在pytorch中自定义dataset读取数据
这篇是我对哔哩哔哩up主 @霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享
有关我们数据读取预训练
以及如何将它打包成一个一个batch输入我们的网络的
首先我们来看一下之前我们在讲resnet网络时所使用的源码
我们去使用了官方实现的image folder去读取我们的图像数据
然后再使用官方提供的data loader去对我们读取的数据进行一个打包
大家有没有想过这个image folder它的内部到底实现了哪些功能呢
那么我们今天为什么要讲这个dataset呢
因为在之前我们讲分类网络时
有很多小伙伴私信问我
如果我的图片不是rgb图像
是灰度图像或者是雷达图像
深度图像等等
就是非rgb的图像时
我该如何去载入并预处理我的图像
那么如果你直接通过官方提供的这个方法呢
其实它是有一定的局限性的
而且比如如果你想去设计一个比较独特的网络
比如说你设计的网络
它有多个输入
那么这种情况呢官方所提供的这些方法都是无法满足你的需求的
所以本节课我们来讲一下如何去实现我们自己的一个data set
以及进一步去讲解我们的data loader是如何利用我们data set所生成的数据
打包成一批一批的数据输入网络的
那么本节课所讲的一个代码呢
我已经提前上传到我的github上了
在pytourh classification模块下的custom dataset这个文件夹当中
然后这三个文件呢就是我们今天主要要讲的内容了
那么这个内容呢也是我们在后面讲利用多gpu训练时
所使用到的一个数据读取
以及预处理的部分
那么我们接下来就进入到我们的代码当中
首先呢我们看一下我们的main这个脚本
首先呢我们这里所使用的数据集
还是我之前所说的划分类数据集
之前也有小伙伴在问我数据在哪下载呀
我该如何去划分训练集以及验证集
那么今天呢我在这里就详细地将整个流程仔细的讲一遍
并且呢我这里写了一个新的关于划分数据集的一个脚本
相比原来那个脚本呢使用起来会更加的方便
不需要再将训练集以及验证集单独划分到不同的文件夹当中了
首先呢如果你想使用之前我们所说的花分类数据集
那么大家可以自己去在这个链接当中去下载
下载完之后呢
你会得到一个点tgz的一个压缩文件
然后解压之后呢
我们可以看到都有个flower photos
在这个文件夹下呢主要有这五个子文件夹
每个文件夹呢它对应的一种花的类型
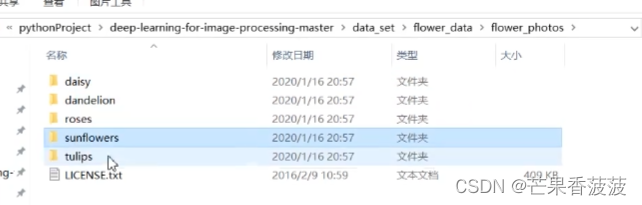
比如说我们看这个daisy
这个daisy呢它对应的就是雏菊
也就是说在这个文件夹下面的所有图片都是关于雏菊这个类别
那么我们下载完之后呢
我们这里的root这个变量就指向我们的flower photos
那么我这里就已经设置好了
就保存在我所给定的这个路径下

然后呢我们就进入到我们这个main函数

接下来呢我们就使用我们的read split data
这个方法来划分我们的训练集一验证集
那么这个方法呢我们只需要传入一个root这个参数就可以了
然后我们来仔细的看一下这个方法
进入这个方法之后呢
我们可以看到有两个参数
第一个是root

就是我们刚刚所说指向我们解压后的文件夹的路径
然后这个rate它是我们划分验证集所占所有样本的一个比例
我们这里将我们引入的random这个随机的这个包
设置一个随机种子设置为零
这里为什么要设计随机种子呢
就在于能够保证随机结果是可以复现的
也就是说只要我们将这个random的种子设置为零之后
无论是在你的电脑上
我的电脑上还是其他人电脑上
我们待会儿通过随机函数所随机划分的数据都是一模一样的
也就是都是可复现的

这样呢就能够保证大家划分的数据集都是一模一样的
然后接下来呢我们来判断一下我们所传入的这个路径
它是否存在
如果不存在
我们就会报出一个错误
接下来我们再通过os库的例子
第二来便利我们所给的那个路径下的所有的文件
那么它它变的文件呢可能就包含有文件夹以及我们普通的文件
然后这里呢我们就通过一个for循环来遍历它所编辑得到的
每一个文件夹或文件

接下来我们再判断
如果我们的这个路径它所对应的是个文件夹的话
那么我们就将它进行保存
如果不是文件夹的话
那我们就将它丢弃
那么这样我们得到的flower class就应该有五个值
![]()

