CKafka 一站式搭建数据流转链路,助力长城车联网平台降低运维成本
关于长城智能新能源
长城汽车是一家全球化智能科技公司,业务包括汽车及零部件设计、研发、生产、销售和服务,旗下拥有魏牌、哈弗、坦克、欧拉及长城皮卡。2022年,长城汽车全年销售1,067,523辆,连续7年销量超100万辆。长城汽车面向全球用户提供智能、绿色出行服务,加速向全球化智能科技公司进阶,智能化车型渗透率达86.17%,车联网作为智能化两大应用方向之一,在这个过程中快速发展。
长城车联网平台涵盖车内总线数据上报、远程、车机配置下发、推送文件、推送消息、运营关怀等全新车联网业务,实现车机端和业务平台解耦并高效完成业务对接整合。
主要场景包括:
● 车端数据上报——电机、位置、发动机、整车数据、电池,报警等,通过 tbox 上报车联网平台,针对上报数据进行实时数据处理、计算、推理,以便提供车况查询、告警等智能化服务。
● 远程控制——手机 APP/智能设备集成车联网平台能力,实现远控、诊断。
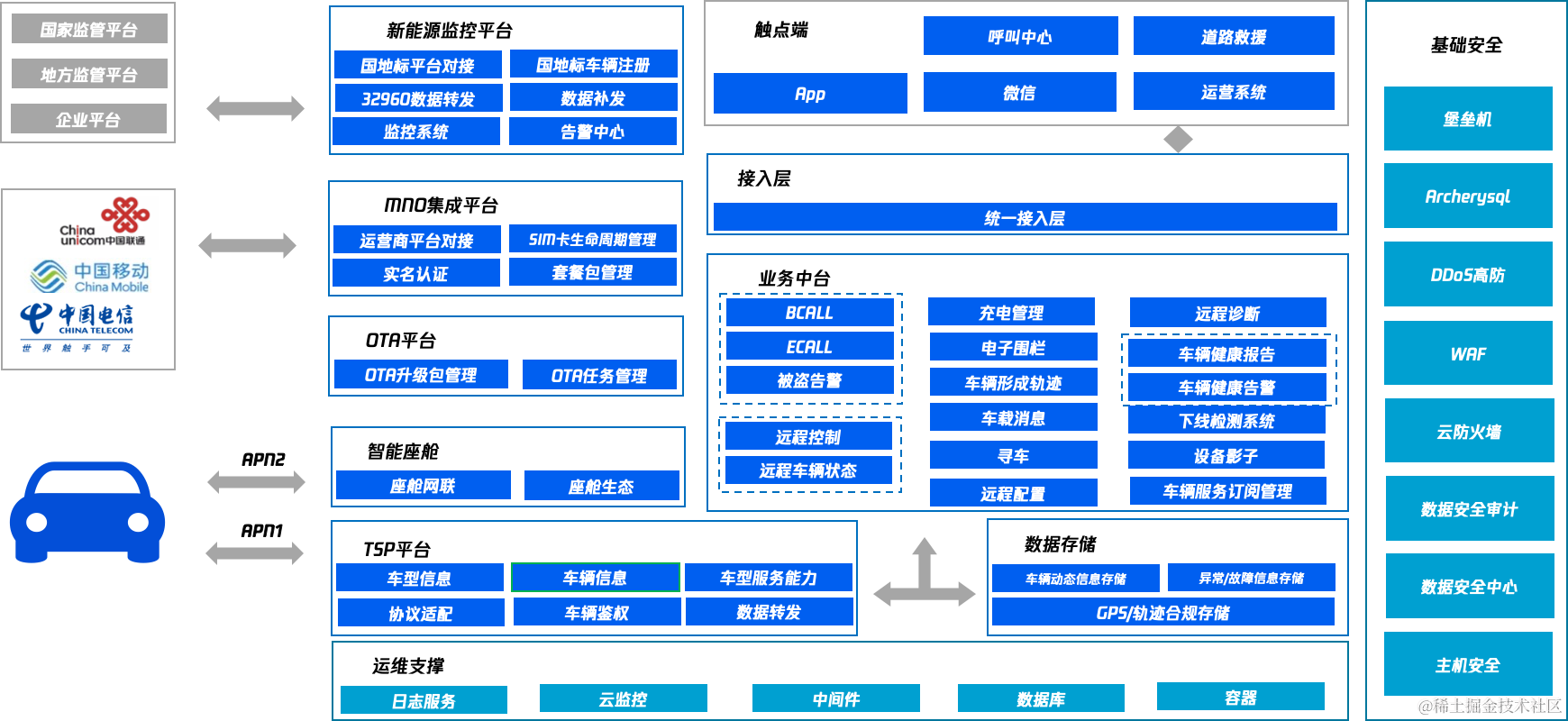
以下是车联网平台架构图(示意)。
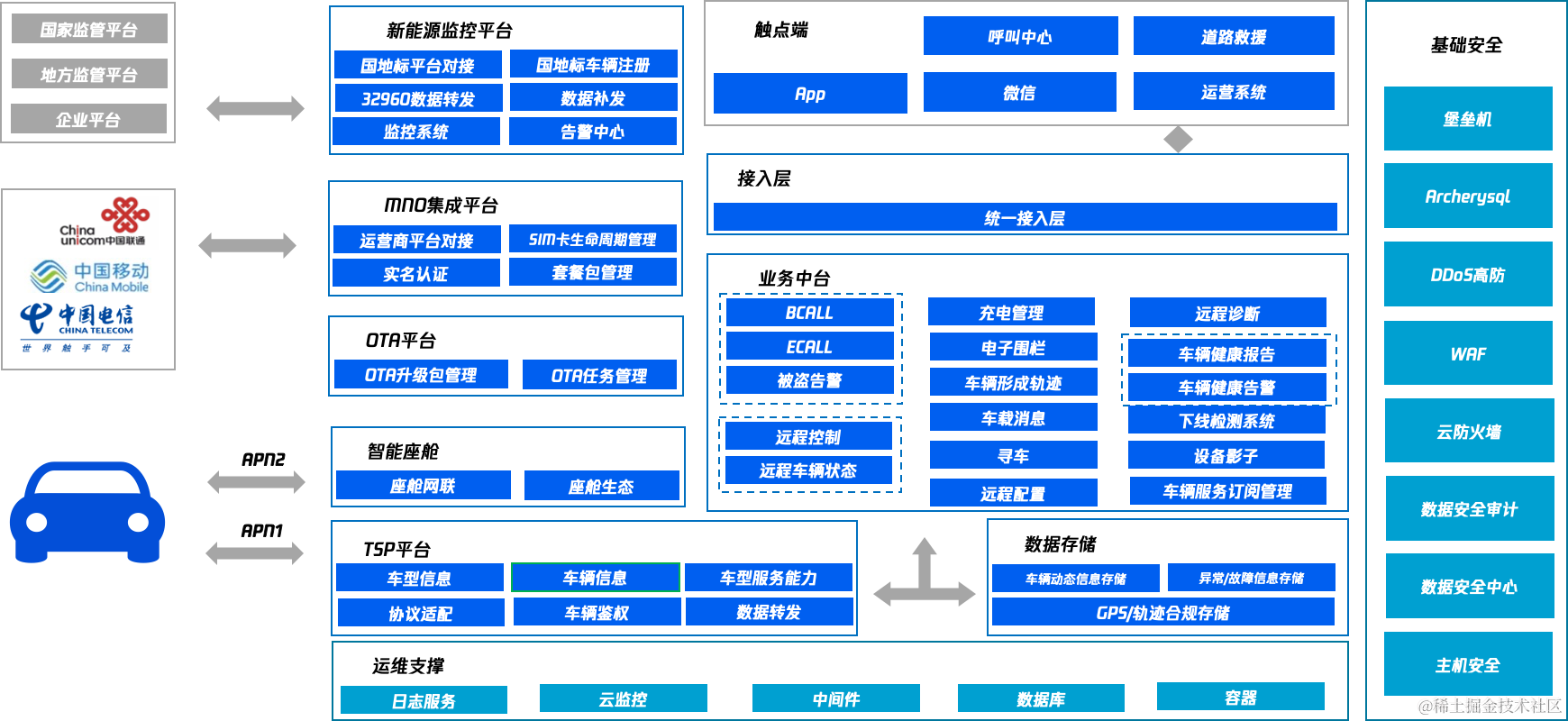
车联网平台架构图(示意)
爆炸式增长带来的挑战
车联网平台目前已接入数百万辆车,峰值在线达百万辆。车端上报信号数据量大、上传频率高,数据呈爆炸式增长,海量数据实时处理与分析面临严重挑战。
对系统提出以下要求:
1、处理时效要求高
查询时效性、分析决策、监控告警
2、数据量大,稳定
分布式、平行扩展、低耦合、高可用性、数据安全
物联网设备通常性能比较弱,很难去使用流行的传统的消息中间件。基本上 IOT 设备里面,都是用 MQTT 来去做消息的传输。但 MQTT 存在以下缺点:
1、只是排队,而不是流处理
2、无法处理使用量激增(没有缓冲)
3、大多数 MQTT 代理不支持高可伸缩性
4、异步处理(通常脱机很长时间)
5、缺乏与企业其他部分的良好集成
6、单一基础设施(通常位于边缘)
7、不能对事件进行再处理
只有 MQTT 数据有可能来不及处理就被丢掉,同时也满足不了海量数据实时处理与分析带来的挑战。
解决方案
作为分布式消息队列的 Kafka,因多分区、零拷贝、批处理、顺序读写等设计和特性能够实现高吞吐量的数据处理。同时作为一个事件流平台,它结合消息传递、存储和数据处理来构建高度可伸缩、可靠、安全和实时的基础设施。从车联网的角度来看具有以下优点:
1、流处理,不仅仅是排队
2、高吞吐量
3、大规模的
4、高可用性
5、长期存储和缓冲
6、再处理的事件
7、与企业的其他部分良好集成
