VIT总结
关于transformer、VIT和Swin T的总结
1.transformer
1.1.注意力机制
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.[1]
输入是query和 key-value,注意力机制首先计算query与每个key的关联性(compatibility),每个关联性作为每个value的权重(weight),各个权重与value的乘积相加得到输出。
Attention Is All You Need 中用到的attention叫做“Scaled Dot-Product Attention”,具体过程如下图所示:
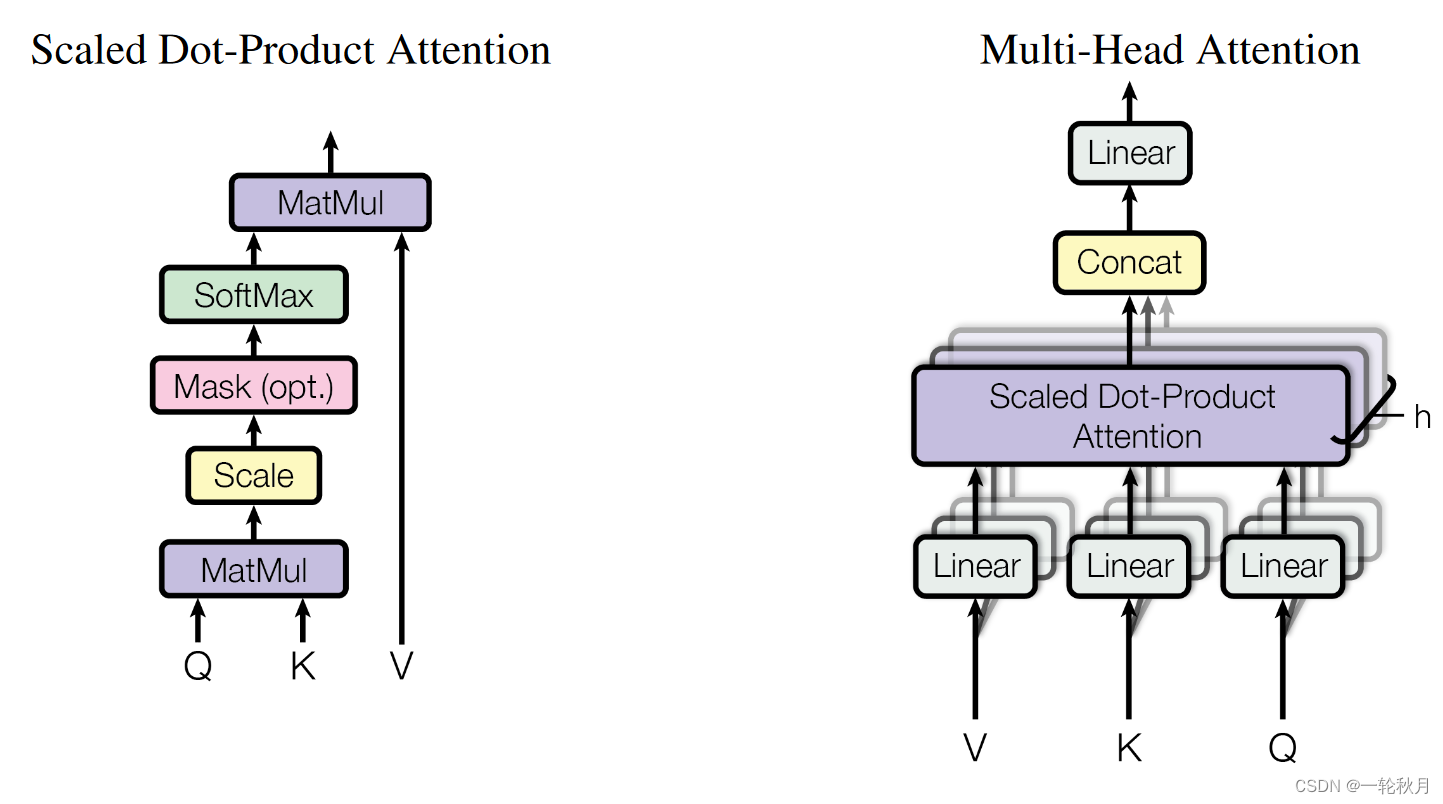
代码实现:
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0] # the number of training examples
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split embedding into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# queries shape: (N, query_len, heads, heads_dim)
# keys shape: (N, key_len, heads, heads_dim)
# energy shape: (N, heads, query_len, key_len)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# Fills elements of self tensor with value where mask is True
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
# attention shape: (N, heads, query_len, key_len)
# values shape: (N, value_len, heads, head_dim)
# after einsum (N, query_len, heads, head_dim) then flatten last two dimensions
out = self.fc_out(out)
return out
1.为什么有mask?
