使用消息队列遇到的问题—kafka
目录
- 1 分区
- 2 消费者
- 3 Kafka 如何保证消息的消费顺序?
- 3.1 方案一
- 3.2 方案二
- 4 消息积压
在项目中使用kafka作为消息队列,核心工作是创建生产者—包装数据;创建消费者----包装数据。
欠缺一些思考,特此梳理项目中使用kafka遇到的一些问题和解决方案
1 分区
参考博文:点击链接
分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序
示例:假设有一个主题(Topic)A,有三个分区(Partition 0、Partition 1、Partition 2)。如果生产者产生了5条消息,该如何分配?
这就涉及到了kafka的分区机制了
kafka 的分区策略指的就是将生产者发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
分区策略有
- 顺序轮询 (下面示例介绍)
- 随机轮询
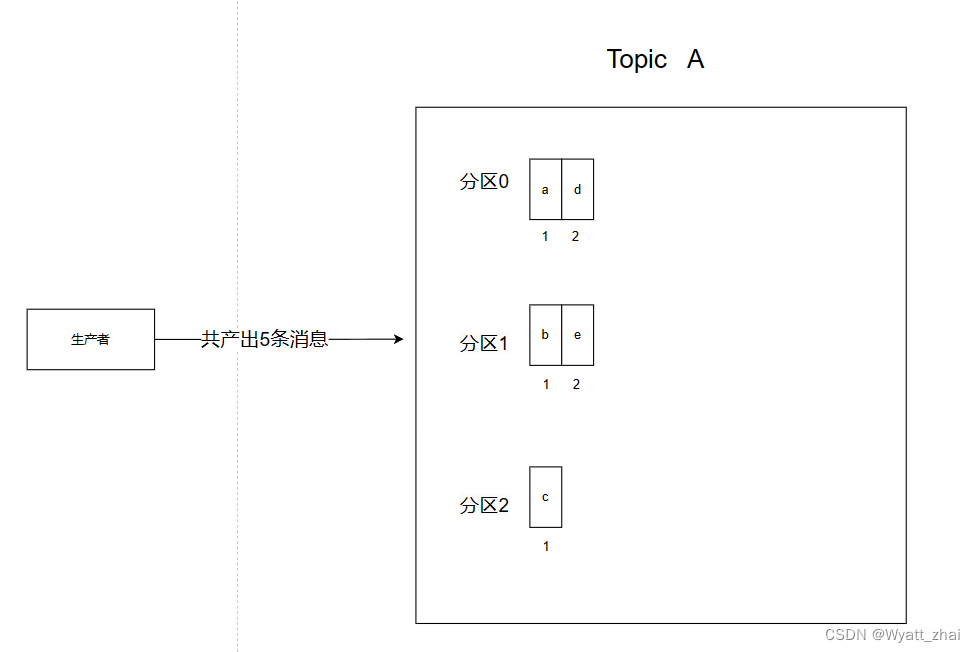
Kafka中消息的分配到分区的过程是由分区器(Partitioner)来负责的。默认情况下,Kafka使用的是轮询分区策略,也就是说,生产者产生的消息会依次被分配到不同的分区,以此循环。
假设有一个主题(Topic)A,有三个分区(Partition 0、Partition 1、Partition 2)。如果生产者产生了5条消息,这些消息会被轮询地分配到这三个分区中,直到所有消息都被发送。分配的过程如下:
第1条消息分配到 Partition 0
第2条消息分配到 Partition 1
第3条消息分配到 Partition 2
第4条消息再次分配到 Partition 0
第5条消息再次分配到 Partition 1
这样的分配方式保证了各个分区的负载均衡。总体而言,如果有足够的消息量,这些消息会在各个分区之间均匀分布,从而实现了平均分配的效果。
需要注意的是,分区策略是可以配置的,你可以自定义分区器来实现不同的分配策略,但默认情况下,轮询分区是常见的方式。
2 消费者
消费组: 消费数据的时候,都必须指定一个group id,指定一个组的id假定程序A和程序B指定的group id号一样,那么两个程序就属于同一个消费组。
特殊: 比如,有一个主题topicA程序A去消费了这个topicA,那么程序B就不能再去消费topicA(程序A和程序B属于一个消费组);再比如程序A已经消费了topicA里面的数据,现在还是重新再次消费topicA的数据,是不可以的,但是重新指定一个group id号以后,可以消费。不同消费组之间没有影响,消费组需自定义,消费者名称程序自动生成(独一无二)。
此时有两个消费者,三个分区,该如何分配呢?
