经典神经网络——ResNet模型论文详解及代码复现
论文地址:Deep Residual Learning for Image Recognition (thecvf.com)
PyTorch官方代码实现:vision/torchvision/models/resnet.py at main · pytorch/vision (github.com)
B站讲解: 【精读AI论文】ResNet深度残差网络_哔哩哔哩_bilibili
一、背景
ResNet是何凯明等人在2015年提出的模型,获得了CVPR最佳论文奖,在ILSVRC和COCO上的比赛成绩:(以下比赛项目都是第一)
- ImageNet Classification
- ImageNet Detection
- ImageNet Localization
- COCO Detection
- COCO Segmentation
Resnet,被誉为撑起计算机视觉半边天的文章,重要性不言而喻,另外,文章作者何凯明,在2022年AI 2000人工智能最具影响力学者排行里排名第一:

深度学习的发展从LeNet到AlexNet,再到VGGNet和GoogLeNet,网络的深度在不断加深,经验表明,网络深度有着至关重要的影响,层数深的网络可以提取出图片的低层、中层和高层特征。 通常来说,在同等条件下,网络越深,性能越好(暂且这样认为)。但当网络足够深时,仅仅在后面继续堆叠更多层会带来很多问题:
第一个问题就是梯度爆炸 / 消失(vanishing / exploding gradients),这可以通过BN和更好的网络初始化解决;
第二个问题就是退化(degradation)问题,即当网络层数多得饱和了,加更多层进去会导致优化困难、且训练误差和预测误差更大了,注意这里误差更大并不是由过拟合导致的(后面实验细节部分会解释)。resnet的出现,解决了这个问题,模型可以轻易堆叠到几十层上百层(一千层的都有)。
那么,接下来就来看看这个网络是如何解决问题的吧。
二、论文解读

1、ResNet网络是什么
ResNet(Residual Network)是一种深度神经网络模型,也被称为残差网络。它通过引入残差块(Residual Building Block)来解决深层神经网络训练过程中的梯度消失问题。
在ResNet中,网络的输出由两部分组成:
恒等映射(identity mapping)和残差映射(residual mapping)。恒等映射指的是将输入直接传递到下一层,而残差映射则是对输入进行一些非线性变换后再进行传递。这种设计使得网络能够更好地学习残差信息,从而让网络变得更加深层。
ResNet的关键创新点:
在于引入了shortcut connections,即跳过一层或多层的连接。这些连接使得信息能够更加顺畅地传递,避免梯度在传播过程中消失。通过这种方式,ResNet可以训练非常深的网络,而不会出现性能下降的问题。
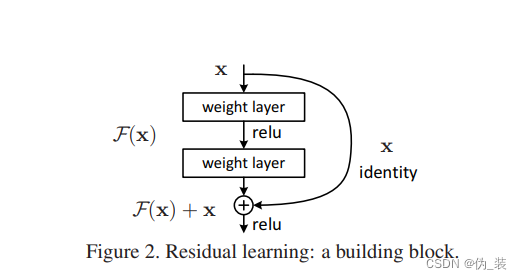
它添加了一个短路连接到第二层激活函数之前。那么激活函数的输入就由原来的输出H(x)=F(x)变为了H(x)=F(x)+x。在RestNet中,这种输出=输入的操作成为恒等映射。那么,上图中的identity其实功能也是恒等映射。
那么这么做的好处是什么呢?
在深度神经网络中,随着训练过程中反向传播权重参数的更新,网络中某些卷积层已经达到最优解了,其实此时这些层的输入输出都是一样的,已经没有训练的必要。但实际训练过程中,我们是很难将权重参数训练为绝对0误差的,但是这种情况已经是最优解了,其实对这些层的训练过程是可以抛弃的,即此时可以设F(x)=0,那么这时的输出为H(x)=x就是最优输出。
在传统平原网络中,即未加入identity之前,如果网络训练已经达到最优解了,那么随着网络继续训练、权重参数的更新,有可能将已经达到最优解的权重参数继续更新为误差更多的值。但随着identity的加入,在达到最优解的时候直接通过F(x)=x,那么权重参数可以达到至少不会比之前训练效果差的目的,并且可以加快网络收敛。
2、ResNets为什么能构建如此深的网络?