Kafka 和 MQTT 的结合是构建可伸缩、可靠和安全的车联网基础设施的天成之选,因此长城车联网平台选择 Kafka 作为数据处理核心组件。
MQTT 的 Broker 集群后对接 Kafka 集群,先通过 MQTT 从设备采集数据,采集后再转储到 Kafka ,供后续引擎分析处理。即使处理的速度没有采集的速度快,数据也不会丢失,因为已转储到 Kafka ,长城正是用这种方案实现了车联网设备状态的持续监控和分析。
但自建 Kafka 带来日益加重的研发和运维成本:
首先,解决问题的研发运维人员需要具备扎实的计算机功底(熟悉计算机网络、IO 等),需对 Kafka 的底层原理、各种配置参数项等具有深刻理解,可以进行 Kafka 集群参数调优,快速处理突发故障、恢复集群抖动和动态进行集群扩缩容等。
其次,一方面需要投入更多的人力、物力成本,另一方面 需要时刻监控集群的健康状况,及时排除问题以保障业务的稳定运行。
最后,自建消息队列在扩展性、可维护性能方面存在不足,当业务的消息数据量到达一定程度后,自建的消息队列集群就会引发各种各样的问题,问题的解决又带来很大的挑战。
举几个简单例子:
● 集群发生异常时,因为监控指标不全,日志输出不合理等原因,排查定位问题困难。只能靠暂停业务、重启 Kafka 集群解决问题,对业务影响较大。
● Kafka 的集群扩容复杂度高,在业务高峰进行迁移的时候,出现分区迁移卡死。
● 自建集群的 ZK 运维难度大,ZK 负载高,导致ZK频繁断连。
与腾讯云技术团队沟通, CKafka(Cloud Kafka)作为云上Kafka版本,具有完善的监控告警系统和运维工单系统,在性能、扩展性、业务安全保障、运维等方面具有很强优势,可以在享受低成本、高性能、丰富功能的同时,免除繁琐运维工作。
车联网平台利用高性能、高吞吐、可拓展的分布式消息队列引擎 CKafka,实现业务解耦、削峰填谷、数据的异步处理,达到业务的高可靠性。
数据上报场景
关于长城智能新能源
长城汽车是一家全球化智能科技公司,业务包括汽车及零部件设计、研发、生产、销售和服务,旗下拥有魏牌、哈弗、坦克、欧拉及长城皮卡。2022年,长城汽车全年销售1,067,523辆,连续7年销量超100万辆。长城汽车面向全球用户提供智能、绿色出行服务,加速向全球化智能科技公司进阶,智能化车型渗透率达86.17%,车联网作为智能化两大应用方向之一,在这个过程中快速发展。
长城车联网平台涵盖车内总线数据上报、远程、车机配置下发、推送文件、推送消息、运营关怀等全新车联网业务,实现车机端和业务平台解耦并高效完成业务对接整合。
主要场景包括:
● 车端数据上报——电机、位置、发动机、整车数据、电池,报警等,通过 tbox 上报车联网平台,针对上报数据进行实时数据处理、计算、推理,以便提供车况查询、告警等智能化服务。
