RepVGG,结构重参数化让VGG风格的ConvNets再次强大起来
论文:RepVGG Making VGG-style ConvNets Great Again
链接:https://arxiv.org/abs/2101.03697
代码链接:https://github.com/DingXiaoH/RepVGG
发表刊物:cvpr2021
作者:Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding Jian Sun
单位:清华大学,旷视科技
文章目录
- 1、算法概述
- 2、RepVGG细节
- 3、实验
- 3.1 分类
- 3.2 语义分割
- 4、限制
1、算法概述
- 算法亮点:
1、训练和推理分开,像ResNet那样训练,像VGG那样推理。
2、不用任何训练技巧,在ImageNet上精度可媲美ResNet,EfficientNet,ResNex,推理速度大幅提升。 - 研究VGG式网络风格的初衷:
1、3x3卷积非常快,很多芯片专门对3x3卷积做了加速,在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
2、单路架构推理非常快,因为并行度高。
3、单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
4、单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
5、VGG式网络算子简单,3x3卷积接ReLU,设计专用芯片时,可以提升效率和降低成本。
有了上面VGG式网络的优点,于是作者猜想,像ResNet,Inception,DenseNet等各种NAS架构,它们均是多分支结构,有之前的研究认为分支结构(如:shortcut)产生了一个大量子模型的隐式ensemble,既可以传递梯度也可以使提取的特征更丰富。既然多分支架构是对训练有益的,而我们想要部署的模型是单路架构,所以作者提出解耦训练时和推理时架构。这样就可以同时利用多分支模型训练时的优势(性能高)和单路模型推理时的好处(速度快、省内存)。
所以传统方式是训练一个模型,然后部署这个模型;而本文的步骤变为:训练一个多分支模型,将多分支模型等价转换为单路模型,部署该单路模型。
2、RepVGG细节
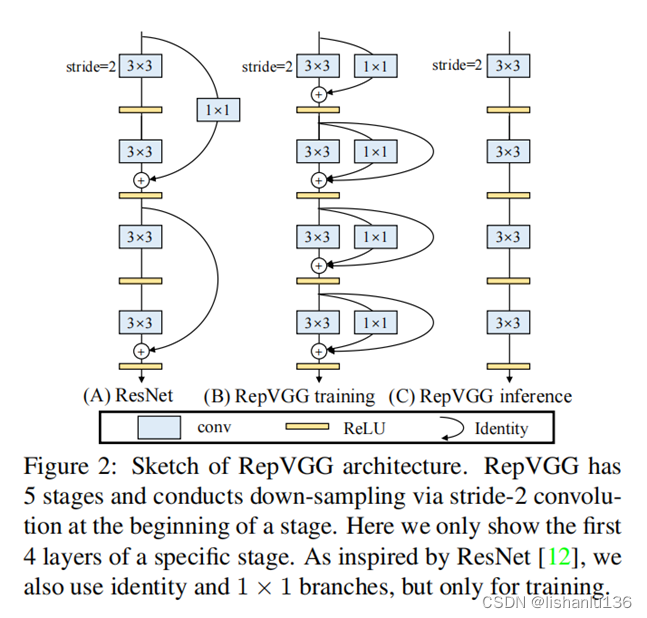
如上图所示,在训练时,为每一个3x3卷积层添加平行的1x1卷积分支和恒等映射分支,构成一个RepVGG Block。这种设计是借鉴ResNet的做法,区别在于ResNet是每隔两层或三层加一分支,而我们是每层都加。训练完成后,将训练模型等价转换成类似于vgg网络的单路网络,加快推理速度。等价转换方式如图:
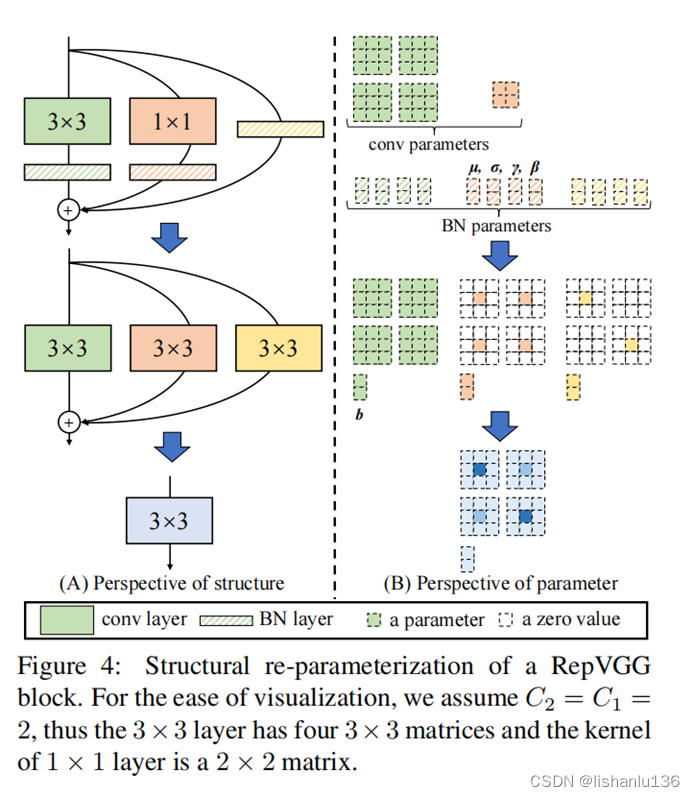