深度学习对于网络深度遇到的主要问题是梯度消失和梯度爆炸,传统对应的解决方案则是数据的初始化(normlized initializatiton)和(batch normlization)正则化,但是这样虽然解决了梯度的问题,深度加深了,却带来了另外的问题,就是网络性能的退化问题,深度加深了,错误率却上升了,而残差用来设计解决退化问题,其同时也解决了梯度问题,更使得网络的性能也提升了。

3、为什么能够解决梯度消失的问题?
首先看核心公式:
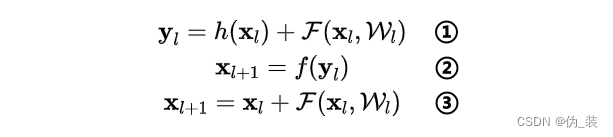
①式为恒等映射函数h(·)和残差函数F(·)之和,即:对第l层的输入x计算残差,再和x的恒等映射加起来,记作y;
②式表示对y进行激活,得到第l层的输出(也就是第l+1层的输入);③式是对①和②的整理,可以用一个式子统一起来书写。
上面的公式是针对相邻两层的情况,那么对于任意深的单元L和任意浅的单元l有:
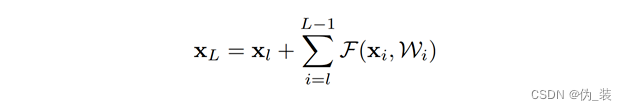
该式表示第L层的输入等于第l层的输出加上第l层到第L-1层的残差和,那么在优化的时候,只需要拟合残差项(后面的∑(·)),使之尽可能为0,就能实现第L层和第l层恒等,从而做到信息不丢失。为什么需要拟合残差呢?我个人的理解是:第L层和第l层之间的每一个部分,都会对当前造成影响,有些地方是不好的残差,那么优化方向可能会被带偏,起到反作用。
假如损失函数为ε,在反向传播时,对上面的式子求偏导,得到:
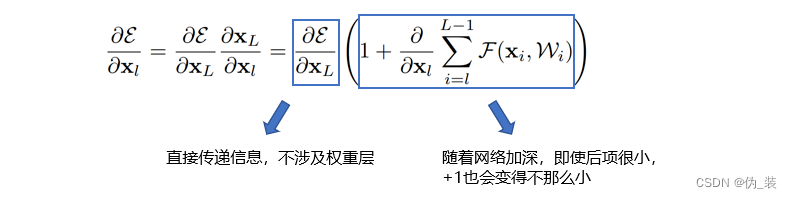
可以看到,左边蓝框框里的项没有权重信息,意味着反向传播的时候,信息能够从第L层直接传递到第l层,而无需经过权重,这就保证了信息的完整性。右边蓝框框里是1+▲是防止梯度消失的关键,因为目前大多用的是批量梯度下降算法,每次是把一个批量(batch)的样本送进去计算,那么不可能所有批量计算偏导的结果都为-1,从而1+▲在大部分情况下不会为0,因此即便某个批量计算的权重很小,都不会发生梯度消失。
4、为什么能够加快收敛速度?