● 远程控制——手机 APP/智能设备集成车联网平台能力,实现远控、诊断。
以下是车联网平台架构图(示意)。
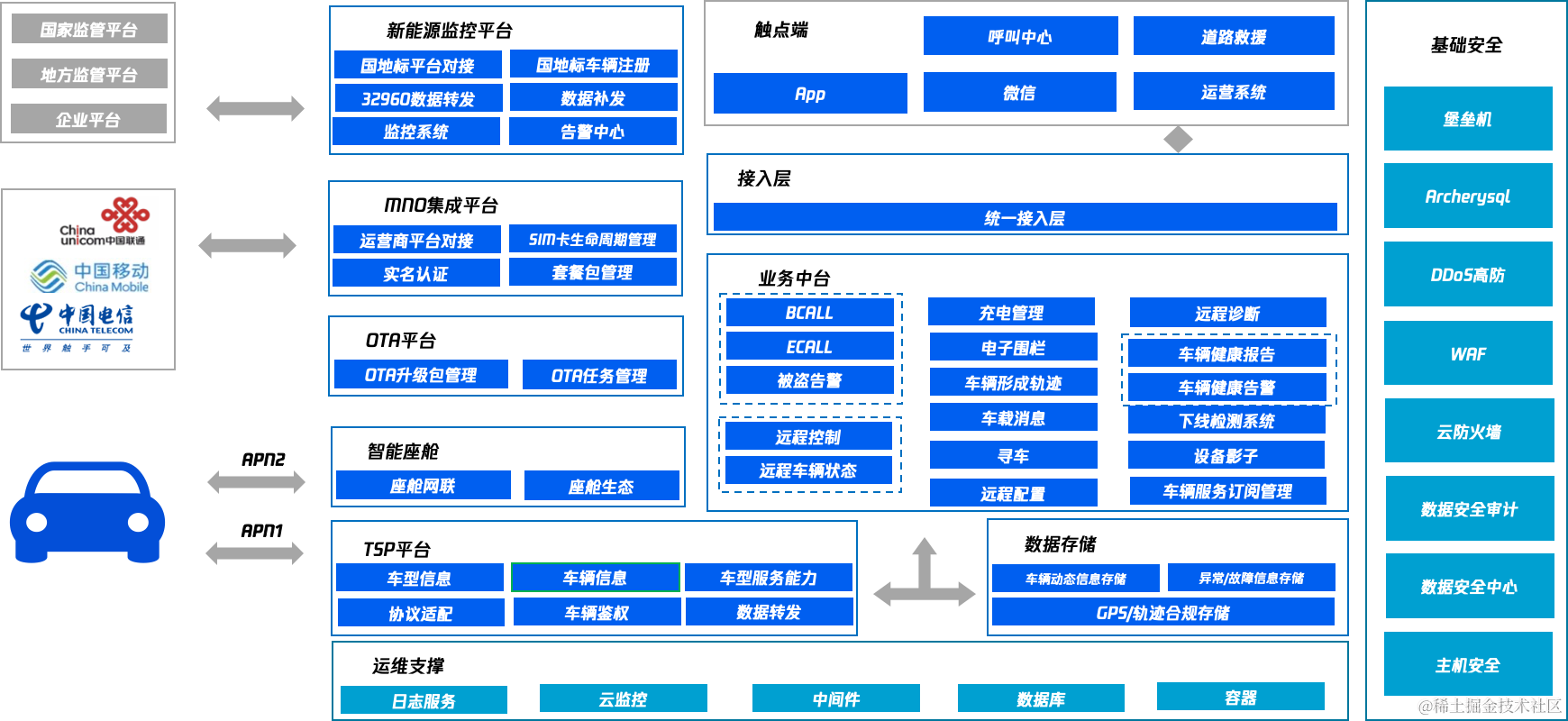
车联网平台架构图(示意)
爆炸式增长带来的挑战
车联网平台目前已接入数百万辆车,峰值在线达百万辆。车端上报信号数据量大、上传频率高,数据呈爆炸式增长,海量数据实时处理与分析面临严重挑战。
对系统提出以下要求:
1、处理时效要求高
查询时效性、分析决策、监控告警
2、数据量大,稳定
分布式、平行扩展、低耦合、高可用性、数据安全
物联网设备通常性能比较弱,很难去使用流行的传统的消息中间件。基本上 IOT 设备里面,都是用 MQTT 来去做消息的传输。但 MQTT 存在以下缺点:
1、只是排队,而不是流处理
2、无法处理使用量激增(没有缓冲)
3、大多数 MQTT 代理不支持高可伸缩性
4、异步处理(通常脱机很长时间)
5、缺乏与企业其他部分的良好集成
6、单一基础设施(通常位于边缘)
7、不能对事件进行再处理
只有 MQTT 数据有可能来不及处理就被丢掉,同时也满足不了海量数据实时处理与分析带来的挑战。
解决方案
作为分布式消息队列的 Kafka,因多分区、零拷贝、批处理、顺序读写等设计和特性能够实现高吞吐量的数据处理。同时作为一个事件流平台,它结合消息传递、存储和数据处理来构建高度可伸缩、可靠、安全和实时的基础设施。从车联网的角度来看具有以下优点:
1、流处理,不仅仅是排队
2、高吞吐量
3、大规模的
4、高可用性
5、长期存储和缓冲
6、再处理的事件
7、与企业的其他部分良好集成
Kafka 和 MQTT 的结合是构建可伸缩、可靠和安全的车联网基础设施的天成之选,因此长城车联网平台选择 Kafka 作为数据处理核心组件。
MQTT 的 Broker 集群后对接 Kafka 集群,先通过 MQTT 从设备采集数据,采集后再转储到 Kafka ,供后续引擎分析处理。即使处理的速度没有采集的速度快,数据也不会丢失,因为已转储到 Kafka ,长城正是用这种方案实现了车联网设备状态的持续监控和分析。
但自建 Kafka 带来日益加重的研发和运维成本:
首先,解决问题的研发运维人员需要具备扎实的计算机功底(熟悉计算机网络、IO 等),需对 Kafka 的底层原理、各种配置参数项等具有深刻理解,可以进行 Kafka 集群参数调优,快速处理突发故障、恢复集群抖动和动态进行集群扩缩容等。
其次,一方面需要投入更多的人力、物力成本,另一方面 需要时刻监控集群的健康状况,及时排除问题以保障业务的稳定运行。