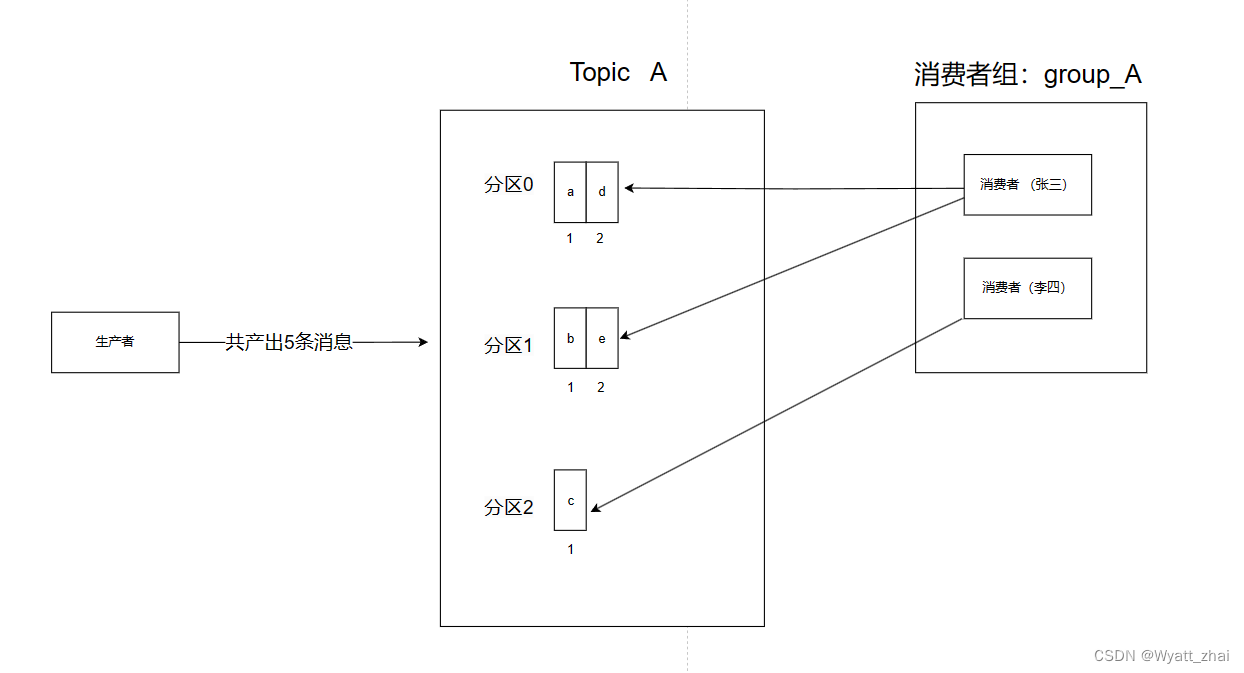
在 Kafka 中,一个消费者组(Consumer Group)可以由多个消费者组成。当消费者组订阅一个主题(Topic)时,Kafka 会自动将主题的分区分配给消费者组中的消费者。
对于一个消费者组中的多个消费者,它们不需要手动指定分区。Kafka 使用一种分区分配策略来确保每个分区只被一个消费者消费。默认情况下,Kafka 使用的是范围分配(Range Assignment)策略。
在范围分配策略下,每个消费者被分配一定范围的分区。例如,有一个主题有三个分区(Partition 0、Partition 1、Partition 2),消费者组中有两个消费者(Consumer A 和 Consumer B),分配可能如下:
Consumer A 被分配 Partition 0 和 Partition 1
Consumer B 被分配 Partition 2
这种自动的分区分配机制使得消费者组能够 并行 地处理消息,提高整体的消费吞吐量。
需要注意的是,如果消费者组中的消费者数量发生变化,分区的分配会动态调整以适应新的消费者数量,而无需手动干预。 Kafka会在有新的消费者加入或者有消费者退出时自动重新平衡分区。这种自动的分区调整机制是 Kafka 提供的一项强大的功能,能够使得整个系统更加灵活和容错。
3 Kafka 如何保证消息的消费顺序?
消费后会提交偏移量
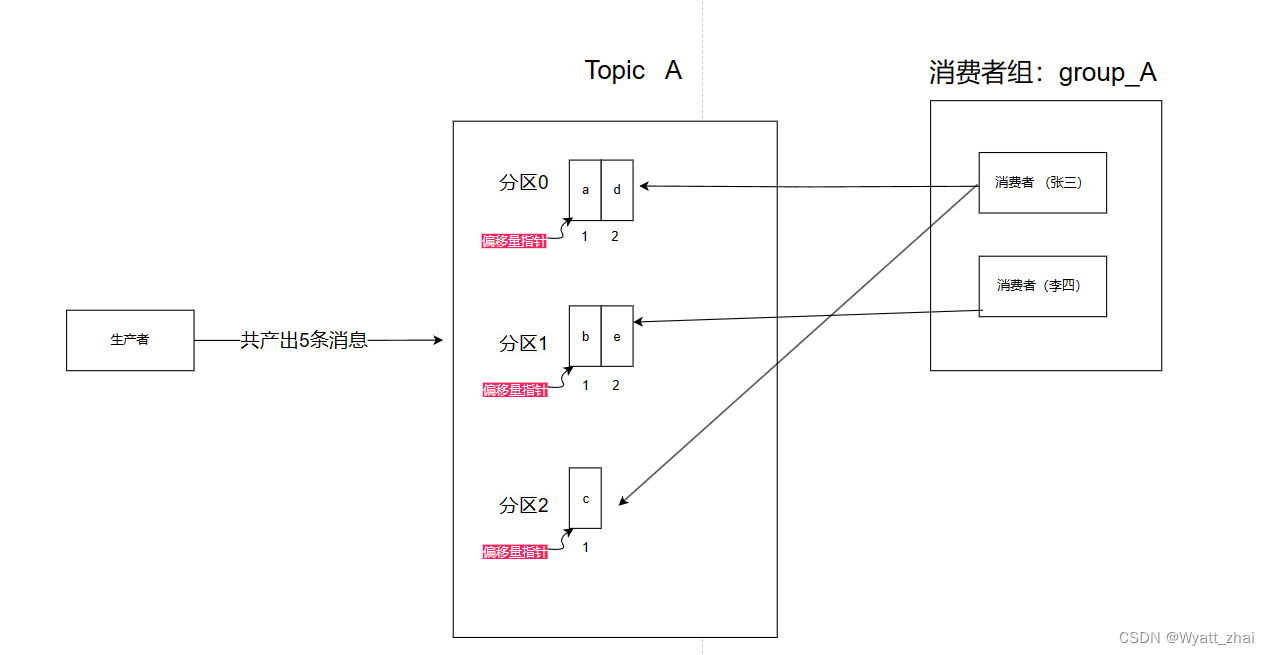
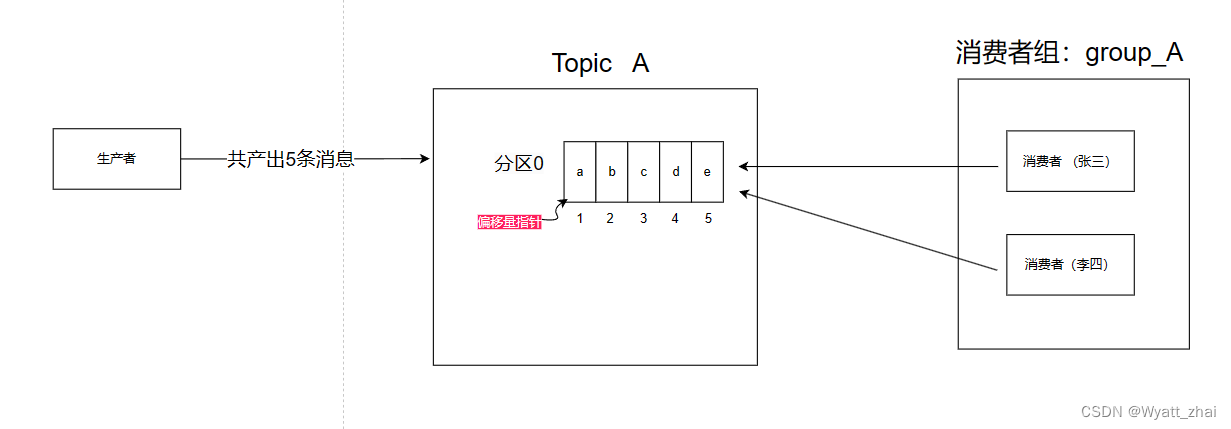
示例:生产者提供了5条消息,暂且按照上述方式分配消息。当消费者组 消费的时候会出现这种情况
0:01时刻 :张三消费c(并提交offset) 李四消费b(并提交offset)
重新动态匹配 消费者和分区,这里暂且忽略
0:02时刻 :张三消费a(并提交offset) 李四消费e(并提交offset)
此时消费的顺序是 c,b---->a,e
期待的消费顺序是a–>b—>c—>d---->e
因此是乱序的,需要重新设计方案解决
3.1 方案一
若是只有一个分区,这样就可以保证消费顺序了:a–>b—>c—>d---->e
3.2 方案二
指定消息全存在某一个分区
如何指定: Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
- Topic: 指定消息要发送到的主题。
- Partition: 指定消息要发送到的分区。如果指定了分区,那么所有的消息都会被发送到这个分区。