NLP处理不定长文本需要padding,但是padding的内容无意义,所以处理时需要mask.
2.关于qkv
qkv是相同的,需要查询的q,与每一个key相乘得到权重信息,权重与v相乘,这样结果受权重大的v影响
3.为什么除以根号dk
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients 4. To counteract this effect, we scale the dot products by 1 √dk
点积过大,经过softmax,进入饱和区,梯度很小
4.为什么需要多头

不同头部的output就是从不同层面(representation subspace)考虑关联性而得到的输出。
1.2.TransformerBlock
解码端的后面两部分和编码段一样,所以打包成一个类
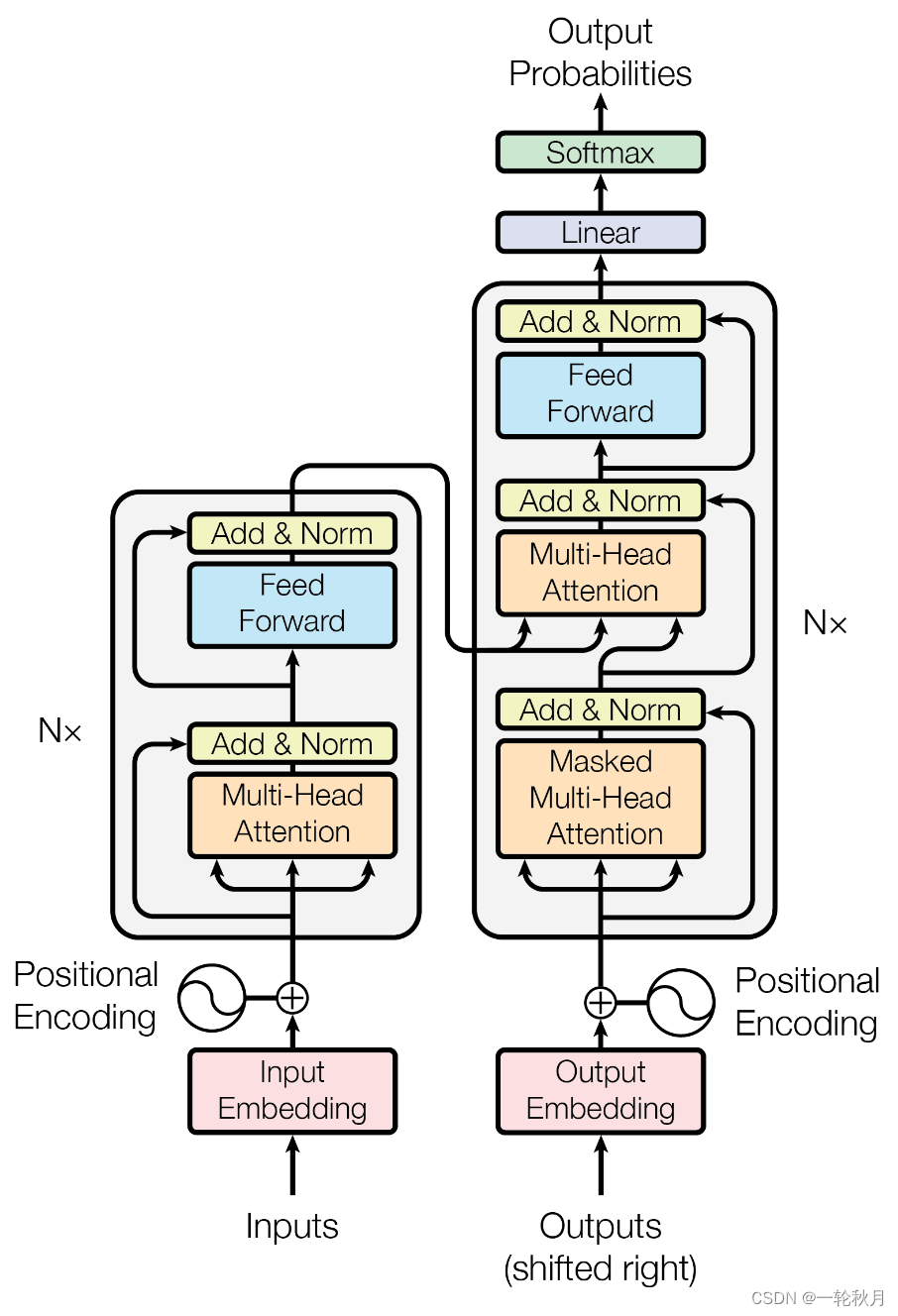
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
1.3.Encoder
关键的就是位置编码
class Encoder(nn.Module):