最后,自建消息队列在扩展性、可维护性能方面存在不足,当业务的消息数据量到达一定程度后,自建的消息队列集群就会引发各种各样的问题,问题的解决又带来很大的挑战。
举几个简单例子:
● 集群发生异常时,因为监控指标不全,日志输出不合理等原因,排查定位问题困难。只能靠暂停业务、重启 Kafka 集群解决问题,对业务影响较大。
● Kafka 的集群扩容复杂度高,在业务高峰进行迁移的时候,出现分区迁移卡死。
● 自建集群的 ZK 运维难度大,ZK 负载高,导致ZK频繁断连。
与腾讯云技术团队沟通, CKafka(Cloud Kafka)作为云上Kafka版本,具有完善的监控告警系统和运维工单系统,在性能、扩展性、业务安全保障、运维等方面具有很强优势,可以在享受低成本、高性能、丰富功能的同时,免除繁琐运维工作。
车联网平台利用高性能、高吞吐、可拓展的分布式消息队列引擎 CKafka,实现业务解耦、削峰填谷、数据的异步处理,达到业务的高可靠性。
数据上报场景
关于长城智能新能源
长城汽车是一家全球化智能科技公司,业务包括汽车及零部件设计、研发、生产、销售和服务,旗下拥有魏牌、哈弗、坦克、欧拉及长城皮卡。2022年,长城汽车全年销售1,067,523辆,连续7年销量超100万辆。长城汽车面向全球用户提供智能、绿色出行服务,加速向全球化智能科技公司进阶,智能化车型渗透率达86.17%,车联网作为智能化两大应用方向之一,在这个过程中快速发展。
长城车联网平台涵盖车内总线数据上报、远程、车机配置下发、推送文件、推送消息、运营关怀等全新车联网业务,实现车机端和业务平台解耦并高效完成业务对接整合。
主要场景包括:
● 车端数据上报——电机、位置、发动机、整车数据、电池,报警等,通过 tbox 上报车联网平台,针对上报数据进行实时数据处理、计算、推理,以便提供车况查询、告警等智能化服务。
● 远程控制——手机 APP/智能设备集成车联网平台能力,实现远控、诊断。
以下是车联网平台架构图(示意)。
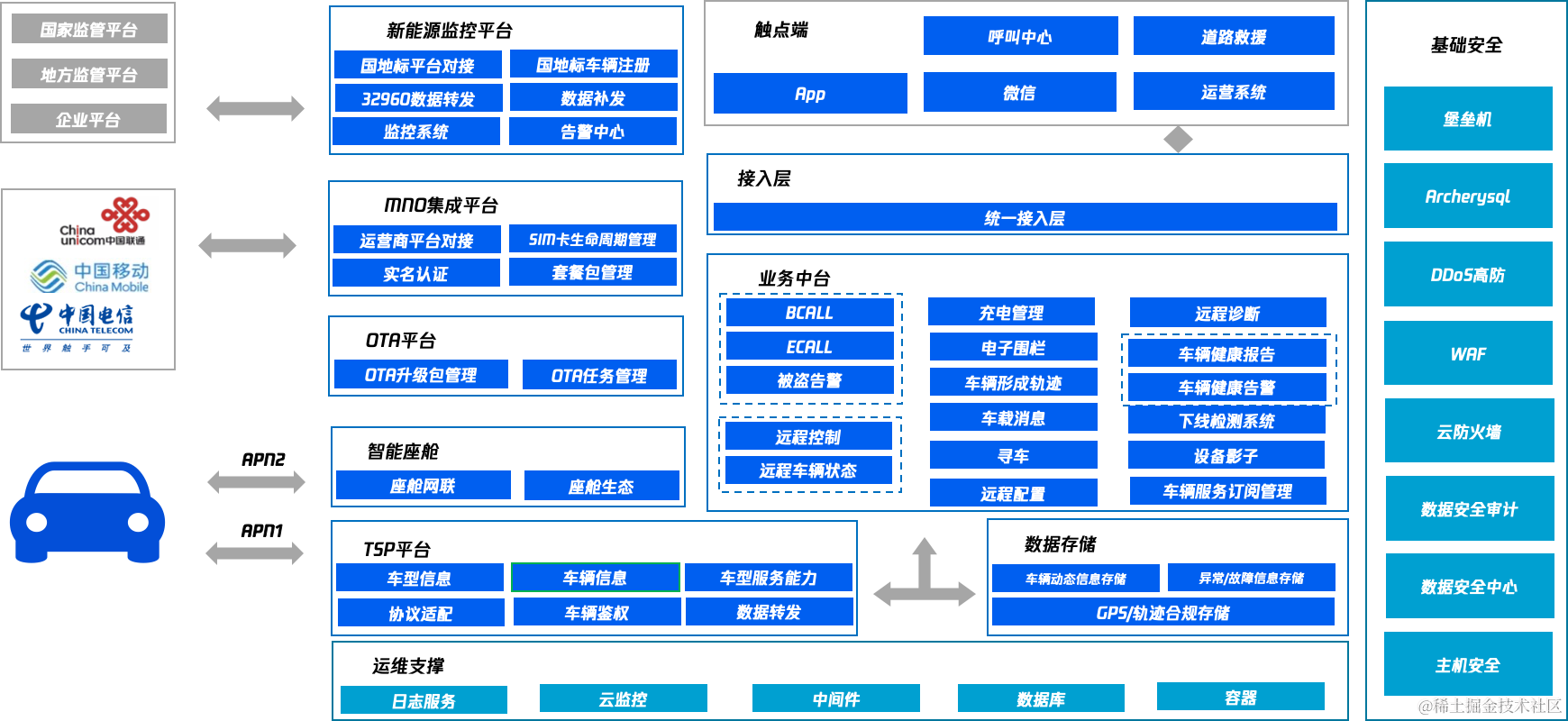
车联网平台架构图(示意)
爆炸式增长带来的挑战
车联网平台目前已接入数百万辆车,峰值在线达百万辆。车端上报信号数据量大、上传频率高,数据呈爆炸式增长,海量数据实时处理与分析面临严重挑战。
对系统提出以下要求:
1、处理时效要求高
查询时效性、分析决策、监控告警
2、数据量大,稳定
分布式、平行扩展、低耦合、高可用性、数据安全
物联网设备通常性能比较弱,很难去使用流行的传统的消息中间件。基本上 IOT 设备里面,都是用 MQTT 来去做消息的传输。但 MQTT 存在以下缺点:
1、只是排队,而不是流处理
2、无法处理使用量激增(没有缓冲)
3、大多数 MQTT 代理不支持高可伸缩性
4、异步处理(通常脱机很长时间)
5、缺乏与企业其他部分的良好集成
6、单一基础设施(通常位于边缘)
7、不能对事件进行再处理
只有 MQTT 数据有可能来不及处理就被丢掉,同时也满足不了海量数据实时处理与分析带来的挑战。
解决方案
作为分布式消息队列的 Kafka,因多分区、零拷贝、批处理、顺序读写等设计和特性能够实现高吞吐量的数据处理。同时作为一个事件流平台,它结合消息传递、存储和数据处理来构建高度可伸缩、可靠、安全和实时的基础设施。从车联网的角度来看具有以下优点:
1、流处理,不仅仅是排队
2、高吞吐量
3、大规模的
4、高可用性
5、长期存储和缓冲
6、再处理的事件
7、与企业的其他部分良好集成
Kafka 和 MQTT 的结合是构建可伸缩、可靠和安全的车联网基础设施的天成之选,因此长城车联网平台选择 Kafka 作为数据处理核心组件。
MQTT 的 Broker 集群后对接 Kafka 集群,先通过 MQTT 从设备采集数据,采集后再转储到 Kafka ,供后续引擎分析处理。即使处理的速度没有采集的速度快,数据也不会丢失,因为已转储到 Kafka ,长城正是用这种方案实现了车联网设备状态的持续监控和分析。
但自建 Kafka 带来日益加重的研发和运维成本:
首先,解决问题的研发运维人员需要具备扎实的计算机功底(熟悉计算机网络、IO 等),需对 Kafka 的底层原理、各种配置参数项等具有深刻理解,可以进行 Kafka 集群参数调优,快速处理突发故障、恢复集群抖动和动态进行集群扩缩容等。
其次,一方面需要投入更多的人力、物力成本,另一方面 需要时刻监控集群的健康状况,及时排除问题以保障业务的稳定运行。
最后,自建消息队列在扩展性、可维护性能方面存在不足,当业务的消息数据量到达一定程度后,自建的消息队列集群就会引发各种各样的问题,问题的解决又带来很大的挑战。
举几个简单例子:
● 集群发生异常时,因为监控指标不全,日志输出不合理等原因,排查定位问题困难。只能靠暂停业务、重启 Kafka 集群解决问题,对业务影响较大。
● Kafka 的集群扩容复杂度高,在业务高峰进行迁移的时候,出现分区迁移卡死。
● 自建集群的 ZK 运维难度大,ZK 负载高,导致ZK频繁断连。
与腾讯云技术团队沟通, CKafka(Cloud Kafka)作为云上Kafka版本,具有完善的监控告警系统和运维工单系统,在性能、扩展性、业务安全保障、运维等方面具有很强优势,可以在享受低成本、高性能、丰富功能的同时,免除繁琐运维工作。
车联网平台利用高性能、高吞吐、可拓展的分布式消息队列引擎 CKafka,实现业务解耦、削峰填谷、数据的异步处理,达到业务的高可靠性。
数据上报场景
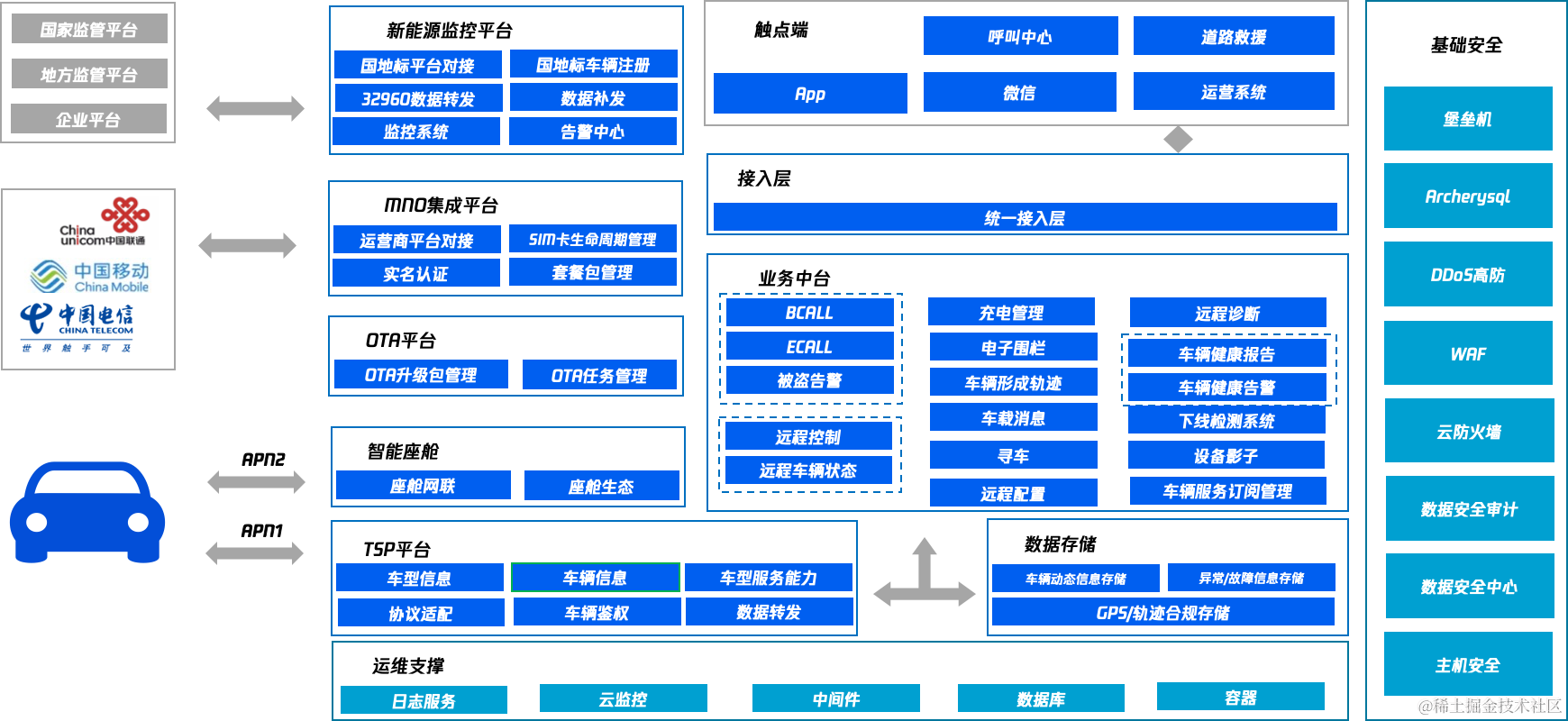
车辆产生的实时数据(如 GPS 位置、速度、油耗等)通过 CKafka 进行收集、传输、分发,实现一份数据多个流向满足多个场景需求。
实时计算部分
通过 Flink 提供的 Kafka 连接器,流数据经过 Flink 算子进行处理落入高性能列式数据库Clickhouse,用于实时更新数据的分析。该流程可提供一次精确的处理语义,同时 CKafka 多分区提供更高的吞吐量,减少数据倾斜和热点。
车辆故障、异常行为等车辆的状态数据,通过实时分析可以快速发现并处理车辆的问题。
离线分析部分
通过 Flume 等日志收集系统,可将 CKafka 中海量日志数据进行高效收集、聚合、移动,最后存储到 HDFS 或者 Hbase。在生产处理环节中,当生产与处理速度不一致时,CKafka 可以充当缓存角色。 拥有 Partition 结构以及采用 Append 追加数据,使 CKafka 具有优秀的吞吐能力;同时其拥有 Replication 结构,使 CKafka 具有很高的容错性。
车辆数据经过离线分析和挖掘,分析结果可以用于优化车辆性能、提高驾驶安全、降低能耗等。
指令下发场景

在指令下发场景中,CKafka 承接远程指令和响应结果,为上下游多个系统提供异步接耦、削峰填谷的能力,同时消息持久化及可回溯的产品特性能保障指令状态的最终一致性。
使用 CKafka 后的业务收益
与自建 Kafka 相比,CKafka 有完善的监控告警系统和运维工单系统,CKafka 研发专家随时答疑解惑,迅速解决客户问题,省心省力。
CKafka 在性能、扩展性、业务安全保障、运维等方面具有超强优势,让客户在享受低成本、超强功能的同时,免除繁琐运维工作。当 CKafka 集群的流量和磁盘容量超过告警阈值,后端会及时扩容设备对客户端无感知,解决开源 Kafka 长期以来迁移数据的痛点,配置升级无感知,轻松应对业务高峰。
除了可拓展性之外,Ckafka 支持同地域自定义多可用区部署,跨地域灾备,提升业务容灾能力。
未来展望
针对降低存储成本、快速应对突发流量峰值的两个核心诉求,CKafka 将演进按量存储形态,并推出弹性带宽能力。
● 按量存储
按照实际使用存储空间弹性计费,无需考虑预留存储空间,更加灵活易运维,且成本更低。
● 弹性带宽
在既定带宽规格上,提供一定范围的上浮空间(即弹性能力)。
若遇到突发的流量毛刺,集群不会触发限流,而是在规定范围内弹性扩缩容,超出原有带宽部分的流量按量计费。
通过合理的架构设计和灵活的产品能力,CKafka 帮助用户在云上以更低成本托管高吞吐、高可用、易用免运维的消息队列 Kafka 服务,一站式搭建数据流转链路。后续也期待与出行行业客户有更多合作,分享更多云上最佳实践。
车辆产生的实时数据(如 GPS 位置、速度、油耗等)通过 CKafka 进行收集、传输、分发,实现一份数据多个流向满足多个场景需求。
实时计算部分
通过 Flink 提供的 Kafka 连接器,流数据经过 Flink 算子进行处理落入高性能列式数据库Clickhouse,用于实时更新数据的分析。该流程可提供一次精确的处理语义,同时 CKafka 多分区提供更高的吞吐量,减少数据倾斜和热点。
车辆故障、异常行为等车辆的状态数据,通过实时分析可以快速发现并处理车辆的问题。
离线分析部分
通过 Flume 等日志收集系统,可将 CKafka 中海量日志数据进行高效收集、聚合、移动,最后存储到 HDFS 或者 Hbase。在生产处理环节中,当生产与处理速度不一致时,CKafka 可以充当缓存角色。 拥有 Partition 结构以及采用 Append 追加数据,使 CKafka 具有优秀的吞吐能力;同时其拥有 Replication 结构,使 CKafka 具有很高的容错性。
车辆数据经过离线分析和挖掘,分析结果可以用于优化车辆性能、提高驾驶安全、降低能耗等。
指令下发场景

在指令下发场景中,CKafka 承接远程指令和响应结果,为上下游多个系统提供异步接耦、削峰填谷的能力,同时消息持久化及可回溯的产品特性能保障指令状态的最终一致性。
使用 CKafka 后的业务收益
与自建 Kafka 相比,CKafka 有完善的监控告警系统和运维工单系统,CKafka 研发专家随时答疑解惑,迅速解决客户问题,省心省力。
CKafka 在性能、扩展性、业务安全保障、运维等方面具有超强优势,让客户在享受低成本、超强功能的同时,免除繁琐运维工作。当 CKafka 集群的流量和磁盘容量超过告警阈值,后端会及时扩容设备对客户端无感知,解决开源 Kafka 长期以来迁移数据的痛点,配置升级无感知,轻松应对业务高峰。
除了可拓展性之外,Ckafka 支持同地域自定义多可用区部署,跨地域灾备,提升业务容灾能力。
未来展望
针对降低存储成本、快速应对突发流量峰值的两个核心诉求,CKafka 将演进按量存储形态,并推出弹性带宽能力。
● 按量存储
按照实际使用存储空间弹性计费,无需考虑预留存储空间,更加灵活易运维,且成本更低。
● 弹性带宽
在既定带宽规格上,提供一定范围的上浮空间(即弹性能力)。
若遇到突发的流量毛刺,集群不会触发限流,而是在规定范围内弹性扩缩容,超出原有带宽部分的流量按量计费。
通过合理的架构设计和灵活的产品能力,CKafka 帮助用户在云上以更低成本托管高吞吐、高可用、易用免运维的消息队列 Kafka 服务,一站式搭建数据流转链路。后续也期待与出行行业客户有更多合作,分享更多云上最佳实践。
