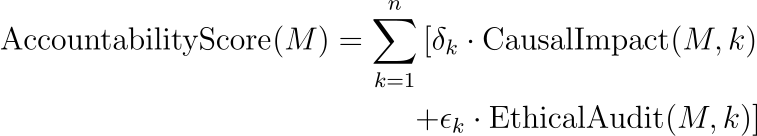
在哪里:
- CausalImpact( M , k ) 使用因果推理技术评估模型决策和结果之间的因果关系。
- EthicalAudit( M , k ) 是一个审核过程,根据道德准则和标准评估模型的决策。
示例:内容推荐 LLM 中的高级指标
考虑用于内容推荐的LLM。先进的透明度指数评估模型的决策过程,确保建议基于相关功能,并且在相似的用户配置文件中保持一致。问责分数评估建议对用户行为的因果影响,并进行道德审核,以确保内容符合社区标准并且不会宣扬有害行为。
进一步的数学扩展:责任的因果推理
为了量化因果影响,可以采用反事实分析:
![]()
其中,Y_ do( X = x ) 是将干预X设置为值x(模型做出的决策)时的预期结果, Y do( X = x ′) 是替代决策 ′ 的预期结果X '。
这代表了一种量化模型所采取的特定决策或行动的因果效应的方法。它使用因果推理中的反事实概念,其中Y_ do( X = x ) 表示模型采取操作x时的预期结果,Y_ do( X = x ′) 表示替代操作 ′ x的预期结果′。
这种方法对于理解模型决策的直接影响至关重要,而不仅仅是相关性,并且在理解因果关系至关重要的场景中尤其重要。
提高LLM的安全性是一项多方面的挑战,需要深入了解这些先进技术的数学复杂性和伦理影响。通过将复杂的数学模型、道德考虑和实际应用相结合,我们可以为LLM铺平道路,这些LLM不仅在技术上精通,而且在道德上健全且对社会有益。