目标检测——Faster R-CNN算法解读
论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
链接:https://arxiv.org/abs/1506.01497
代码:https://github.com/rbgirshick/py-faster-rcnn
R-CNN系列其他文章:
- R-CNN算法解读
- SPPNet算法解读
- Fast R-CNN算法解读
目录
- 1、算法概述
- 2、Faster R-CNN细节
- 2.1 Region Proposal Networks
- 2.2 RPN和Fast R-CNN共享卷积特征
- 3、实验结果
- 4、创新点和不足
1、算法概述
之前的工作,像SPPnet和Fast R-CNN虽然都相对于R-CNN在提取特征的时间上有所改进,但针对区域候选框的生成这一步未做改进,这是两个算法的不足之处,此论文提出了Region Proposal Network(RPN)通过共享卷积层自动生成区域候选框:通过将RPN集成到Fast R-CNN中可实现区域候选框生成、类别预测及边界框预测一步到位,用VGG-16作为主干,在GPU上推理能达到5fps。Faster R-CNN在2015年的ILSVRC和COCO竞赛中取得了第一名的成绩。
2、Faster R-CNN细节
先说区域候选框的选取规则,为了尽量完全地包含图像中的目标,区域候选框旨在有效地预测具有广泛尺度和纵横比。目前的方式如下图几种:
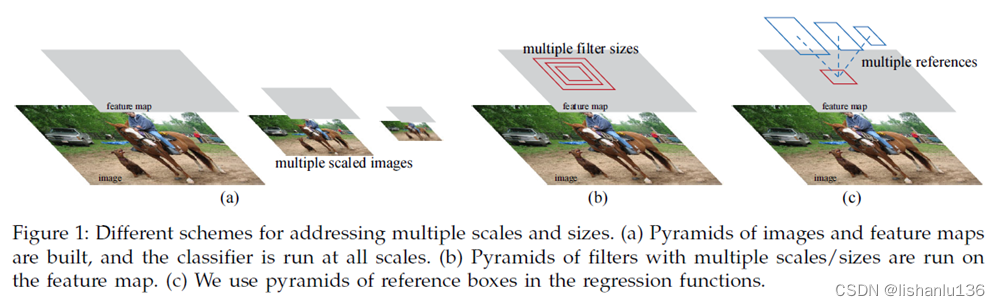
图1-a中是图像金字塔,图1-b是卷积核金字塔(通过变换卷积核大小),图1-c就是本文采用的方法,在特征图上应用多尺度/多纵横比的矩形框参考(论文中命名为“anchor”),这样可以避免枚举多个比例或宽高比的图像或卷积核。Faster R-CNN由于这样的操作,使得可以在单一尺度图像上完成候选框生成工作从而提高了运行速度。其整体网络框图如下所示:
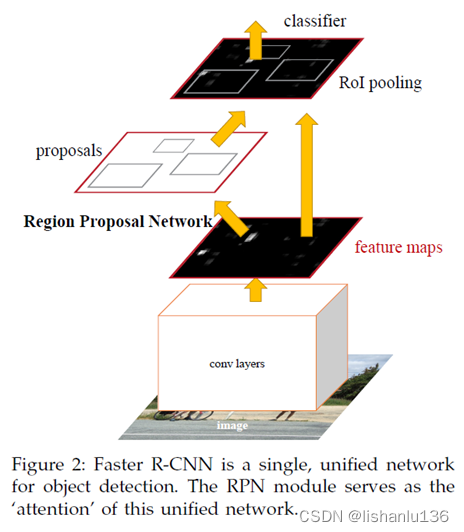