车辆产生的实时数据(如 GPS 位置、速度、油耗等)通过 CKafka 进行收集、传输、分发,实现一份数据多个流向满足多个场景需求。
实时计算部分
通过 Flink 提供的 Kafka 连接器,流数据经过 Flink 算子进行处理落入高性能列式数据库Clickhouse,用于实时更新数据的分析。该流程可提供一次精确的处理语义,同时 CKafka 多分区提供更高的吞吐量,减少数据倾斜和热点。
车辆故障、异常行为等车辆的状态数据,通过实时分析可以快速发现并处理车辆的问题。
离线分析部分
通过 Flume 等日志收集系统,可将 CKafka 中海量日志数据进行高效收集、聚合、移动,最后存储到 HDFS 或者 Hbase。在生产处理环节中,当生产与处理速度不一致时,CKafka 可以充当缓存角色。 拥有 Partition 结构以及采用 Append 追加数据,使 CKafka 具有优秀的吞吐能力;同时其拥有 Replication 结构,使 CKafka 具有很高的容错性。
车辆数据经过离线分析和挖掘,分析结果可以用于优化车辆性能、提高驾驶安全、降低能耗等。
指令下发场景
在指令下发场景中,CKafka 承接远程指令和响应结果,为上下游多个系统提供异步接耦、削峰填谷的能力,同时消息持久化及可回溯的产品特性能保障指令状态的最终一致性。
使用 CKafka 后的业务收益
与自建 Kafka 相比,CKafka 有完善的监控告警系统和运维工单系统,CKafka 研发专家随时答疑解惑,迅速解决客户问题,省心省力。
CKafka 在性能、扩展性、业务安全保障、运维等方面具有超强优势,让客户在享受低成本、超强功能的同时,免除繁琐运维工作。当 CKafka 集群的流量和磁盘容量超过告警阈值,后端会及时扩容设备对客户端无感知,解决开源 Kafka 长期以来迁移数据的痛点,配置升级无感知,轻松应对业务高峰。
除了可拓展性之外,Ckafka 支持同地域自定义多可用区部署,跨地域灾备,提升业务容灾能力。
未来展望
针对降低存储成本、快速应对突发流量峰值的两个核心诉求,CKafka 将演进按量存储形态,并推出弹性带宽能力。
● 按量存储
按照实际使用存储空间弹性计费,无需考虑预留存储空间,更加灵活易运维,且成本更低。
● 弹性带宽
在既定带宽规格上,提供一定范围的上浮空间(即弹性能力)。
若遇到突发的流量毛刺,集群不会触发限流,而是在规定范围内弹性扩缩容,超出原有带宽部分的流量按量计费。
通过合理的架构设计和灵活的产品能力,CKafka 帮助用户在云上以更低成本托管高吞吐、高可用、易用免运维的消息队列 Kafka 服务,一站式搭建数据流转链路。后续也期待与出行行业客户有更多合作,分享更多云上最佳实践。