实际上还是可以从上面的偏导公式来解释,在计算batch的梯度时,大多数情况可以获得一个较大的梯度值(因为有一个1在那里),从而可以大步向前走,更快地找到最优值。
另外,在整个模型中,浅层网络提取到的是低级特征,深层网络提取到的是复杂特征,如果没有恒等映射连接,那么最后是利用复杂特征进行拟合,从而比较费时,加入恒等映射,相当于保留了一部分低级特征用来判断。
理论方面讲完了,现在看看网络架构是什么样的:
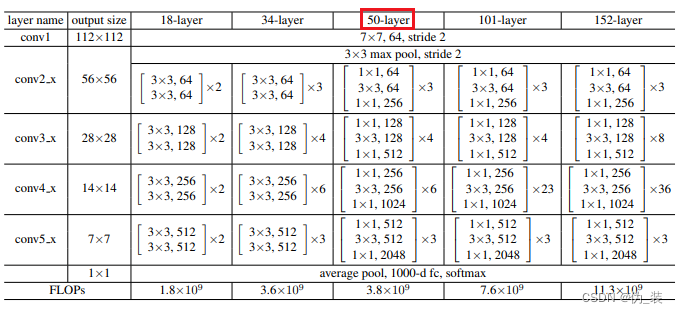
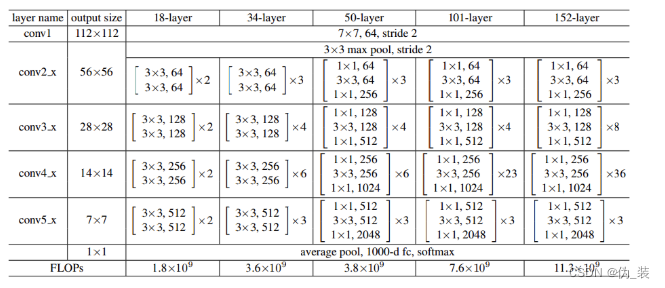
以50-layer为例,也就是后面将要实现的resnet_50,可以看到总共有6个模块,分别是:conv1、conv2_x、conv3_x、conv4_x、conv5_x、fc。
conv1主要是对原始输入图像进行第一波卷积,把输入图像从224缩小为112(这里的224和112指图像的长宽,后面同理);conv2/3/4/5_x是4个卷积模块,每个模块包含了多个由3个卷积层组成的小模块,例如,对于conv3_x这个模块来说,包含了4个小模块(右边有一个×4),每个小模块包含了3个卷积层。
三、ResNet使用PyTorch框架实现
kaggle项目地址:ResNet | Kaggle
import torch
from torch import nn
import sys
sys.path.append("../input/d2ld2l")
import d2l
from d2l.torch import load_data_fashion_mnist
from d2l.torch import train_ch6
from d2l.torch import try_gpu
from torch.nn import functional as Fclass Residual(nn.Module):
def __init__(self,in_channes,out_channes,use_1x1_conv=False,stride = 1):
super().__init__()
if use_1x1_conv:
self.res = nn.Sequential(
nn.Conv2d(in_channes,out_channes,kernel_size=1,stride=stride)
)
else:
self.res = nn.Sequential()
self.model =nn.Sequential(
nn.Conv2d(in_channes,out_channes,kernel_size=3,padding=1,stride=stride),
nn.BatchNorm2d(out_channes),
nn.ReLU(),
nn.Conv2d(out_channes,out_channes,kernel_size=3,padding=1),
nn.BatchNorm2d(out_channes)
)
def forward(self,x):
ret = self.model(x)
ret = ret+self.res(x)
return F.relu(ret)def get_residual_block(num_res,in_channels,out_channels,down_first = False):
blk = []
for i in range(num_res):
blk.append(Residual(in_channels,out_channels,i==0 and down_first,1+(i==0 and down_first)))
in_channels = out_channels
return blkin_channels = 1
b1 = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b2 = nn.Sequential(*get_residual_block(3,64,64))
b3 = nn.Sequential(*get_residual_block(4,64,128,True))
b4 = nn.Sequential(*get_residual_block(6,128,256,True))
b5 = nn.Sequential(*get_residual_block(3,256,512,True))resnet = nn.Sequential(b1,b2,b3,b4,b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),nn.Linear(512,10)
)test = torch.rand((1,1,224,224))
print("test net")
for layer in resnet:
test = layer(test)
print(layer.__class__.__name__,"shape:",test.shape)lr,num_epochs,batch_size = 0.05,10, 128
train_iter,test_iter =load_data_fashion_mnist(batch_size,resize=224)
train_ch6(resnet,train_iter,test_iter,num_epochs,lr,try_gpu())
四、 Resnet50使用keras框架实现
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D
from keras.models import Model, load_model
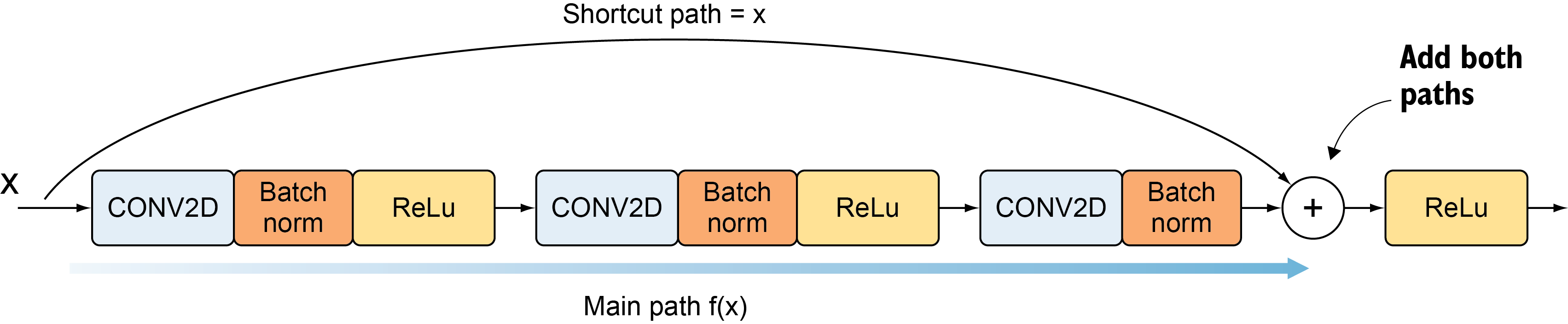
from keras.initializers import glorot_uniform特征块
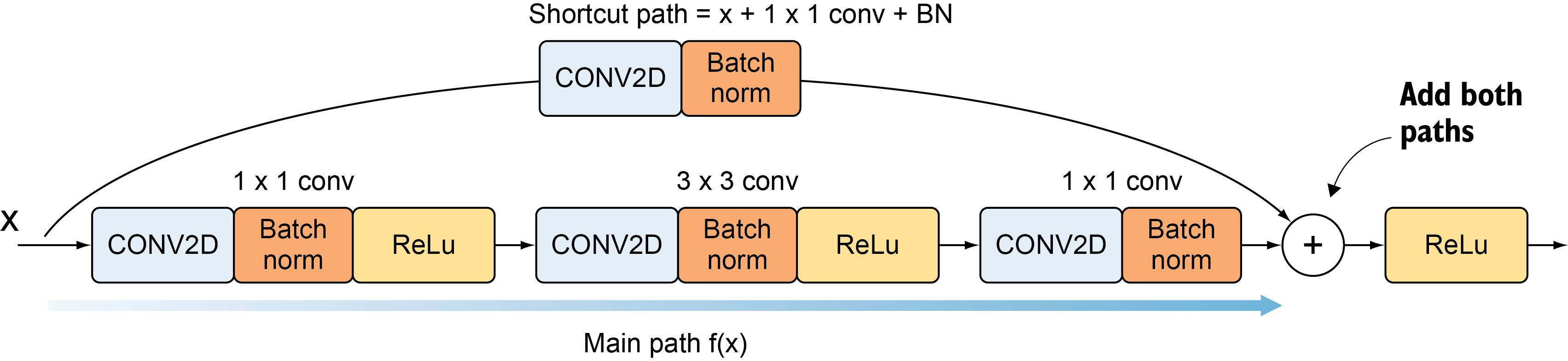
减少块
def bottleneck_residual_block(X, f, filters, stage, block, reduce=False, s=2):
"""
Arguments:
X -- input tensor of shape (m, height, width, channels)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
reduce -- boolean, True = identifies the reduction layer at the beginning of each learning stage
s -- integer, strides
Returns:
X -- output of the identity block, tensor of shape (H, W, C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value. You'll need this later to add back to the main path.
X_shortcut = X
if reduce:
# if we are to reduce the spatial size, apply a 1x1 CONV layer to the shortcut path
# to do that, we need both CONV layers to have similar strides
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (s,s), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
X_shortcut = Conv2D(filters = F3, kernel_size = (1, 1), strides = (s,s), padding = 'valid', name = conv_name_base + '1',
kernel_initializer = glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis = 3, name = bn_name_base + '1')(X_shortcut)
else:
# First component of main path
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
# Second component of main path
X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
# Third component of main path
X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
# Final step: Add shortcut value to main path, and pass it through a RELU activation
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return X
ResNet50 采用以下架构
def ResNet50(input_shape, classes):
"""
Arguments:
input_shape -- tuple shape of the images of the dataset
classes -- integer, number of classes
Returns:
model -- a Model() instance in Keras
"""
# Define the input as a tensor with shape input_shape
X_input = Input(input_shape)
# Stage 1
X = Conv2D(64, (7, 7), strides=(2, 2), name='conv1', kernel_initializer=glorot_uniform(seed=0))(X_input)
X = BatchNormalization(axis=3, name='bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X)
# Stage 2
X = bottleneck_residual_block(X, 3, [64, 64, 256], stage=2, block='a', reduce=True, s=1)
X = bottleneck_residual_block(X, 3, [64, 64, 256], stage=2, block='b')
X = bottleneck_residual_block(X, 3, [64, 64, 256], stage=2, block='c')
# Stage 3
X = bottleneck_residual_block(X, 3, [128, 128, 512], stage=3, block='a', reduce=True, s=2)
X = bottleneck_residual_block(X, 3, [128, 128, 512], stage=3, block='b')
X = bottleneck_residual_block(X, 3, [128, 128, 512], stage=3, block='c')
X = bottleneck_residual_block(X, 3, [128, 128, 512], stage=3, block='d')
# Stage 4
X = bottleneck_residual_block(X, 3, [256, 256, 1024], stage=4, block='a', reduce=True, s=2)
X = bottleneck_residual_block(X, 3, [256, 256, 1024], stage=4, block='b')
X = bottleneck_residual_block(X, 3, [256, 256, 1024], stage=4, block='c')
X = bottleneck_residual_block(X, 3, [256, 256, 1024], stage=4, block='d')
X = bottleneck_residual_block(X, 3, [256, 256, 1024], stage=4, block='e')
X = bottleneck_residual_block(X, 3, [256, 256, 1024], stage=4, block='f')
# Stage 5
X = bottleneck_residual_block(X, 3, [512, 512, 2048], stage=5, block='a', reduce=True, s=2)
X = bottleneck_residual_block(X, 3, [512, 512, 2048], stage=5, block='b')
X = bottleneck_residual_block(X, 3, [512, 512, 2048], stage=5, block='c')
# AVGPOOL
X = AveragePooling2D((1,1), name="avg_pool")(X)
# output layer
X = Flatten()(X)
X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X)
# Create the model
model = Model(inputs = X_input, outputs = X, name='ResNet50')
return modelmodel = ResNet50(input_shape = (32,32, 3), classes = 10)
model.summary()使用 plot_model 可视化网络
安装
- conda install graphviz
- conda install pydotplus
from keras.utils import plot_model
plot_model(model, to_file="images/resnet50.png", show_shapes=True)
参考:
ResNet50学习笔记 (附代码)_resnet中的恒等映射-CSDN博客
【AI】《ResNet》论文解读、代码实现与调试找错_resnet论文地址_Dreamcatcher风的博客-CSDN博客