Faster R-CNN由两部分组成,第一部分为由全卷积网络组成的RPN结构,第二部分为Fast R-CNN检测器。如上图所示,RPN结构可以集成到Fast R-CNN中,共享其网络前部产生的特征图。当RPN模块产生区域候选框后,告诉Fast R-CNN模块区域候选框的位置,后面就是延续Fast R-CNN的操作了,应用RoI Pooling,然后输出接分类和回归分支。
2.1 Region Proposal Networks
候选框生成网络(RPN)接受任意大小的图像作为输入并输出一组矩形框做为目标的候选框,每个候选框都有一个是否是目标的得分(objectness,用softmax,只有两类,是目标或是背景,也可以用逻辑回归直接回归一个是目标的分数)。RPN结构为全卷积网络,文中采用ZFNet和VGG16,在特征图上应用3x3大小的滑窗将特征转换为256个1x1大小的特征图(ZFNet)和512个1x1大小的特征图(VGG16),最后用1x1大小的卷积核接分类分支和回归分支。
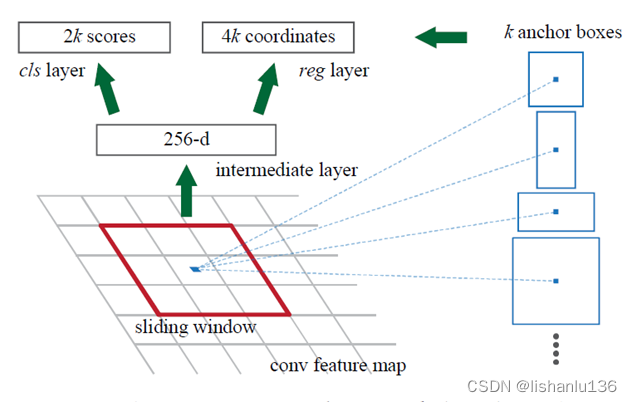
Anchors
每个滑窗包含有k个anchor boxes,所以每个3x3大小的滑窗对应有2k个分类分数和4k个坐标框预测。如上图所示,文中k取9,包含3个尺度,每个尺度包含3个宽高比;对于一个WxH大小的特征图,共生成WHk个anchor。由于这种基于锚点的多尺度设计,我们可以简单地使用在单尺度图像上计算的卷积特征,多尺度锚框的设计是共享特征而不需要为寻找多尺度花费额外成本的关键组件。
样本选择
正样本:该anchor与ground-truth拥有最高的IoU,或者该anchor与任意一个ground-truth的IoU都大于0.7。这里就说明一个ground-truth可以为多个anchor分配正样本标签。
负样本:与所有ground-truth的IoU都小于0.3的anchor被视为负样本。
其他剩余的anchor被丢弃,没有参与到RPN训练中。
Loss Function
RPN的损失函数有些类似于Fast R-CNN的多任务损失,如下:

Lcls为二分类损失,Lreg为回归损失,采用smoothL1,其中正负样本均参与分类损失的计算,回归损失只有正样本参与计算。对于bounding-box回归,也是采用类似R-CNN的做法,学习基于anchor的偏移量,预测box,anchor box,和ground-truth box之间的关系如下面公式:

例如针对某个预测box,使得anchor box中心点xa与预测box中心点x的距离尽量接近anchor box中心点xa与ground-truth box中心点x*的距离,其他三个值同理,这样就等价于预测box接近ground-truth box了。
训练RPN
训练RPN网络的样本都是来自图片的anchor样本选取的正负样本,由于负样本较多,会造成正负样本不平衡问题,所以我们设置batchsize为256,正负样本比例为1:1,如果正样本少于128,就用负样本补齐。
2.2 RPN和Fast R-CNN共享卷积特征
论文采用四步交替训练的方式实现RPN与Fast R-CNN的统一:
- 第一步:用ImageNet预训练模型微调RPN网络;
- 第二步:用RPN网络生成的区域候选框训练Fast R-CNN,训练之前也用ImageNet预训练模型初始化参数,这两步RPN和Fast R-CNN还没有共享卷积层参数;
- 第三步:用Fast R-CNN前部分卷积层参数初始化RPN训练,但是固定住共享层的参数,单独更新RPN独有部分的参数,这个时候就保证两个网络共享卷积层参数一致了。
- 第四步:固定住共享卷积层参数,微调Fast R-CNN独有部分的参数。
3、实验结果
作者在VOC2007,VOC2012上测试结果如下:
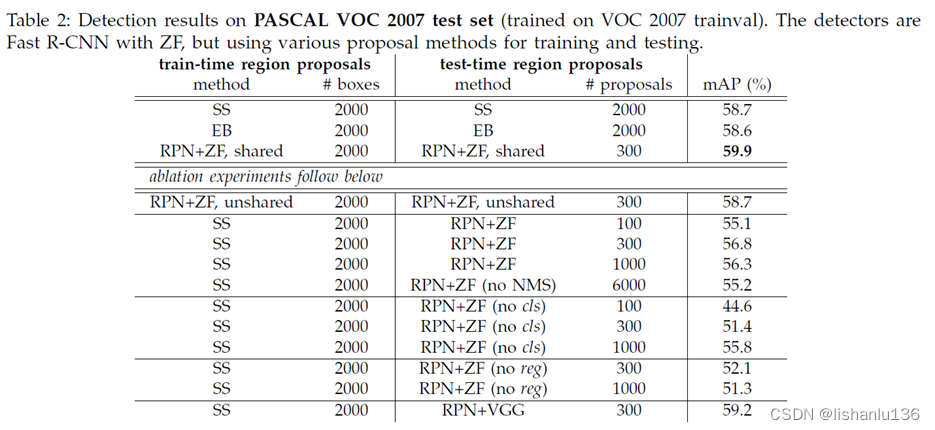
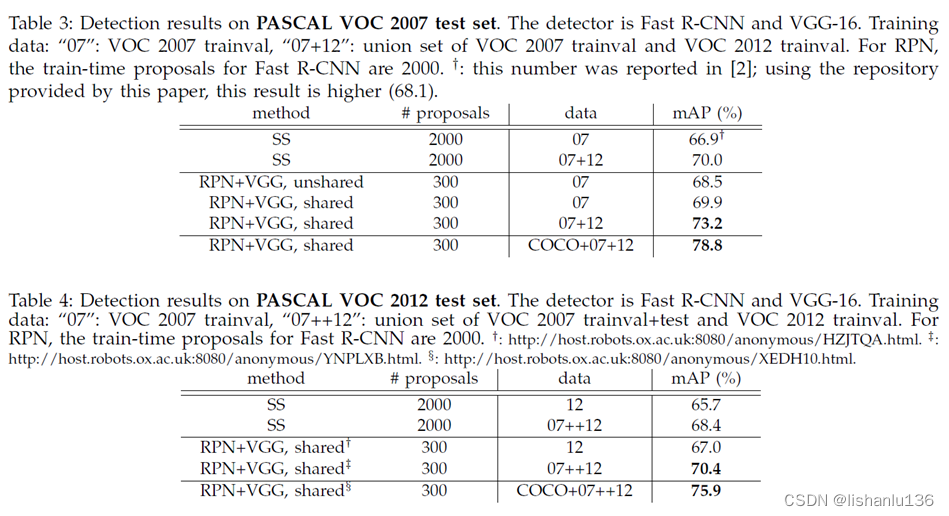
和用SS方式生成区域候选框的时间对比结果如下:

4、创新点和不足
- 创新点:
1、提出RPN网络生成候选框并集成到Fast R-CNN网络中,使得推理速度进一步得到提升;
2、提出anchor锚框的概念,使得能在一张图片上得到多尺度多宽高比的预测框学习参考;
3、 提出交替训练方法,使得RPN与Fast R-CNN能共享卷积层参数。 - 不足:
1、二阶段方法,推理速度还是难以在终端上运行;
突然想到yolo系列和这个RPN不谋而合啊,yolov2可以算单尺度版的RPN,yolov3可以算FPN版的RPN,只是yolo多了个类别识别分支,anchor设置不同,且分配正负样本的方式不同而已。