def __init__(self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion
)
for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_lengh = x.shape
positions = torch.arange(0, seq_lengh).expand(N, seq_lengh).to(self.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
return out
2.VIT
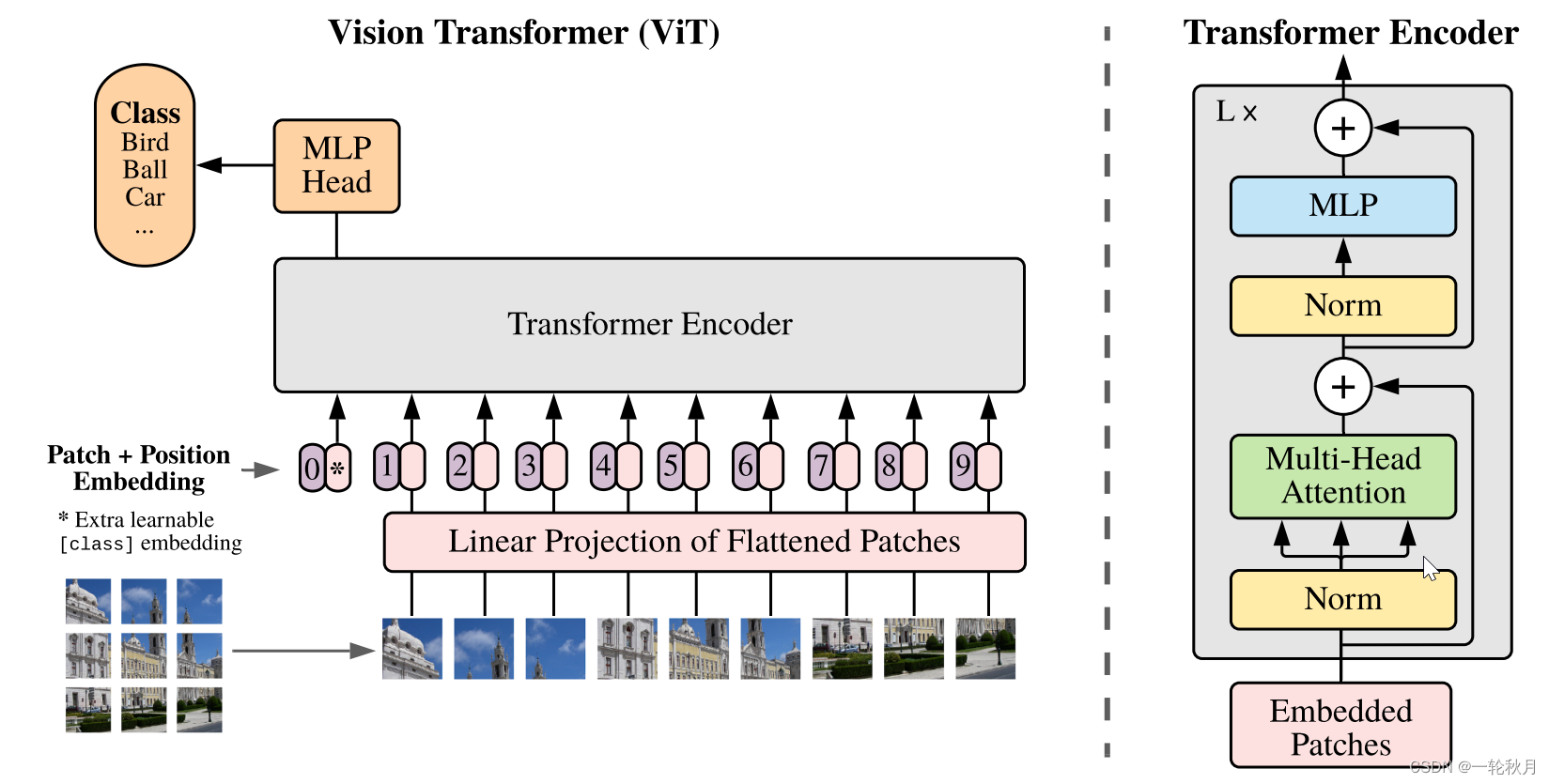
Reference:
[1].Attention Is All You Need
[2].https://zhuanlan.zhihu.com/p/366592542
[3].代码实现:https://zhuanlan.zhihu.com/p/653170203
[4].An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale