论文笔记:Model-Contrastive Federated Learning
0 简介
论文:Model-Contrastive Federated Learning
代码:https://github.com/QinbinLi/MOON
相关链接:本文主要是将SimCLR对比学习的思想迁移到联邦学习中,关于SimCLR的介绍见https://blog.csdn.net/search_129_hr/article/details/130419626
1 核心思想
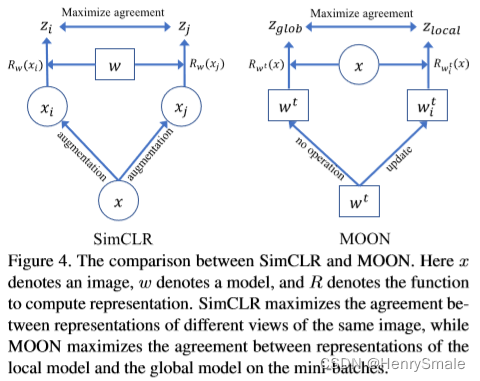
SimCLR对比学习的对象是:
- 图像 x x x先经过数据增强后得到的 x i x_i xi和 x j x_j xj,然后经过特征提取器 R w ( ⋅ ) R_w(\cdot) Rw(⋅)得到的特征 z i z_i zi和 z j z_j zj,训练的参数就是特征提取器的参数 w w w;
- 总体想法是同一张图片增强后的图片得到的特征要相聚,不同图片增强后的图片得到的特征相离;

本文提出的联邦学习MOON对比学习的对象为:
- w t w^t wt:the global model全局模型;
- w i t w_i^t wit:客户端 P i P_i Pi的局部模型;
- z prev = R w i t − 1 ( x ) z_{\text{prev}} = R_{w_i^{t-1}}(x) zprev=Rwit−1(x):上一轮本地训练好的发往服务器的本地模型得到的表征(固定);
- z glob = R w t ( x ) z_{\text{glob}} = R_{w^t}(x) zglob=Rwt(x):这轮开始时服务器发送到本地客户端的全局模型得到的表征(固定);
- z = R w i t ( x ) z = R_{w_i^t}(x) z=Rwit(x):这轮正在被更新的本地模型得到的表征(不断更新),本文作者在符号系统上没有仔细推敲,图中用的 z local z_{\text{local}} zlocal,公式用的是 z z z。
本文的目标是让
z
z
z靠近
z
glob
z_{\text{glob}}
zglob (固定),让
z
z
z远离
z
prev
z_{\text{prev}}
zprev (固定),通过如下损失函数来控制:
ℓ
con
=
−
log
exp
(
sim
(
z
,
z
glob
)
/
τ
)
exp
(
sim
(
z
,
z
glob
)
/
τ
)
+
exp
(
sim
(
z
,
z
prev
)
/
τ
)
,