训练完成后,对模型做等价转换,得到部署模型。根据卷积的线性(具体来说是可加性),设三个3x3卷积核分别是W1,W2,W3,有 conv(x, W1) + conv(x, W2) + conv(x, W3) = conv(x, W1+W2+W3)。
1x1卷积是相当于一个特殊(卷积核中有很多0)的3x3卷积,而恒等映射是一个特殊(以单位矩阵为卷积核)的1x1卷积,因此也是一个特殊的3x3卷积
3、实验
3.1 分类
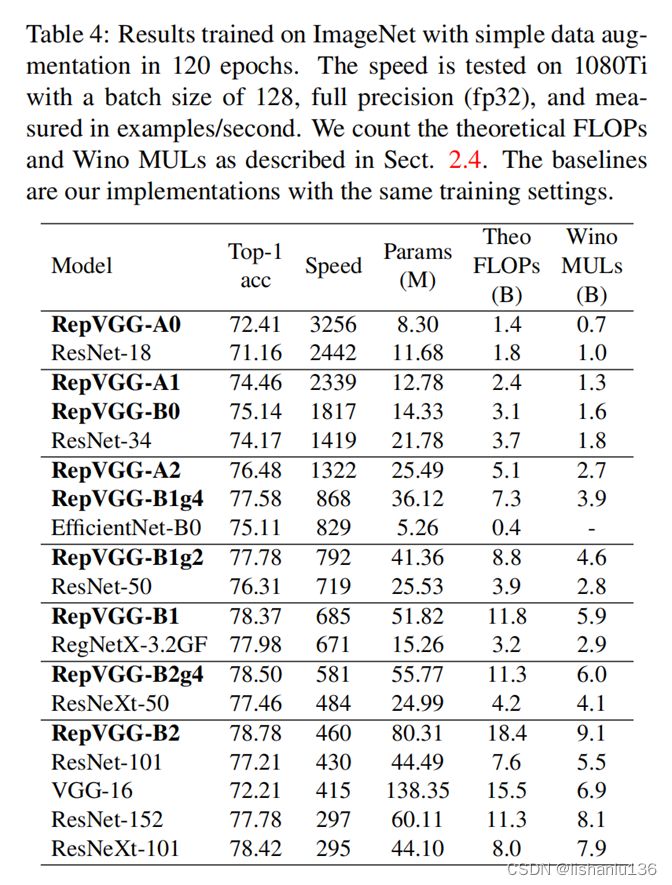
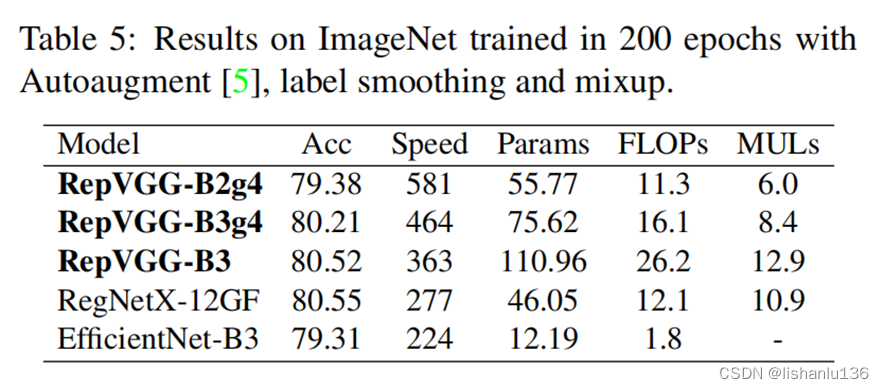
RepVGG和ResNet、EfficientNet、ResNeXt精度差不多,但是速度更快。
这也说明,在不同的架构之间用FLOPs来衡量其真实速度是欠妥的。例如,RepVGG-B2的FLOPs是EfficientNet-B3的10倍,但1080Ti上的速度是后者的2倍,这说明前者的计算密度是后者的20余倍。
3.2 语义分割
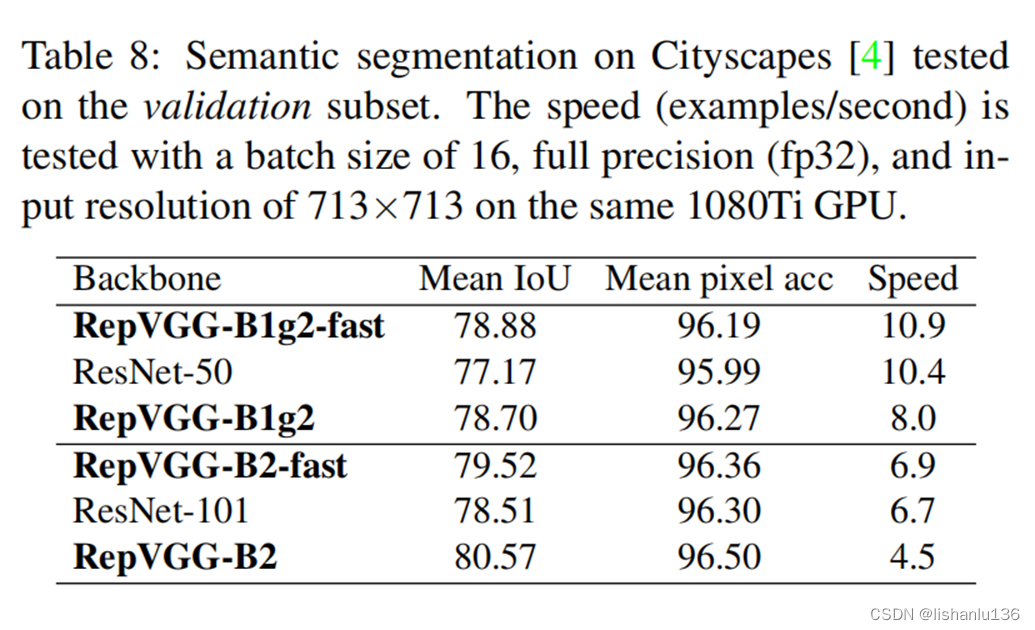
在Cityscapes上的语义分割实验表明,在速度更快的情况下,RepVGG模型比ResNet系列高约1%到1.7%的mIoU,或在mIoU高0.37%的情况下速度快62%。
4、限制
RepVGG是为GPU和专用硬件设计的高效模型,追求高速度、省内存,较少关注参数量和理论计算量。在低算力设备上,可能不如MobileNet和ShuffleNet系列适用。