初始化几个空列表
那么这里呢我再多说一句
我们这里为什么要使用PIL的image这个库

而不去使用open cv
因为在touch它所提供的这一系列预处理方法

其实它主要还是针对pl库所读入的images

比如我们随机看一个预处理方法
那么在他预处理方法的计划当中呢
他写的就是针对一个PIL的image进行一个处理的
然后这里我再多说一句
就是有时候我们在调试过程当中可能会遇到这种情况
就是我想看一下变量的一个信息
但是我设置断点之后
我们在debug这个信息当中呢
看到每个变量一直在显示正在载入数据
然后一直看不到
那么这个问题要怎么解决呢
那么这里呢大家可以点击这个file
然后在设置当中
然后在我们的build execution deployment
 然后在这个地方呢大家可以勾选一下这个
然后在这个地方呢大家可以勾选一下这个
然后再点ok
这样的话你在调试过程当中
每一个变量它的参数值就会很快的载入进来了
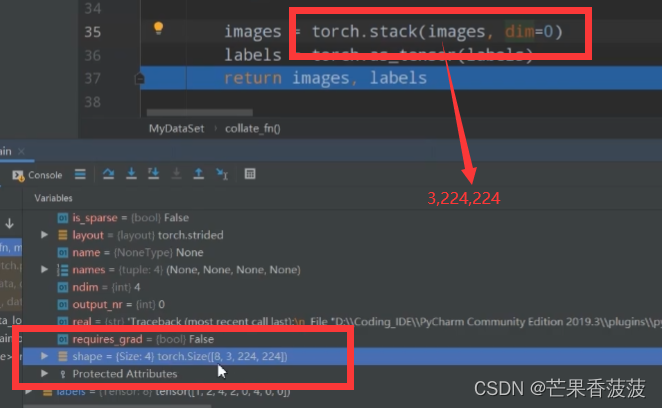
那么通过stack方法之后呢
它会增加一个新的维度
那么这个新维度是在dimension等于零的位置上
那么拼接之后我们可以来看一下我们所得到的shape

那接下来我们再将我们的labels也转化成tensor形式
因为刚在我们item的方法当中呢
我们通过transform方法将我们的image已经转换成tensor格式了
但我们label它并不是tender格式
所以这里我们要通过touch as tensor这个方法
我们label也转换成tensor
然后我们所得到的labels呢
它就是一个tensor变量了
然后我们再通过return
就可以将我们打包好的图片以及标签信息进行一个返回
那么接下来我们再停止我们的一个调试过程
我们再回到我们的main函数当中
那么这里我们讲了这么多
我说的这些到底是不是对的呢
我们接下来再通过我们所得到的这个train data loader
应该读取它的图片以及标签信息
看是否是正确的
那么这里我又实现了个plot data loader image这个方法

那我们来看一下这个方法
这个方法当中呢
首先我们获取一下我们这个data load的batchsize
然后我们这个json pass就指向我们刚刚生成的这个json文件
然后我们这里判断一下存存在
如果不存在就报错
然后我们再打开这个计算文件
然后载入它就得到了我们的一个字典

然后通过transport方法来调整它的一个通道顺序
原来通道顺序是channel
高度宽度
那么通过transpose之后
我们就还原成了高度宽度以及channel
然后在我们刚刚预处理过程当中呢
首先我们这个Totensor会将我们的数据范围从0~255
缩放到0~1之间

然后呢通过这个normalize这个方法
将我们数据rgb 个通道的数值分别减去这三个均值
然后再除以这三个标准差
得到我们标准化之后的数据
那么现在我们读入的数据就是标准化之后的数据
如果我们要绘制它呢
我们就需要将它转化回去
所以呢我们这里就对我们的rgb 通道首先乘以这三个数值
然后再加上这三个数值
然后再乘以255
我们就可以还原回原来的一个图像了

那么我们这里绘制的一个图像当中一共有1个行,plot number个列
![]()
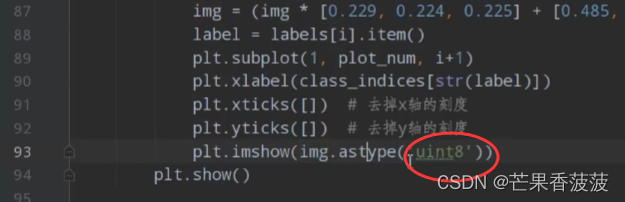
我们这里呢由于我们刚刚进行了一系列操作之后呢
它是一个float类型
我们这里将它转化成一个int 类型然后再show