\ell_{\text {con }}=-\log \frac{\exp \left(\operatorname{sim}\left(z, z_{\text {glob }}\right) / \tau\right)}{\exp \left(\operatorname{sim}\left(z, z_{\text {glob }}\right) / \tau\right)+\exp \left(\operatorname{sim}\left(z, z_{\text {prev }}\right) / \tau\right)},
ℓcon =−logexp(sim(z,zglob )/τ)+exp(sim(z,zprev )/τ)exp(sim(z,zglob )/τ),
其中
τ
\tau
τ为温度系数,分子是正样本对
(
z
,
z
glob
)
(z , z_{\text{glob}})
(z,zglob) ,分母是正样本对
(
z
,
z
glob
)
(z , z_{\text{glob}})
(z,zglob) +负样本对
(
z
,
z
prev
)
(z , z_{\text{prev}})
(z,zprev)。
ℓ
=
ℓ
sup
(
w
i
t
;
(
x
,
y
)
)
+
μ
ℓ
con
(
w
i
t
;
w
i
t
−
1
;
w
t
;
x
)
\ell=\ell_{\text {sup }}\left(w_i^t ;(x, y)\right)+\mu \ell_{\text {con }}\left(w_i^t ; w_i^{t-1} ; w^t ; x\right)
ℓ=ℓsup (wit;(x,y))+μℓcon (wit;wit−1;wt;x)
其中
ℓ
sup
(
w
i
t
;
(
x
,
y
)
)
\ell_{\text {sup }}\left(w_i^t ;(x, y)\right)
ℓsup (wit;(x,y))为监督学习交叉熵损失,客户端的
x
x
x利用全局模型
z
glob
=
R
w
t
(
x
)
z_{\text{glob}} = R_{w^t}(x)
zglob=Rwt(x)进行预测得到
y
^
\hat{y}
y^,然后和真实标签
y
y
y计算交叉熵Loss;
μ
\mu
μ为超参数控制对比学习的权重。
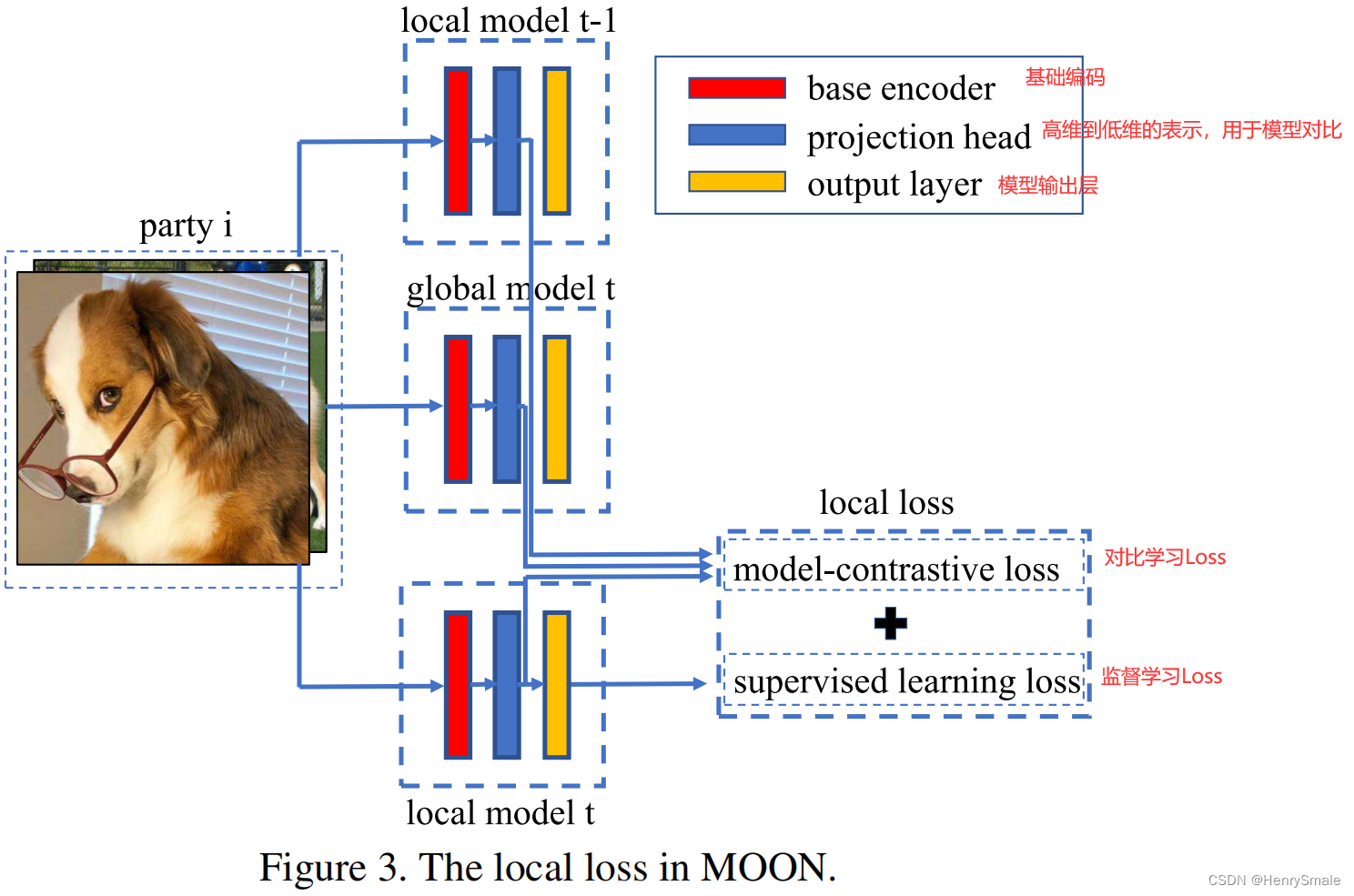
2 伪代码

- 理想情况下(IID),全局模型和本地模型训练得到的表征应该是一样好的,此时 ℓ con \ell_{\text {con }} ℓcon 是一个常数,这样会得到FedAvg一样的效果。
- 在这种意义上,MOON比FedAvg更具鲁棒性(能处理Non-IID的情况)。