- Key: 通常用于确定消息应该被发送到哪个分区。如果你使用相同的 key,Kafka 会根据 key 使用分区器(Partitioner)将具有相同 key 的- 消息发送到同一个分区。
- Value: 实际的消息内容。
Key是用于计算消息应该被分配到哪个分区的依据,而Partition是直接指定分区
4 消息积压
4.1 方案一
场景描述:
- Kafka 主题:orders,2个分区
- 初始状态:有一个消费者组(Consumer Group)中有一个消费者实例(Consumer Instance)用于处理订单消息。
- 积压情况:由于订单数量激增,导致 orders 主题中的消息积压。
- 增加消费者
以前消息被分发到2个分区,但是只有一个消费者消费其中一个分区,另外一个暂时搁置,多创建一个消费者,提高使用率。
这里有个细节,项目执行后,唯一的线程:main线程---->消费分区1,无法做到同时控制另外一个消费者去消费分区2。看似消费者多了,实际效率没变化。只能增加线程
- 增加线程
一个消费者占一个线程,这样项目启动,2个线程控制2个消费者,kafka负载均衡自动分配(一个消费者消费一个分区),提高了效率
- 异步消费 (并不能处理消息积压)
在系统中,主线程调用 某个方法后,这个方法先返回数据给主,主继续执行自己的逻辑。而这个方法是异步的,所以他可以在后台创建线程和消费者,不会造成系统阻塞。